







第八节 2021 - 自编码器 (Auto-encoder) (上) – 基本概念_哔哩哔哩_bilibili
OUTLINE
Basic idea of Auto-Encoder
Auto-Encoder也可以看作Self-Supervised Learning 的一種 Pre-Train 的方法(2006年就有的方法,)
Self-Supervised Learning的运作:首先你有大量的沒有標註的資料、你必須發明一些不需要標註資料的任務,比如填空题、预测下一个token,
在這些不用標註資料就可以學習的任務裡、在有 BERT 在有 GPT 之前、其實有一個更古老的任務、更古老的不需要用標註資料的任務Auto-Encoder
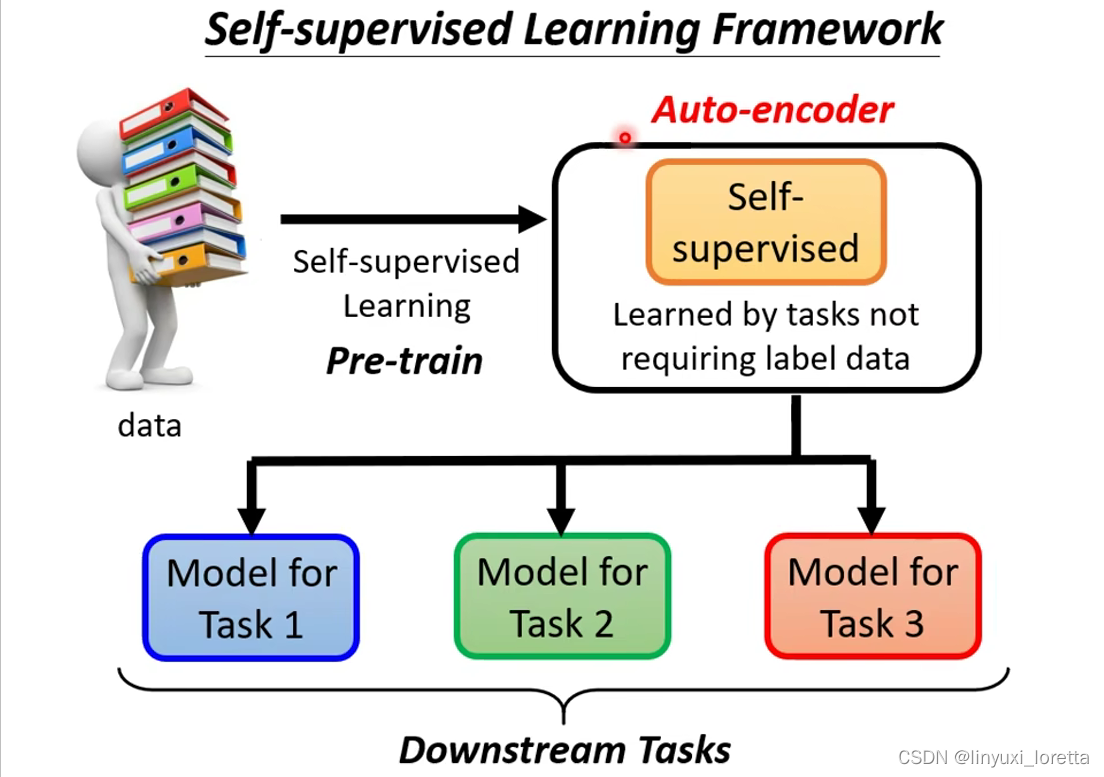
Auto-encoder的流程(Encoder将输入向量压缩为更低维度的向量,但是携带的信息会更多)
假设你有非常大量的图片,在 Auto-Encoder 裡面你有两个多层的 Network,一个叫做 Encoder,一个叫做 Decoder,
Encoder 可能是很多层的 CNN,把一张图片读进来,它的输出是一个向量,
接下来这个向量会作为 Decoder 的输入,Decoder 会产生一张图片,所以 Decoder 的 Network 的架构,可能会像是 GAN 裡面的 Generator,它是 吃1个向量输出一张图片
