




文章目录
一、背景
目前,随着移动设备的越发普及,模型训练的数据日益增大,而这些 数据通常是以孤岛形式存在。传统模型训练中,通过将不同设备的 数据统一上传中心服务器 进行模型训练,但是,用户的数据通常是隐私敏感的,将数据统一上传会有 隐私泄露 等风险。
针对传统模型训练的隐私泄露问题提出了 联邦学习 。将原本的数据统一上传中心服务器变为 在多个设备的数据集上构建深度学习模型进行模型训练 。用户不再需要将数据上传至中心服务器,保证了数据的隐私性 。在联邦学习中,
- 首先,中心服务器将初始模型分发到各个客户端,客户端接受分发到的初始模型在其本地数据集上进行模型训练,并将训练好后得到的模型权重上传至中心服务器;
- 接着,中心服务器通过加权平均对接受到的模型权重进行聚合,更新全局模型;
- 随后,再将新的全局模型继续下发反复训练,直至模型收敛。
然而,联邦学习虽然解决了数据以孤岛形式存在的模型训练隐私问题,但由于各个客户端的计算能力、存储能力、通信能力等不同,更新落后的局部模型会拖慢整个模型的训练过程。除此之外,不同客户端之间的数据往往是不同且non-IID分布的,这就会 导致模型训练过程非常缓慢甚至滞停 。
如此,便有了 去中心化联邦学习 的概念。
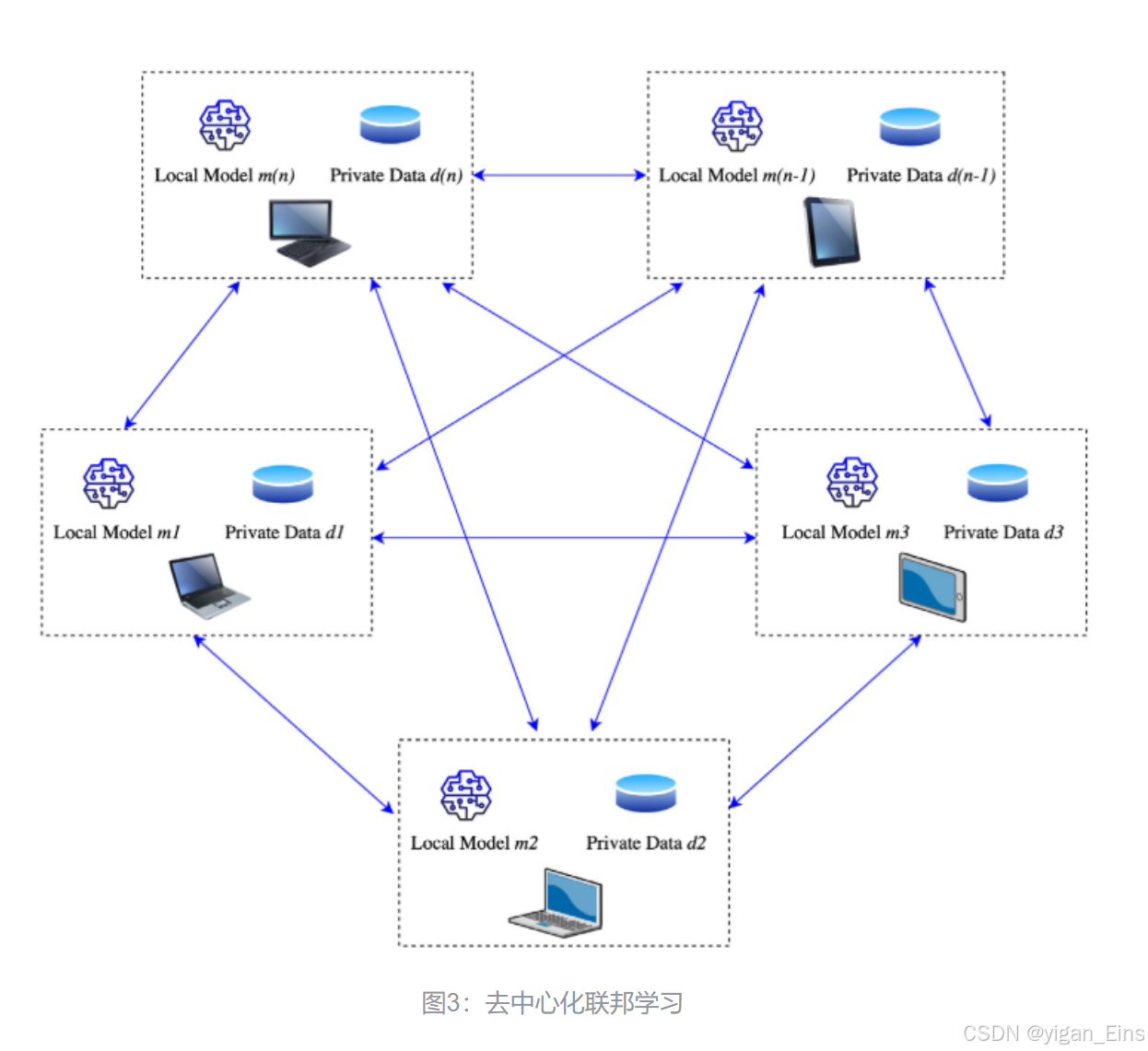
二、介绍
去中心化联邦学习 不需要中心服务器来协调各客户端之间的通信,而是各客户端之间自行通信,因此 极大地减少了通信开销和单点故障风险,对客户端之间的异构性有了有效的处理 。在去中心化联邦学习中,
- 首先,各客户端在其本地数据集上进行模型训练,并将训练好的模型权重发送给周围的邻居客户端;
- 接着,各客户端接受其邻居客户端上传的模型权重对其本地模型进行更新,得到新的本地模型;
- 随后,各客户端开启新一轮的模型训练,反复执行多次,直至模型收敛。
与集中式联邦学习相比,去中心化联邦学习不仅减少了系统异构性和统计异构性的影响,而且 更加注重保护用户数据隐私,同时也更具扩展性和健壮性 。

三、CoCo算法
CoCo算法 由Wang等人于2018年在《Accelerating Decentralized Federated Learning in Heterogeneous Edge Computing》中首次提出。接下来,对该论文进行精度。
摘要:
背景:边缘计算中,联邦学习使得大量设备能够在不暴露本地数据的情况下协作训练人工智能模型。在去中心化联邦学习中,采用点对点通信,而不维护全局模型。然而,由于边缘计算的内在特征,例如资源限制和异构性、网络动态和非独立同分布数据,在固定的点对点拓扑结构和相同的模型压缩比使得各工作节点的训练效率下降,导致收敛速度变慢。
解决:本文提出了一种高效的算法CoCo,通过整合拓扑构建和模型压缩的优化来加速DFL。可以将模型训练速度提高10%,平均减少50%的通信流量。
1、介绍
