







 本文介绍了自编码器(Auto-Encoder,AE)的基本概念和应用,包括如何通过编码器和解码器进行信息压缩与重建,并讨论了深度自编码器在图像降噪和小样本学习中的作用。接着,深入探讨了变分自编码器(VariationalAuto-Encoder,VAE)的生成能力,解释了为什么VAE能生成新样本,以及其背后的数学原理,包括全概率公式、变分推理和KL散度损失。此外,还提到了条件VAE(CVAE)和VQ-VAE的相关内容。
本文介绍了自编码器(Auto-Encoder,AE)的基本概念和应用,包括如何通过编码器和解码器进行信息压缩与重建,并讨论了深度自编码器在图像降噪和小样本学习中的作用。接着,深入探讨了变分自编码器(VariationalAuto-Encoder,VAE)的生成能力,解释了为什么VAE能生成新样本,以及其背后的数学原理,包括全概率公式、变分推理和KL散度损失。此外,还提到了条件VAE(CVAE)和VQ-VAE的相关内容。
一、Auto-Encoder (AE)
1)Auto-encoder概念
自编码器要做的事:将高维的信息通过encoder压缩到一个低维的code内,然后再使用decoder对其进行重建。“自”不是自动,而是自己训练[1],即无监督学习。
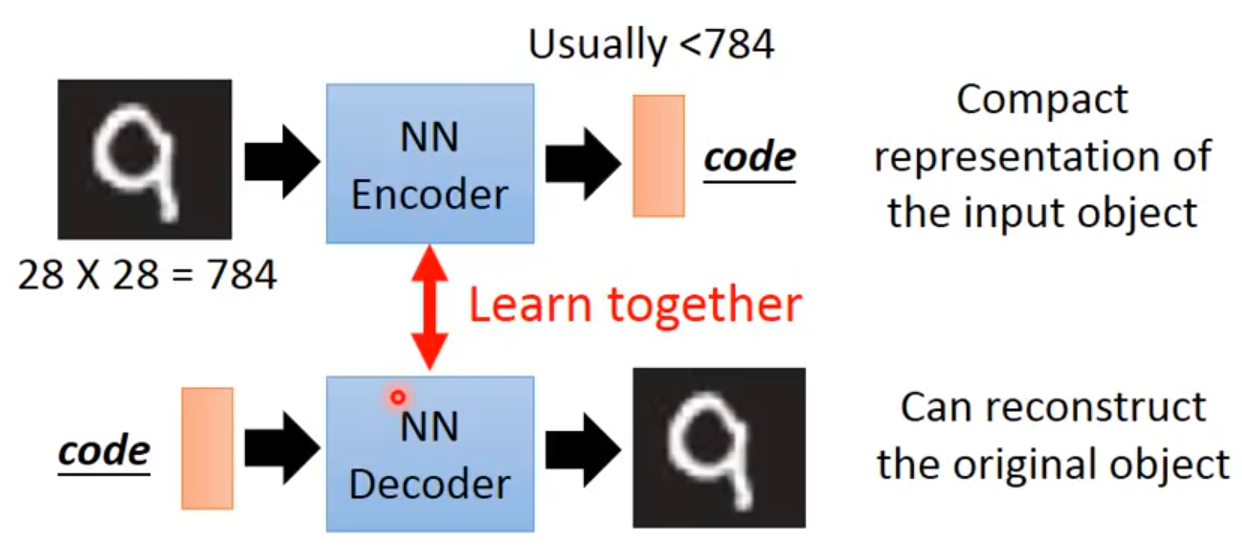
PCA要做的事其实与AE一样,只是没有神经网络。对于一个输入x,PCA通过一个转换矩阵W将x转换为c,因为是线性的过程,就可以再通过WT将其转换为x^,目的是使x和x^尽可能一致。而AE要做的就是,在这样一个过程中,将PCA的转换矩阵W,WT换成encoder和decoder。
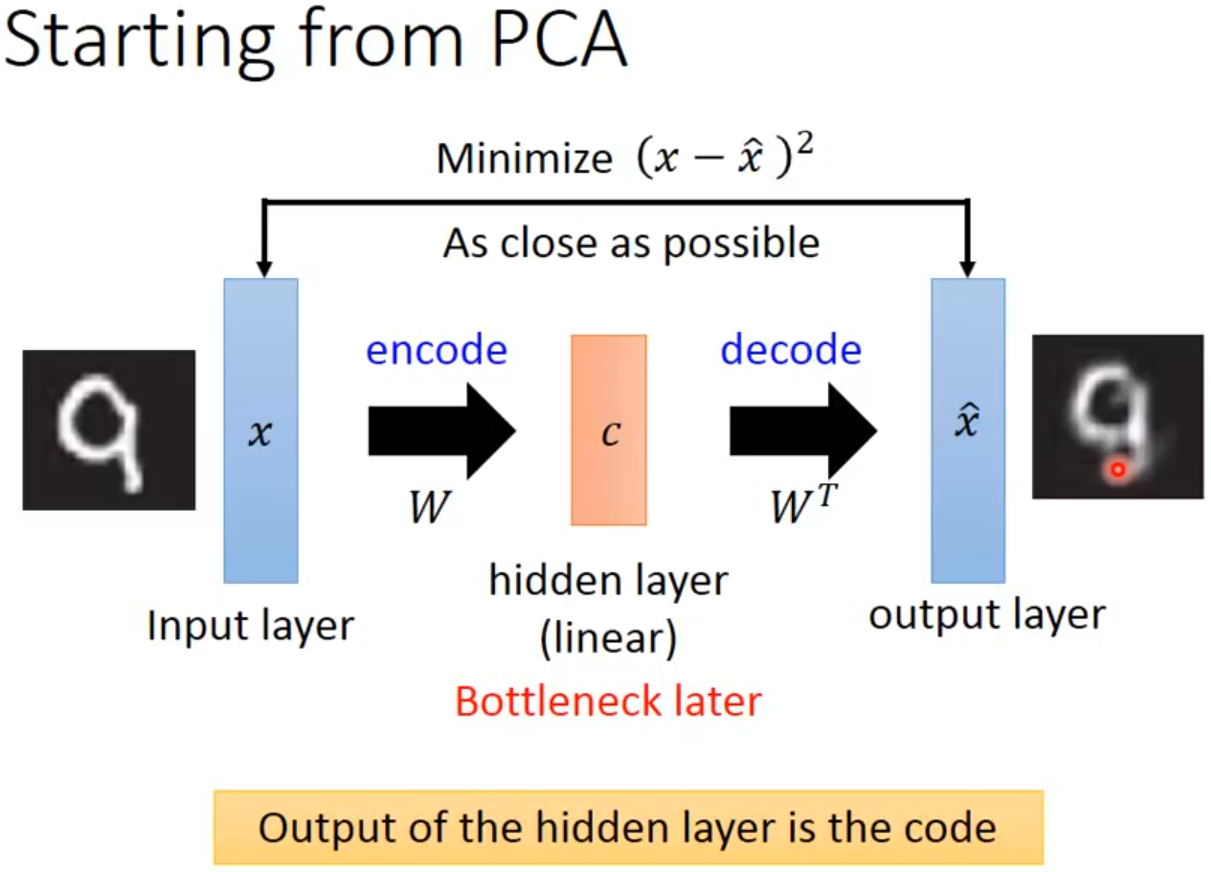
