







对于训练过YOLO模型的开发者来说,最常遇到的灵魂拷问是:明明跑了100个epoch,为什么模型效果还是不够好?本文将从训练日志的每一个数字曲线出发,带您像老中医"把脉"一样诊断模型问题,掌握数据集优化与参数调整的核心方法论。
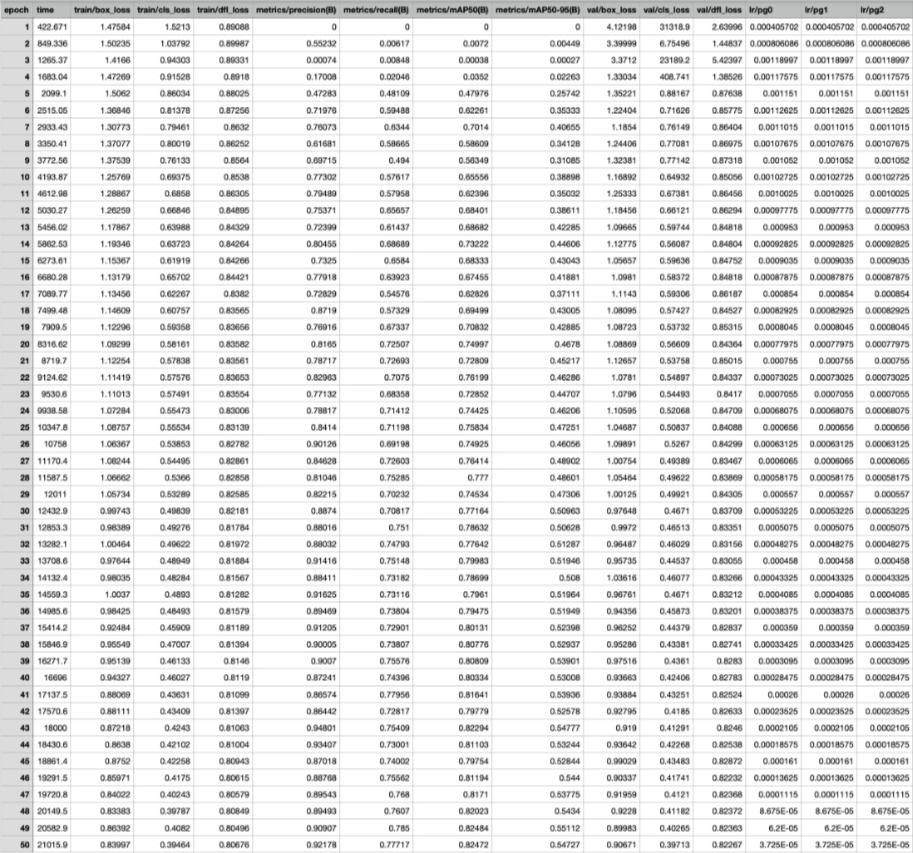
模型训练输出文件概述
训练完 YOLO 模型后,您通常会得到:
-
results.csv 跟踪每个时期指标的文件。
-
显示 confusion_matrix.png 每个类别的预测性能。
-
train_batch0.jpg , val_batch0.jpg 展示数据增强结果。
-
weights/ 带有模型检查点的文件夹,如 best.pt 和 last.pt 。
-
(可选)TensorBoard 或 WandB 日志用于可视化趋势
我们将主要关注 results.csv 和混淆矩阵。
关键评估指标
-
mAP(平均精度)
mAP是判断一个物体检测模型好坏的最重要指标。

