







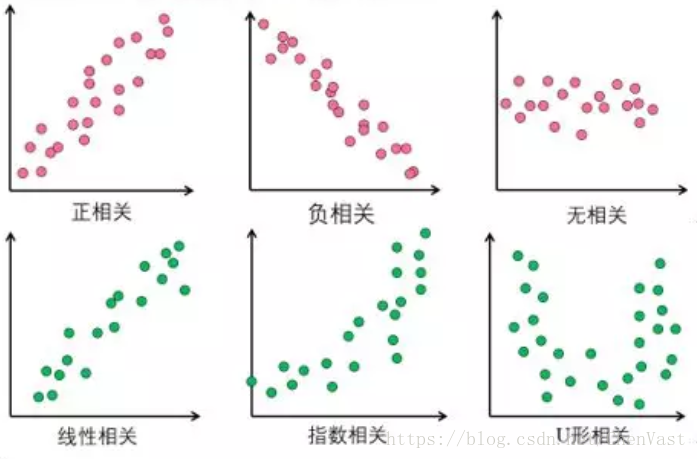
相关的类型:
- 正相关:两个变量同时增加(或减小)。
- 负相关:两个变量变化的趋势相反,一个变量增加而另一个变量减小。
- 不相关:两个变量间没有明显的(线性)关系。
- 非线性关系:两个变量有关联,但是以散点图呈现的相关关系不是直线形状。
相关类型散点图
相关系数r的性质:
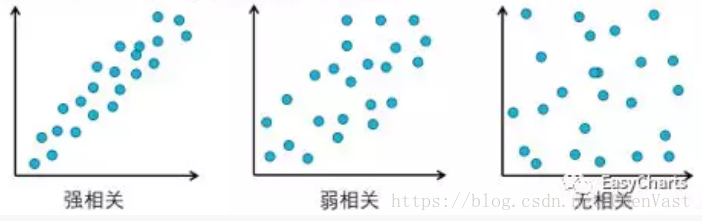
(1)相关系数工用于测量相关性的强度,它的取值范围是-1~1
(2)如果不相关,点的分布就不会以直线模式上升或下降的值接近于0
(3)如果是正相关,相关系数就是正数(0<r≤1):两个变量一同增加。完全正相关(所有的点在散点图中呈现一条上升的直线)的相关系数r=1。r的值接近1表明是强正相关,r的值接近0表明是弱正相关
(4)如果是负相关,相关系数就是负数(-1≤r<0):一个变量上升,另一个变量下降。完全负相关(所有的点在散点图中呈现一条下降的直线)的相关系数r=-1。r的值接近-1表明是强负相关,r的值接近0表明是弱负相关。
公式:
正相关是正数、负相关是负数、不相关趋近于零
相关的可能解释
- 相关是偶然的。
- 两个相关变量可能直接受到一些潜在因素的影响。
- 一个变量是另一个变量的原因。但是要注意,即便如此,它也许只是众多原因中的一个
最佳拟合线:散点图中的最佳拟合线(或回归直线),是指比其他拟合线更优的直线(根据严谨的标准统计派量,所有的点都更接近这条直线。
利用最佳拟合线进行预测时的注意事项:
- 如果关系不强或是数据量不足,用最佳拟合线预测的效果就不会太好。如果所有的点都落在最佳拟合线跗近、相关性非常强、预测也会因此而非常准确。如果有大量的样本点远离最佳拟合线相关性非常弱、预测的结果也会不太准确
- 不要使用最佳拟合线对超出数据范围的点进行预测
- 一条由过去数据得到的最佳拟合线对现在和未来的预测都是无效的
- 不要对与样本所在总体不同的总体进行预测
- 当相关性不显著或呈现非线性关系时拟合的线没有意义
最佳拟合线和:
相关系数的平方(),是指可以用最佳拟合线进行解释的变量的变化比率
利用多元回归以计算一个变量(如价格)和两个或两个以上变量的组合变量(如重量和颜色)之间拟合的最佳方程。判定系数(R^2)告诉我们最佳拟合方程可以解释的散点数据的比率
y = mx + b
斜率 = m = r * sy/sx
截距 = b = y^- m * x^-
建立因果关系的指导原则:
如果你怀疑某一特定的变量(被怀疑的原因)对其他变量产生了一些影响:
- 寻找对被怀疑变量产生影响的那些变量,此时我们并不
- 关心其他因素变化与否。
- 在被怀疑变量存在或剔除后有不同变化的变量中,核实被怀疑的变量剔除与否对这些变量的影响是否相同。
- 寻找大量的被怀疑变量产生众多影响的证据。
- 如果影响由其他潜在的原因引起(你怀疑之外的原因),确保在解释了其他潜在的原因之后,影响依然存在。
- 如有可能,通过实验研究测试被怀疑的原因。如果由于道德原因实验不能够模拟的话,考虑用动物、细胞培养物或计算机模型进行实验。
- 试判断由被怀疑变量产生影响的物理机制
因果关系的置信水平:
可能的原因:我们已经讨论了相关性,但是不能确定相关性之中是否蕴含着因果关系。在法律体系中,可能的原因(例如认为一个嫌疑人可能犯罪了)经常成为开始一项调查的原因。
合理的根据:我们有足够的理由去怀疑相关包含因果关系,可能是因为符合一些建立因果关系的原则。在法律体系中,合理的根据会成为法官批准逮捕令或合法窃听的一般标准
排除合理怀疑:我们已经找到合理解释一件事情影响另一件事情的实体模型,怀疑这个因果关系是不合理的。
在法律体系中,排除合理怀疑是定罪的一般标准,并且要在陈述中展示嫌疑人是如何以及为什么犯罪。排除合理怀疑并不意味着排除一切怀疑

















 3356
3356

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









