






作者 | 量子位 编辑 | 量子位
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
如果把DeepSeek-R1震撼硅谷的深度推理表现,运用到多模态场景,那会怎样?
此前DeepSeek自家的Janus-Pro-7B没有结合推理能力,但现在,国内有研究团队先做到了——
基于自研全模态框架Align-Anything,北大联合港科大团队推出多模态版DeepSeek-R1:
Align-DS-V,它在部分视觉理解表现评测集上超越GPT-4o。
当图文结合地询问它减肥时更适合喝哪一款饮品时,Align-DS-V精确地指出图中饮品的款数、饮品名称,以及减脂时最适合饮用的是“低糖原味豆奶”。
不仅如此,它还额外指出,图中的原味豆奶同样适合减脂期饮用。

更重要的是,在让DeepSeek-R1“长眼睛”的过程中,研究人员还发现了模态穿透对于模型文本模态推理能力的提升效果。
具体来说,团队在DeepSeek-R1的全模态化尝试中发现,多模态训练之后,模型不仅在文本模态任务上的表现有所提升,在科学任务、复杂推理、数学代码等方面的表现亦均有提升。
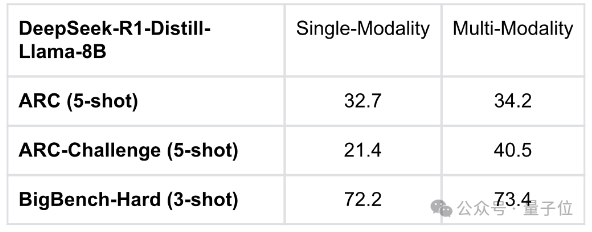
尤为显著的是,在ARC-Challenge(5-shot)上,成绩从单模态的21.4提升到了多模态的40.5。
基于此,团队认为当下多模态大模型已具备强大的跨模态穿透与融合的感知能力,能够通过结合世界知识与上下文学习能力,实现多种模态(如图像、文本、音频、视频等)的高效推理与协同输出。
通过深度融合世界知识,模型在文本模态下的推理边界得以拓展。
全模态对齐Align-Anything,涌现模态穿透能力
人类在日常生活中接收到的信息往往是全模态的,如何将“强推理慢思考”从单文本模态进一步推广到更多模态甚至是全模态场景,不可否认是大势所趋。
在此基础上,如何将全模态大模型与人类的意图相对齐,也是一个极具前瞻性且至关重要的挑战。
在单一文本模态场景下,许多复杂推理任务可以通过基于规则的奖励提供监督信号,作为人类意图和偏好的载体。
而当从文本模态扩展到多模态甚至全模态场景下时,许多问题会随之浮现:
随着模态数量增加,传统二元偏好或规则奖励是否能够捕捉人类意图的多元偏好或层次化偏好?
当多模态扩展到全模态空间,模态交互更加复杂,RL方法需要做哪些改进?
不同模态下,模态特有与模态共有的信息如何统一在奖励信号建模中?
……
输入输出空间的分布更加广泛,幻觉现象加剧,这都使得全模态对齐变得更加复杂。
为进一步促进多模态对齐研究,研究团队提出了Align-Anything框架,致力于使全模态大模型与人类意图和价值观对齐。
这里的全模态包括文生文、文生图、文图生文、文生视频等任意到任意的输入与输出模态。
总体而言,框架设计了具备高度的模块化、扩展性以及易用性的对齐训练框架,支持由文本、图片、视频、音频四大基本模态衍生出的任意模态模型对齐微调,并验证了框架对齐算法的实现正确性。
该框架具有以下特点:
高度模块化:对不同算法类型的抽象化和精心设计的API,用户能够为不同的任务修改和定制代码,以及定制化模型与数据集注册等高级扩展用法;
支持跨任意模态模型的微调:包含对如LLaMA3.2、LLaVA、Chameleon、Qwen2-VL、Qwen2-Audio、Diffusion等跨越多种模态生成与理解的大模型的微调能力;
支持不同的对齐方法:支持任意模态上的多种对齐算法,既包括SFT、DPO、PPO等经典算法,也包括ORPO, SimPO和KTO等新算法;
支持多种开、闭源对齐评估:支持了30多个多模态评测基准,包括如MMBench、VideoMME等多模态理解评测,以及如FID、HPSv2等多模态生成评测。
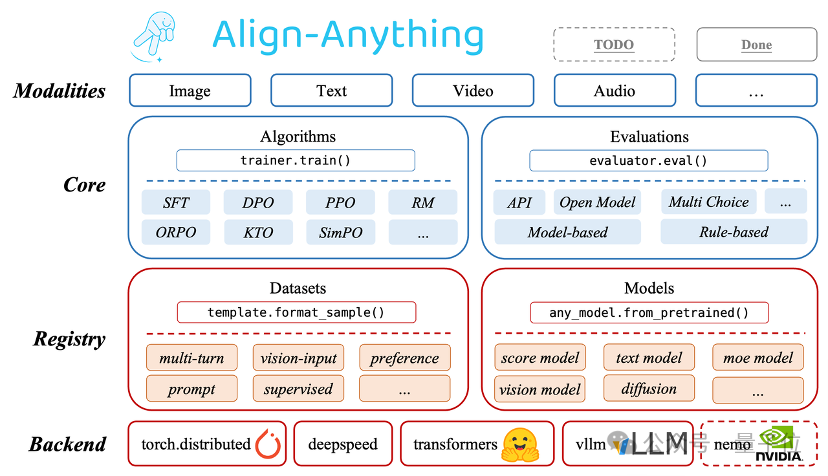
也就是说,Align-Anything团队从数据集、算法、评估以及代码库四个维度贡献了开源力量:
数据:200k包含人类语言反馈和二元偏好的数据集,包含图、文、视频、语音全模态。
算法:从语言反馈中学习的合成数据范式,大幅提升RLHF后训练方法的表现。
评估:面向全模态模型的模态联动与模态选择评估。
代码库:支持图、文、视频、语音全模态训练与评估的代码框架。
同时,为了促进对全模态对齐模型的进一步开发,研究团队发布首个全模态人类偏好数据集Align-Anything。
与专注于单个模态且质量参差不齐的现有偏好数据集不同,Align-Anything提供了高质量的数据,包括了输入和输出中的任何模态。
这旨在提供详细的人类偏好注释以及用于批评和改进的精细语言反馈,从而实现跨模态的全面评估和改进。

