







论文原文:
https://arxiv.org/pdf/2004.10934.pdf
代码实现:
https://github.com/AlexeyAB/darknet
一、介绍
原文名称:《YOLOv4: Optimal Speed and Accuracy of Object Detection》,可以看出这是一个非常自信的题目,声称YOLOv4在目标检测具有最优的速度和准确率。相比于Joe Redmon的最终作品YOLOv3,Alexey Bochkovskiy为一作的YOLOv4确实取得了非常明显的速度和准确率的提升。笔者认为YOLOv4的提升更多的还是一些工程上的奇技淫巧,将最近几年内提出的用于其他模型的方法结合YOLO进行融汇贯通。从数据增强,模型结构和训练方法等都进行了大量的改进,通过本文也可以了解到最近一些年提出的工程上的最佳实践。
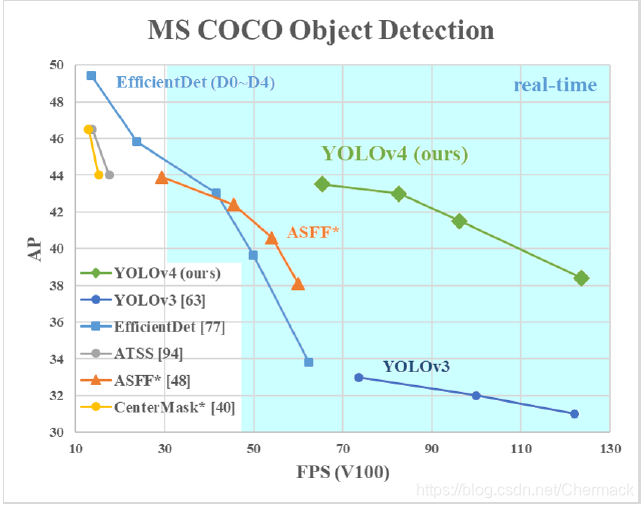
上图横轴为效率,纵轴为准确率。效率和准确率都高则会在图中右上部分。在低帧率上,例如EfficientDet能够达到更高的准确率,但是就低于30FPS而言(图中非蓝色部分),达不到实时流畅的程度。所以说YOLOv4在效率和准确率上具有最佳性价比更加贴切。
二、YOLOv4改进
YOLOv4的改进内容十分丰富,但原作者在Introduction部分自述贡献主要包括以下三点:
- 提出了一个高效高性能的目标检测模型,确保任何人都可以使用单张传统的GPU便可以训练YOLOv4,例如1080Ti或2080Ti(相比于TITAN V 或者Tesla V100等高端显卡或多张显卡而言)。
- 结合最新的BoF(Bag-of-Freebies)和BoS(Bag-of-Specials)方法YOLOv4进行改进。(BoF,一袋免费的商品,比喻的是一些训练方法技巧,加入这些训练方法和技巧,并不会增加模型推理时候的开销,即在模型部署使用时并不会推理更慢或者占用更高的机器性能,但是可能会在训练时多费一些时间和功夫,加入这些方法和技巧肯定能使模型训练的更好,因此比作一袋免
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1333
1333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









