







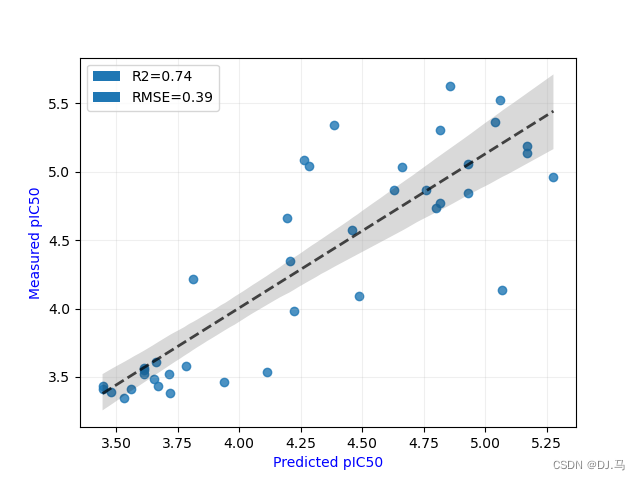
图中的灰色部分代表了预测pIC50值与实测pIC50值之间的95%置信区间(confidence interval)。这个区间提供了一个预测误差的范围,意味着在统计上,我们有95%的把握认为真实值会落在这个区间内。具体来说,这个置信区间围绕着最佳拟合线(图中的虚线)而形成,显示了数据点在预测模型中的分散程度。简而言之,这个区间展示了模型预测的不确定性。
栋哥说就是置信区间,不是软间隔。是sns这个函数默认的95%
关于灰色条带越宽越好还是越窄越好的问题:
理论上,置信区间的宽度取决于数据点的分散程度和预测的准确性:
-
置信区间越窄:通常意味着预测的不确定性更小。如果实验数据的变异性低(即数据点紧密地围绕最佳拟合线分布),置信区间会比较窄,这表明模型的预测对于新的、未知的数据点是比较可靠的。
-
置信区间越宽:意味着不确定性较高。如果数据点分散(即远离最佳拟合线),置信区间会变宽。这表明模型的预测存在更大的不确定性,对于新的数据点可能不那么可靠。
在实际应用中,我们通常希望置信区间尽可能窄,这样预测的准确性和可靠性就更高。然而,置信区间的宽度也受样本大小和变异性的影响,有时候较宽的置信区间可能是因为样本本身的固有变异性较大,而不一定是模型预测不准确。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