训练的目标是希望,Encoder 的输入跟 Decoder 的输出,越接近越好
假设你把图片看作是一个很长的向量的话,我们就希望input向量跟 Decoder 的输出向量,这两个向量他们的距离越接近越好,也有人把这件事情叫做 Reconstruction,叫做重建
和Cycle GAN具有相同的idea

怎么把 Train 的 Auto-Encoder,用在 Downstream 的任务里面呢?常见的用法就是,原来的图片,你也可以把它看作是一个很长的向量,但这个向量太长了不好处理,于是你把这个图片丢到 Encoder 以后,输出另外一个向量,这个向量你会让它比较短,比如说只有10维,100 维,那你拿这个新的向量来做你接下来的任务。也就是让图片不再是一个很高维度的向量,它通过 Encoder 的压缩以后,变成了一个低维度的向量,你再拿这个低维度的向量,来做接下来想做的事情,这就是常见的Auto-Encoder用在下游任务的方法。
Encoder 做的事情就是把本来很高维度的东西,转成低维度的东西,又叫 Dimension Reduction。Dimension Reduction 这个技术在机器学习领域常听到,其实涉及的范围非常地广,你可以把 Auto-Encoder 的 Encoder拿来做 Dimension Reduction,那其他还有很多不是以深度学习为基础的降维技术,比如说PCA,t-SNE等等,具体的介绍视频的链接就放在下面:

自编码器到底好在哪里?
那 Auto-Encoder 到底好在哪里呢,当我们把一个高维度的图片变成一个低维度的向量时,到底带来什么样的帮助?我们来想一下,Auto-Encoder 要做的是把一张图片压缩又还原回来,但是还原这件事情为什么能成功呢?
你想想看假设本来图片是 3×3 的大小,你要用 9 个数值来描述一张 3×3 的图片,假设 Encoder 输出的向量是二维的,我们是如何从二维的向量去还原 3×3 的图片,用2个值还原9个数值呢?
能够做到这件事情是因为,对于图片来说,并不是所有 3×3 的矩阵都是图片,图片的变化其实是有限的,你随便 Sample 一个矩阵,得到的通常都不是我们平常会看到的图片。
举例来说,假设图片是 3×3 的,那表面上看我们要有 3×3 个数值,才能够描述 3×3 的图片,但是也许它的变化实际上是有限的,也许你把图片收集起来发现,它的出现其实只有两种模式:
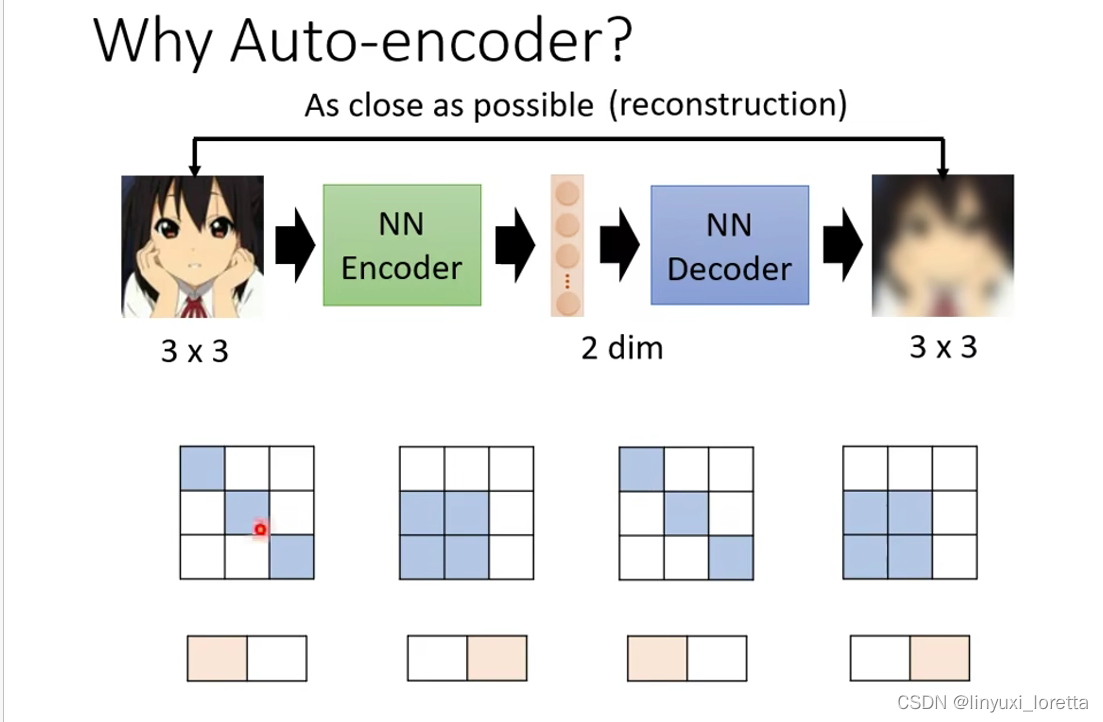
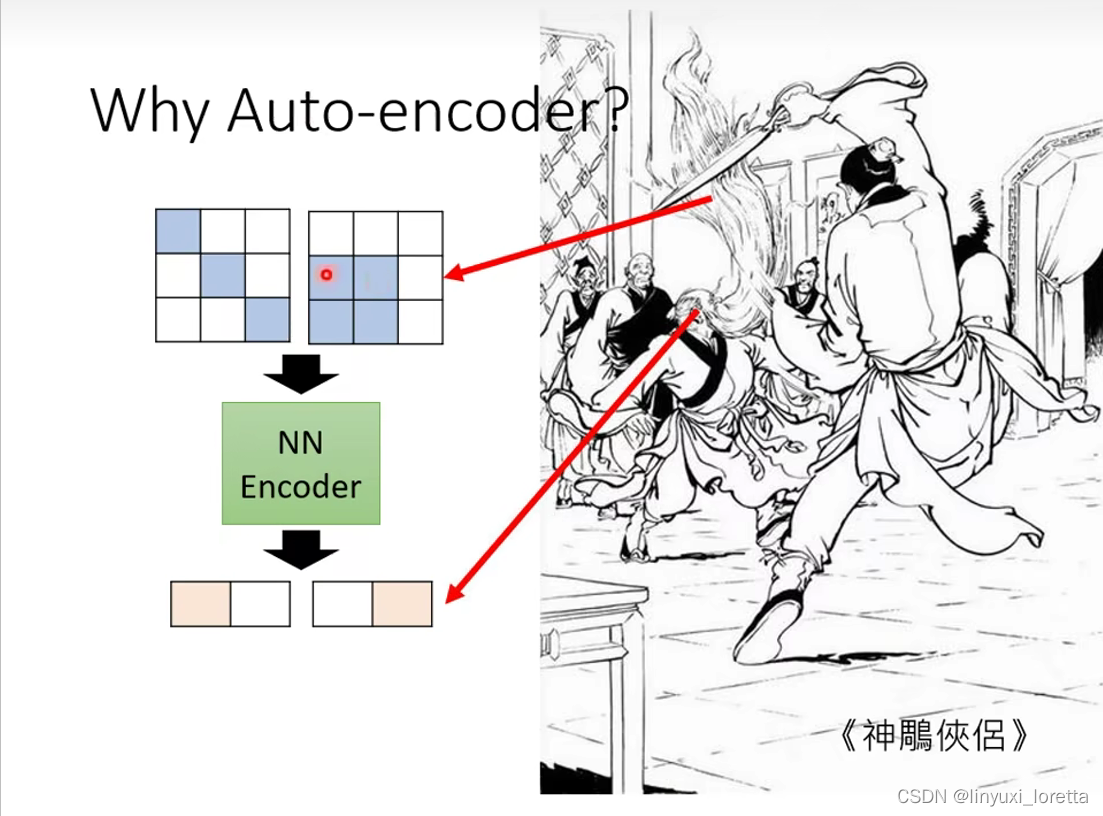
所以 Encoder 做的事情就是化繁为简,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









