






作者 | Loki 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/1887083966760195478
点击下方卡片,关注“自动驾驶之心”公众号
>>点击进入→自动驾驶之心『自动驾驶』技术交流群
本文只做学术分享,如有侵权,联系删文
随着Tesla全面转向端到端技术路线并终止AI Day开放分享,全球自动驾驶行业陷入技术演进路径的真空期。在此背景下,理想汽车自2023年起通过「理想科技日」逐步确立国内技术标杆地位——其首创的行业级技术布道平台,成功构建起中国智能驾驶发展的新型知识枢纽。
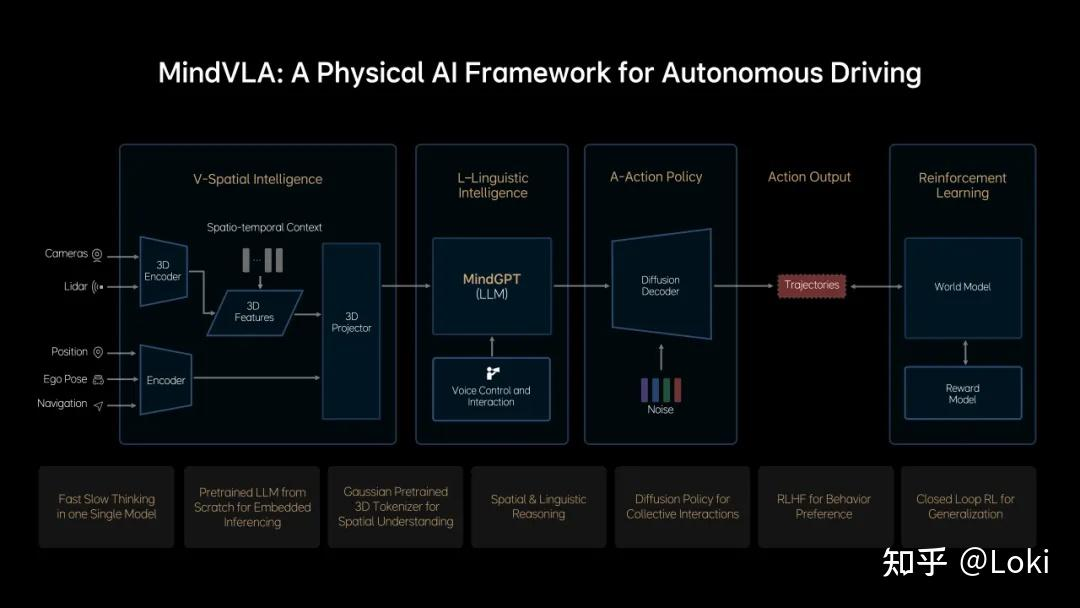
2024年,理想汽车基于卡尼曼「快思考-慢思考」认知模型,率先提出端到端大模型与视觉语言模型(VLM)的双系统协同架构,为行业提供了首个可落地的类人驾驶技术框架。今年更迭代推出革命性Vision-Language-Action(VLA)模型MindVLA,开创智能体认知新范式。该架构依托三大核心能力重塑自动驾驶边界:
空间智能:通过多模态融合实现厘米级3D场景解构
因果推理:构建驾驶决策的符号逻辑演绎链条
行为涌现:基于环境反馈的自适应策略生成机制
「理想汽车发布下一代自动驾驶架构MindVLA」,2025年3月18日,理想汽车自动驾驶技术研发负责人贾鹏在NVIDIA GTC 2025发表主题演讲《VLA:迈向自动驾驶物理智能体的关键一步》,分享了理想汽车对于下一代自动驾驶技术MindVLA的最新思考和进展。
理想汽车高调推出的MindVLA模型,究竟是革命性突破还是技术迁移实验?答案或许介于两者之间。需明确的是,视觉-语言-动作模型(Vision-Language-Action, VLA)并非自动驾驶原生技术,其本质是机器人领域技术范式的跨界延伸。让我们穿透营销迷雾,回归技术演进本质:
技术基础铺垫
VLM(视觉语言模型)的兴起:2015-2022年间,视觉问答系统(VQA)、CLIP、ViT等技术的发展,奠定了多模态融合的基础,使机器能同时理解图像与语言。
机器人控制技术的积累:强化学习(如DQN、PPO)和轨迹编码技术的成熟,为动作生成提供了方法论支持。
早期尝试
RT-1的突破:2023年3月,谷歌DeepMind推出RT-1(Robotic Transformer 1),首次将预训练的视觉语言模型应用于机器人动作生成,但泛化能力有限。
RT-2的里程碑意义
2023年7月:谷歌DeepMind发布RT-2(Robotic Transformer 2),首次明确VLA范式。该模型通过互联网规模的视觉-语言数据训练,支持自然语言指令直接生成动作序列,显著提升泛化能力(如处理未见过的物体和场景)。
核心技术突破:引入“思维链”机制,结合语言模型的推理能力与机器人轨迹数据,实现长期规划与低级技能融合。
开源与扩展
OpenVLA开源项目:2024年6月,斯坦福、伯克利等机构联合推出OpenVLA,基于7B参数的Llama 2和SigLIP视觉编码器,推动VLA技术标准化与普及。
3D-VLA的演进:2024年,麻省理工与伯克利团队提出3D-VLA,引入三维空间表征技术,增强复杂场景的几何感知能力,解决二维模型的局限性。
工业与家庭场景落地
Figure公司的Helix模型:2025年2月,Figure发布支持多机器人协作的VLA模型Helix,采用“系统1(高频控制)+系统2(语义决策)”双架构,实现低功耗、高泛化的家庭服务机器人。
特斯拉人形机器人Optimus:结合VLA技术优化动作生成,提升对动态环境的适应性,推动具身智能商业化7。
技术细分与分层架构
分层端到端VLA:2024年后,研究重点转向结合大模型泛化能力与小模型执行效率的混合架构,如TinyVLA通过模型压缩降低算力需求。
多模态数据集推动:谷歌开放X-Embodiment数据集(含160万条多机器人任务数据),加速VLA模型的训练与迭代。
随着VLA神秘面纱的揭开,那么我们迎来了自动驾驶的终极之问:VLA真的是打开大门的万能钥匙吗?
