










这篇论文提出了 AnomalyGPT,一个基于大型视觉语言模型的工业异常检测框架,首次将通用多模态对话能力引入工业视觉场景,通过引入图像解码器增强像素级感知,设计 Prompt 学习器实现任务自适应控制,并利用合成异常样本解决异常数据稀缺问题,最终实现了无阈值、无额外后处理的异常检测、定位与自然语言解释一体化能力。
目录
(4)异常数据生成器(Synthetic Anomaly Generator)
任务2:异常分类任务(Anomaly Classification)
任务3:异常定位任务(Anomaly Localization)
论文标题
AnomalyGPT: Detecting Industrial Anomalies Using Large Vision-Language Models
AnomalyGPT:使用大型视觉语言模型检测工业异常
核心问题:
本论文聚焦于工业异常检测(Industrial Anomaly Detection, IAD)中的两大难点:其一,当前主流的IAD方法仅提供异常分数,需手动设定阈值区分异常与正常样本,限制其在实际工业场景中的实用性;其二,尽管大型视觉语言模型(Large Vision-Language Models, LVLMs)如MiniGPT-4和LLaVA在通用视觉理解任务中表现优异,但其对工业领域缺乏专业知识,且对物体局部细节理解能力较弱,无法有效检测微小但关键的工业缺陷。论文提出的核心问题正是如何借助LVLM提升工业异常检测的智能化和实用性。
创新方法:
作者提出了一种新颖的基于大型视觉语言模型的异常检测框架——AnomalyGPT,其主要创新包括:
-
异常数据生成机制:通过模拟生成异常图像并配套生成文本描述,构建多模态训练数据,增强LVLM对工业异常概念的理解;
-
图像解码器集成:引入图像解码模块以获取图像中细粒度的语义信息,提升模型的细节理解能力;
-
Prompt学习机制:设计专用Prompt Learner模块,通过Prompt嵌入方式对LVLM进行微调,赋予其异常判断能力;
-
端到端判断能力:该方法无需阈值设定,可直接做出异常与否及其定位判断,显著提升实用性;
-
多轮对话与小样本学习:具备对异常原因的多轮对话分析能力,以及显著的in-context few-shot学习能力,仅需一个正常样本即可达成SOTA性能。
该方法依赖于预训练的大型视觉语言模型 LLaVA-1.5【1】,通过Prompt嵌入与图像解码模块增强其工业异常判断能力,适配专业领域需求。
论文讲解:
-
问题背景与挑战界定(第1节):
作者指出IAD任务【2】普遍面临异常样本稀缺、细节变化微小、模型依赖阈值设定等问题,并指出LVLM尽管具备强大的跨模态理解能力,但对细节敏感度不足,不适用于IAD任务。引出本文欲将LVLM适配至工业检测场景的动机。 -
AnomalyGPT框架设计(第3节):
整个系统包括四个关键模块:图像预编码器、图像解码器、Prompt Learner以及LVLM主体。训练数据由正常样本生成,通过仿真方式制作异常图并配对文本描述,增强模型多模态理解能力。Prompt Learner负责根据不同任务学习任务嵌入,以增强模型的上下文推理能力。 -
数据与任务构建(第4节):
为解决真实异常样本稀缺的问题,作者设计了一个模拟生成数据集机制,能够在无异常样本的前提下构建有效的训练样本。此外,还设计了三种任务:图像-文本匹配、异常分类与异常定位,用于全面训练模型的判断与解释能力。 -
实验与结果分析(第5节):
在MVTec-AD数据集上,AnomalyGPT取得 图像级AUC 94.1%、像素级AUC 95.3% 的成绩,超越现有方法。尤其值得注意的是,AnomalyGPT仅需一个正常样本就能在few-shot设定下达到SOTA性能,并支持多轮对话能力。表1系统对比了不同方法在异常得分、定位、判断与交互方面的能力,突显AnomalyGPT的全面性。
局限分析:
-
计算成本:AnomalyGPT基于大型预训练视觉语言模型(如MiniGPT-4),其推理与训练阶段均具有较高计算开销,特别是在多轮对话与图像细节解码部分,部署在资源受限设备上具有挑战;
-
领域泛化能力:尽管通过模拟生成异常图像与文本增强了泛化能力,但该策略在面对高度复杂或未知类别异常时仍可能出现识别盲区;
-
数据需求与依赖:该方法虽不依赖真实异常样本,但其构造的训练数据仍需依赖精确的仿真图像生成与文本描述构造,对数据生成质量存在一定要求;
-
对LVLM的依赖:方法核心依赖于预训练LVLM的通用视觉理解能力,其在特定工业子领域若存在图像分布偏差,则可能面临性能下降问题。
两个问题与回答
• Why型:为什么该方法比传统方案更优?
