









WGAN-div
论文Wasserstein Divergence for GANs提出了WGAN-div,主要是针对 1-Lipschitz 问题提出了一种新的解决方案.论文中实验结果是要比WGAN-GP要好的.
以下代码的超参数是根据论文中的写的,但模型并不是.
论文中使用的是ResNet模型
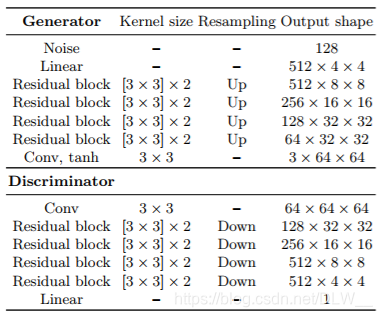
本文中用的是普通的卷积网络模型
#! -*- coding: utf-8 -*-
# wgan-div
import msvcrt
import time
import numpy as np
from scipy import misc
import glob
import imageio
from keras.models import Model
from keras.layers import *
import tensorflow as tf
from keras import backend as K
import keras.backend.tensorflow_backend as KTF
from keras.initializers import RandomNormal
from keras.optimizers import Adam
import os
# 手动分配GPU
config = tf.ConfigProto()
config.gpu_options.allow_growth = True # 不全部占满显存, 按需分配
sess = tf.Session(config=config) # 设置session
KTF.set_session(sess)
if not os.path.exists('samples'):
os.mkdir('samples')
img_dim = 96
z_dim = 100
num_layers = int(np.log2(img_dim)) - 3
max_num_channels = img_dim * 8
f_size = img_dim // 2**(num_layers + 1)
batch_size = 64
# 判别器
x_in = Input(shape=(img_dim, img_dim, 3))
x = x_in
for i in range(num_layers + 1):
num_channels = max_num_channels // 2**(num_layers - i)
x = Conv2D(num_channels,
(5, 5),
strides=(2, 2),
use_bias=False,
padding='same',
kernel_initializer=RandomNormal(stddev=0.02))(x)
if i > 0:
x = BatchNormalization()(x)
x = LeakyReLU(0.2)(x)
x = GlobalAveragePooling2D()(x)
x = Dense(1, use_bias=False)(x)
d_model = Model(x_in, x)
d_model.summary()
# 生成器
z_in = Input(shape=(z_dim, ))
z = z_in
z = Dense(f_size**2 * max_num_channels,
kernel_initializer=RandomNormal(stddev=0.02))(z)
z = BatchNormalization()(z)
z = Activation('relu')(z)
z = Reshape((f_size, f_size, max_num_channels))(z)
for i in range(num_layers):
num_channels = max_num_channels // 2**(i + 1)
z = Conv2DTranspose(num_channels,
(5, 5),
strides=(2, 2),
padding='same',
kernel_initializer=RandomNormal(stddev=0.02))(z)
z = BatchNormalization()(z)
z = Activation('relu')(z)
z = Conv2DTranspose(3,
(5, 5),
strides=(2, 2),
padding='same',
kernel_initializer=RandomNormal(stddev=0.02))(z)
z = Activation('tanh')(z)
g_model = Model(z_in, z)
g_model.summary()
# 整合模型(训练判别器)
x_in = Input(shape=(img_dim, img_dim, 3))
z_in = Input(shape=(z_dim, ))
g_model.trainable = False
x_real = x_in
x_fake = g_model(z_in)
x_real_score = d_model(x_real)
x_fake_score = d_model(x_fake)
d_train_model = Model([x_in, z_in],
[x_real_score, x_fake_score])
k = 2
p = 6
d_loss = K.mean(x_real_score - x_fake_score)
real_grad = K.gradients(x_real_score, [x_real])[0]
fake_grad = K.gradients(x_fake_score, [x_fake])[0]
real_grad_norm = K.sum(real_grad**2, axis=[1, 2, 3])**(p / 2)