深度学习模型的强大能力依赖海量数据和密集计算,传统模型训练将这些数据从设备传输到数据中心统一训练,这将消耗大量带宽资源,并可能导致隐私泄露。So,引入了联邦学习(FL),将深度学习模型分配到靠近数据源的边缘节点或终端设备上,进行分布式模型训练。它即防止了个人隐私泄露,又充分利用了网络边缘的大量计算资源。
分布式模型训练:在训练过程中,PS(参数服务器)首先将全局模型的副本发送给worker(设备或边缘节点),然后worker在本地数据集上训练接收到的模型。等待所有worker训练完后,PS将所有更新的局部模型进行聚合,得到全新的全局模型,进行下一轮训练。
然而,当越来越多的worker参与模型训练,worker与PS之间的通信资源需求将显著增加,从而导致网络拥塞和收敛速度下降。So,引入了去中心化联邦学习(DFL),它协调worker建立点对点(P2P)通信网络。在P2P设置下,每个worker负责在自己的数据集上训练一个本地模型,并从邻居那里聚合模型。此外,可以通过限制worker的邻居数量来限制worker的带宽需求,使系统易于扩展。在P2P设置中,worker上的网络流量取决于其邻居数量,而与整个系统的规模无关。因此,分散式架构可以缓解模型聚合对带宽的需求,加快训练过程,避免集中式参数服务器可能出现的瓶颈。
虽然,DFL有一些明显的优势,但边缘计算的一些固有特征使得它对于高效模型训练来说非常重要。目前,主要有三个挑战:
-
1)有限和异构的通信带宽
-
2)动态网络状况
-
3)worker之间的non-IID数据
为解决上述挑战,涌现了许多不同的解决方案。通常,减少模型训练的通信流量采用模型/梯度压缩。例如,Koloskova等人在一些经典拓扑(如环)上研究并实现了压缩技术,并证明了模型压缩在分散学习中加速模型收敛的有效性。然而,在模型训练过程中,指定的压缩比对所有工人都是相同和固定的。对于worker上的异构带宽,具有相同压缩比的交换模型对链路的影响有明显差异,导致worker之间传输时间滞后较大。此外,在动态网络条件下,固定拓扑不一定总是有效的。为此,一些相关工作提出了基于worker的时变链路速度来构建P2P网络拓扑。例如,Zhou等提出选择高速链路和高带宽worker构成网络拓扑,进行分散学习。Tang等研究了拓扑构建与模型压缩相结合的方法,显著降低了通信流量,提高了系统对网络动态的鲁棒性。类似,他们中的压缩比对于所有worker在训练过程中也是相同且固定的,导致异构系统无效。此外,在构建网络拓扑时,这些算法没有考虑到work身上的non-IID数据,因此在non-IID数据上无法达到较高的收敛速度。
在本文中,提出了一种高效算法CoCo,集成了拓扑构造和模型压缩来加速边缘计算中的DFL。具体而言,共同构建了P2P网络拓扑结构,并为worker确定了不同的压缩比,以解决网络动态以及有限和异构通信带宽的挑战。为了反映non-IID数据对局部模型一致性的影响,引入了共识距离,它表征了每个局部模型与所有局部模型的平均值之间的差异,作为指导网络拓扑和压缩比联合优化的定量度量。