AnomalyGPT摒弃了传统IAD方法对异常分数与手动阈值设定的依赖,转而直接基于自然语言生成与多模态对齐进行异常识别和定位,不仅提升了判断的自动化程度,还通过Prompt调控支持个性化任务定义。同时,其few-shot学习能力在极低样本条件下也能达到SOTA性能,极大拓展了方法的适用场景。
• How型:如何将该方法扩展到其他场景?
AnomalyGPT的框架具有高度的通用性,可以通过重构仿真图像与文本描述体系,迁移到如医疗影像异常识别(如肿瘤检测)、交通异常监控(如事故检测)、航天产品检测等其他异常检测任务中。同时其多轮对话能力也可用于制造环节的人机协作、缺陷原因解释等智能交互场景。
AnomalyGPT的实现原理
下图来自论文原文。
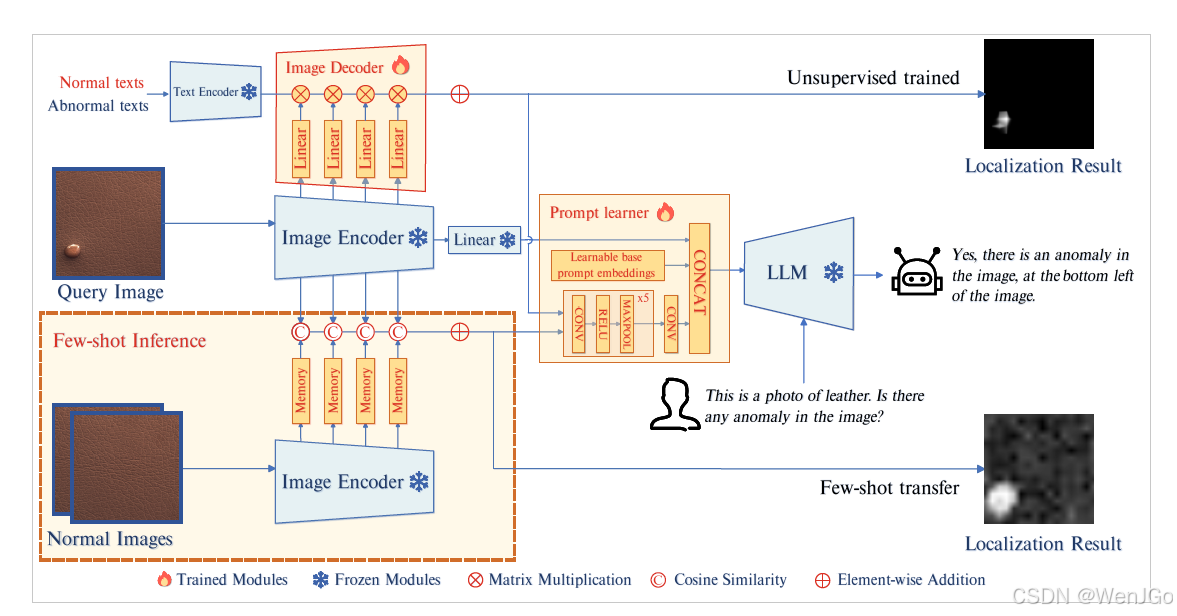
AnomalyGPT的架构。查询图像被传递给冻结的图像编码器,从中间层提取的块级特征被输入到图像解码器中以计算它们与正常和异常文本的相似度,从而获得定位结果。由图像编码器提取的最终特征通过线性层处理后,连同定位结果一起传递给提示学习器。提示学习器将它们转换成适合与用户文本输入一起输入到大型语言模型(LLM)中的提示嵌入。在少样本设置下,正常样本的块级特征存储在记忆库中,定位结果可以通过计算查询块与其在记忆库中最相似的对应块之间的距离来获得。
文字结构描述。
【AnomalyGPT】
↓
【Image Encoder】→ 提取图像特征
↓
【Prompt Learner】←→【Task Queries】←【Image Decoder】
↓ ↓
【Prompt】 【Fine-grained Features】
↓ ↓
←←←←←←【融合】→→→→→
↓
【Output】
组件作用与配合关系说明
-
Image Encoder(图像编码器)
-
作用:将输入的工业图像编码为视觉特征表示。
-
输出:为 Prompt Learner 提供基础视觉特征。
-
-
Prompt Learner(提示词学习器)
-
作用:根据图像编码器的输出,学习任务相关的 Prompt(任务描述/控制信号)。
-
配合:
-
接收 Image Encoder 输出;
-
将学习到的 Prompt 与 Decoder 侧的 Task Queries 对齐;
-
将 Prompt 输出给后续模块用于融合生成最终预测。
-
-
-
Image Decoder(图像解码器)
-
作用:用于图像重建,捕捉图像中更细粒度的特征。
-
配合:
-
解码图像以生成用于下游任务的 Query(任务查询);
-
这些查询进一步输入 Task Queries 模块。
-
-
-
Task Queries(任务查询)
-
作用:将图像解码结果组织成任务特定的查询(例如检测、定位等)。
-
配合:
-