fake_grad_norm = K.sum(fake_grad**2, axis=[1, 2, 3])**(p / 2)
grad_loss = K.mean(real_grad_norm + fake_grad_norm) * k / 2
w_dist = K.mean(x_fake_score - x_real_score)
d_train_model.add_loss(d_loss + grad_loss)
d_train_model.compile(optimizer=Adam(2e-4, 0.5))
d_train_model.metrics_names.append('w_dist')
d_train_model.metrics_tensors.append(w_dist)
# 整合模型(训练生成器)
g_model.trainable = True
d_model.trainable = False
x_fake = g_model(z_in)
x_fake_score = d_model(x_fake)
g_train_model = Model(z_in, x_fake_score)
g_loss = K.mean(x_fake_score)
g_train_model.add_loss(g_loss)
g_train_model.compile(optimizer=Adam(2e-4, 0.5))
# 检查模型结构
d_train_model.summary()
g_train_model.summary()
# 采样函数
def sample(path):
n = 9
figure = np.zeros((img_dim * n, img_dim * n, 3))
for i in range(n):
for j in range(n):
z_sample = np.random.randn(1, z_dim)
x_sample = g_model.predict(z_sample)
digit = x_sample[0]
figure[i * img_dim:(i + 1) * img_dim,
j * img_dim:(j + 1) * img_dim] = digit
figure = (figure + 1) * 127.5
figure = np.round(figure, 0).astype(int)
imageio.imwrite(path, figure)
iters_per_sample = 100
total_iter = 1000000
print('正在加载数据...')
# shape=(500000,96,96,3),已调整到(-1,1)
img = np.load('./faces5m96s.npy')
def run():
# 断点继续
if os.path.exists('./g_train_model.weights'):
g_train_model.load_weights('./g_train_model.weights')
history = np.load('./history.npy', allow_pickle=True).tolist()
last_iter = int(history[-1][0])
print('CONTINUE:last save iter:%d' % (last_iter))
else:
print('START')
history = []
last_iter = -1
# 开始计时
last_time = time.clock()
for i in range(last_iter + 1, total_iter):
# 按q退出
while msvcrt.kbhit():
char = ord(msvcrt.getch())
if char == 113:
print('QUIT:last save iter:%d' % (last_iter))
return history
for j in range(1):
z_sample = np.random.randn(batch_size, z_dim)
rand_idx = np.random.randint(0, img.shape[0], batch_size)
real_img = img[rand_idx]
d_loss = d_train_model.train_on_batch(
[real_img, z_sample], None)
for j in range(1):
z_sample = np.random.randn(batch_size, z_dim)
g_loss = g_train_model.train_on_batch(z_sample, None)
if i % 10 == 0:
print('iter: %s, d_loss: %s, g_loss: %s' % (i, d_loss, g_loss))
if i % iters_per_sample == 0:
# 样本与模型
sample('samples/test_%s.png' % i)
g_train_model.save_weights('./g_train_model.weights')
# 历史
history.append([i, d_loss, g_loss])
np.save('./history.npy', history)
# 计时
print('interval run %d s, total run %d s' % (time.clock() - last_time, time.clock()))
last_time = time.clock()
last_iter = i
print('FINISH:last save iter:%d' % (last_iter))
return history
由于手边刚好有二次元人物头像数据集,于是用来做二次元人物头像生成,效果如下
1k iter

