






作者 | 黄哲威 hzwer 编辑 | 自动驾驶之心
原文链接:https://www.zhihu.com/question/7837132971/answer/65410137584
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
国产大模型又信仰充值了
deepseek 找到了一个弯道超车海外 LLM 的方法,作为友商员工我都愿意粉一下,真产业升级
我觉得把刷榜看成是模型能力增强带来的副产品,效果是好于 1. 对着榜去刷过拟合 2.急着用赶超战略复刻新技术的
比方说我们发现 GPT4 某些榜表现好,专门加这类数据并不本质,反而污染了一个原本很好的评价指标
把基模做强就有惊喜!又是 The Bitter Lesson。既想刷榜又不想做预训练,就很容易技术落后
当 OpenAI / Anthropic 有些新现象和新技术出来,要复刻的前提是基础模型够强,不然即使人家把监督微调 / 强化学习的数据开源了,小模型可能学完也没什么变化
研究小模型最怕的也是得到的结论和大模型完全不相关,浪费宝贵人力和时间
从这个角度来说,预训练不做就很难发现新的模型特性和现象,只能等别人喂
等别人开源模型完再动工新产品或者研究,再退一步就是等着 copy huggingface 开源社区 demo 了
https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf
作为近期必读的技术报告,我也来瞅瞅,当然工程上我有很多不了解的地方,欢迎大家指正
主要贡献
架构改进: 在 DeepSeek-V2 的高效架构基础上,我们引入了一种无辅助损失的负载均衡策略,以最小化负载均衡对模型性能的负面影响。
多令牌预测: 我们研究了多令牌预测(MTP)目标,并证明了它在模型性能方面的益处。MTP 目标可以用于推测性解码,以加速推理。
预训练: 我们设计了一个 FP8 混合精度训练框架(工程好强啊),并首次在极其大规模的模型上验证了其可行性和有效性。通过算法、框架和硬件的联合设计,我们克服了跨节点 MoE 训练的通信瓶颈,实现了近全计算-通信重叠,从而显著提高了训练效率并降低了成本。
后训练: 我们引入了一种创新的方法,从 DeepSeek-R1 系列模型中蒸馏推理能力,并将其集成到标准 LLMs 中,特别是 DeepSeek-V3。我们的管道优雅地将 R1 的验证和反射模式集成到 DeepSeek-V3 中,显著提高了其推理性能。同时,我们还保持了对输出样式和长度的控制。
核心评估结果总结: DeepSeek-V3 在知识、代码、数学和推理等多个领域表现出色。在教育基准测试(如 MMLU、MMLU-Pro 和 GPQA)上,它超越了所有其他开源模型,并表现出与领先封闭源代码模型(如 GPT-4o 和 Claude-Sonnet-3.5)相当的性能。在数学相关基准测试上,DeepSeek-V3 取得了最先进的性能,甚至在某些基准测试上超过了 o1-preview。在编码相关任务上,DeepSeek-V3 在编码竞赛基准测试(如 LiveCodeBench)上表现出色,成为该领域的领先模型。
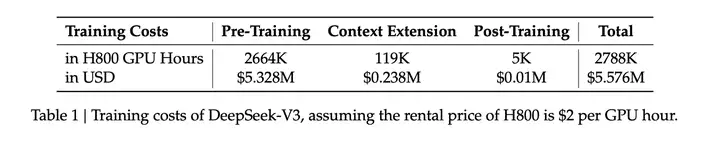
预训练
14.8T数据,2048 H卡,训了56天(2.788M GPU hours),算力开销是四千万人民币,很值的感觉。这就能烧一个 GPT4 水平的基础模型,大佬们应该都蠢蠢欲动了。
14.8T 训练:
完整训练仅需 2.788M H800 GPU 小时。
看报告有三十位数据标注员。这版覆盖更多语言,继续增加了数学 / 代码的比例,代码数据中的 10% 用中间补充(FIM)策略来组织(我理解这主要是为了给模型强化一个常用的推理功能)。为了压缩其它语言的内容,调整了分词器。
模型架构:
700B MoE 模型。
256 个总专家,其中 1/8 共享专家,8 top-k,推理激活了 37B 参数。
与 DeepSeek v2 的比较:236B MoE,16 个专家,1/8 共享,1 top-k 选择,推理激活了 21B 参数。
多头潜在注意力(MLA):
类似于 DeepSeek v2 MoE,前三层不是 MoE。
其他细节:
61 层,宽度 7168。
多令牌预测(MTP)作为目标。
16 PP(并行)/ 64 EP(专家并行)/ Zero-1 DP(数据并行)#优化了全对全通信内核,而不是昂贵的 TP(张量并行)。
在 CPU 上进行 EMA
超参数
初始的学习率和优化器配置,都是继承 deepseek v1 的结论,batchsize 也是按缩放定律从 v1 的 3072 到 15,360。
WSD 学习率调度器:0 → 2.2e-4(2k steps)→ 常数直到 10T → 2.2e-5(在 4.3T tokens 时余弦衰减)→ 2.2e-5(在剩余的 167B tokens 时常数)。
长文本能力
用 YaRN 方法 (arXiv:2309.00071)
上下文窗口扩展: 每 1000 steps,从 4k 逐步扩展到 32k,然后到 128k。
RLHF 部分
奖励构建:
基于规则的奖励机制。对于可以使用特定规则进行验证的问题,我们采用基于规则的奖励系统来确定反馈。例如,某些数学问题有确定的结果,我们要求模型在指定的格式内(例如,在方框中)提供最终答案,以便我们可以应用规则来验证正确性。类似地,对于 LeetCode 问题,我们可以利用编译器根据测试用例生成反馈。通过尽可能利用基于规则的验证,我们确保了更高的可靠性,因为这种方法不易受到操纵或利用。
对于具有自由形式真实答案的问题,我们依靠奖励模型来确定响应是否与预期的真实答案匹配。相反,对于没有明确真实答案的问题,例如涉及创意写作的问题,奖励模型的任务是根据问题和相应的答案作为输入提供反馈。奖励模型从 DeepSeek-V3 SFT 检查点进行训练。为了提高其可靠性,我们构建了偏好数据,这些数据不仅提供最终奖励,还包括导致奖励的思维链。这种方法有助于减轻在特定任务中奖励被操纵的风险。
看起来还是客观题用规则方法,主观题用奖励模型,而且是一种 COT 的奖励模型
训练了 2epoch,余弦学习率衰减
提到了 constitutional AI approach 和 self-rewarding,显然有模型打分造数据的部分了
评测
我圈出了一些比较有亮点的数字
我个人觉得如果一个榜 qwen-dense 也能做得不错,可能就不是做超大 MoE 模型应该关注的点了
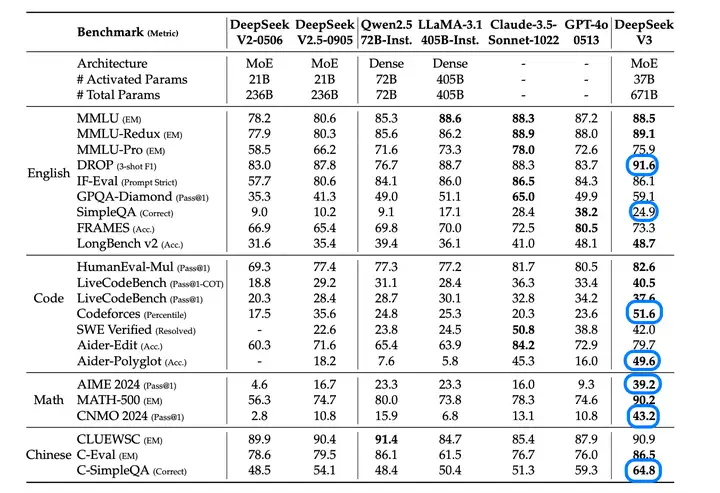
比较有亮点的是数学能力,Coding 看这个榜不好说提升是不是非常大,因为 Codeforces 漏题还是比较严重的,从论文字面上没看出来有没有排除相关影响
无所谓,训出来了,自有大儒会讲经的
论文讨论部分
蒸馏好像很重要,但是主要在这部分描述
从 DeepSeek-R1 蒸馏
我们通过基于 DeepSeek-V2.5 的实验来消融从 DeepSeek-R1 蒸馏的贡献。基线模型是在短链数据上训练的,而其竞争对手则使用了由专家检查点生成的数据。