2、DFL
2.1、Network System
一个DFL系统通过维护一组worker在本地数据集上训练深度学习模型。每个worker只需要与邻居交换模型,而不需要共享自己的原始数据,可以采用安全聚合、差分隐私等技术来更好地保护传输模型或梯度地隐私。本文中以同步方式执行DFL,并将异步方式作为未来地方向。
P2P网络拓扑建模为连通无向图, E ( k ) E^{(k)} E(k) 表示在第 k k k 轮连接worker的链路集。具体来说,在第 k k k 轮,我们使用邻接矩阵 A ( k ) = { a i , j ( k ) ∈ ( 0 , 1 ) , 1 ≤ i , j ≤ m } A^{(k)} = \left\{ a_{i,j}^{(k)} \in (0,1),1 \leq i,j \leq m \right\} A(k)={ai,j(k)∈(0,1),1≤i,j≤m}来表示P2P中的网络拓扑结构,第 i i i 个worker的邻居集表示为 N i ( k ) N^{(k)}_{i} Ni(k),入站带宽和出战带宽分别表示为 b i ( k , i n ) b_{i}^{(k,in)} bi(k,in) 和 b i ( k , o u t ) b_{i}^{(k,out)} bi(k,out)。
链路 e i , j ( k ) e_{i,j}^{(k)} ei,j(k) 的带宽 为: b i , j ( k ) = m i n { b i ( k , o u t ) ∣ N i ( k ) ∣ , b j ( k , i n ) ∣ N j ( k ) ∣ } b_{i,j}^{(k)} = min\left\{ \frac{b_{i}^{(k,out)}}{\lvert N_{i}^{(k)} \rvert}, \frac{b_{j}^{(k,in)}}{\lvert N_{j}^{(k)} \rvert}\right\} bi,j(k)=min{∣Ni(k)∣bi(k,out),∣Nj(k)∣bj(k,in)}。
2.2、Model Compression
模型压缩技术的目的是减少每次训练时传输的数据量。在分布式训练中,一种流行的压缩技术是稀疏化,例如RandomK和TopK,他选择一部分模型参数,得到一个稀疏变量。RandomK和TopK的区别在于如何选择要传输的模型参数,其中RandomK随机选择参数,而TopK只选择绝对值较大的参数。随着所选参数数量的增加,模型的训练精度会越来越高,但会导致更多的流量消耗。在本文中,采用了RandomK。
2.3、Consensus Distance
由于DFL中没有全局模型,因此每个worker托管的本地模型并不总是相同的,本文中引入共识距离来衡量一个局部模型偏离所有局部模型的平均值的距离。