5k iter

1w iter

5w iter

10w iter

16w iter

训练过程中,w距离缓慢增长,g_loss逐渐升高.
速度平均120s/100iter
16w iter共跑了我大概两天两夜(用的GTX1060,感觉我的GPU没配置好,怪慢的)
训练到最后也没有出现越练画的越差的情况,估计跑久一点效果还能更好.
改进 1
1(主要改进).使用论文原文提到的 Deep residual learning for image recognition 设计模型
2.根据 Deconvolution and Checkerboard Artifacts 使用 UpSampling2D+Conv2D 代替 Conv2DTranspose 以消除棋盘伪影
#! -*- coding: utf-8 -*-
# wgan-div
import msvcrt
import time
import numpy as np
from scipy import misc
import glob
import imageio
from keras.models import Model
from keras.layers import *
import tensorflow as tf
from keras import backend as K
import keras.backend.tensorflow_backend as KTF
from keras.initializers import RandomNormal
from keras.optimizers import Adam
import os
# 手动分配GPU
config = tf.ConfigProto()
config.gpu_options.allow_growth = True # 不全部占满显存, 按需分配
sess = tf.Session(config=config) # 设置session
KTF.set_session(sess)
if not os.path.exists('samples'):
os.mkdir('samples')
img_dim = 96
z_dim = 100
num_layers = int(np.log2(img_dim)) - 3
max_num_channels = img_dim * 8
f_size = img_dim // 2 ** (num_layers + 1)
weight_decay = 1e-4
batch_size = 64
def ResBlock(x, num_filters, resampling=None, kernel_size=3):
def BatchActivation(x):
x = BatchNormalization(momentum=0.9, epsilon=1e-5)(x)
x = Activation('relu')(x)
return x
def Conv(x, resampling=resampling):
if resampling is None:
x = Conv2D(num_filters, kernel_size=kernel_size, padding='same',
kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(x)
elif resampling == 'up':
x = UpSampling2D()(x)
x = Conv2D(num_filters, kernel_size=kernel_size, padding='same',
kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(x)
elif resampling == 'down':
x = Conv2D(num_filters, kernel_size=kernel_size, strides=2, padding='same',
kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(x)
return x
a = BatchActivation(x)
y = Conv(a, resampling=resampling)
y = BatchActivation(y)
y = Conv(y, resampling=None)
if resampling is not None:
x = Conv(a, resampling=resampling)
return add([y, x])
# 判别器
x_in = Input(shape=(img_dim, img_dim, 3))
x = x_in
for i in range(num_layers + 1):
num_channels = max_num_channels // 2 ** (num_layers - i)
if i > 0:
x = ResBlock(x, num_channels, resampling='down')
else:
x = Conv2D(num_channels, kernel_size=3, strides=2, padding='same',
kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(x)
x = BatchNormalization(momentum=0.9, epsilon=1e-5)(x)
x = Activation('relu')(x)
x = GlobalAveragePooling2D()(x)
x = Dense(1)(x)
d_model = Model(x_in, x)
d_model.summary()
# 生成器
z_in = Input(shape=(z_dim,))
z = z_in
z = Dense(f_size ** 2 * max_num_channels,
kernel_initializer="he_normal")(z)
z = Reshape((f_size, f_size, max_num_channels))(z)
for i in range(num_layers):
num_channels = max_num_channels // 2 ** (i + 1)
z = ResBlock(z, num_channels, resampling='up')
z = BatchNormalization()(z)
z = Activation('relu')(z)
z = UpSampling2D()(z)
z = Conv2D(3, kernel_size=3, padding='same',
kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(z)
z = Activation('tanh')(z)
g_model = Model(z_in, z)