在这样一个过程中,将input layer, bottleneck, output layer 换做深度神经网络,就变成了deep auto-encoder,最开始由hinton 在2006年提出,这一替换的明显好处是,引入了神经网络强大的拟合能力,使得编码(Code)的维度能够比原始图像(X)的维度低非常多。
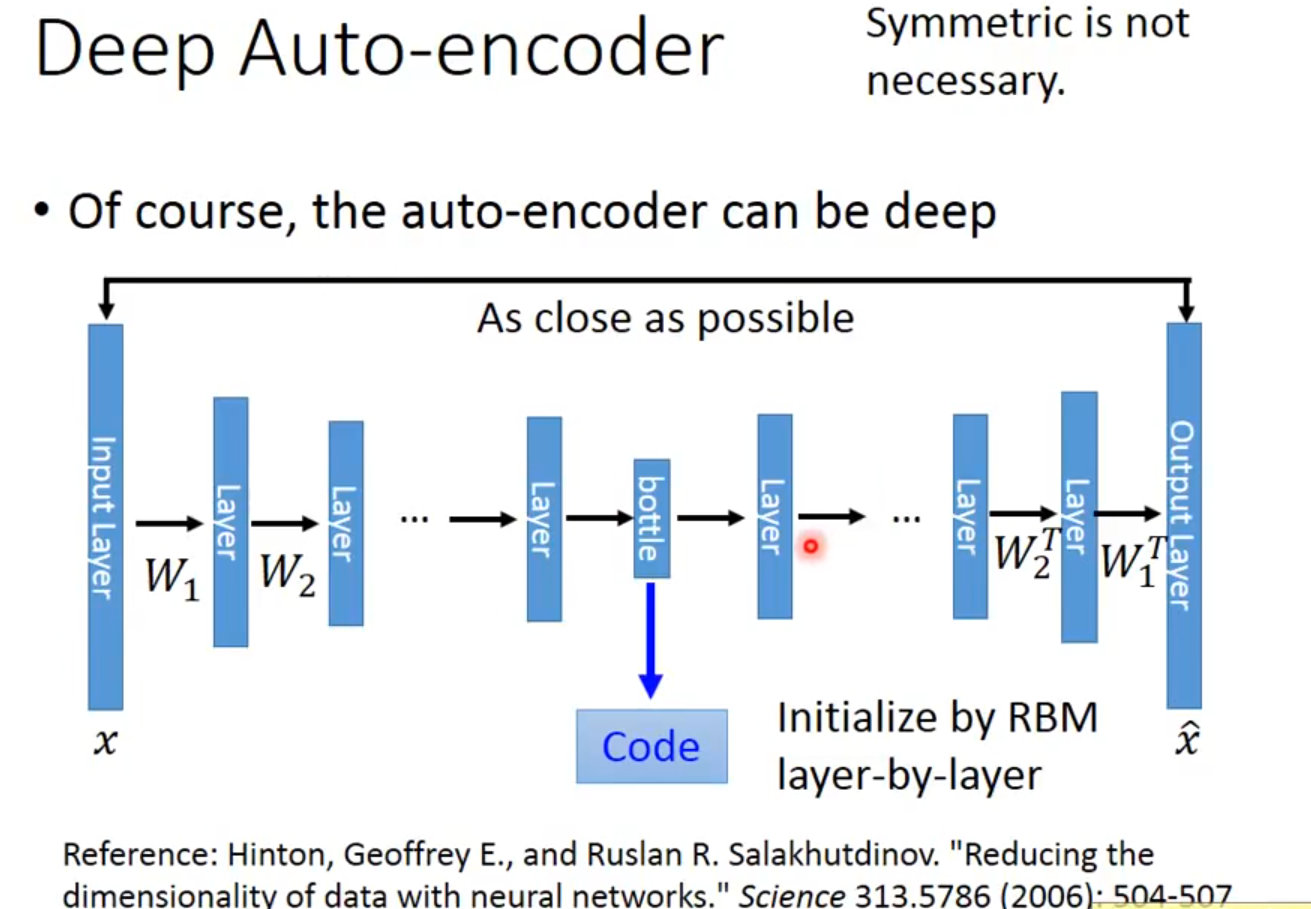
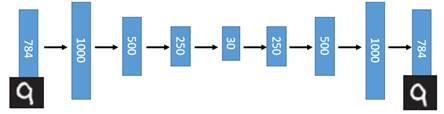
在一个手写数字图像的生成模型中,这样的一个简单的Deep Auto-Encoder模型能够把一个784维的向量(28*28图像)压缩到只有30维,并且解码回的图像具备清楚的辨认度(如下图)[2]。
2)Auto-encoder的应用
Auto-encoder可以用于解决小样本学习,预训练 DNN:当labeled data比较少的时候,对前几层网络进行合适的initialization是有必要的(目的就是找到比较好的特征),这是可以先用 unlabelled data 使用AE技术分别train并fix W1,W2,W3,最后只需要使用label data训练W4即可。如果是分类任务,就是先使用AE技术以无监督学习的方式预训练好编码器部分,目的是使得提取的初始特征比较好,然后在最后加上一个检测头(全连接)来预测类别,使用少量标签数据以有监督的方式去微调即可。
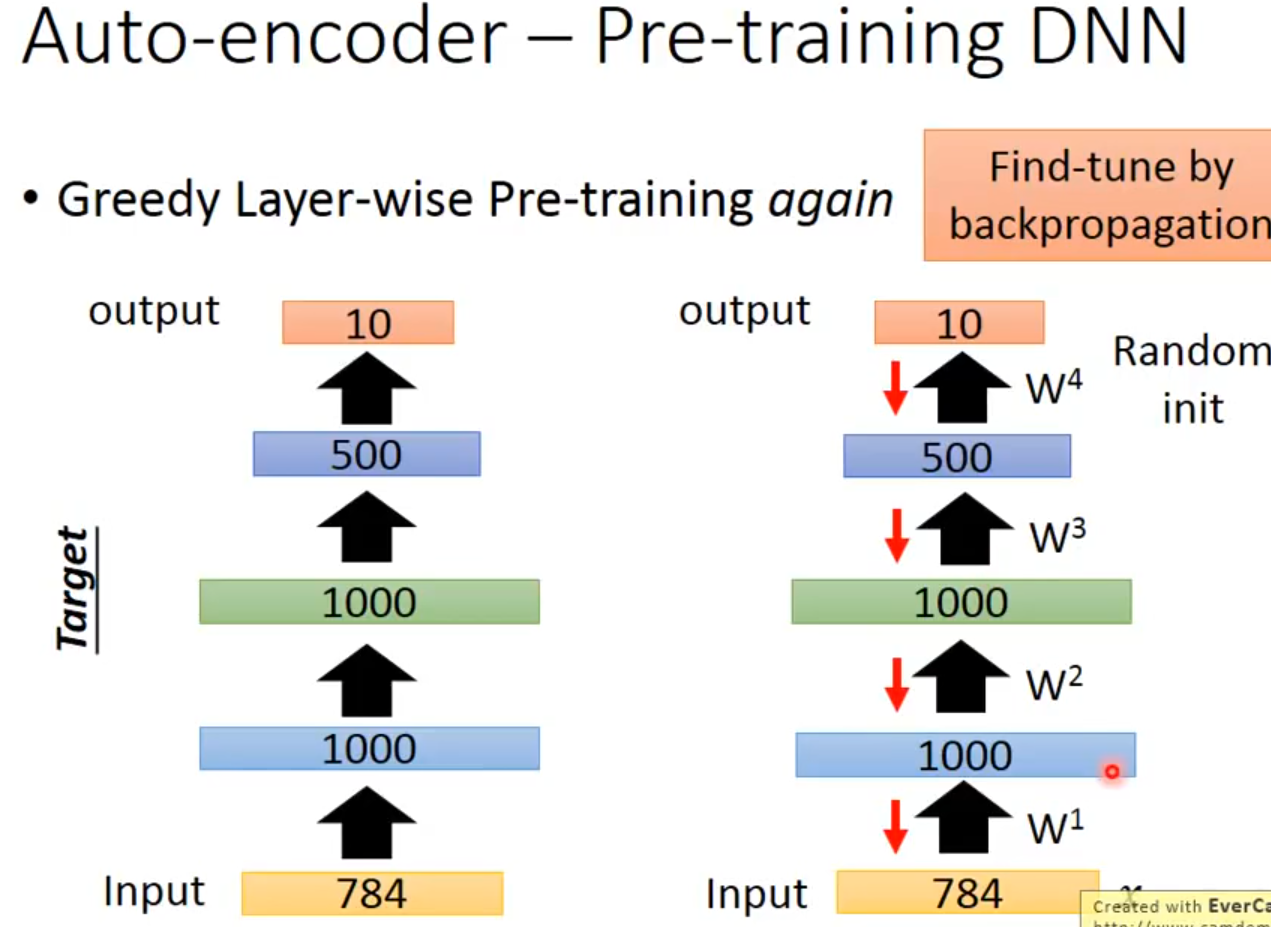
但是以上这种思路是较早之前的做法,近些年来在逐渐开源了一些大规模预训练模型,上述的效果不如直接在这些模型(比如VGG)上去做微调。
