







计算机视觉任务(Computer Vision)整理
计算机视觉是关于研究机器视觉能力的学科,或者说是使机器能对环境和其中的刺激进行可视化分析的学科。机器视觉通常涉及对图像或视频的评估,英国机器视觉协会(BMVA)将机器视觉定义为“对单张图像或一系列图像的有用信息进行自动提取、分析和理解”。
计算机视觉任务用一句话概括就是:Visual problem solving:“What is where?“.是指用摄影机和电脑代替人眼对目标进行识别、跟踪和测量等。
本文针对每项任务给出了基本概念及相应的典型方法(相关的深度学习模型和应用程序),以对各项任务进行简单介绍。
在CV领域,主要的任务分别为图像分类/定位、目标检测、目标跟踪、语义分割以及实例分割。此外还有很多其他更加具体的任务,简介如下:
主要任务
图像分类(Image Classification)
一张图像中是否包含某种物体,对图像进行特征描述是物体分类的主要研究内容。一般说来,物体分类算法通过手工特征或者特征学习方法对整个图像进行全局描述,然后使用分类器判断是否存在某类物体。
图像分类流程:给定一组各自被标记为单一类别的图像,我们对一组新的测试图像的类别进行预测,并测量预测的准确性结果。
对于图像分类而言,最受欢迎的方法是卷积神经网络(CNN)。CNN网络结构基本是由卷积层、池化层以及全连接层组成。通常,输入图像送入卷积神经网络中,通过卷积层进行特征提取,之后通过池化层过滤细节(一般采用最大值池化、平均池化),最后在全连接层进行特征展开,送入相应的分类器得到其分类结果。
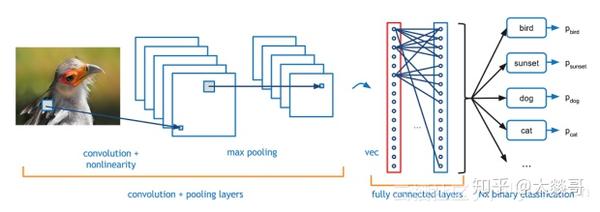
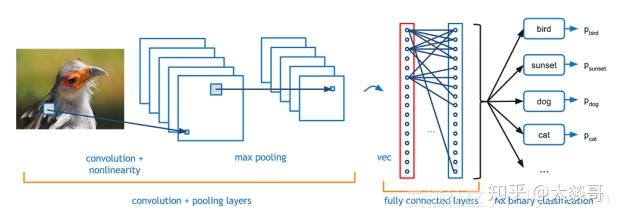
Figure 1. CNN
在分类任务中,CNN经典神经网络结构是AlexNet网络模型,在其之后,有很多基于CNN的算法也在ImageNet上取得了特别好的成绩,比如ZFNet(2013)、GoogleNet(2014)、VGGNet(2014)、ResNet(2015)以及DenseNet(2016)等。
图像定位(Image location)
在图像分类的基础上,我们还想知道图像中的目标具体在图像的什么位置,通常是以包围盒的(bounding box)形式。
多任务学习,网络带有两个输出分支。一个分支用于做图像分类,即全连接+softmax判断目标类别,和单纯图像分类区别在于这里还另外需要一个“背景”类。另一个分支用于判断目标位置,即完成回归任务输出四个数字标记包围盒位置(例如中心点横纵坐标和包围盒长宽),该分支输出结果只有在分类分支判断不为“背景”时才使用。
目标检测(Object Dection)
目标检测通常是从图像中输出单个目标的Bounding Box(边框)以及标签。在目标定位中,通常只有一个或固定数目的目标,而目标检测更一般化,其图像中出现的目标种类和数目都不定。因此,目标检测是比目标定位更具挑战性的任务。
第一个高效模型是R-CNN(基于区域的卷积神经网络,后期又出现了Fast R-CNN算法以及Faster R-CNN算法。近年来,目标检测研究趋势主要向更快、更有效的检测系统发展。目前已经有一些其它的方法可供使用,比如YOLO、SSD以及R-FCN等。
目标跟踪
目标跟踪是指在给定场景中跟踪感兴趣的具体对象或多个对象的过程。简单来说,给出目标在跟踪视频第一帧中的初始状态(如位置、尺寸),自动估计目标物体在后续帧中的状态。
使用SAE方法进行目标跟踪的最经典深层网络是Deep Learning Tracker(DLT),提出了离线预训练和在线微调。
基于CNN完成目标跟踪的典型算法是FCNT和MD Net。
语义分割(Semantic Segmentation)
计算机视觉的核心是分割过程,它将整个图像分成像素组,然后对其进行标记和分类。语言分割试图在语义上理解图像中每个像素的角色(例如,汽车、摩托车等)。语义分割是目标检测更进阶的任务,目标检测只需要框出每个目标的包围盒,语义分割需要进一步判断图像中哪些像素属于哪个目标。
基本思路:逐像素进行图像分类。我们将整张图像输入网络,使输出的空间大小和输入一致,通道数等于类别数,分别代表了各空间位置属于各类别的概率,即可以逐像素地进行分类。
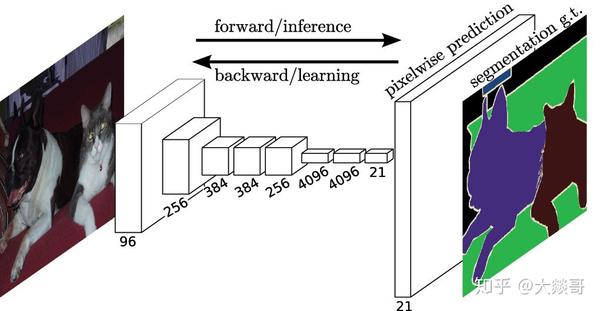
