







【大模型】 大模型 deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
DeepSeek-R1 模型介绍
第一代推理模型 DeepSeek-R1-Zero和DeepSeek-R1。
DeepSeek-R1-Zero是一个通过大规模强化学习(RL)训练的模型,它在推理任务上表现出色,且未经过监督微调(SFT)作为初步步骤。借助强化学习,DeepSeek-R1-Zero自然地展现出了许多强大且有趣的推理行为。然而,DeepSeek-R1-Zero也面临一些挑战,例如无休止的重复、可读性差以及语言混合等问题。为了应对这些问题并进一步提升推理性能,我们推出了DeepSeek-R1,该模型在进行强化学习之前引入了冷启动数据。DeepSeek-R1在数学、编程和推理任务上的表现与OpenAI-o1相当。为了支持研究社区,我们已经开源了DeepSeek-R1-Zero、DeepSeek-R1以及基于Llama和Qwen从DeepSeek-R1蒸馏出的六个密集模型。其中,DeepSeek-R1-Distill-Qwen-32B在多个基准测试中超越了OpenAI-o1-mini,为密集模型创造了新的最佳性能记录。
-
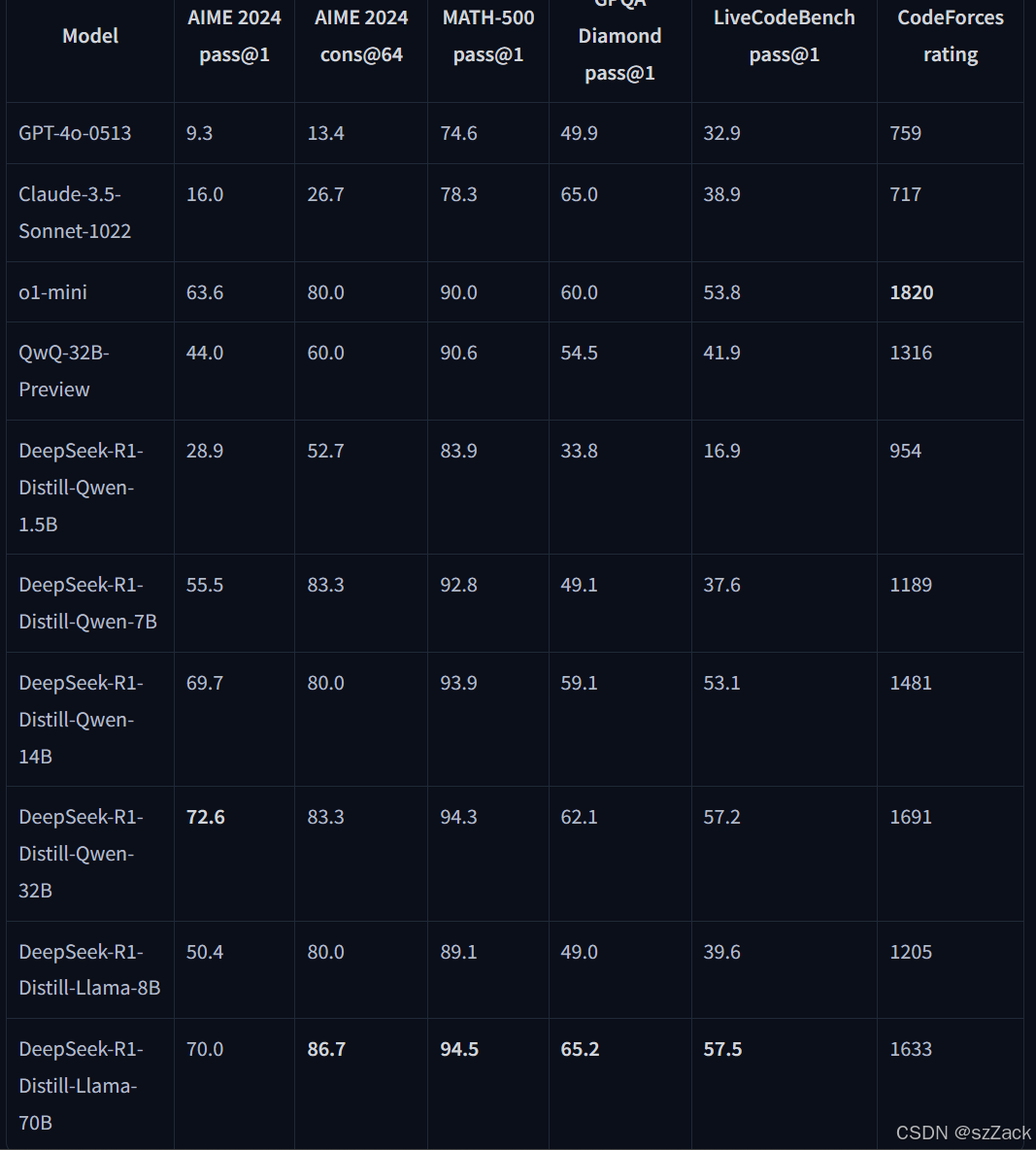
性能
Model Summary
后训练:在基础模型上进行大规模强化学习
- 我们直接在基础模型上应用强化学习(RL),而不依赖于监督微调(SFT)作为初步步骤。这种方法使模型能够探索用于解决复杂问题的思维链(CoT),从而开发出DeepSeek-R1-Zero。DeepSeek-R1-Zero展示了诸如自我验证、反思以及生成长思维链的能力,这标志着研究社区的一个重要里程碑。值得注意的是,它是首次公开研究验证,通过纯粹的强化学习(无需SFT)可以激励大型语言模型(LLM)的推理能力。这一突破为该领域的未来发展铺平了道路。