在判别模型,比如说分类任务,最重要的是找特征,而且是找到有判别的特征。
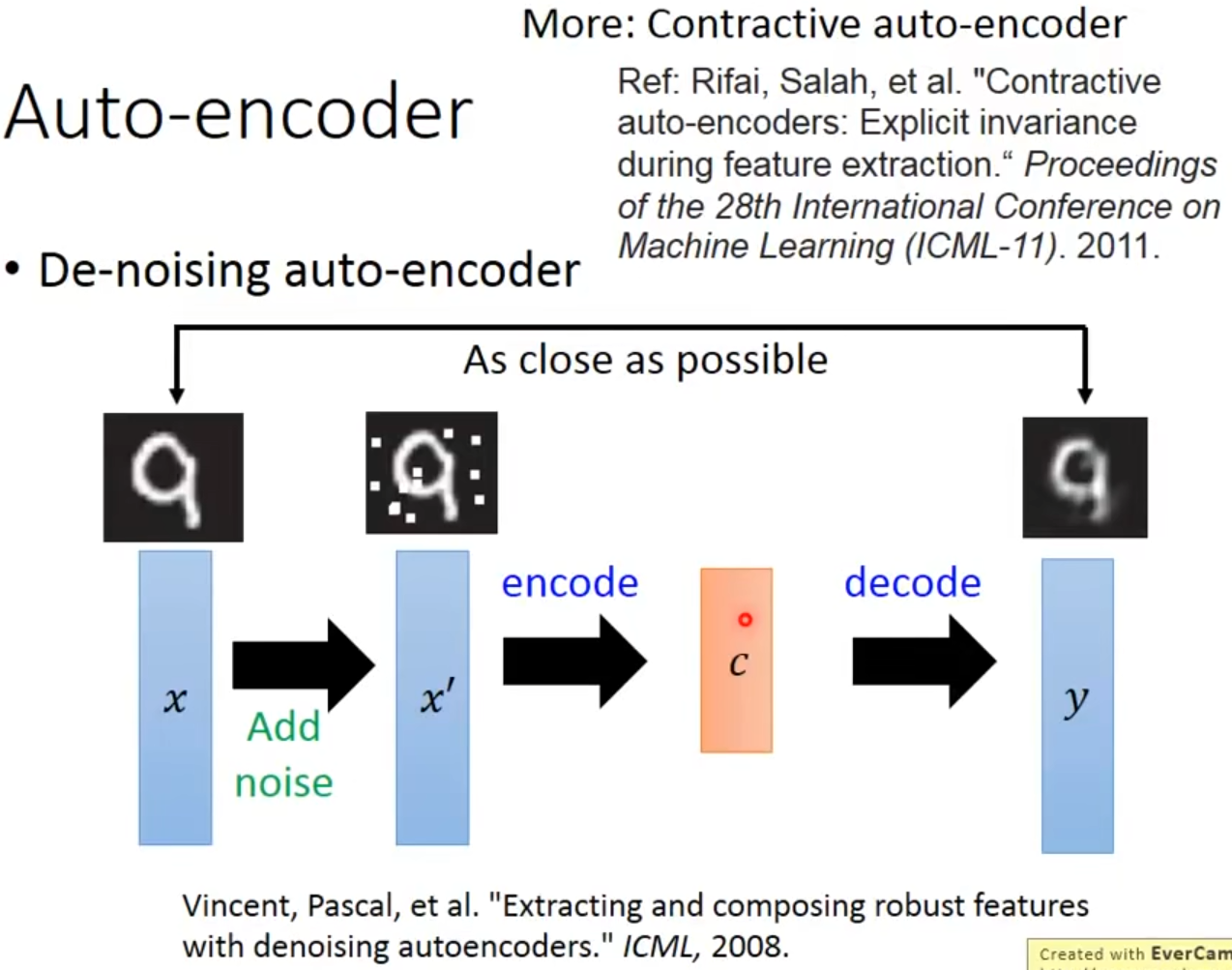
Auto-encoder还可以用来降噪:首先加噪,然后进行AE,目的是使网络不仅可以重构,还可以过滤其中的noise。这种方法叫做DAE,过程如下。
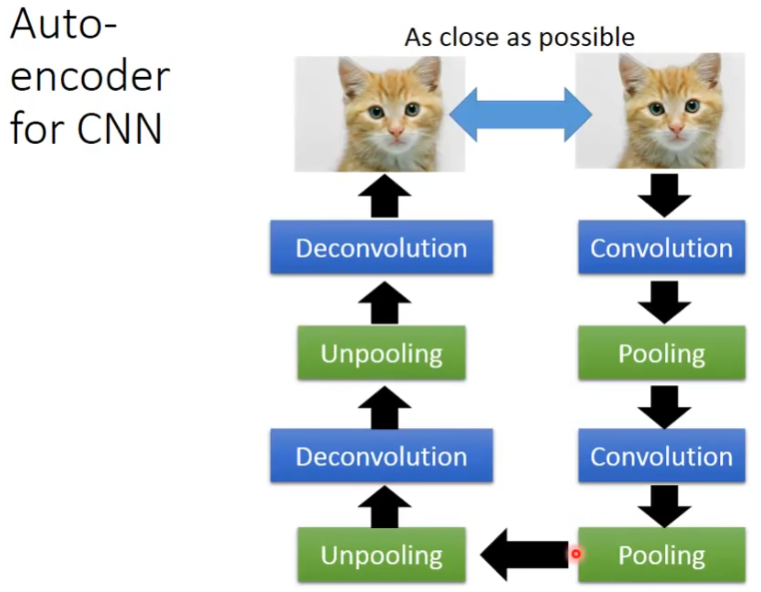
3)Auto-encoder for CNN
在CNN中应用auto-encoder,主要是先使用convolution和pooling降维,然后再使用deconvolution和unpooling升维。deconvolution叫做逆卷积,也是一个卷积操作,其对feature map恢复的原理核心就是(k-1-p)扩展(padding),详细可以阅读:Deconvolution(逆卷积)。unpooling与upsampling还是有点区别,unpooling是在CNN中常用的来表示max pooling的逆操作,简单来说,记住做max pooling的时候的最大item的位置,比如一个3x3的矩阵,max pooling的size为2x2,stride为1,反卷积记住其位置,unpooling的操作就是让其余位置至为0就行。
参考:
[1] https://www.bilibili.com/video/av15889450/?p=33
[2] http://www.gwylab.com/note-vae.html
二、Variational Auto-Encoder (VAE)
主成分分析(PCA)和自编码器(AutoEncoders, AE)是无监督学习中的两种代表性方法。两者都是非概率方法。
1)为什么会有VAE?