接收来自 Image Decoder 的解码结果;
-
与 Prompt Learner 对齐,结合生成 Prompt 所需的任务理解。
-
-
-
Fine-grained Features(细粒度特征)
-
作用:由任务查询进一步提取的关键特征,用于判断图像中是否存在异常区域。
-
输出:与 Prompt 一起融合,构成最终模型决策依据。
-
-
Prompt(提示)
-
作用:作为语言形式的提示,控制模型的任务行为(如是否检测、是否定位)。
-
来源:由 Prompt Learner 生成。
-
-
Output(最终输出)
-
作用:融合 Prompt 与 Fine-grained Features 的信息,生成包括:
-
异常检测结果;
-
异常区域定位;
-
自然语言描述(多模态输出)。
-
-
1. 总体架构概览
AnomalyGPT 是一个基于大型视觉语言模型(LLaVA-1.5)构建的工业异常检测系统,其整体目标是实现:
-
图像级异常判断(是否异常)
-
像素级异常定位(哪里异常)
-
异常原因描述(为什么异常)
-
多轮问答分析能力(与用户交互式追问)
为达成上述目标,AnomalyGPT 在 LLaVA 的基础上,加入了三大关键模块:
-
图像解码器(Image Decoder)
-
Prompt学习模块(Prompt Learner)
-
异常生成数据机制(Synthetic Anomaly Generator)
并围绕这些模块设计了三类任务,使模型能够完成从检测、定位到交互解释的全过程。
2. 模块详解
(1)图像编码器(CLIP Vision Encoder)
-
输入:工业图像(正常或模拟异常图像)
-
输出:图像的高层视觉特征
-
模型结构:使用 CLIP 的视觉编码器(如 ViT-L/14)作为图像特征提取主干
-
作用:为 LLaVA 模型提供图像语义表示输入
注意:此部分与标准 LLaVA 保持一致,是其视觉感知部分。
(2)图像解码器(Image Decoder)
-
目的:补强 LLaVA 在小尺度、细粒度异常上的感知能力
-
结构:加入一个轻量的 UNet 解码结构【3】,对 CLIP 提取的中间图层特征进行上采样
-
输出:像素级特征图,用于异常定位任务
-
用法:特征图可视化后与异常热图对齐,用于训练中的定位监督或推理时可解释性输出
(3)Prompt Learner 模块
-
功能:为不同任务动态生成文字 Prompt 向量,引导 LLaVA 正确理解任务
-
形式:
-
对每个任务(如判断异常、定位异常、问原因)学习一个 Prompt 向量嵌入
-
该 Prompt 与文本输入拼接,作为 LLM 的初始上下文
-
-
目的:让模型具备“条件理解能力”,不同 Prompt 引导不同任务模式
例如:
Prompt 1:这个图像中是否存在异常?
