







各位数据爱好者们,你是否曾经面对过杂乱无章的数据,感到无从下手?你是否曾经被缺失值、异常值、格式混乱等问题搞得焦头烂额?你是否渴望掌握一套系统的数据处理方法,将原始数据“点石成金”,为后续的分析和建模打下坚实基础?
我们将开启一系列关于数据处理的精彩文章,带你从零开始,逐步掌握数据处理的方方面面,最终成为数据领域的“炼金术士”!
在这系列文章中,我们将涵盖以下内容(更新中,您可以你直接点击跳转):
-
数据清洗:从“脏数据”到“干净数据”的蜕变之旅,教你如何识别和处理数据中的各种问题。
-
数据增强:掌握数据增强技巧,解决数据不足的问题,提升模型性能。
无论你是数据科学初学者,还是有一定经验的从业者,这系列文章都将为你带来新的启发和收获!
目录
一、引言
在Al项目中,我们常常听到一句话:“垃圾进,垃圾出”(GarbageIn,GarbageOut)。这句话形象地道出了数据质量对于模型效果的重要性。无论你使用多么先进的神经网络结构、多么强大的算力,若数据本身充斥着错误、缺失、噪声或偏差,模型最终也难以表现理想。本节将针对这一问题,详细探讨“脏”数据的常见类型,以及如何系统地对其进行清洗,让训练数据能够"让模型满意。”
二、数据清洗
在数据科学和机器学习的世界里,数据是燃料,模型是引擎。然而,现实中的数据往往并不完美,它们可能充满了错误、缺失、不一致和噪声。如果直接将这些“脏数据”喂给模型,结果往往会让人大失所望。这时,数据清洗就成了数据科学家和工程师的必修课。
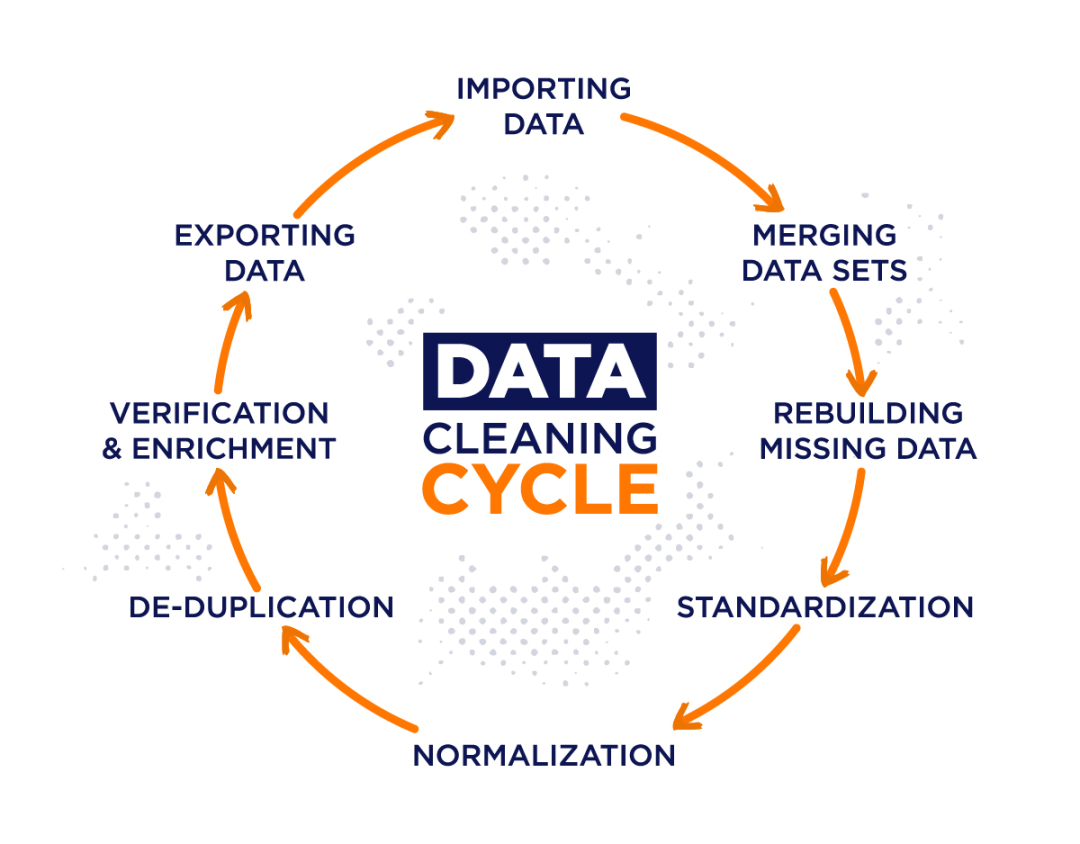
数据清洗(Data Cleaning)是指对原始数据进行处理,以纠正或删除错误、不完整、重复或不相关的部分,从而提高数据的质量和可用性。它是数据预处理的重要环节,它包括处理缺失值、去除重复数据、修正数据错误、统一数据格式、清除噪音数据以及校对标注等步骤。数据清洗的目的是确保数据的准确性和一致性,从而为后续的分析和模型训练提供可靠的基础。
三、常见的“脏”数据
-
缺失值(Missing Values)

成因:缺失值可能由于硬件故障、网络中断或存储损坏等原因导致某些文件或字段丢失。
图像数据体现:某些照片或帧可能无法解码,或者拍摄过程中可能漏掉某段场景。
影响:少量缺失数据影响较小,但若缺失比例较高,会严重扭曲数据分布,影响模型性能。在深度学习中,尤其是图像或文本任务,缺失数据常常意味着无法使用该样本。
处理:一些结构化数据中的缺失值可以被某些算法(如决策树、随机森林)忽略或自动处理,但图像数据中的缺失往往无法弥补。
-
异常值(Outliers)
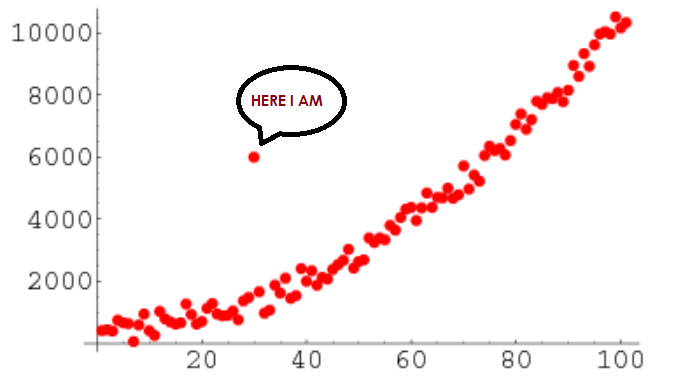
定义:异常值指数据中显著偏离总体分布的极端样本,可能是采集错误,也可能是真实的稀有情况。
图像数据体现:例如,极端天气(暴雨、沙尘暴等)或飞行高度异常的无人机拍摄图像。
影响:如果异常值反映真实世界的极端情况,则应保留并加以学习;如果只是错误数据,则会让模型难以收敛,甚至出现误判。
检测:可以通过统计学方法(如3σ原则、箱形图)、机器学习方法(如聚类、孤立森林)或人工审核来定位。
-
噪声(Noise)
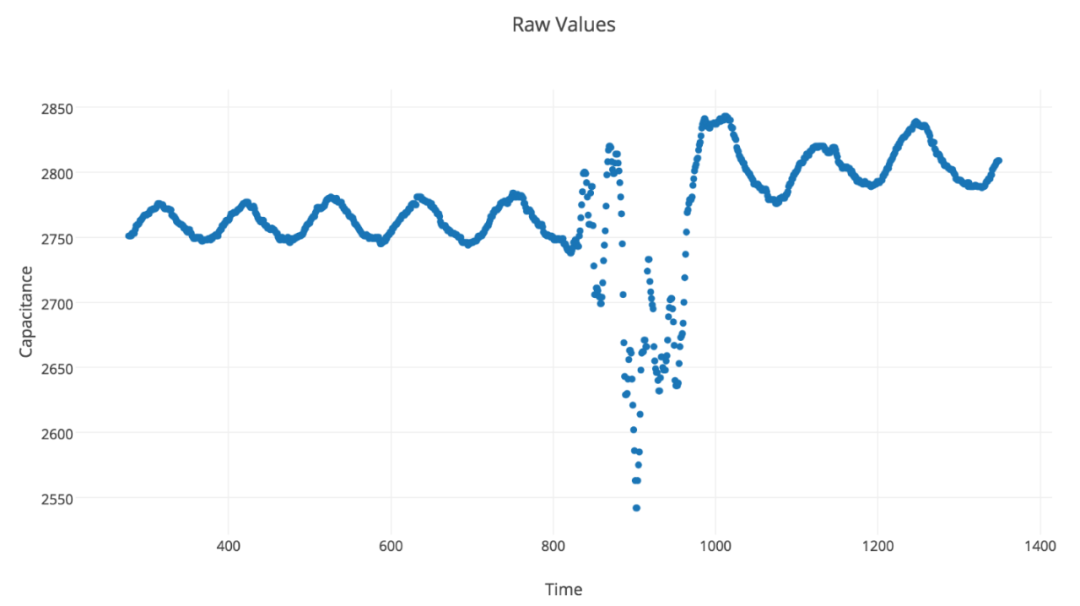
图像中的体现:如高ISO导致的噪点、运动模糊、压缩伪影等,或传感器坏点、镜头污渍等。
影响:噪声会掩盖图像中的真实特征,尤其在边缘检测、目标检测等任务中,噪声会干扰关键特征的提取。
区分噪声与有用特征:某些“花纹”或“复杂背景”看似噪声,但实际上可能是有用的特征(如道路破损、积水等),清洗时需要小心判断。
-
不一致或错误的标注(标注噪声)
成因:标注过程中的仓促、标注员能力不足或任务要求不清晰等问题。