g_model.summary()
# 整合模型(训练判别器)
x_in = Input(shape=(img_dim, img_dim, 3))
z_in = Input(shape=(z_dim,))
g_model.trainable = False
x_real = x_in
x_fake = g_model(z_in)
x_real_score = d_model(x_real)
x_fake_score = d_model(x_fake)
d_train_model = Model([x_in, z_in],
[x_real_score, x_fake_score])
k = 2
p = 6
d_loss = K.mean(x_real_score - x_fake_score)
real_grad = K.gradients(x_real_score, [x_real])[0]
fake_grad = K.gradients(x_fake_score, [x_fake])[0]
real_grad_norm = K.sum(real_grad ** 2, axis=[1, 2, 3]) ** (p / 2)
fake_grad_norm = K.sum(fake_grad ** 2, axis=[1, 2, 3]) ** (p / 2)
grad_loss = K.mean(real_grad_norm + fake_grad_norm) * k / 2
w_dist = K.mean(x_fake_score - x_real_score)
d_train_model.add_loss(d_loss + grad_loss)
d_train_model.compile(optimizer=Adam(2e-4, 0.5))
d_train_model.metrics_names.append('w_dist')
d_train_model.metrics_tensors.append(w_dist)
# 整合模型(训练生成器)
g_model.trainable = True
d_model.trainable = False
x_fake = g_model(z_in)
x_fake_score = d_model(x_fake)
g_train_model = Model(z_in, x_fake_score)
g_loss = K.mean(x_fake_score)
g_train_model.add_loss(g_loss)
g_train_model.compile(optimizer=Adam(2e-4, 0.5))
# 检查模型结构
d_train_model.summary()
g_train_model.summary()
# 采样函数
def sample(path):
n = 9
figure = np.zeros((img_dim * n, img_dim * n, 3))
for i in range(n):
for j in range(n):
z_sample = np.random.randn(1, z_dim)
x_sample = g_model.predict(z_sample)
digit = x_sample[0]
figure[i * img_dim:(i + 1) * img_dim,
j * img_dim:(j + 1) * img_dim] = digit
figure = (figure + 1) * 127.5
figure = np.round(figure, 0).astype(int)
imageio.imwrite(path, figure)
iters_per_sample = 100
total_iter = 1000000
print('正在加载数据...')
img = np.load('./faces5m96s.npy')
def run():
# 断点继续
if os.path.exists('./g_train_model.weights'):
g_train_model.load_weights('./g_train_model.weights')
history = np.load('./history.npy', allow_pickle=True).tolist()
last_iter = int(history[-1][0])
print('CONTINUE:last save iter:%d' % (last_iter))
else:
print('START')
history = []
last_iter = -1
# 开始计时
last_time = time.clock()
for i in range(last_iter + 1, total_iter):
# 按q退出
while msvcrt.kbhit():
char = ord(msvcrt.getch())
if char == 113:
print('QUIT:last save iter:%d' % (last_iter))
return history
for j in range(1):
z_sample = np.random.randn(batch_size, z_dim)
rand_idx = np.random.randint(0, img.shape[0], batch_size)
real_img = img[rand_idx]
d_loss = d_train_model.train_on_batch(
[real_img, z_sample], None)
for j in range(1):
z_sample = np.random.randn(batch_size, z_dim)
g_loss = g_train_model.train_on_batch(z_sample, None)
if i % 10 == 0:
print('iter: %s, d_loss: %s, g_loss: %s' % (i, d_loss, g_loss))
if i % iters_per_sample == 0:
# 样本与模型
sample('samples/test_%s.png' % i)
g_train_model.save_weights('./g_train_model.weights')
# 历史
history.append([i, d_loss, g_loss])
np.save('./history.npy', history)
# 计时
print('interval run %d s, total run %d s' % (time.clock() - last_time, time.clock()))
last_time = time.clock()
last_iter = i
print('FINISH:last save iter:%d' % (last_iter))
return history
1k iter