多模态场景加持的Deepseek-R1:Align-DS-V
接下来,团队开始攻坚多模态场景加持下的Deepseek-R1会有怎样的表现。
借鉴LLaVA的训练思路,通过训练投影层(Projector),Align-Anything团队将视觉编码器(Vision Encoder)输出映射到语言表征空间,从而扩展了DeepSeek-R1的视觉模态。
在Align-Anything库中,团队开源了训练的全部流程。
首先,基于Deepseek-R1系列模型,构建“文本 + 图片-> 文本”架构。例如以下脚本:

在新的多模态模型中,输入图像Xv经过视觉编码器提取特征,生成中间表示Zv,然后通过投影层进行映射,得到视觉表征Hv。
与此同时,语言指令Xq经过处理,生成语言表征Hq。
这些视觉和语言特征共同输入到语言模型,语言模型将两种信息结合进行推理,最终生成文本回复。
在构建好模态扩展的DeepSeek-R1架构后,具体的训练分成两个步骤:
第一步,冻结除投影层Projector外所有模型参数,对投影层Projector进行预训练,使得投影层Projector能够将经过视觉编码器的视觉表征映射到语言表征空间。

第二步,同时微调投影层Projector和大语言模型,激发语言模型多模态推理能力。

训练成功后,研究人员将多模态版本的DeepSeek-R1系列模型命名为Align-DS-V。
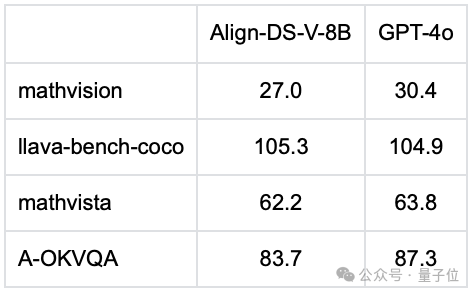
以下是Align-DS-V在不同视觉理解表现评测集上的表现(对比GPT-4o)。
可以看到,Align-DS-V在部分评测集(如llava-bench-coco)上的表现超过了GPT-4o。
除此之外,更重要的是团队还发现了模态穿透对于模型文本模态推理能力的提升效果。
具体来说,团队在DeepSeek-R1的全模态化尝试中发现,经过多模态训练之后,模型在文本模态任务上的表现有所提升,在科学任务、复杂推理、数学代码等方面的表现均有提升。
尤为显著的是,在ARC-Challenge(5-shot)上,成绩从单模态的21.4提升到了多模态的40.5。
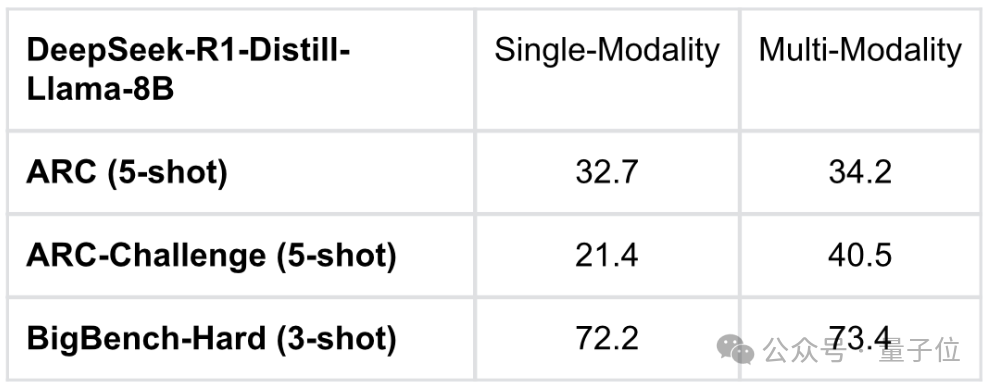
由此团队认为,基于“慢思考强推能力”的持续自我进化,模型能力已经突破了单一模态的局限性,跨模态穿透深度显著提升。
通过深度融合世界知识,模型在文本模态下的推理边界得以拓展。
为验证全模态推理大模型在垂域应用的能力,研发团队对Align-DS-V面向进行香港地区价值观的本地化对齐,令Align-DS-V适应粤语/英语/普通话混合语言输入。
这一过程深度整合港铁动态、台风预警及八达通缴费等香港本土生活场景。