常见后果:例如,车道线标注偏移,车辆边界框不准确,甚至误将行人标注为车辆。
影响:标注噪声比缺失值更具破坏性,因为它直接导致训练目标错误,影响模型学习正确的规律。若标注噪声较大,模型可能永远无法学习到准确的目标。
-
其它脏数据类型
数据“脏”还可能体现在采样偏差、重复数据过多、时间戳错位等方面。这些问题同样会影响模型的训练和结果。
在进行数据清洗前,了解业务需求和数据采集背景是至关重要的。理解数据的产生背景,能够帮助判断哪些“脏”数据是纯粹的噪声,哪些是具有实际意义但极端的情况。
四、数据清理步骤
对“脏”数据的处理并没有”一招鲜“的通用方案,而是需要结合技术和业务,分步、迭代地执行。可将其概括为以下几个核心原则和流程:
-
数据概览与“脏”数据识别
图像数据概览
使用 check_image_validity 方法检查图像的有效性,并统计无效图像的比例和原因。
# 示例:检查单张图像的有效性
cleaner = DataCleaner()
result = cleaner.check_image_validity("test.jpg")
print("图像检查结果:", result)
# 批量检查图像有效性
image_paths = ["image1.jpg", "image2.jpg", "image3.jpg"]
invalid_images = []
for path in image_paths:
result = cleaner.check_image_validity(path)
if not result["is_valid"]:
invalid_images.append((path, result["error_message"]))
print("无效图像列表:", invalid_images)输出示例:
图像检查结果: {'is_valid': True, 'error_message': ''}无效图像列表: [('image2.jpg', '图像尺寸过小'), ('image3.jpg', '图像可能全黑或全白')]
分析:
通过检查图像有效性,发现部分图像尺寸过小或全黑/全白。
可以进一步统计无效图像的比例,决定是否删除或修复。
表格数据概览
使用Pandas的 describe() 和 info() 方法查看表格数据的基本信息。
# 示例:查看表格数据的基本信息
data = {
'A': [1, 2, None, 4],
'B': [None, 2, 3, 4],
'value': [1, 2, 100, 3, 4, 5]
}
df = pd.DataFrame(data)
# 查看描述统计
print("描述统计:\n", df.describe())
# 查看字段信息和缺失值
print("\n字段信息:\n")
df.info()输出示例:
描述统计:
A B value
count 3.0 3.0 6.0
mean 2.333333 3.0 19.0
std 1.527525 1.0 43.108
min 1.0 2.0 1.0
25% 1.5 2.5 2.25
50% 2.0 3.0 3.5
75% 3.0 3.5 4.75
max 4.0 4.0 100.0
字段信息:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4 entries, 0 to 3
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 A 3 non-null float64
1 B 3 non-null float64
2 value 4 non-null int64