5k iter

1w iter

2w iter

3w iter

5w iter

7w iter

10w iter

训练曲线:
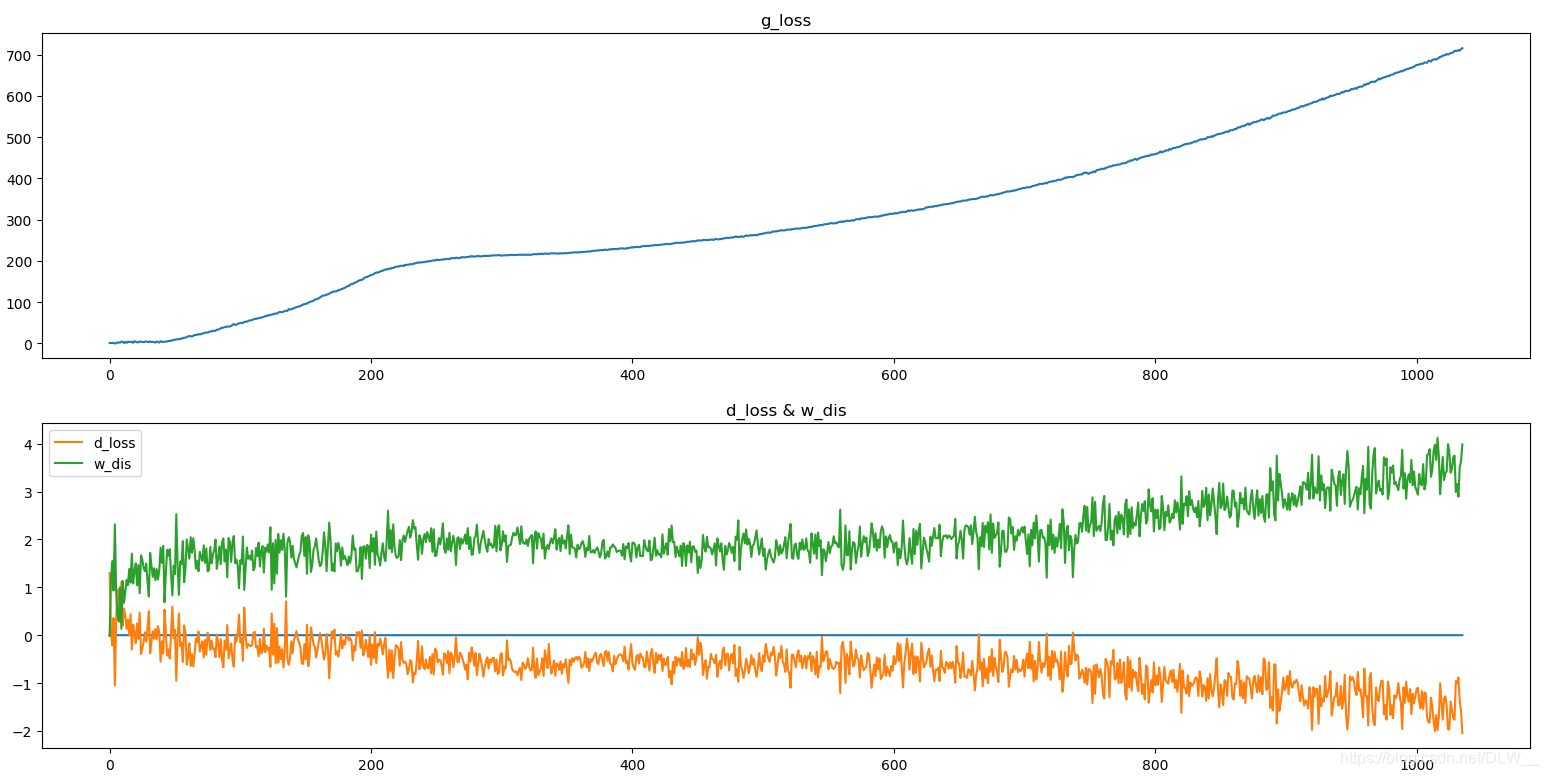
训练速度比没用Res的要慢(毕竟模型大了)大概180s/100iter
但是效果要比之前的好,可见在5w iter的情况下质量已经比原来训练16w iter的效果要好了.
改进 2
从磁盘动态加载图片,优化图片加载流程.
可以根据显存大小更改max_num_channels以改变网络宽度.
#! -*- coding: utf-8 -*-
# wgan-div
import msvcrt
import time
import threading
from queue import Queue
import numpy as np
from scipy import misc
import glob
import imageio
import keras
from keras.models import Model
from keras.layers import *
import tensorflow as tf
from keras import backend as K
import keras.backend.tensorflow_backend as KTF
import matplotlib.pyplot as plt
from keras.initializers import RandomNormal
from keras.optimizers import Adam
import os
from keras.preprocessing.image import ImageDataGenerator
# 动态分配GPU
# config = tf.ConfigProto()
# config.gpu_options.allow_growth = True # 不全部占满显存, 按需分配
# sess = tf.Session(config=config) # 设置session
# KTF.set_session(sess)
keras.backend.clear_session()
if not os.path.exists('samples'):
os.mkdir('samples')
img_dim = 512
z_dim = 100
num_layers = int(np.log2(img_dim)) - 3
max_num_channels = img_dim * 1 # 8
f_size = img_dim // 2 ** (num_layers + 1)
weight_decay = 1e-4
batch_size = 16
kernel_size = 3
def ResBlock(x, num_filters, resampling=None, kernel_size=kernel_size):
def BatchActivation(x):
x = BatchNormalization(momentum=0.9, epsilon=1e-5)(x)
x = Activation('relu')(x)
return x
def Conv(x, resampling=resampling):
if resampling is None:
x = Conv2D(num_filters, kernel_size=kernel_size, padding='same',
kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(x)
elif resampling == 'up':
x = UpSampling2D()(x)
x = Conv2D(num_filters, kernel_size=kernel_size, padding='same',
kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(x)
elif resampling == 'down':
x = Conv2D(num_filters, kernel_size=kernel_size, strides=2, padding='same',
kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(x)
return x
a = BatchActivation(x)
a = Conv(a, resampling=resampling)
y = BatchActivation(a)
y = Conv(y, resampling=None)
if resampling is not None:
x = a
return add([y, x])
print('正在构建模型...')
# 判别器
x_in = Input(shape=(img_dim, img_dim, 3))
x = x_in
for i in range(num_layers + 1):
num_channels = max_num_channels // 2 ** (num_layers - i)
if i > 0:
x = ResBlock(x, num_channels, resampling='down')
else:
x = Conv2D(num_channels, kernel_size=kernel_size, strides=2, padding='same',
kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(x)