第 i i i 个worker在第 k k k 轮的共识距离定义为: D i ( k ) = ∣ ∣ x ˉ i ( k ) − x i ( k ) ∣ ∣ D_{i}^{(k)} = \lvert\lvert \bar{x}_{i}^{(k)} - x_{i}^{(k)} \rvert\rvert Di(k)=∣∣xˉi(k)−xi(k)∣∣,
其中 x ˉ i ( k ) = 1 m ∑ j = 1 m x j ( k ) \bar{x}_{i}^{(k)} = \frac{1}{m} \sum_{j=1}^{m} x_{j}^{(k)} xˉi(k)=m1∑j=1mxj(k),表示第 k k k 轮所有worker模型的平均值。然而,实际的 x ˉ i ( k ) \bar{x}_{i}^{(k)} xˉi(k) 在实践中是不可用的,为此,应该使用第 i i i个worker模型和其他worker模型之间的共识距离。所有worker模型的平均共识距离为: D ( k ) = 1 m ∑ i = 1 m D i ( k ) D^{(k)} = \frac{1}{m} \sum_{i=1}^{m} D_{i}^{(k)} D(k)=m1∑i=1mDi(k)。
为验证共识距离与数据分布相关,本文在两种拓扑上训练模型,随机环 和 共识感知环。
随机环:worker随机排列形成一个环形拓扑。
共识感知环:(1)连接两个具有最大共识距离的worker作为第一条链;
(2)找到与链两端公式距离最大的下一个worker,连接形成新的链;
(3)重复(2),直到所有worker都在链中;
(4)连接链的两个端点,形成共识环。
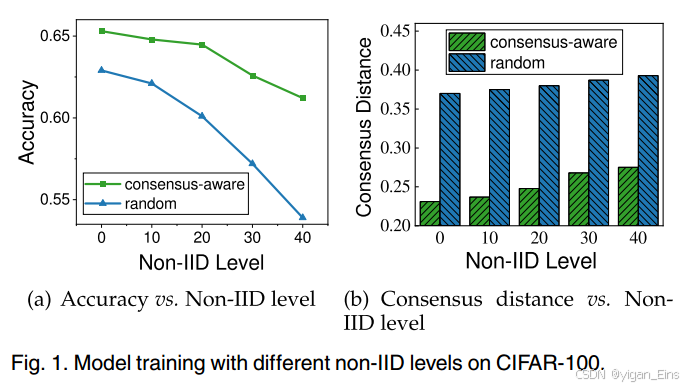
结果表明:共识感知环拓扑可以实现更小的共识距离和更高的测试精度。
为了监测网络的动态并协调worker的训练和沟通,我们需要一个协调器。Algorithm1描述了每个worker的算法,Algorithm2描述了协调器的算法。其中,协调器根据接收到的状态信息,调整通信拓扑,确定每个worker的局部模型压缩比。

在第 k k k 轮开始时,我们将worker i i i 的模型表示为 x i ( k ) x_{i}^{(k)} xi(k),通过设置 x i ( k , 0 ) = x i ( k ) x_{i}^{(k,0)} = x_{i}^{(k)} xi(k,0)=xi(k),梯度下降更新其局部模型。
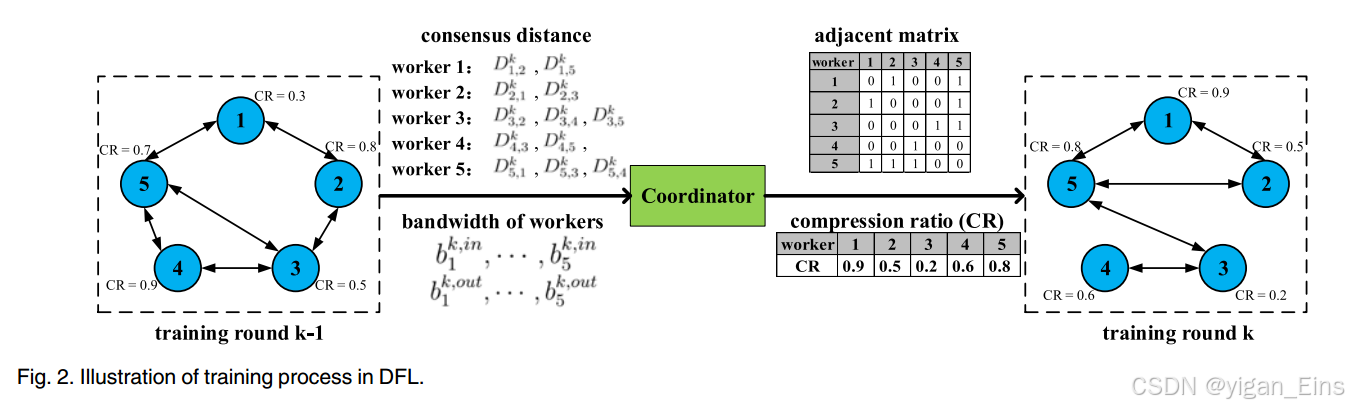
上图利用一个示例来说明训练过程,在 k − 1 k-1 k−1 轮,协调器收集worker的状态,并构建一个新的拓扑,在第 k k k 轮更改所有worker的模型压缩比。基于最新的拓扑和压缩比,worker继续按照Algorithm1进行模型训练。由于每个worker的状态信息仅由几个字节表示,因此与具有数千万或数亿字节的模型相比,其传输成本可以忽略不计。