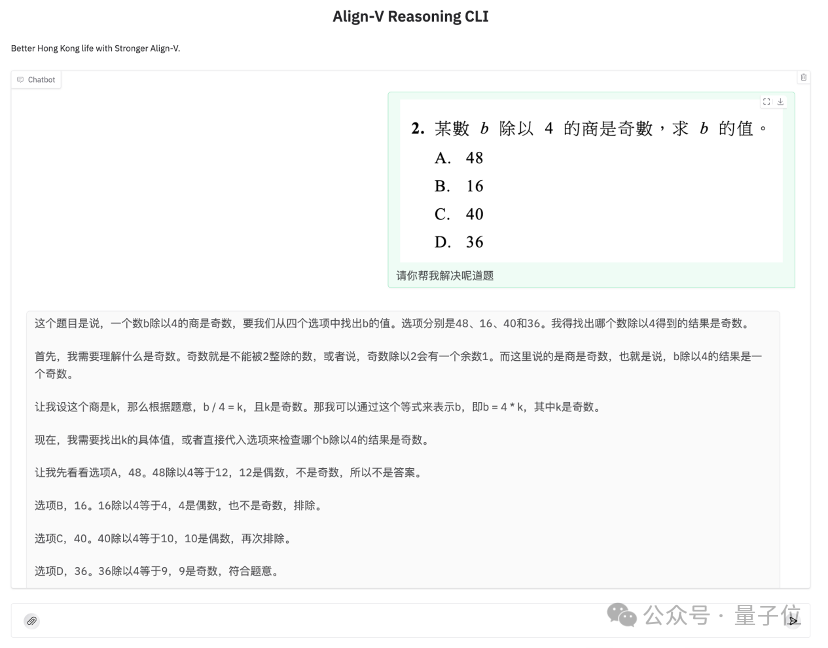
在面对包含繁体字的图文数学问题时,Align-DS-V能够准确联动图文模态信息。
如图所示,它逐步使用严密的数学推导展示求解过程,展示了被应用于教育等行业的可信前景。
北大&港科大联合开发、开源、维护
Align-Anything和Align-DS-V由北京大学联合香港科技大学开发。
目前,Align-Anything框架,以及DeepSeek-R1的多模态版本Align-DS-V,均已开源,团队将携手对其进行长期维护(文末附地址直通车)。
联合研究团队中的北京大学对齐团队,专注于人工智能系统的安全交互与价值对齐。
团队指导老师为北京大学人工智能研究院助理教授杨耀东。
联合研究团队中的香港生成式人工智能研发中心(HK Generative AI R&D Center,HKGAI)成立于2023年10月,致力于推动香港人工智能生态系统的发展。
由香港科技大学首席副校长,郭毅可院士领衔担任中心主任。

量子位了解到,在Align-DS-V的基础上,北大-灵初联合实验室已经着手在VLA(Vision Language Action Model,视觉语言动作模型)领域方面做更深度的探索。
灵初正在研发的VLA模型,在大脑端利用多模态大模型进行对齐和微调,并向小脑端的控制器输出action token;而后,小脑端的控制器再根据输入的token和其他模态的信息,输出具体的机器人控制指令。
这两个过程都需要运用针对多模态大模型的后训练(post-training)和微调(fine-tuning)技术。
北大-灵初联合实验室表示,Align-DS-V的多模态强推理能力是VLA模型大脑端的核心,接下来的研究训练计划,是利用多模态推理模型的跨模态穿透能力,实现action穿透,最终实现真正高效的VLA模型。
同样的后训练技术也可以应用于小脑端控制器的微调,实现更高的成功率、泛化性和鲁棒性。
Align-Anything框架开源地址:
https://github.com/PKU-Alignment/align-anything
Align-DS-V开源地址:
https://huggingface.co/PKU-Alignment/Align-DS-V
— 完 —
① 自动驾驶论文辅导来啦

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵


















 1196
1196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