mAP@0.5意思是:IoU阈值0.5时的平均精度;(工业常用基准)
mAP@0.5:0.95:对多个 IoU(0.5到0.95,步长0.05)的精度进行平均——一个更严格、更全面的指标。(学术研究首选)
-
准确率和召回率
高精准低召回:模型过于保守(漏检严重)
低精准高召回:模型过于激进(误报频发)
-
混淆矩阵
行:真实值标签;列:预测标签
对角线 = 正确预测
非对角线 = 错误(例如,足球被错误地归类为进球)
由此,您可以清楚地识别哪些类经常被混淆。
如何比较两轮训练结果
假设在足球比赛视频检测中,第一轮训练包含球员(Player)和足球(Ball),第二轮新增球门(Goal)类别后效果反而下降。
-
诊断步骤
-
mAP趋势对比
新增类别后整体mAP@0.5下降5% → 可能引入噪声数据
Goal类别的mAP@0.5仅0.3 → 样本量不足(1000 vs 其他类别10000+)
-
混淆矩阵分析
球门被误判为广告牌的比率达40% → 两类外观相似需数据增强
原有球员检测精度下降 → 新类别分散了模型注意力
-
损失曲线解读
val_loss 在第50 epoch后开始上升 → 典型过拟合信号
cls_loss 波动剧烈 → 学习率可能设置过高
-
解决方案
-
类别平衡法则
手动对目标帧进行过采样:包括更多球门可见帧(即使是合成的)。
注释平衡是关键:旨在保持每个类别的计数更加均匀(例如,理想情况下比例低于 1:5)。
类别权重(在某些框架中):为稀有类别分配更高的损失权重。
增强:使用 copy-paste 或 mosaic 人为增加稀有类别的存在。
-
损失函数改造
# 自定义类别权重
class_weights = [1.0, 1.0, 3.0] # 给Goal类别3倍权重
model = YOLO('yolov8n.yaml', class_weights=class_weights)Coovally AI模型训练与应用平台
你是否厌倦了繁琐的模型配置与代码调试?Coovally——新一代AI开发平台,为研究者和产业开发者提供极简高效的AI训练与优化体验!
-
无需代码,训练结果即时可见!
在Coovally平台上,上传数据集、选择模型、启动训练无需代码操作,训练结果实时可视化,准确率、损失曲线、预测效果一目了然。无需等待,结果即训即看,助你快速验证算法性能!

-
大模型加持,智能辅助模型调优!
若对模型效果不满意?Coovally即将推出大模型智能调参能力,针对你的数据集与任务目标,自动推荐超参数优化方案,让模型迭代事半功倍!