- 我们介绍了开发DeepSeek-R1的流程。该流程包含两个强化学习阶段,旨在发现更好的推理模式并使其与人类偏好对齐,以及两个监督微调阶段,作为模型推理和非推理能力的种子。我们相信,这一流程将通过创造更好的模型而惠及整个行业。
蒸馏:小模型也可以很强大
- 我们证明了较大模型的推理模式可以被蒸馏到较小模型中,与通过在小模型上进行强化学习发现的推理模式相比,表现更好。开源的DeepSeek-R1及其API将有助于研究社区在未来蒸馏出更好的小模型。
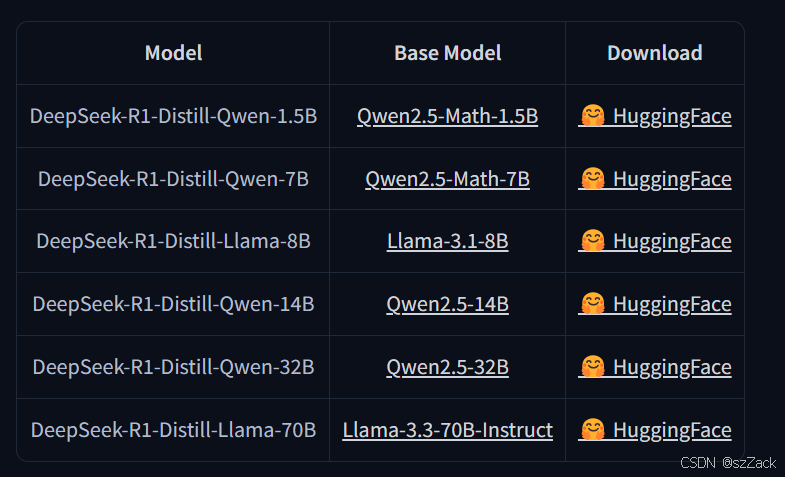
- 利用DeepSeek-R1生成的推理数据,我们对研究社区广泛使用的几种密集模型进行了微调。评估结果显示,这些经过蒸馏的小型密集模型在基准测试中表现卓越。我们基于Qwen2.5和Llama3系列,向社区开源了1.5B、7B、8B、14B、32B和70B的蒸馏模型checkpoints。
-
发布时间
2025年1月28日
下载
model_id: deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