x = BatchNormalization(momentum=0.9, epsilon=1e-5)(x)
x = Activation('relu')(x)
x = GlobalAveragePooling2D()(x)
x = Dense(1)(x)
d_model = Model(x_in, x)
d_model.summary()
# 生成器
z_in = Input(shape=(z_dim,))
z = z_in
z = Dense(f_size ** 2 * max_num_channels,
kernel_initializer="he_normal")(z)
z = Reshape((f_size, f_size, max_num_channels))(z)
for i in range(num_layers):
num_channels = max_num_channels // 2 ** (i + 1)
z = ResBlock(z, num_channels, resampling='up')
z = BatchNormalization()(z)
z = Activation('relu')(z)
z = UpSampling2D()(z)
z = Conv2D(3, kernel_size=kernel_size, padding='same',
kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(z)
z = Activation('tanh')(z)
g_model = Model(z_in, z)
g_model.summary()
# 整合模型(训练判别器)
x_in = Input(shape=(img_dim, img_dim, 3))
z_in = Input(shape=(z_dim,))
g_model.trainable = False
x_real = x_in
x_fake = g_model(z_in)
x_real_score = d_model(x_real)
x_fake_score = d_model(x_fake)
d_train_model = Model([x_in, z_in],
[x_real_score, x_fake_score])
k = 2
p = 6
d_loss = K.mean(x_real_score - x_fake_score)
real_grad = K.gradients(x_real_score, [x_real])[0]
fake_grad = K.gradients(x_fake_score, [x_fake])[0]
real_grad_norm = K.sum(real_grad ** 2, axis=[1, 2, 3]) ** (p / 2)
fake_grad_norm = K.sum(fake_grad ** 2, axis=[1, 2, 3]) ** (p / 2)
grad_loss = K.mean(real_grad_norm + fake_grad_norm) * k / 2
w_dist = K.mean(x_fake_score - x_real_score)
d_train_model.add_loss(d_loss + grad_loss)
d_train_model.compile(optimizer=Adam(2e-4, 0.5))
d_train_model.metrics_names.append('w_dist')
d_train_model.metrics_tensors.append(w_dist)
# 整合模型(训练生成器)
g_model.trainable = True
d_model.trainable = False
x_fake = g_model(z_in)
x_fake_score = d_model(x_fake)
g_train_model = Model(z_in, x_fake_score)
g_loss = K.mean(x_fake_score)
g_train_model.add_loss(g_loss)
g_train_model.compile(optimizer=Adam(2e-4, 0.5))
# 检查模型结构
d_train_model.summary()
g_train_model.summary()
# 采样函数
def sample(path):
n = 5
figure = np.zeros((img_dim * n, img_dim * n, 3))
for i in range(n):
for j in range(n):
z_sample = np.random.randn(1, z_dim)
x_sample = g_model.predict(z_sample)
digit = x_sample[0]
figure[i * img_dim:(i + 1) * img_dim, j * img_dim:(j + 1) * img_dim] = digit
figure = (figure + 1) * 127.5
figure = np.round(figure, 0).astype(int)
imageio.imwrite(path, figure)
def show_history():
a = np.load('history.npy', allow_pickle=True)
b = []
for i in range(a.shape[0]):
b.append(a[:, 1][i])