假设原始数据为一张人脸图像F,它有256*256个维度。AE的编码器将F编码为N维的隐变量z,z的每一维对应一个特征(比如表情、肤色、发型等),每一维上的值表示样本F在这种特征上的取值。也就是说,AE是将样本编码为N个固定的特征值,用单个特征值描述输入图像F在每个潜在特征上的表现,每个特征值在对应的特征空间下是一个离散值。
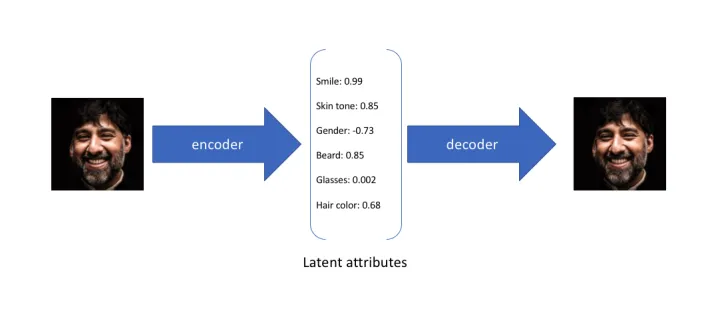
因为神经网络只能去做学习过的事情,所以AE的解码器,只能基于隐变量z中每个潜在特征(每一维)出现过的特征值去恢复图像。比如,AE只学习过"smile"的特征值为-9的恢复过程(decode),那碰到"smile"的特征值为-8时,AE的解码器是没有能力去恢复的。也就是说,在每一个特征空间中,对于训练过程中没有涵盖过的地方,AE的解码器没办法去decode。
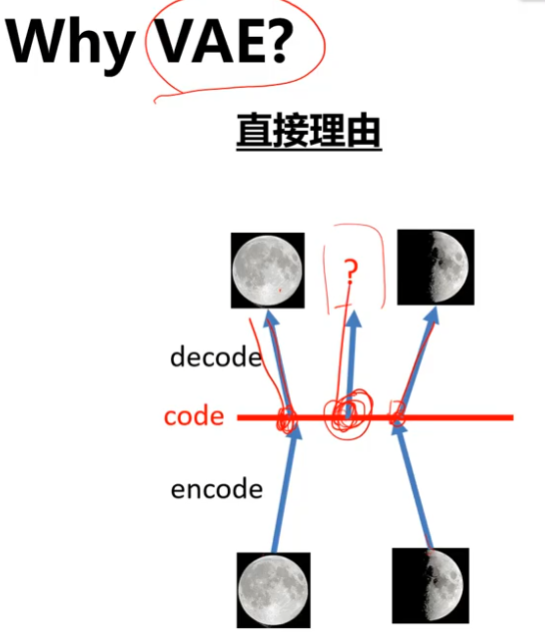
进一步的说,无论是AE,DAE,还是MAE,本质上都是学习bottleneck处的这个隐变量特征z,然后拿z去做目标检测、分割、分类等这些下游任务。但这样的方式不叫做生成,原因就是中间特征z是一个用于重建的固定特征,即使DAE或MAE等技术可以使得中间特征z的范围变大,这也只是让离散特征值的数量变多而已,他们是永远不可能占满整个特征空间的。当隐变量z是一个概率分布时,就可以touch到整个特征空间,这样就可以基于特征空间中的任何一个特征值来生成图像,这样才能称为真正的生成。
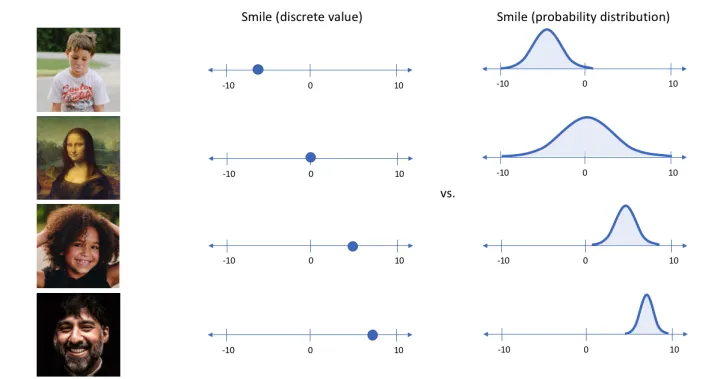
假如说我们中间学习的隐变量z不是一个特定值,而是一个分布(严谨来讲是一个联合分布,在每一个特征维度上学到的都是一个分布),那么经过训练后,解码器就会知道"面对学到的一个分布,应该生成什么样的图像",而之前的AE经过训练后,解码器知道的是"面对学到的一个特征值,应该生成什么样的图像"。"面对学到的一个分布,应该生成什么样的图像"这样能力的意思是:只要特征值属于这个分布,那么"解码器"就可以对它进行解码,这无疑极大地扩大了解码器的“知识范围”。那么当我们想生成样本的时候,只要给出一个这个分布下的特征值,解码器就会进行生成,当这个特征值是"见"过的时,生成的是老样本,当这个特征值是"没见"过的时,生成的就是新样本。
基于此,VAE应运而生,它在中间不再生成一个固定的编码特征,而是生成一个分布(高斯)。本质上是增大隐变量z在特征空间上的范围,从而使解码器能access整个特征空间,拥有真正的生成能力(对任意特征值都可生成)。
2)VAE如何实现“生成”?
数学约定:X表示样本的随机变量,x表示一个样本,Z表示潜特征的随机变量,z表示潜特征的一个值向量。X k、Z k表示随机变量X、Z的第k个样本 。
首先回顾生成模型的终极任务:从一批给定样本{X1,X2, ..., Xn}中,去得到整体X的分布p(X)。但是这个理想是很难实现的,所以就将p(X)改成如下形式,这里就是引入了全概率公式:
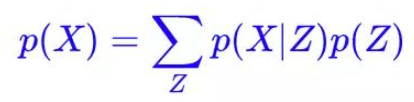
这里蕴含了VAE的核心思想:将预测复杂分布p(X)的问题(生成模型的核心问题),通过全概率公式转换为拟合分布p(X|Z)(解码器)的问题。
要实现上述思想,我们需要知道分布p(Z),这里我们可以将p(Z)分布设定成各种各样,因为无论p(Z)是什么样的分布都可以,上式都能成立。也就是说,我们把p(Z)看作是一个已知的先验分布,因为它不是我们的目标,我们的目标是求p(X|Z),它是一个由Z生成X的模型。VAE的核心也就是学习一个函数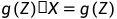 ,将分布Z变换为分布X,这里g(Z)就是p(X|Z)。
,将分布Z变换为分布X,这里g(Z)就是p(X|Z)。
为了方便生成,也就是方便“从分布p(Z)中采样生成一个值z,再用decoder对z解码”,我们需要保证在先验分布p(Z)中采样尽可能的简单。而我们常用的采样就是在标准高斯分布N(0,1)中采样,并且标准高斯分布也具有很好的性质,所以我们将先验分布p(Z)约束为一个标准高斯分布。
有了p(Z)后,那我们只需要训练出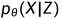 就可以得到p(X)了,其实就是decoder。但是这存在一个问题,如果用从p(Z)中采样出来的值来恢复所有样本{X1,X2,...,Xn},这样可能会混淆。因此,VAE为每个X构造一个专属的分布p(Z |Xk),那么从这个分布中采样出来的z,确实就是要还原到Xk中的。
就可以得到p(X)了,其实就是decoder。但是这存在一个问题,如果用从p(Z)中采样出来的值来恢复所有样本{X1,X2,...,Xn},这样可能会混淆。因此,VAE为每个X构造一个专属的分布p(Z |Xk),那么从这个分布中采样出来的z,确实就是要还原到Xk中的。
至此,VAE模型被分为两个部分:
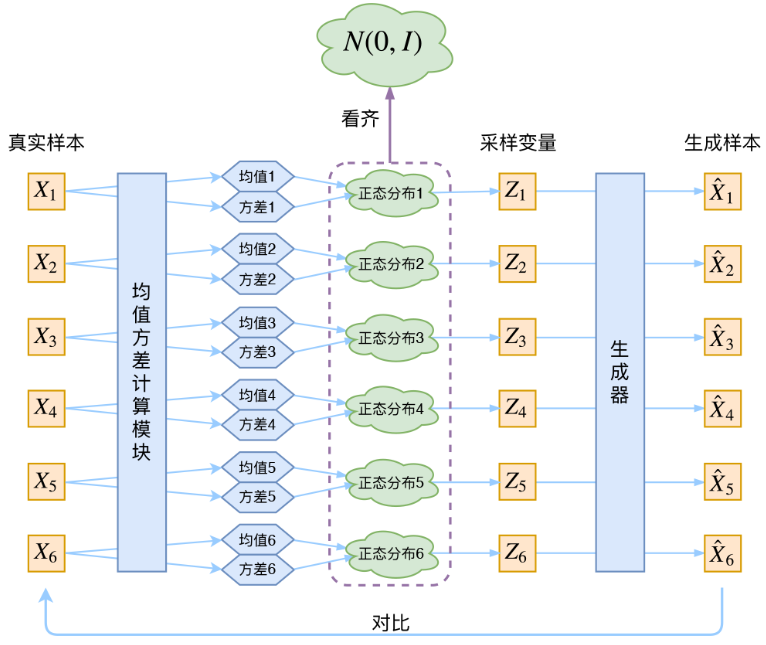
1)隐变量 Z 后验分布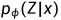 的近似推断过程,即推断网络。这一部分可以看作是AE中的“编码器部分”,只是目的从生成一个固定隐变量z,变为为每个样本的专属分布生成均值和方差;在代码中,对于一个输入图像Xk,encoder部分就是先将Xk输入一系列卷积层(每一层图像的尺寸减半,通道翻倍),再将卷积结果(假设维度为d)分别输入两个全连接预测"均值μ"、“方差对数log (σ^2)”(假设维度为d');
的近似推断过程,即推断网络。这一部分可以看作是AE中的“编码器部分”,只是目的从生成一个固定隐变量z,变为为每个样本的专属分布生成均值和方差;在代码中,对于一个输入图像Xk,encoder部分就是先将Xk输入一系列卷积层(每一层图像的尺寸减半,通道翻倍),再将卷积结果(假设维度为d)分别输入两个全连接预测"均值μ"、“方差对数log (σ^2)”(假设维度为d');
2)条件分布 的生成过程,即生成网络,这一部分可以看作是AE中的“解码器部分”。对于编码器生成的μ、log (σ^2),模型会先通过一个reparameterize模块采样出一个服从这样参数的分布的一个值z,这个模块既保证了梯度的传递又保证了采样的随机性。比如下图中,左边是没有reparameterize模块,右边是有,两个网络的前馈行为是相同的,但是反向传播只能用于右边的网络。重参数化后,隐变量采样值z才会被输入至解码器。在解码器中,对于输入的采样值z(维度为d'),首先会用一个全连接层将其维度反向投影为d,然后再用反卷积进行处理(每一层图像的尺寸翻倍,通道减半)。
