







 K近邻模型是监督学习中的判别式模型,用于分类问题。通过计算新实例与已有数据集的距离,选择最近的K个邻居进行分类。K值的选择和距离度量对算法性能至关重要。KNN的缺点是随着数据量增加,计算成本增加。解决策略包括数据降维和使用类中心点代替所有实例计算距离,以提高效率。
K近邻模型是监督学习中的判别式模型,用于分类问题。通过计算新实例与已有数据集的距离,选择最近的K个邻居进行分类。K值的选择和距离度量对算法性能至关重要。KNN的缺点是随着数据量增加,计算成本增加。解决策略包括数据降维和使用类中心点代替所有实例计算距离,以提高效率。
本文主要梳理KNN,K近邻模型的基本原理。
从机器学习的大分类来看,K近邻模型属于监督学习中的一种判别式模型,常用于分类问题。初始的数据集中,包含了已经分类标签好的数据。一句话来说,K近邻模型就是通过计算实例与现有数据集中所有数据的数学距离,从中挑选出K个最近的例子。在这K个例子中,占据大多数的分类就是新的实例的分类。
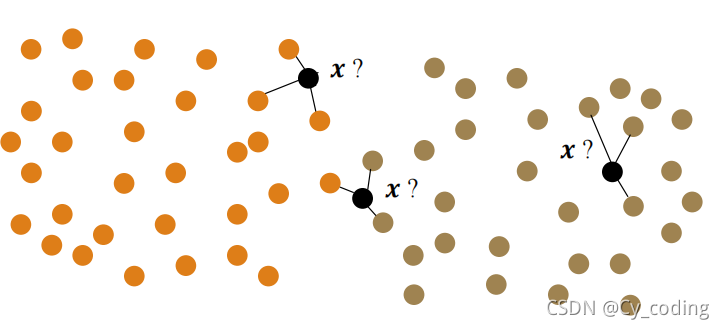
在使用K近邻法时,需要注意的就是定义好数学意义上的距离(一般使用欧拉距离)以及选取合适的K值。这个方法作为分类器的优势在于实现简单,没有先行的假设,但其局限性也很明显,随着样本以及数据量的上升,运算成本也是同比例地增加。
有两种主要的思路,来加速K近邻法的运算。首先我们可以利用PCA主成分分析,或者LDA线性判别分析来对原始数据进行降维处理,降维后再计算向量之间的距离就可以提高效率。
其次,在实现过程中,我们放弃计算新的实例和每一个数据集中的例子的距离,而是先计算各个分类中所有已知数据的平均值,通过新的实例与这个平均值之间的距离来进行分类,虽然一定程度牺牲了分类的准确性提高了不可避免的误差,但却可以大幅度加速我们算法运行的速度。
d E
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 802
802

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