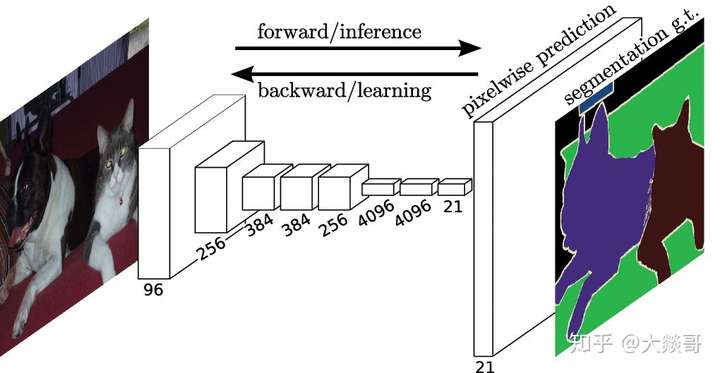
Figure 2. Semantic Segmentation
CNN同样在此项任务中展现了其优异的性能。典型的方法是FCN。FCN模型输入一幅图像后直接在输出端得到密度预测,即每个像素所属的类别,从而得到一个端到端的方法来实现图像语义分割。
实例分割
与语义分割有所不同,物体分割不仅需要对图像中不同的对象进行分类,而且还需要确定它们之间的界限、差异和关系。
基本思路:目标检测+语义分割。先用目标检测方法将图像中的不同实例框出,再用语义分割方法在不同包围盒内进行逐像素标记。
CNN在此项任务中同样表现优异,典型算法是Mask R-CNN。Mask R-CNN在Faster R-CNN的基础上添加了一个分支以输出二元掩膜。
其他任务(持续更新)
图像标注 (Image Captioning)
图像标注是一项引人注目的研究领域,它的研究目的是给出一张图片,你给我用一段文字描述它。(根据图片生成描述文字)
图像生成(Image Generator)
文字转图像
超分辨率、风格迁移、着色
超分辨率指的是从低分辨率对应物估计高分辨率图像的过程,以及不同放大倍数下图像特征的预测,这是人脑几乎毫不费力地完成的。最初的超分辨率是通过简单的技术,如bicubic-interpolation和最近邻。在商业应用方面,克服低分辨率限制和实现“CSI Miami”风格图像增强的愿望推动了该领域的研究。
风格转换作为一个主题,一旦可视化是相当直观的,比如,拍摄一幅图像,并用不同的图像的风格特征呈现。
着色是将单色图像更改为新的全色版本的过程。最初,这是由那些精心挑选的颜色由负责每个图像中的特定像素的人手动完成的。2016年,这一过程自动化成为可能,同时保持了以人类为中心的色彩过程的现实主义的外观。
显著性检测
显著性目标检测,是指对于一幅图像,以最接近于人眼关注范围的方法将图像的较为突出或者比较重要的目标区域标注出来以便后续利用。显著性检测任务从原理上可以分为两种,即眼动点检测和显著性目标检测.后者显著性检测任务与目标检测与分割等任务联系紧密。
行为识别
行为识别的任务是指在给定的视频帧内动作的分类,以及最近才出现的,用算法预测在动作发生之前几帧的可能的相互作用的结果。
人体姿势估计
人体姿势估计试图找出人体部位的方向和构型。 2D人体姿势估计或关键点检测一般是指定人体的身体部位,例如寻找膝盖,眼睛,脚等的二维位置。
场景理解
在物体识别问题已经很大程度上解决以后,我们的下一个目标是走出物体本身,关注更为广泛的对象之间的关系、语言等等。
图像恢复
图像合成
图像重建
自然场景文本检测与识别
3D视觉
3D理解传统上面临着几个障碍。首先关注“自我和正常遮挡”问题以及适合给定2D表示的众多3D形状。由于无法将相同结构的不同图像映射到相同的3D空间以及处理这些表示的多模态,所以理解问题变得更加复杂。最后,实况3D数据集传统上相当昂贵且难以获得,当与表示3D结构的不同方法结合时,可能导致训练限制。
场景重构,多视点和单视点重建,运动结构(SfM),SLAM等。
主要深度学习技术
监督学习
给定样本一个固定标签,然后去训练模型
无监督学习
深度无监督学习(Deep Unsupervised Learning)–预测学习。推荐一篇2017年初Ian GoodFellow结合他在NIPS2016的演讲写出的综述性论文—— 《NIPS 2016 Tutorial: Generative Adversarial Networks》
强化学习(Reinforcement Learning)
给定一些奖励或惩罚,强化学习就是让模型自己去试错,模型自己去优化怎么才能得到更多的分数。
应用
- 人脸识别:人脸检测算法,能够从照片中认出某人的身份;
- 图像检索:类似于谷歌图像使用基于内容的查询来搜索相关图像,算法返回与查询内容最佳匹配的图像。
- 游戏和控制:体感游戏;
- 监控:公共场所随处可见的监控摄像机,用来监视可疑行为;
- 生物识别技术:指纹、虹膜和人脸匹配是生物特征识别中常用的方法;
- 智能汽车:视觉仍然是观察交通标志、信号灯及其它视觉特征的主要信息来源;


















 453
453












 到【灌水乐园】发言
到【灌水乐园】发言









概括的很全面,很清晰,感谢