Prompt 2:异常出现在哪个位置?
Prompt 3:是什么导致了异常?
(4)异常数据生成器(Synthetic Anomaly Generator)
-
问题:真实工业异常样本极度稀缺
-
解决方案:从仅有的正常样本中自动构造异常数据(图像+描述文本)
-
方法:
-
在正常图像中加入扰动/伪造异常区域(如局部颜色变化、缺陷模拟)
-
同时生成对应的异常描述文本,如“图像左下角存在划痕”
-
-
用途:
-
构造训练样本(图像 + 文本)
-
提高模型对异常的对齐理解能力
-
3. 训练任务设计
论文中引入了三个训练任务,用于全面训练模型的不同能力:
任务1:图像-文本匹配(ITM)
-
目标:判断图像和文本描述是否匹配(是否为异常)
-
监督信号:二分类标签(匹配 / 不匹配)
任务2:异常分类任务(Anomaly Classification)
-
目标:多分类判断异常类型(如划痕、断裂、污染等)
-
监督信号:异常类别标签
任务3:异常定位任务(Anomaly Localization)
-
目标:输出异常的像素位置(分割图)
-
监督信号:异常热图(通过伪标签或图像解码器监督)
这三类任务共同训练,使模型具备“判断 + 解释 + 定位”全链能力。
4. 推理过程(Inference Pipeline)
推理阶段使用标准的多轮对话形式实现以下功能:
输入:工业图像(无标签) 流程: 1. 用户输入问题(或系统自动触发):"这张图像有没有异常?" 2. 模型根据 Prompt + 图像特征回答:有/没有 3. 若有异常,用户继续追问:"异常在哪里?",模型输出热图或文字定位 4. 用户进一步追问:"为什么出现这个异常?",模型基于上下文输出可能原因描述
整个过程无需阈值,无需手工后处理,支持交互式可解释分析。
5. 核心优势总结
| 能力 | 实现方式 | 优势 |
|---|---|---|
| 图像判断 | ITM + Prompt | 无需阈值,直接 Yes/No |
| 像素定位 | 解码器 + 热图训练 | 可视化区域定位 |
| 原因解释 | 多轮VQA | 增强可解释性 |
| 小样本学习 | In-context Few-shot | 仅需1张正常图即可工作 |
名词解释
【1】大型视觉语言模型 LLaVA-1.5
LLaVA-1.5(Large Language-and-Vision Assistant 1.5)是一个多模态的大型预训练模型,由微软研究院、威斯康星大学麦迪逊分校以及哥伦比亚大学的研究人员共同开发。它是在LLaVA的基础上进行改进和发展而来的一个版本,旨在提升多模态理解和生成能力。
LLaVA-1.5的核心组成部分
-
视觉模型:使用了在大规模数据上预先训练好的CLIP ViT-L/336px视觉模型,用于提取图像的特征表示。这使得模型能够理解并处理图像内容。
-
大语言模型:采用了拥有130亿参数的Vicuna v1.5作为语言模型部分,负责理解用户输入的文本内容,并具备强大的推理和生成能力。
-
视觉语言连接器:采用了一个双层的MLP(多层感知机)连接器来替代之前的线性投影,这样可以更有效地将视觉编码器输出的图像特征映射到大语言模型的词向量空间中,从而实现跨模态的信息融合。
主要改进点
- MLP cross-modal connector:增强了视觉与语言之间的信息传递效率。
- 结合学术相关的任务数据集:例如VQA(视觉问答),以增强模型在特定任务上的表现。
- 响应格式提示优化:解决了短文本回答与长文本回答之间的兼容问题,提高了指令跟随的表现。
【2】IAD任务