b = np.array(b)
plt.subplot(2, 1, 1)
plt.title('g_loss')
plt.plot(a[:, 2])
plt.subplot(2, 1, 2)
plt.title('d_loss & w_dis')
plt.plot(np.zeros(a.shape[0]))
plt.plot(b[:, 0], label='d_loss')
plt.plot(b[:, 1], label='w_dis')
plt.legend(loc='upper left')
plt.show()
# 采样间隔
iters_per_sample = 1000
total_iter = 1000000
print('正在配置数据集...')
# *************** ImageDataGenerator *************** #
dataset_dir = r'C:\dataset\faces'
# 图片处理函数
def img_process(image):
return image / 127.5 - 1
# 训练集数据增强
data = ImageDataGenerator(preprocessing_function=img_process).flow_from_directory(
dataset_dir,
target_size=(img_dim, img_dim),
batch_size=batch_size,
class_mode=None)
# 数据队列
data_queue = Queue(maxsize=10)
# 数据加载线程
class DataTread(threading.Thread):
def __init__(self):
super().__init__()
self.exitFlag = 0
def run(self):
while not self.exitFlag:
if data_queue.full():
time.sleep(0.1)
else:
data_queue.put(next(data))
def run():
# 断点继续
if os.path.exists('./g_train_model.weights'):
print('正在加载模型...')
g_train_model.load_weights('./g_train_model.weights')
history = np.load('./history.npy', allow_pickle=True).tolist()
last_iter = int(history[-1][0])
print('CONTINUE:last save iter:%d' % (last_iter))
else:
print('START')
history = []
last_iter = -1
# 开始计时
last_time = time.clock()
# 创建数据加载线程
data_thread = DataTread()
data_thread.start()
for i in range(last_iter + 1, total_iter):
# 按q退出
while msvcrt.kbhit():
char = ord(msvcrt.getch())
if char == 113:
# 停止数据加载线程
data_thread.exitFlag = 1
data_thread.join()
print('QUIT:last save iter:%d' % (last_iter))
return history
# 训练判别器
for j in range(1):
z_sample = np.random.randn(batch_size, z_dim)
real_img = data_queue.get()
d_loss = d_train_model.train_on_batch(
[real_img, z_sample], None)
# 训练生成器
for j in range(1):
z_sample = np.random.randn(batch_size, z_dim)
g_loss = g_train_model.train_on_batch(z_sample, None)
if i % 10 == 0:
print('iter: %s, d_loss: %s, g_loss: %s' % (i, d_loss, g_loss))
if i % iters_per_sample == 0:
# 样本与模型
sample('samples/test_%s.png' % i)
g_train_model.save_weights('./g_train_model.weights')
# 历史
history.append([i, d_loss, g_loss])
np.save('./history.npy', history)
# 计时
print('interval run %d s, total run %d s' % (time.clock() - last_time, time.clock()))
last_time = time.clock()
last_iter = i
print('FINISH:last save iter:%d' % (last_iter))
return history
history = run()















 579
579











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