-
千款模型+海量数据,开箱即用!
平台汇聚国内外开源社区超1000+热门模型,覆盖YOLO系列、Transformer、ResNet等主流视觉算法。同时集成丰富公开数据集,涵盖图像分类、目标检测、语义分割等场景,一键下载即可投入训练,彻底告别“找模型、配环境、改代码”的繁琐流程!
-
从实验到落地,全程高速零代码!
无论是学术研究还是工业级应用,Coovally均提供云端一体化服务:
✅ 免环境配置:直接调用预置框架(PyTorch、TensorFlow等);
✅ 免复杂参数调整:内置自动化训练流程,小白也能轻松上手;
✅ 高性能算力支持:分布式训练加速,快速产出可用模型;
✅ 无缝部署:训练完成的模型可直接导出,或通过API接入业务系统。
!!点击下方链接,立即体验Coovally!!
平台链接:https://www.coovally.com
无论你是算法新手还是资深工程师,Coovally以极简操作与强大生态,助你跳过技术鸿沟,专注创新与落地。访问官网,开启你的零代码AI开发之旅!
随时间变化的趋势参数解释
在 results.csv 中,您会发现:
-
损失相关参数
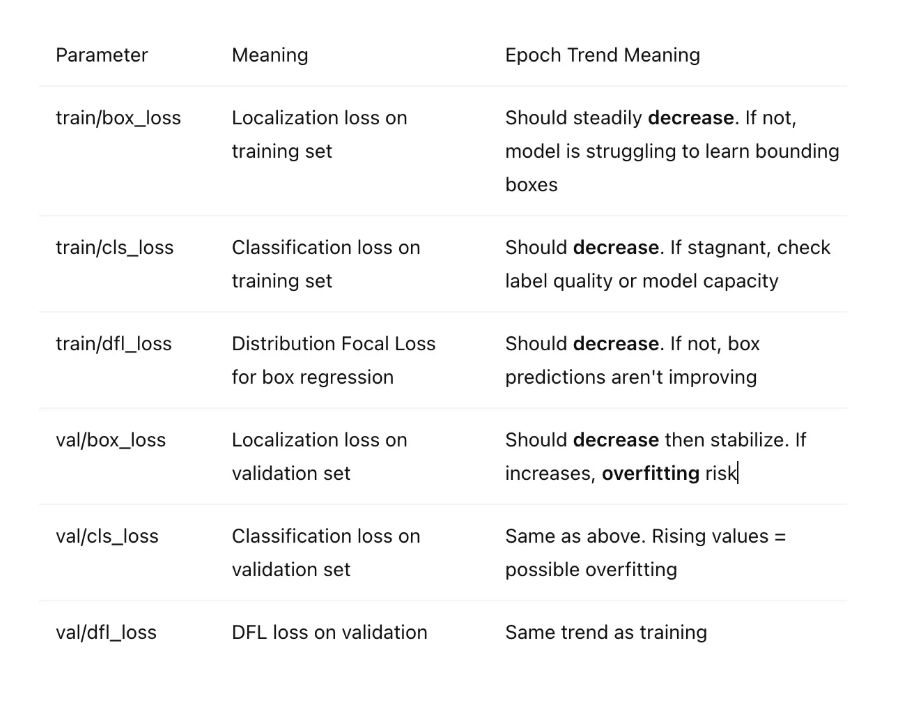
-
绩效指标
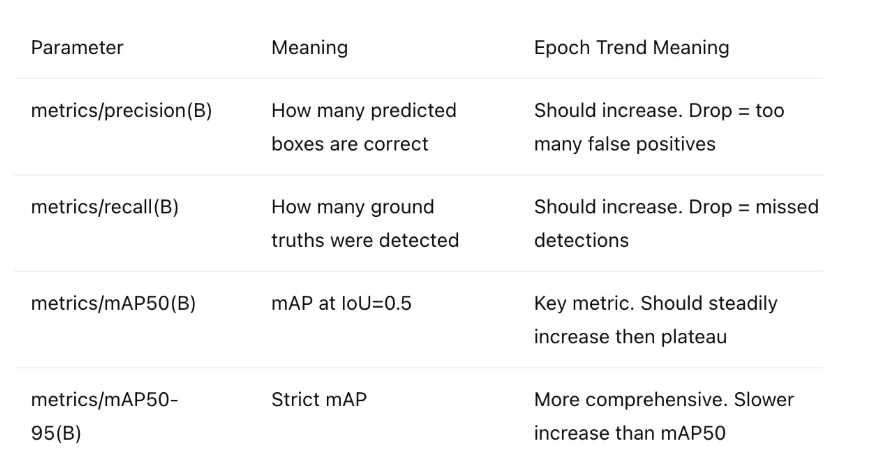
-
学习率

-
其他

如何解读字里行间的含义
除了损失和mAP曲线之外,趋势中还有更深层次的信号:
-
收敛与过度拟合
如果 val/cls_loss 开始增加但 train/cls_loss 仍 在下降,则可能是过度拟合。
如果两者都停滞不前,请考虑提前停止或更改学习率计划。
-
mAP突然下降
通常是由于学习率飙升或过度增强造成的。
检查学习率调度程序和数据转换。
-
后期epoch中的mAP波动
模型不稳定。可能表示数据存在噪声、批次大小不合适或批次范数存在问题。
尝试降低批量大小或冻结 BN 层。
-
准确率与召回率的差距
如果准确率高但召回率低→模型保守,可能会错过检测。
如果召回率高但准确率低→太多误报,可能是标签噪音。
总结与建议
高效的工具会帮助我们的模型训练更加快捷方便,但也要多观察训练曲线、精心调理数据,训练高性能物体检测器不仅仅是运行 epoch。它还涉及:
-
仔细检查指标和损失
-
战略数据集构建和注释平衡
-
了解每个参数趋势告诉你有关模型行为的信息
-
观察训练动态,如收敛、振荡或发散
掌握这个过程将帮助你训练出具有良好泛化能力的模型。



















 1696
1696

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