dtypes: float64(2), int64(1)
memory usage: 224.0 bytes分析:
字段 A 和 B 存在缺失值。
字段 value 存在异常值(最大值为100,明显偏离其他值)。
-
制定清洗策略
缺失值处理策略
对字段 A 使用均值填补。
对字段 B 使用前向填充。
异常值处理策略
对字段 value 使用Z-score方法,剔除超出阈值(如 2.0)的异常值。
图像处理策略
删除无效图像(如尺寸过小、全黑/全白)。
修复轻微损坏的图像(如去噪)。
-
执行清洗
处理缺失值
使用 fix_missing_values 方法填补缺失值。
# 示例:填补缺失值
strategy = {'A': 'mean', 'B': 'ffill'}
df_cleaned = cleaner.fix_missing_values(df, strategy)
print("\n处理缺失值后:\n", df_cleaned)输出示例:
处理缺失值后:
A B value
0 1.0 NaN 1
1 2.0 2.0 2
2 2.333333 3.0 100
3 4.0 4.0 3分析:
字段 A 的缺失值已用均值填补。
字段 B 的缺失值已用前向填充。
处理异常值
使用 remove_outliers 方法剔除异常值。
# 示例:剔除异常值
df_cleaned = cleaner.remove_outliers(df_cleaned, ['value'], 'zscore', 2.0)
print("\n处理异常值后:\n", df_cleaned)输出示例:
处理异常值后:
A B value
0 1.0 NaN 1
1 2.0 2.0 2
3 4.0 4.0 3分析:
字段 value 的异常值(100)已被剔除。
修复图像
使用 repair_image 方法修复轻微损坏的图像。
# 示例:修复图像
repaired_image = cleaner.repair_image("damaged_image.jpg", repair_method="denoise")
cv2.imwrite("repaired_image.jpg", repaired_image)
print("图像修复完成,已保存为 repaired_image.jpg")分析:
对损坏的图像进行去噪处理,并保存修复后的图像。
-
迭代评估
清洗前后对比
对比清洗前后的数据分布(如直方图、箱线图)。
检查清洗后的数据是否符合业务逻辑和预期。
# 示例:绘制清洗前后的数据分布
import matplotlib.pyplot as plt
# 清洗前的分布
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.hist(df['value'], bins=10, color='blue', alpha=0.7)
plt.title("清洗前分布")
# 清洗后的分布
plt.subplot(1, 2, 2)
plt.hist(df_cleaned['value'], bins=10, color='green', alpha=0.7)
plt.title("清洗后分布")
plt.show()分析:
清洗后,异常值被剔除,数据分布更加合理。
基准模型验证
使用清洗前后的数据训练基准模型,比较模型性能。
如果清洗后模型性能提升,则表明清洗有效;反之,则需重新评估清洗策略。
-
可追溯性与文档化
日志记录
清洗过程中的每一步操作都被记录在日志文件中。
# 查看日志文件
with open("cleaning_log.txt", "r", encoding='utf-8') as f:
print(f.read())日志示例:
数据清洗日志
==================================================
操作:缺失值处理
详情:应用策略:{'A': 'mean', 'B': 'ffill'}
------------------------------
操作:异常值处理
详情:方法:zscore, 阈值:2.0, 处理列:['value']
------------------------------
操作:图像修复
详情:方法:denoise, 文件:damaged_image.jpg
------------------------------版本控制
对清洗后的数据进行版本控制(如保存为 cleaned_data_v1.csv )。
确保每次清洗的结果可追溯。
五、实践案例
为了让概念更落地,以下简要介绍个案例:清洗无人机低空影像中的异常值。
-
首先查看所有文件的基本信息,如文件大小、分辨率、时间戳等,发现有若干时刻因为雾太大导致图像严重模糊。
-
观察图像内容后,判断雾天效果并不在当前需求范围之内,或是比例太小,无法支撑模型进行有效学习。
-
针对这部分数据,你可以做的选择有两种:1)完全删除,将这些雾天图像标记为丢弃“版本。2)将它们单独存放在一个“待定"版本库中,以备后续做特定研究或补充。
-
若确定删除,则在数据版本管理系统里记录本次操作:删除了某日期、某时段内的X张“雾天影像,并说明理由。
代码示例:
# 导入必要的库
import os
import cv2
import datetime
# 函数:获取图像文件的基本信息
def get_image_info(image_path):
# 获取图像文件大小(字节)
file_size = os.path.getsize(image_path)
# 读取图像
image = cv2.imread(image_path)
# 获取分辨率
height, width, channels = image.shape
# 获取文件的时间戳
timestamp = os.path.getmtime(image_path)
# 返回图像的基本信息
return file_size, (width, height), timestamp, image
# 函数:判断图像是否模糊(雾天影像)
def is_blurry(image, threshold=1000):
# 使用拉普拉斯算子进行模糊度检测
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
variance = cv2.Laplacian(gray, cv2.CV_64F).var()
return variance < threshold # 返回是否模糊
# 函数:记录删除或存储待定的图像
def record_action(action, image_path, reason, version_system):
timestamp = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
log_message = f"{timestamp} - {action} image: {image_path}, Reason: {reason}\n"
# 将记录写入版本管理系统的日志文件
with open(version_system, 'a') as log_file:
log_file.write(log_message)
# 函数:处理图像数据
def process_images(image_folder, version_system, discard_threshold=1000):