表 9 展示了蒸馏数据的有效性,在 LiveCodeBench 和 MATH-500 基准测试中都取得了显著改进。我们的实验揭示了一个有趣的权衡:蒸馏会导致性能更好,但也会显著增加平均响应长度。为了在模型准确性和计算效率之间保持平衡,我们为 DeepSeek-V3 的蒸馏精心选择了最佳设置。
我们的研究表明,从推理模型中蒸馏知识是一个有前途的后训练优化方向。虽然我们目前的工作重点是蒸馏数学和编码领域的数据,但这种方法在各种任务领域都显示出潜力。这些特定领域的有效性表明,长链蒸馏可能对增强其他需要复杂推理的认知任务的模型性能有价值。对这种方法在其他领域的进一步探索仍然是未来研究的一个重要方向。
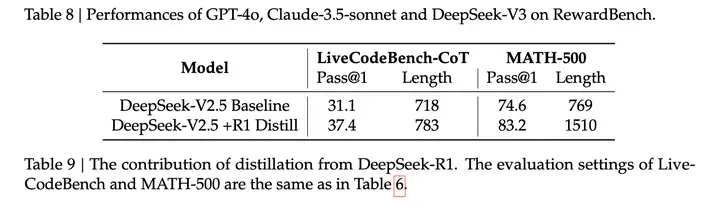
推理过程强化,然后筛选和蒸馏反哺,听起来很有搞头
自我奖励
奖励在 RL 中起着至关重要的作用,指导着优化过程。在可以通过外部工具进行验证的领域,如某些编码或数学场景中,RL 显示出了出色的效果。然而,在更一般的场景中,通过硬编码构建反馈机制是不切实际的。在 DeepSeek-V3 的开发过程中,对于这些更广泛的上下文,我们采用了Constitutional AI 方法(Bai et al., 2022),利用 DeepSeek-V3 本身的投票评估结果作为反馈源。这种方法产生了显著的对齐效果,显著提高了 DeepSeek-V3 在主观评估中的表现。
通过将补充信息与 LLM(大型语言模型)作为反馈源相结合,DeepSeek-V3 可以优化到 Constitutional 方向。我们认为这种范式将补充信息与 LLM 作为反馈源相结合,对于推动 LLM 的自我改进至关重要。除了自我奖励外,我们还致力于发现其他一般性和可扩展的奖励方法,以持续推动模型能力在一般场景中的发展。
Constitutional AI 方法简单来说就是,不是所有打标都要人搞,比如有害性标注就可以交给模型负责,然后我们可以在降低有害性,提高有用性两个维度上,做帕累托改进
多令牌预测评估
DeepSeek-V3 通过多令牌预测(MTP)技术预测了下一个 2 个令牌,而不是仅仅预测下一个单个令牌。结合推测性解码框架(Leviathan et al., 2023; Xia et al., 2023),这可以显著加速模型的解码速度。一个自然的问题是,额外预测的令牌的接受率是多少?基于我们的评估,第二个令牌预测的接受率在各种生成主题上都保持在 85% 到 90% 之间,展示了一致的可靠性。这个高接受率使 DeepSeek-V3 能够实现显著改进的解码速度,将 TPS(每秒令牌数)提高了 1.8 倍。
虽然解码速度提升是常数级的,但是对于用户体验非常重要的
① 2025中国国际新能源技术展会
自动驾驶之心联合主办中国国际新能源汽车技术、零部件及服务展会。展会将于2025年2月21日至24日在北京新国展二期举行,展览面积达到2万平方米,预计吸引来自世界各地的400多家参展商和2万名专业观众。作为新能源汽车领域的专业展,它将全面展示新能源汽车行业的最新成果和发展趋势,同期围绕个各关键板块举办论坛,欢迎报名参加。

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵


















 1030
1030

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