下载地址:https://hf-mirror.com/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B 不需要翻墙
-
DeepSeek-R1-Distill Models
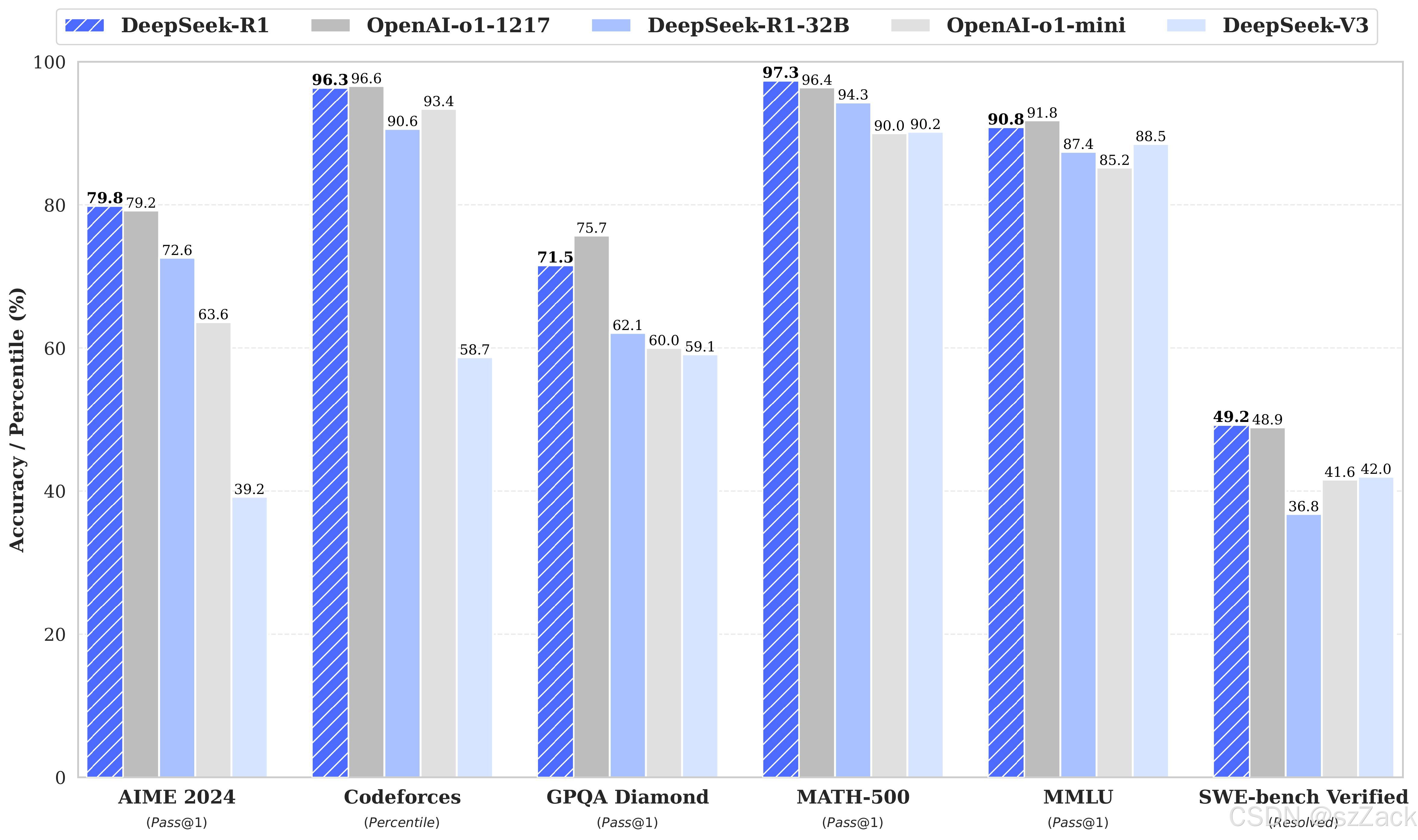
DeepSeek-R1-Evaluation
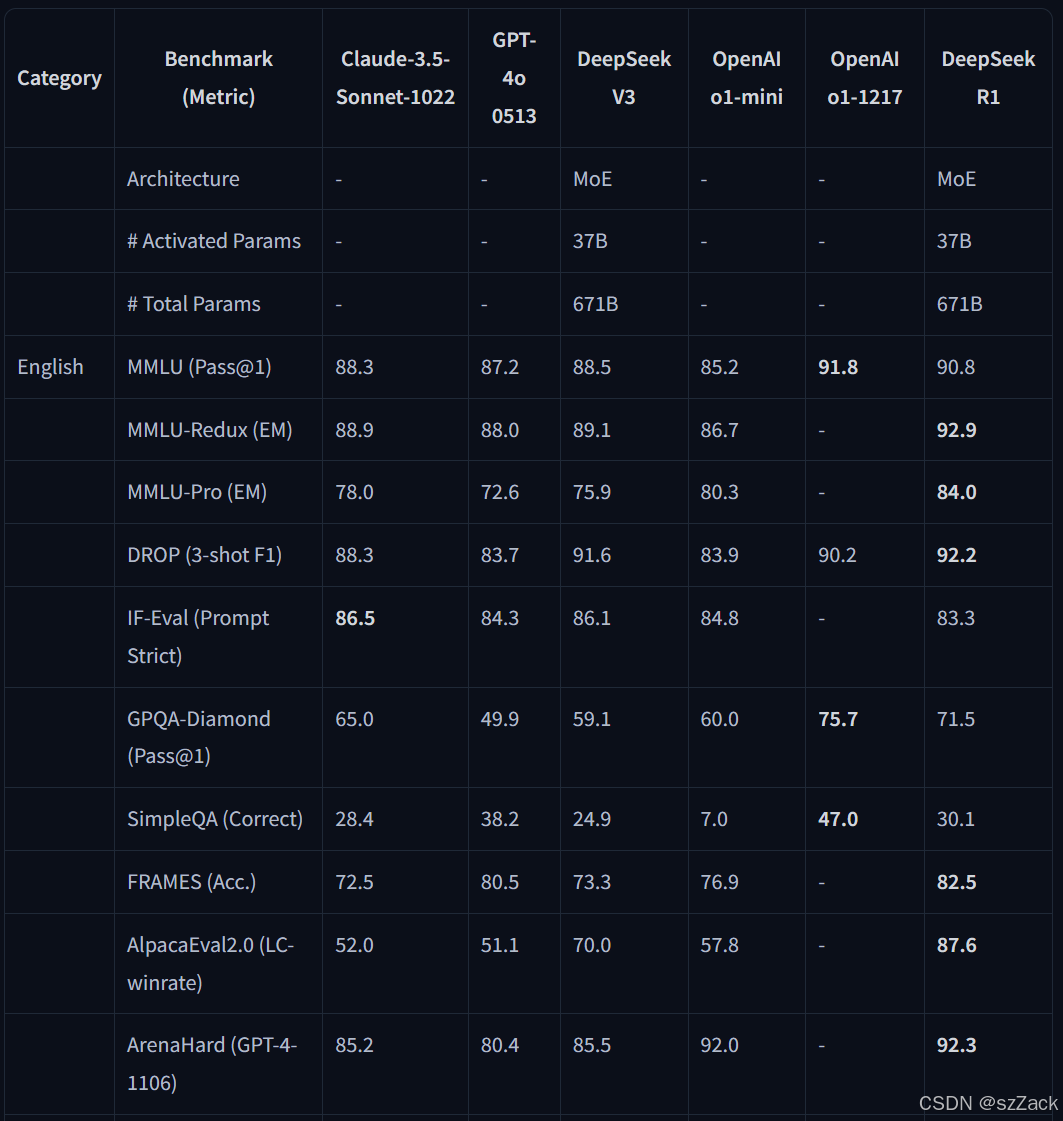
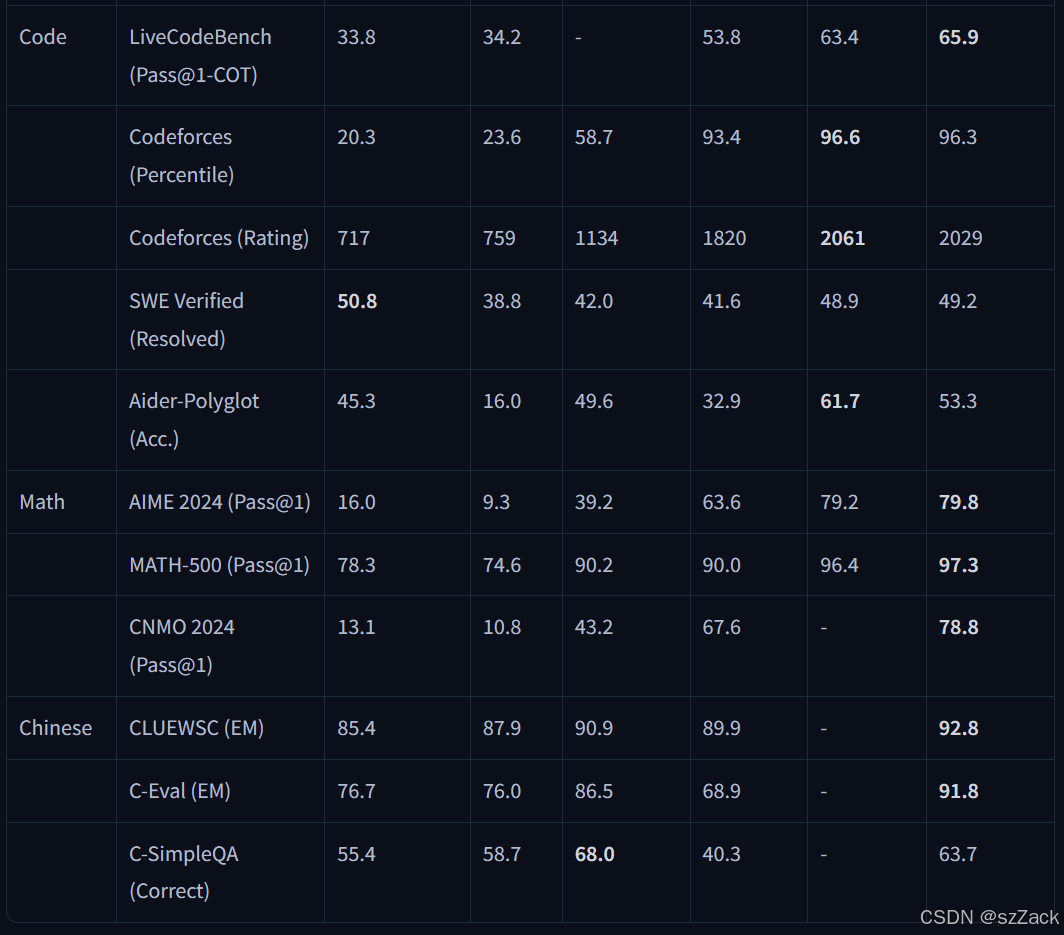
Distilled Model Evaluation
github
https://github.com/deepseek-ai/DeepSeek-R1
模型运行示例
-
vLLM
vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --tensor-parallel-size 2 --max-model-len 32768 --enforce-eager
-
SGLang
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --trust-remote-code --tp 2
开源协议
MIT License
DeepSeek-R1-Distill-Llama-8B is derived from Llama3.1-8B-Base and is originally licensed under llama3.1 license.
DeepSeek-R1-Distill-Llama-70B is derived from Llama3.3-70B-Instruct and is originally licensed under llama3.3 license.


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