的生成过程,即生成网络,这一部分可以看作是AE中的“解码器部分”。对于编码器生成的μ、log (σ^2),模型会先通过一个reparameterize模块采样出一个服从这样参数的分布的一个值z,这个模块既保证了梯度的传递又保证了采样的随机性。比如下图中,左边是没有reparameterize模块,右边是有,两个网络的前馈行为是相同的,但是反向传播只能用于右边的网络。重参数化后,隐变量采样值z才会被输入至解码器。在解码器中,对于输入的采样值z(维度为d'),首先会用一个全连接层将其维度反向投影为d,然后再用反卷积进行处理(每一层图像的尺寸翻倍,通道减半)。
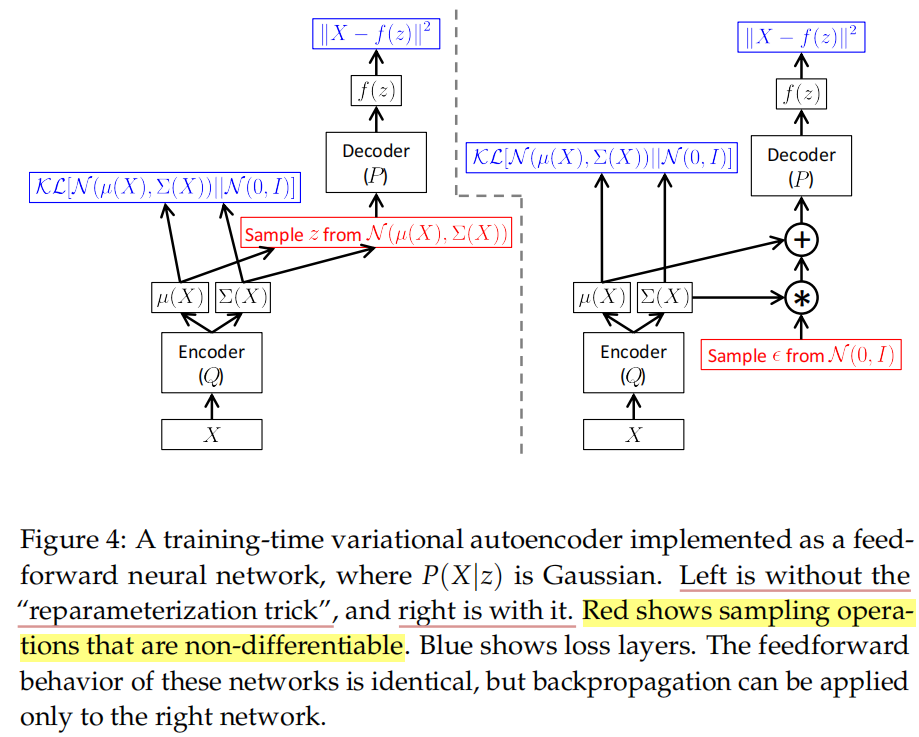
训练时,VAE具有两个损失:重构损失 & KL散度损失。原因分析:vae的中间特征Z是一个分布,在这个分布中采样得到一个值z再输入给编码器,而之前ae的特征是一个固定值z,因此vae中输入至解码器中的z值,可以看作是在ae中输入至解码器的固定z值上添加了一个方差为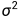 的噪声,这个噪声保证了模型具有生成能力(能够access到整个特征空间),但也会对解码器阶段的生成产生干扰。因此若只有重构损失,模型必然为了更好地重构而减小这个噪声的干扰,即让为分布q(Z|x)预测的方差变成0,这样的话中间特征z就变成了一个固定值,与ae 就没区别了,丧失了生成能力。所以为了避免这种情况,应保证q(Z|x)分布的方差不为0,所以对所有的q(Z|x)又加了一个KL散度来向N(0,I)看齐,这样就保证了模型具有生成能力。说白了,重构的过程是希望没噪声的,而KL loss则希望有高斯噪声的,两者是对立的。所以,VAE跟GAN一样,内部其实是包含了一个对抗的过程,只不过它们两者是混合起来,共同进化的。
的噪声,这个噪声保证了模型具有生成能力(能够access到整个特征空间),但也会对解码器阶段的生成产生干扰。因此若只有重构损失,模型必然为了更好地重构而减小这个噪声的干扰,即让为分布q(Z|x)预测的方差变成0,这样的话中间特征z就变成了一个固定值,与ae 就没区别了,丧失了生成能力。所以为了避免这种情况,应保证q(Z|x)分布的方差不为0,所以对所有的q(Z|x)又加了一个KL散度来向N(0,I)看齐,这样就保证了模型具有生成能力。说白了,重构的过程是希望没噪声的,而KL loss则希望有高斯噪声的,两者是对立的。所以,VAE跟GAN一样,内部其实是包含了一个对抗的过程,只不过它们两者是混合起来,共同进化的。
 损失计算结果如下,d是隐变量Z的维度:
损失计算结果如下,d是隐变量Z的维度:
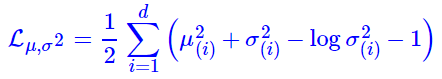
加上重构损失后,VAE的整体loss的负值如下,也就是要最大化下面这个公式:
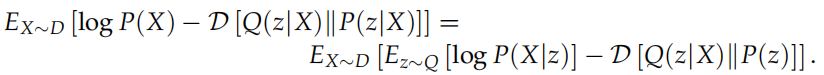
这个损失中的符号跟上图中一致,但可能与本文中其他地方的公式不一致,单独理解这个loss公式就好,能明白就行。P()表示的是解码器,Q()表示的是生成器,X~D中D表示训练集。log P(X|z)的含义是,最大化从采样值z生成X的概率,这是对解码器的要求。-D[Q(z|X)||P(z|X)]的含义是,最小化分布Q(z|X)与分布P(z|X)的差异,其中Q(z|X)就是解码器生成的分布(在本文其他地方写作q(Z|x)),P(z|X)就是P(z)~N(0, 1),因为当前的X已经给出了。
此外,若每一个p(Z |Xk)是标准正态分布,就可以有如下计算,这样就正好满足了我们的先验假设“p(Z)是标准高斯分布”,也就是实现了我们的最初目标:从标准高斯分布中采样来生成图像。
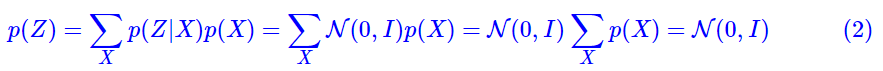
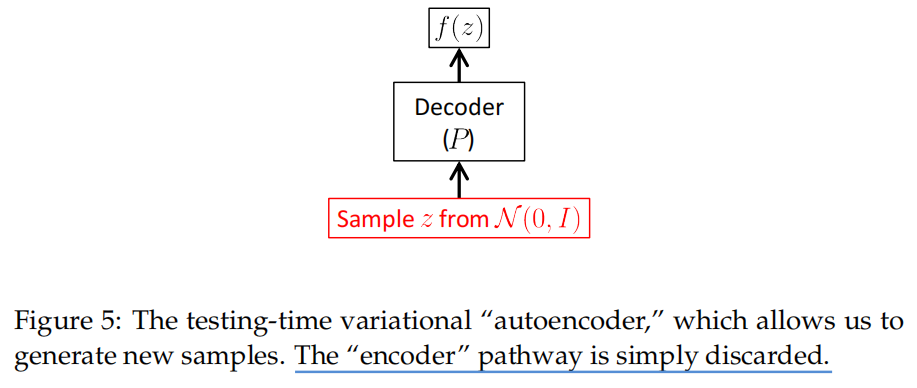
因此在随机生成图像时,我们是直接从标准高斯分布中随机采样(torch.randn),然后输入至解码器中生成样本的。
最后,贴一下项目AntixK / PyTorch-VAE中的vanilla_vae代码来方便学习:
import torch
from models import BaseVAE
from torch import nn
from torch.nn import functional as F
from .types_ import *
class VanillaVAE(BaseVAE):
def __init__(self,
in_channels: int,
latent_dim: int,
hidden_dims: List = None,
**kwargs) -> None:
super(VanillaVAE, self).__init__()
self.latent_dim = latent_dim
modules = []
if hidden_dims is None:
hidden_dims = [32, 64, 128, 256, 512]
# Build Encoder
for h_dim in hidden_dims:
modules.append(
nn.Sequential(
nn.Conv2d(in_channels, out_channels=h_dim,
kernel_size= 3, stride= 2, padding = 1),
nn.BatchNorm2d(h_dim),
nn.LeakyReLU())
)
in_channels = h_dim
self.encoder = nn.Sequential(*modules)
self.fc_mu = nn.Linear(hidden_dims[-1]*4, latent_dim)
self.fc_var = nn.Linear(hidden_dims[-1]*4, latent_dim)
# Build Decoder
modules = []
self.decoder_input = nn.Linear(latent_dim, hidden_dims[-1] * 4)
hidden_dims.reverse()
for i in range(len(hidden_dims) - 1):
modules.append(
nn.Sequential(
nn.ConvTranspose2d(hidden_dims[i],
hidden_dims[i + 1],
kernel_size=3,
stride = 2,
padding=1,
output_padding=1),
nn.BatchNorm2d(hidden_dims[i + 1]),
nn.LeakyReLU())
)
self.decoder = nn.Sequential(*modules)
self.final_layer = nn.Sequential(
nn.ConvTranspose2d(hidden_dims[-1],
hidden_dims[-1],
kernel_size=3,
stride=2,
padding=1,
output_padding=1),