IAD任务,即工业异常检测(Industrial Anomaly Detection),是指在工业环境中识别产品或生产过程中出现的异常情况的任务。这种异常可能包括但不限于表面缺陷、结构损伤、功能失效等。IAD的目标是通过自动化的方法及时发现这些异常,以确保产品质量,提高生产效率,并减少因故障导致的成本和风险。
IAD任务的关键要素
-
数据收集:通常涉及到从生产线上的传感器、摄像头或其他监测设备中收集大量数据。这些数据可以是图像、视频流、声学信号、温度读数等多种形式。
-
特征提取与选择:从原始数据中提取有用的特征,以便后续分析使用。这一步骤对于区分正常与异常样本至关重要。例如,在图像处理中,可能会提取边缘、纹理或者颜色信息作为特征。
-
模型训练:利用历史数据集来训练模型,使其能够学习到正常状态下的模式以及如何区分异常。常用的模型包括传统的机器学习算法如支持向量机(SVM)、随机森林(RF),以及深度学习方法如卷积神经网络(CNN)。
-
异常检测:基于训练好的模型对新数据进行实时监控,判断是否存在异常。常见的做法是为每个样本计算一个异常分数,如果分数超过预设阈值,则认为该样本存在异常。
-
结果解释与可视化:为了便于理解和采取行动,还需要将检测结果以直观的方式呈现出来,比如标注出图像中的具体异常位置,给出详细的描述等。
-
反馈机制:建立有效的反馈回路,让系统能够根据实际操作中的反馈不断改进自身的性能。
IAD当前存在的问题
- 复杂性与多样性:工业环境中的异常种类繁多且形态各异,增加了准确检测的难度。
- 数据不平衡问题:正常样本往往远多于异常样本,这对训练模型提出了额外的要求(个人认为最难攻克的问题,当前看了十多篇论文,一半是在这里下功夫)。
- 实时性要求高:特别是在高速流水线作业中,需要快速响应以避免大规模损失。
- 成本控制:既要保证高精度,又要考虑部署成本,寻找性价比最优的解决方案。
【3】U-Net的解码结构
U-Net的解码结构与编码结构对称,用于逐步恢复特征图的空间分辨率,同时结合来自编码器的高分辨率特征信息来生成精确的分割结果。
解码器(Decoder)结构
-
上采样层(Upsampling Layer):
- 在每个解码阶段开始时,通过转置卷积(也称为反卷积或deconvolution)或最近邻插值等方法进行上采样操作,将特征图的尺寸翻倍。
- 上采样的目的是逐渐恢复原始输入图像的空间分辨率。
-
跳跃连接(Skip Connections):
- U-Net的一个关键创新就是引入了跳跃连接,这些连接将编码器中对应层级的特征图直接传递给解码器中的相应层级。
- 这些连接允许解码器利用编码器中保留的高分辨率细节信息,从而有助于提高分割精度,特别是在边界区域。
-
特征拼接(Concatenation of Features):
- 上采样后的特征图会与编码器中对应层的特征图在通道维度上进行拼接(而不是相加),这增加了特征的丰富性,并帮助模型更好地定位目标对象。
- 拼接后的特征图包含了更丰富的空间信息,有助于细化分割结果。
-
双卷积层(Double Convolution Layers):
- 在完成特征拼接后,通常会应用两个连续的3x3卷积层(每次卷积后跟一个ReLU激活函数),进一步处理和提取组合后的特征图的信息。
- 这些卷积层有助于捕捉更高层次的语义信息,并减少可能的伪影(artifacts)。
-
输出层(Output Layer):
- 最终,在解码器的最后一层,使用1x1卷积层将特征图映射到所需的类别数目的通道数,以得到最终的分割掩码。
- 根据任务的不同,可以使用Sigmoid激活函数(对于二分类问题)或者Softmax激活函数(对于多分类问题)来获得每个像素点属于各个类别的概率分布。



















 3611
3611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