将传统FL中的现有方法应用于DFL以处理worker的失败:
- worker可以主动报告他们的不良状态或可能的故障
- worker通过一些网络消息来探测邻居的状态,并将这些信息报告给协调器
- 协调器可以为worker设置模型训练和转移的截止日期,忽略在截止日期前未报告最新状态的worker
3、算法描述

将worker的网络状态、所有worker对的共识距离、共识距离阈值和基本网络拓扑作为算法的输入。从基本拓扑 A b A_{b} Ab 开始,其中包括用于P2P通信的所有可用链路,并使用LP求解器最优地求解Eq.(27),以获得初始化 t ( k ) t^{(k)} t(k) 和相应的模型压缩比 r ( k ) r^{(k)} r(k) 。基于这些结果,我们通过公式计算每个P2P链路的时间。将搜索步骤s设置为当前拓扑中链路数的平方根,在第 k k k 轮中,我们删除5个最慢的链路,然后调整压缩比,以最大限度地减少共识距离和worker带宽的约束。如果找到更好的解决方案(即更短的查询时间),则更新当前的网络拓扑和压缩比。如果不能,则将搜索步骤减少一半。如果移除任何链路都不能进一步减少循环时间 t ( k ) t^{(k)} t(k),则停止搜索并获得最终的网络拓扑以及所有worker的压缩比。为了满足Eq.(19b)的约束,我们只删除不影响网络拓扑连通性的链路。
自适应的确定平均共识距离的阈值: D m a x ( k ) = ( 1 − β 2 ) D m a x ( k − 1 ) + β 2 m ∑ i ∈ M ∣ ∣ g i ( k ) ∣ ∣ 2 D_{max}^{(k)} = (1 - \beta_{2})D_{max}^{(k-1)} + \frac{\beta_{2}}{m}\sum_{i \in M}||g_{i}^{(k)}||_{2} Dmax(k)=(1−β2)Dmax(k−1)+mβ2∑i∈M∣∣gi(k)∣∣2 。
其中, 1 m ∑ i ∈ M ∣ ∣ g i ( k ) ∣ ∣ 2 \frac{1}{m}\sum_{i \in M}||g_{i}^{(k)}||_{2} m1∑i∈M∣∣gi(k)∣∣2 表示所有worker在第 k k k 轮局部更新的梯度范数, β 2 ∈ [ 0 , 1 ] \beta_{2} \in [0,1] β2∈[0,1] 。
4、实验与评估
4.1 Simulation Platform
深度学习平台:AMAX
模拟边缘计算系统,20个worker用于分散的联邦学习,一个协调器用于记录训练性能和调整P2P网络拓扑以及worker的模型压缩比。每个worker上模型训练的实现基于Pytorch框架,并使用python的socket库来建立worker之间的通信。