nn.BatchNorm2d(hidden_dims[-1]),
nn.LeakyReLU(),
nn.Conv2d(hidden_dims[-1], out_channels= 3,
kernel_size= 3, padding= 1),
nn.Tanh())
def encode(self, input: Tensor) -> List[Tensor]:
"""
Encodes the input by passing through the encoder network
and returns the latent codes.
:param input: (Tensor) Input tensor to encoder [N x C x H x W]
:return: (Tensor) List of latent codes
"""
result = self.encoder(input)
result = torch.flatten(result, start_dim=1)
# Split the result into mu and var components
# of the latent Gaussian distribution
mu = self.fc_mu(result)
log_var = self.fc_var(result)
return [mu, log_var]
def decode(self, z: Tensor) -> Tensor:
"""
Maps the given latent codes
onto the image space.
:param z: (Tensor) [B x D]
:return: (Tensor) [B x C x H x W]
"""
result = self.decoder_input(z)
result = result.view(-1, 512, 2, 2)
result = self.decoder(result)
result = self.final_layer(result)
return result
def reparameterize(self, mu: Tensor, logvar: Tensor) -> Tensor:
"""
Reparameterization trick to sample from N(mu, var) from
N(0,1).
:param mu: (Tensor) Mean of the latent Gaussian [B x D]
:param logvar: (Tensor) Standard deviation of the latent Gaussian [B x D]
:return: (Tensor) [B x D]
"""
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return eps * std + mu
def forward(self, input: Tensor, **kwargs) -> List[Tensor]:
mu, log_var = self.encode(input)
z = self.reparameterize(mu, log_var)
return [self.decode(z), input, mu, log_var]
def loss_function(self,
*args,
**kwargs) -> dict:
"""
Computes the VAE loss function.
KL(N(\mu, \sigma), N(0, 1)) = \log \frac{1}{\sigma} + \frac{\sigma^2 + \mu^2}{2} - \frac{1}{2}
:param args:
:param kwargs:
:return:
"""
recons = args[0]
input = args[1]
mu = args[2]
log_var = args[3]
kld_weight = kwargs['M_N'] # Account for the minibatch samples from the dataset
recons_loss =F.mse_loss(recons, input)
kld_loss = torch.mean(-0.5 * torch.sum(1 + log_var - mu ** 2 - log_var.exp(), dim = 1), dim = 0)
loss = recons_loss + kld_weight * kld_loss
return {'loss': loss, 'Reconstruction_Loss':recons_loss.detach(), 'KLD':-kld_loss.detach()}
def sample(self,
num_samples:int,
current_device: int, **kwargs) -> Tensor:
"""
Samples from the latent space and return the corresponding
image space map.
:param num_samples: (Int) Number of samples
:param current_device: (Int) Device to run the model
:return: (Tensor)
"""
z = torch.randn(num_samples,
self.latent_dim)
z = z.to(current_device)
samples = self.decode(z)
return samples
def generate(self, x: Tensor, **kwargs) -> Tensor:
"""
Given an input image x, returns the reconstructed image
:param x: (Tensor) [B x C x H x W]
:return: (Tensor) [B x C x H x W]
"""
return self.forward(x)[0]3)从贝叶斯角度推导VAE(变分推理)
简单来说,由于直接描述复杂分布是难以做到的,所以VAE通过引入隐变量来将复杂分布变成条件分布的叠加,并对隐变量的分布和条件分布都可以做适当的简化(比如都假设为正态分布),并且在条件分布的参数可以跟深度学习模型结合起来(用深度学习来算隐变量的参数),至此,“深度概率图模型”就可见一斑了。
TODO:从最大似然到EM算法:一致的理解方式、用变分推断统一理解生成模型(VAE、GAN、AAE、ALI)、变分自编码器(三):这样做为什么能成?、
数学推导参看:变分自编码器(二):从贝叶斯观点出发、一文理解变分自编码器(VAE)
4)一些核心问题
为什么假设先验是正态分布?