for filename in os.listdir(image_folder):
image_path = os.path.join(image_folder, filename)
if os.path.isfile(image_path):
# 获取图像的基本信息
file_size, resolution, timestamp, image = get_image_info(image_path)
# 检查是否模糊(雾天)
if is_blurry(image):
# 判断是否删除或待定
print(f"Image {filename} is blurry.")
user_choice = input("Do you want to discard (d) or save to pending (p)?: ").strip().lower()
if user_choice == 'd':
# 删除图像并记录
os.remove(image_path)
record_action("Deleted", image_path, "Foggy image", version_system)
elif user_choice == 'p':
# 将图像保存到待定文件夹并记录
pending_folder = os.path.join(image_folder, "pending")
if not os.path.exists(pending_folder):
os.makedirs(pending_folder)
os.rename(image_path, os.path.join(pending_folder, filename))
record_action("Moved to pending", image_path, "Foggy image", version_system)
# 主程序
if __name__ == "__main__":
# 数据集文件夹路径
image_folder = "path/to/your/images"
# 数据版本管理日志文件路径
version_system = "path/to/your/version_log.txt"
# 处理图像
process_images(image_folder, version_system)通过这一过程,可以看到一个典型的数据清洗思路:先进行可视化或统计分析,识别异常或不合需求的部分,再结合场景目标来做决定。在此过程中,每一步都需要留有记录,以备后续追溯。
六、Coovally AI模型训练与应用平台
在Coovally平台上,提供了可视化的预处理流程配置界面,您可以:选择预处理方法(去噪、锐化、均衡化等),设置处理参数,预览处理效果,批量处理数据。
与此同时,Coovally还整合了各类公开可识别数据集,进一步节省了用户的时间和精力,让模型训练变得更加高效和便捷。
在Coovally平台上,无需配置环境、修改配置文件等繁琐操作,可一键另存为我的模型,上传数据集,即可使用YOLO、Faster RCNN等热门模型进行训练与结果预测,全程高速零代码!而且模型还可分享与下载,满足你的实验研究与产业应用。
总结
数据清洗是数据科学中不可或缺的一环,它决定了数据的质量和后续分析的效果。通过本文的学习,你应该已经掌握了数据清洗的基本概念、常见问题和处理方法。接下来,你可以尝试在实际项目中应用这些知识,逐步提升自己的数据清洗能力。
记住,干净的数据是成功的一半!祝你在数据清洗的旅程中收获满满!


















 282
282

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









