







先在咱们的虚拟环境中安装scrapy,用虚拟环境中的pip工具:
环境搭建:
F:\
cd F:\GIThubRepository\PythonTest01\PythonTest01_Home\Scripts
pip install scrapy -i https://pypi.douban.com/simple/
然后在项目根目录(上级目录)中为爬虫建一个独享的空间(文件夹):
cd ..
scrapy startproject MyScrapyProject
进入爬虫的文件夹,创建一个爬虫:
cd MyScrapyProject
scrapy genspider MyScrapy quotes.toscrape.com
这里quotes.toscrape.com是一个很不错的用来学习爬虫的网站,html元素比较简洁。
后来发现的问题 这个url虽然在之后可能不会被使用,但是如果写错了也会报错
并且他会自动添加https:// 所以咱就不要多写了
在这里指定的意义是以他为start_url开始爬,这个网站可以在之后的.py文件中修改
编写爬虫(重点):
框架:
具体的爬虫核心代码应该放在Spiders文件夹里面
也就是这里我新建的Spider01.py文件(文件名没有意义,重要的是内部类定义的名字)

用notepad++打开,主要是在这里notepad++代码补全比VS强一些
import scrapy
class Spider01 (scrapy.Spider):
name= 'MyMainSpider'#!!!!!!!
start_urls=[
'https://quotes.toscrapy.com/'
]
def parse(self,response):
pass
写一个框架,这里Spider01类的name属性是标识爬虫的识别符,之后用它来启动爬虫
先了解下怎么处理网站的数据(收集的工作可以说是自动的):

我用的chrome,
f12打开要爬的网站:http://quotes.toscrape.com/ 的html代码
能找到网站的这些名人名言的Text元素

用这个小工具能直观地定位元素
接下来想从网站源码中获取元素,要用到“样式选择器”
初学肯定不知道通过css选择器能返回一些什么值,那么可以用scrapy shell来交互式地检查返回值是什么:
具体使用一下就懂了
进入项目目录 输入
scrapy shell http://quotes.toscrape.com/

进入scrapy的交互式控制台并得到quotes.toscrape的网页源码
然后就是自己对返回的response用css选择器进行内容检查:
比如:返回 title 标签的内容:

返回title标签的字符串内容:

对标签元素用(’::text’) .get()方法就是获得标签头<>和标签尾</>中间夹着的文本
Title这个标签很简单,
但是往往有用的不是这么简单的,是写一个类来实例化的
比如我们需要的这句名言:
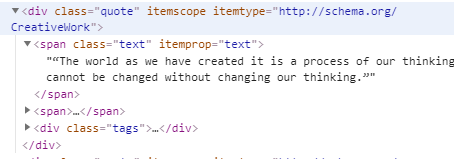
那么它的元素标签div是一个很通用的标签,不能用来指定到我们要的元素
但是注意到后面的类名class=”quote”,这是比较具体的,所以可以用标签+类名准确地指向要的元素

返回这个页面所有的div中类名为quote的元素,并用list的形式呈现
然而如果现在尝试用title中的方法,直接get,结果是很诡异的,因为div.quote类的元素还有一个子类span.text

我们在get前应该先获得这个叶子的元素
实现方法很多
(第一行是response.css(‘div.quote’).css(‘span.text’)
第二行是 response.css(‘span.text’)
)

比较一下,是一样的
因为从div.quote中选择span.text标签元素显然是我们需要的元素
而直接从整个页面中选择span.text标签元素,因为没有其他元素的标签是span.text,所以还是我们需要的元素
这样获得了叶子元素,我们就可以仿照title的方法,

这里是列表,用get()默认是从第一个元素取其text
下面再试试,对第一句名言获得它的tags:

这里必须得先用div.quote过滤一次了,否则肯定会找到了其它名言tags了!
好,现在应该对用css选择器获得我们想要的东西比较了解了,那么我们把它写到爬虫里去:

这里的parse函数就是处理网页源码获得我们想要的内容的地方
def parse(self,response):
quote_list=response.css('div.quote')
with open('text.txt','w') as f:
for oneSentence in quote_list:
f.write(oneSentence.css('span.text::text').get()+'\n')
f.write(oneSentence.css('small.author::text').get()+'\n')
tag_list=oneSentence.css('a.tag');
for tag in tag_list:
f.write(tag.css('::text').get()+' ')
f.write('\n')
简单编辑一下,这里就先不用数据库了,咱们用文件记录
保存,下面运行爬虫:
退出scrapy shell回到项目目录

启动爬虫:
有很多方法,这里用scrapy crawl
进入爬虫的项目文件夹(不进入应该也可以,试试):

启动:
scrapy crawl MyMainSpider
注意这里用的爬虫名是什么
成功!

200这个代码,说明网页源码获得成功!(上面有个404 是获得网站robot.txt爬虫限制文件失败,说明这个网站你用爬虫可随便搞!)
怀着激动的心情打开看看!

非常漂亮,名言内容、作者、标签都很全面而且形式简单适合后续处理
大概这样就会了最基本的使用了吧!
(写blog真的很能促进理解,继续加油!)















 1188
1188











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