给定一二阶矩, 正态分布的熵最大,即给定的先验信息最少,最随机,因此许多方法都假设先验是正态分布。
在VAE中,我们假设p(Z|X)为正态分布,是因为p(zΙx)这个真实的分布是不知道的,多半是一个奇奇怪怪的分布。但从推导过程上看,我们需要从这个分布中抽样,所以我们考虑用一个已知的分布形式去近似这个p(zΙx),然后就选择了用高斯分布去近似它。
虽然我们假设p(Z|X)为正态分布,但是最后得到的p(Z|X)不一定是正态分布:
在训练初期,重构loss很大,模型focus 在重构loss上,可能得到p(Z|X)为零方差。训练后期逐渐focus在KL散度(控制p(Z|X)和N(0,I)相近),但最终肯定是平衡了两个loss的。可以把这个KL的loss看做一个正则化项来理解,例如我们经常对参数做L1 正则化,但我们并不认为参数就一定全等于0。
对生成能力的理解?
生成能力指的是:对于潜在特征空间Z中每一个取值,解码器都有能力去解码。所以要想使模型具有生成能力,就要保证在训练时潜在特征z的值可以access到潜在特征空间Z的任何一个地方,即让潜在特征是一个覆盖全域的分布。
VAE中的“变分”体现在哪?
VAE的名字中“变分”,是因为它的推导过程用到了KL散度及其性质。
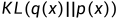 实际上是一个泛函,在数学上,要对泛函求极值就要用到变分法。或者说,KL散度的主要性质就是非负性,当且仅当q(x)=p(x)时KL散度为0,而这一点的推导需要用到变分法。VAE的推导中用到了KL散度的性质,因此包含了变分法,比如VAE的变分下界,是直接基于KL散度就得到的,详细的推导可以参看:一文理解变分自编码器(VAE)。在代码中,直接调用的是KL散度求损失,其实这一个操作内部就包含了“变分”的思想。
实际上是一个泛函,在数学上,要对泛函求极值就要用到变分法。或者说,KL散度的主要性质就是非负性,当且仅当q(x)=p(x)时KL散度为0,而这一点的推导需要用到变分法。VAE的推导中用到了KL散度的性质,因此包含了变分法,比如VAE的变分下界,是直接基于KL散度就得到的,详细的推导可以参看:一文理解变分自编码器(VAE)。在代码中,直接调用的是KL散度求损失,其实这一个操作内部就包含了“变分”的思想。
为什么要用KL散度衡量分布之间的差异?
度量两个概率分布之间的差异只有KL散度吗?当然不是,除此之外还有巴士距离等等。但是在这里我们还是用KL散度,因为KL散度可以写成期望的形式,这允许我们对其进行采样计算。
如何训练?
在训练时,对于一个样本x,我们会在其专属的分布q(Z|x)上采样出一个值z,再根据这个z来训练解码器p(X|Z)。那么问题来了,采样一个值究竟够了吗?事实上我们会运行多个epoch,每次的隐变量都是随机生成的,因此当epoch数足够多时,可以保证采样的充分性,即z会根据分布q(Z|x)占满整个特征空间。
为什么要预测方差对数log (σ^2),而不是方差σ^2本身?
这个要从关于KL散度的损失函数来进行分析,它的公式如下:
如果模型的预测是方差σ^2本身,则在计算损失函数时要去一次自然对数,这时假如预测的方差很小(≈0),loss就会趋于负无穷,就会出现梯度消失问题(nan)。因此这里直接预测方差的对数,这样即使再求方差σ^2时也不会出现上述的问题。总结:在神经网络中我们应该避免拟合要取对数的数,而是直接去拟合其对数运算结果。
5)对流形(manifold)的理解
先给出对流行的本质理解:流行是数据“从高维空间降维到低维空间,还不损失信息”的映射,数据在“流行空间”中的表示才是它的本质。
流形学习的观点是认为,我们所能观察到的数据实际上是由一个低维流形映射到高维空间上的。由于数据内部特征的限制,一些数据在高维中的表示会产生维度上的冗余,实际上只需要较低的维度就能唯一地表示。
我们观察到的一个数据,比如一个圆,它本身是一个二维数据,因为我们是在二维坐标空间下观察到它的,但是在二维坐标的表示空间中,只有圆上的点属于这个数据(比如(1,0)),除此之外二维坐标空间下还存在着成千上万的点,这些点是冗余的。因此就会想,如果能建立某一种描述方法,让这个描述方法所确定的所有点的集合都能在圆上,甚至能连续不间断地表示圆上的点,那就好了!那有没有呢?对于圆来讲,当然是有的,那就是极坐标。在极坐标的表示方法下,圆心在原点的圆,只需要一个参数就能确定:半径,也就是我们用一个维度就能表示在二维空间观察到的圆。对于这种现象,我们称之为:“圆是一个二维数据,但它本质是一个一维流形”。与之相似的,三维空间中一个球面,用x, y, z三个坐标轴确定时会产生冗余(很多在三维空间中的数据点并不在球面上)。但其实只需要用两个坐标就可以确定了,比如经度和维度。
与之相似的,三维空间中一个球面,用x, y, z三个坐标轴确定时会产生冗余(很多在三维空间中的数据点并不在球面上)。但其实只需要用两个坐标就可以确定了,比如经度和维度。也就是说,球面是一个三维数据,但它本质是一个二维流形。再举个例子,比如说下面这个经典的瑞士卷,我们观察到它是一个三维数据,但它本质就是一个二维流形。
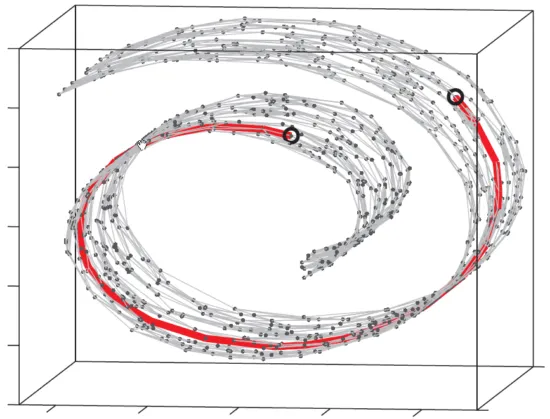
从英文的角度来理解:manifold=many fold。流行就是一个由多个部分欧式空间粘接而成的空间,它的每一个局部同胚于欧式空间的拓扑空间。两个空间同胚可以理解为两个空间是一个空间。因此对于一个流行,比如球面,在它的每一个局部都可以建立一个二维坐标系,跟二维欧式空间建立一个同胚。