4.2 Experimental Settings
- 数据集:CIFAR10 和 CIFAR100。
- 模型:CIFAR10上使用VGG9,学习率初始化为0.05,以0.98的速率衰减。CIFAR100上使用ResNet9,学习率初始化为0.1,以0.99的速率衰减。对于VGG9和ResNet9,本地更新次数和批量数据大小分别设置为50和32。并采用SGD优化器对模型进行优化,动量设置为0.9。另外,VGG9训练200个epoch,ResNet训练300个epoch,可以保证模型的收敛性。
- 基线:将CoCo和DCD、Choco、SASP三种算法进行比较。
- 通信与计算配置:为了在模拟中反映P2P网络的异质性和动态性,让每个worker的入站带宽在1Mb/s和20Mb/s之间波动,出战带宽在0.5Mb/s和10Mb/s之间波动。
- 性能指标:(1)测试精度 (2)训练时间 (3)通信消耗
- 训练时间计算: ∑ k = 1 k ′ t ( k ) \sum_{k=1}^{k'}t^{(k)} ∑k=1k′t(k) , k ′ k' k′ 为达到目标精度的最小回合数
- 通信消耗计算: ∑ k = 1 k ′ ∑ i ∈ M B ⋅ r i ( k ) ⋅ ∣ N i ( k ) ∣ \sum_{k=1}^{k'} \sum_{i \in M} B \cdot r_{i}^{(k)} \cdot |N_{i}^{(k)}| ∑k=1k′∑i∈MB⋅ri(k)⋅∣Ni(k)∣ 。
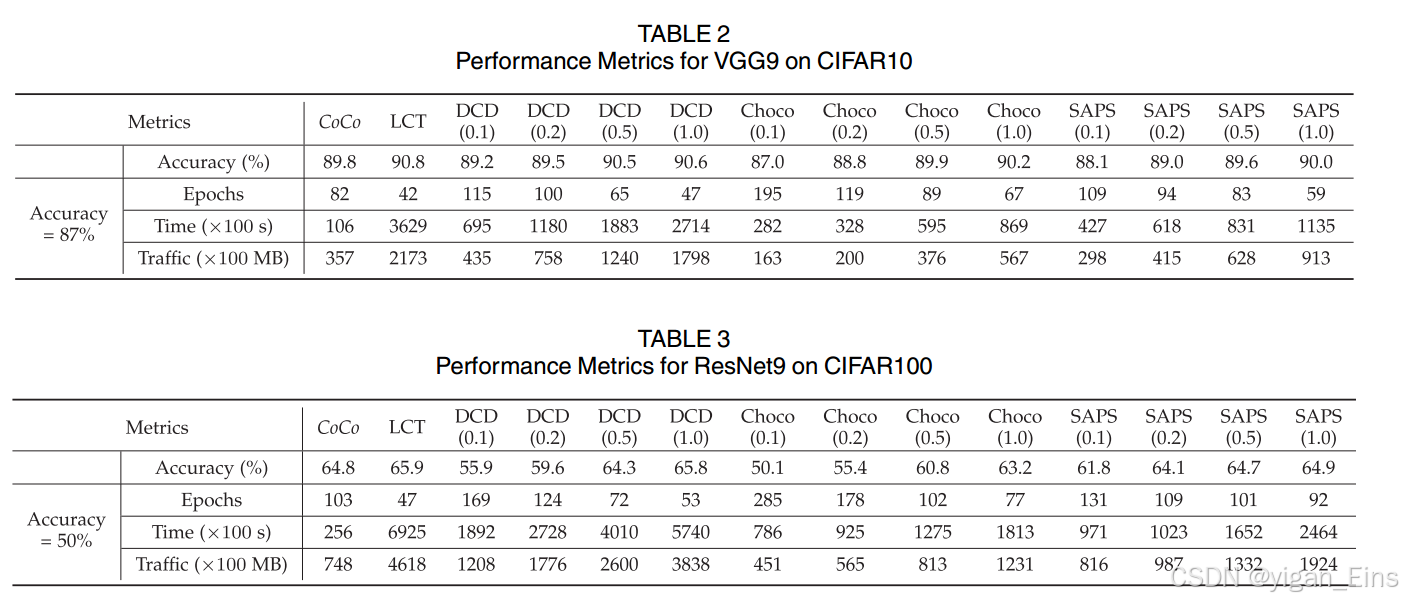
4.3 Overall Performance
实验结果表明:CoCo算法不仅加速了训练,而且减少了通信消耗。
4.4 Impact of Topology and Compression Ratio
结果表明:仅优化网络拓扑或模型压缩比无法获得与CoCo相当的训练性能,而CoCo对所有的worker共同优化网络拓扑和模型压缩比。
4.5 CoCo in Different Network Environments
结果表明:无论通信资源的异质性如何,CoCo都能充分利用可用带宽来加速DFL,并达到与同质网络条件下相同的收敛速度。这是因为CoCo能够根据worker的通信容量自适应地确定邻居和压缩比,这是其他固定网络拓扑和相同压缩比的算法无法实现的。
5、结论
为了加速DFL,本文提出了一种高效算法CoCo,它自适应地构建P2P网络拓扑,并为所有worker确定适当的压缩比,以克服网络动力学和系统异构性问题。大量的仿真和实验证明了CoCo的有效性和效率。


















 60万+
60万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