在自动驾驶的竞技场上,全球头部玩家正以截然不同的技术哲学展开角力:
Tesla:BEV→Occ→E2E的颠覆之路
BEV革命:通过鸟瞰图视角统一多传感器数据,打破传统前视图感知的局限
Occ跨越:占据网络(Occupancy Network)实现对未知障碍物的三维空间建模,解决长尾场景覆盖难题
端到端终局:从感知到控制的直接映射,2024年FSD V12已实现纯神经网络驱动
小鹏:中国版Tesla的技术复刻
跟随战略:XNGP系统高度对标Tesla技术架构,BEV+Transformer成为标配
本土化改良:针对中国复杂路况优化博弈算法,但核心框架仍受制于技术路径依赖
华为:稳中求胜的渐进主义
车云协同架构:ADS 2.0采用云端大模型与车端小模型协同,确保安全冗余
高精地图依赖:在无图化浪潮中保持谨慎,通过多模态融合弥补感知短板
理想:VLA范式的激进突围
认知科学赋能:基于卡尼曼双系统理论构建MindVLA模型,分离直觉式反应(快思考)与深度推理(慢思考)
三维空间智能:通过VLA架构实现环境理解、逻辑推演与动作生成的端到端闭环
当前自动驾驶行业正陷入两大核心矛盾:
Tesla的技术霸权与跟随者困境
算力鸿沟:Dojo超算集群提供1.1EFLOPS算力,远超国内车企(理想自建算力仅120PFLOPS)
数据飞轮碾压:Tesla 800万辆量产车日均采集数据量超国内玩家年度总和
伪端到端乱象:部分企业将传统模块化系统包装为“分段式端到端”,实为营销概念游戏
VLA的技术泡沫质疑
推理延迟瓶颈:当前VLA模型(如MindVLA)在Jetson AGX Orin平台需300ms响应时间,难以满足紧急制动需求
虚实鸿沟难题:仿真环境训练出的逻辑推理能力,在真实交通场景中出现高达37%的决策偏差
成本悖论:搭载VLA系统的域控制器成本增加4000元,与车企降本诉求直接冲突
要判断VLA的技术价值,需回归三个根本问题:
认知架构突破vs工程优化
VLA带来的“类人思考”是否真能解决Corner Case,还是仅将问题从代码层转移至模型黑箱?
技术路径的不可逆性
当Tesla用纯视觉端到端实现城市NOA 99.9%场景覆盖时,多模态架构是否仍有存在必要?
商业落地的时间窗口
在2025年L3法规落地前,VLA能否完成从实验室到量产的致命一跃?
破局之路:实现真·自动驾驶的四大支柱
认知架构的重构
双系统协同:借鉴人脑决策机制,构建快响应(System 1)与慢思考(System 2)的混合架构
案例:理想MindVLA通过视觉语言大模型处理常规场景,符号逻辑引擎应对交通规则冲突
数据-算力-算法的三角进化
数据民主化:建立跨企业数据联盟,破解Tesla的数据垄断(如中国汽车数据共享联盟)
算力平民化:基于国产芯片(如地平线征程6)开发量化版VLA模型,推理效率提升5倍
仿真-实车的闭环验证
4D仿真革命:通过时空一致性建模,将VLA训练效率提升80%(理想DrivingSphere实测数据)
影子模式升级:在量产车部署决策对比系统,持续优化VLA在真实场景中的泛化能力
成本-性能的平衡艺术
模块化部署:将VLA拆分为云端预判与车端执行,降低硬件依赖
功能分级激活:基础版提供车道保持,高阶版通过OTA解锁城市NOA,实现技术价值分层变现
终局判断:没有银弹,唯有进化
VLA不是自动驾驶的终极答案,而是认知革命的关键台阶:
短期(2024-2026):VLA将主要解决特定场景的推理瓶颈(如施工区绕行决策)
中期(2027-2030):与神经符号AI融合,形成可解释、可审计的混合架构
长期(2030+):融入具身智能体系,成为智慧城市交通网络的细胞单元
当技术狂热退潮,唯有那些在架构创新、工程实现、商业落地间找到平衡点的玩家,才能最终摘下自动驾驶圣杯上的明珠。
自动驾驶之心
论文辅导来啦

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 255
255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