仍以上图的瑞士卷为例,因为我们观察到它是一个三维数据,所以就非要用三维坐标系内的尺度去对它进行评价,这可能存在一些不合理,因为它本质上是一个二维流形。比如评价上图中画圈的两个点,在三维空间中,两点之间的距离非常近,但在该数据的内部构造下,也就是在该数据的流行空间下,两个点其实是离得非常远的(红色线)。对于上句话,有两个点需要理解:
对流行进行衡量,可以在流行空间下使用欧氏距离来衡量,因为它的每一个局部空间同胚于欧氏空间。但也只有在流行空间使用欧氏距离衡量才有意义,如果在其展开的高维空间下使用欧氏距离衡量将没有意义。
数据在“流行空间”中的表示才是它的本质。对于瑞士卷数据而言,我们将图中的三维空间称为“观测空间”或“展开空间”,因为低维流形一般是在高维空间中展开,然后才会被我们观察到。此外,我们将图中的二维空间称为“流行空间”。这几种空间只是为了方便理解的个人描述,如有不妥还请指正。
流行学习有什么用:
用于非线性降维。数据在高维空间(观测空间)有冗余,在低维空间(流行空间)没冗余。如上所述,数据在“流行空间”中的表示才是它的本质,因此如果对一个数据使用欧氏距离衡量,在其“流行空间”下进行才是有意义的。如果直接在其被观察到的高维空间下进行衡量,将忽略该数据的内部特征(比如瑞士卷形状的信息)。
流形能够刻画数据的本质。如开头所说,流行是一个“数据从高维空间降维到低维空间,还不损失信息”的映射。其实深度学习要做的本质上也是这样一个事情,深度学习主要的特点就是“特征学习”,而所谓特征,就是“能表示事物本质的内容”。也就是说深度学习就是要找到“能表示事物本质的内容”,这其实就是在找“事物”的“流行”。
了解了流行的概念后,再回过头来看VAE。
首先,需要明确的是,随机变量X所有潜特征的联合分布p(Z)其实就是随机变量X的流行空间,其中Z={z1,z2, ..., zn}。为方便表述,我们用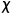 表示随机变量X的流行空间。其次,用流行的方式来分析AE和VAE的组件,它们encoder的作用都是找到流行空间中的值,decoder的作用都是基于某个流行空间中的值生成一个该流行对应的图像。
表示随机变量X的流行空间。其次,用流行的方式来分析AE和VAE的组件,它们encoder的作用都是找到流行空间中的值,decoder的作用都是基于某个流行空间中的值生成一个该流行对应的图像。
AE的encoder通过训练图像只找到了Z={z1,z2, ..., zn}中每一个潜变量zk的若干个离散值,这些离散值属于随机变量X的流行空间,但我们只知道这些离散值,并不知道该空间下其他的值,因此decoder只能基于这些离散值来生成图像,生成的图像也是这些离散值在该流行空间中对应的图像。当我们想做生成任务时,需要实现的是生成该流行空间对应的新图像,因此需要给decoder一个新的离散值它才能去生成,我们可以有很多方式获取一个新的离散值(随机生成一个数,或基于训练集的离散值做更新),但这个新的离散值绝大概率不会位于随机变量X的流行空间(当然可能处于其他流行上),因为流行所展开的高维空间太大了,流行只占据了非常小的部分,因此decoder基于新的离散值生成的图像大概率不属于随机变量X的流行对应的图像。所以,AE没办法做生成任务。
而VAE要找到的是Z={z1,z2, ..., zn}中每一个潜变量zk的分布,也就是找到潜特征的联合分布p(Z),而找到了联合分布p(Z)其实就是找到了随机变量X的流行空间。有了联合分布p(Z)后,我们可以从这个分布p(Z)中随意采样一个值z,这个值必然是属于流行空间的,那么将属于流行空间的这个值z输入至decoder中去生成的样本X',也必然是流行空间对应的样本。所以,VAE可以做生成任务。
参考:https://www.zhihu.com/question/24015486/answer/194284643
6)VAE vs. 高斯混合模型(GMM)
高斯混合模型(GMM)
对于生成模型而言,主流的理论模型可以分为隐马尔可夫模型HMM、朴素贝叶斯模型NB和高斯混合模型GMM,而VAE的理论基础就是高斯混合模型。高斯混合模型是指:任何一个数据的分布,都可以看作是若干高斯分布的叠加。
为什么要用正态分布?大部分部分其实并不符合正态分布,但是根据高斯混合模型可以得知,任何一个数据的分布,都可以看作是若干高斯分布的叠加。
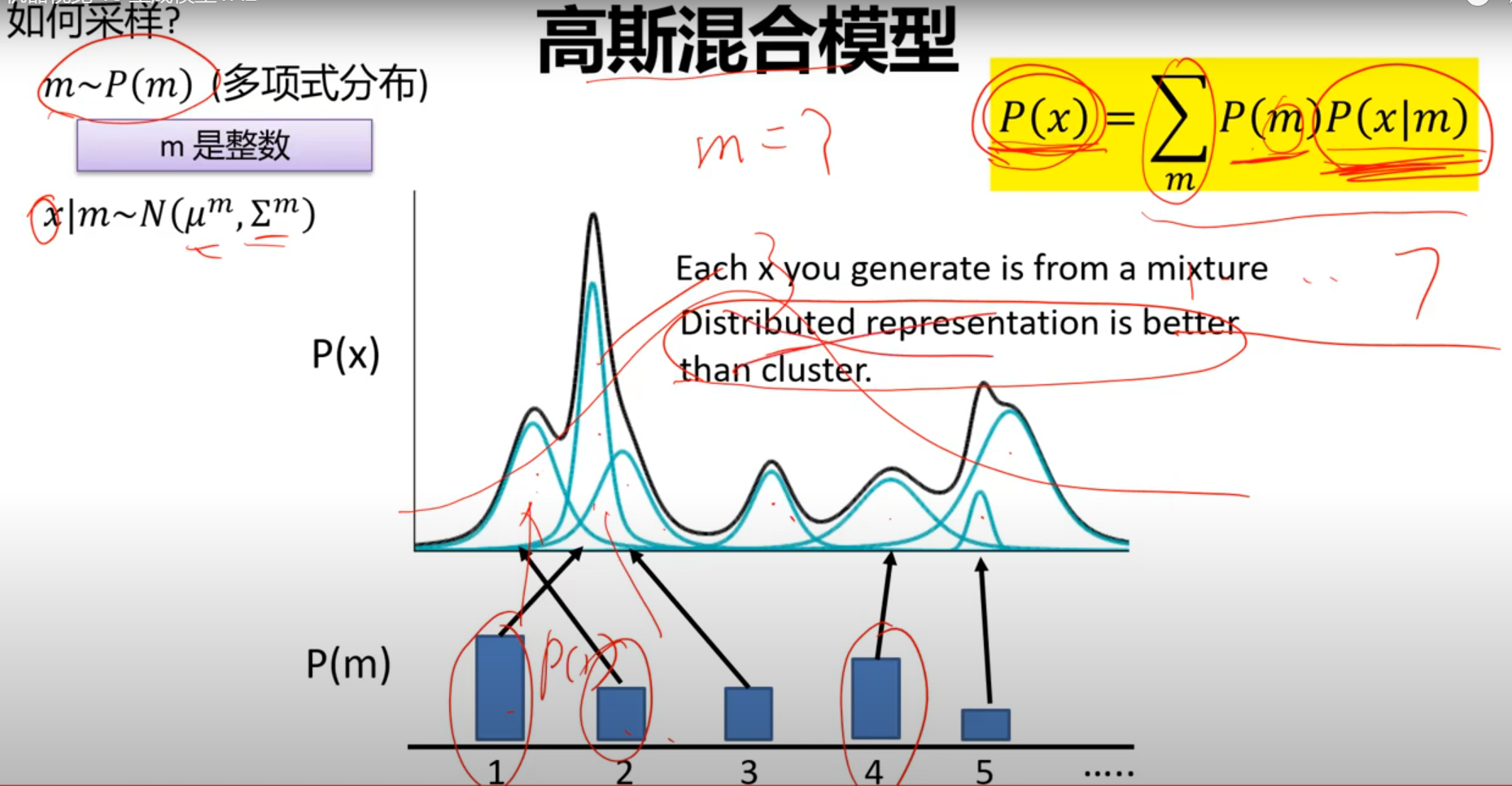
VAE也采取了这种思想,将随机变量X的完整分布P(X),看作是由无限个正态分布P(x|z)构成: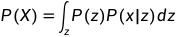
混合高斯模型只能解决有限个高斯的混合问题;但在VAE中,需要无限个高斯进行混合。
参考:
[4] 一文理解变分自编码器(VAE)
[5] Doersch C. Tutorial on variational autoencoders[J]. arXiv preprint arXiv:1606.05908, 2016.
[7] https://www.youtube.com/watch?v=1aQtj8mTuF4

















 1472
1472

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









