







V-Net简介
介绍
卷积神经网络(Convolutional Neural Networks, CNNs)的大多数方法只能处理2D图像,而临床使用的大多数医疗数据都是3D的。V-Net提供了一个三维图像分割方法,它采用端到端的训练方式,在训练时使用了一个基于Dice coefficient的新的目标函数来优化训练。它可以很好地处理前景和背景体素数量之间存在严重不平衡的情况。为了处理可用于训练的数据有限的情况,它使用了随机非线性转换和直方图匹配来增强数据。
V-Net网络结构

V-Net网络左侧是一条压缩路径;右侧是一条解压缩路径,为了使图片恢复到原始大小。
压缩路径
V-Net没有按切片方式处理输入体积,而是使用体积卷积作为输入。
首先输入大小为128X128X64的图像,通过一个卷积核大小为5X5X5,滑动步长为1的卷积,得到通道数为16的大小为128X128X64的feature map,我们可以发现经过卷积后图像的大小没有发生变化,变化的只有通道数,由此我们可以知道图片在卷积时是经过适当填充的(即padding = 2)。
在第一次element-wise sum中,由于input的channel为1,而卷积后的feature map卷积channel为16,无法直接相加,因此作者采用了复制的方式将input的channel扩展至16。(代码如下)
# split input in to 16 channels
x16 = torch.cat((x, x, x, x, x, x, x, x,
x, x, x, x, x, x, x, x), 0)
完成以上操作后使用大小为2X2X2,步长为2的卷积来代替池化层使feature map大小变为原来的一半(将池操作替换为卷积操作可以使网络在训练期间内存占用更小)。之后再不断重复这个过程(除了卷积次数不同,其他同理),直到得到大小为8X8X4,channel为256的feature map。这样就完成了左侧的压缩路径。
注:此时有一个图片上没有体现的细节,就是2X2X2卷积过后feature map的channel变为了原来的两倍,这样的好处是使接下来参与element-wise sum的两个feature map的channel相同。
解压缩路径
在右侧的解压缩路径中,首先对压缩路径得到的结果进行反卷积处理,使其变成大小为16X16X8的,channel为128的feature map。然后将其与压缩路径中经过element-wise sum后大小为16X16X8,channel为128的feature map进行拼接,得到大小为16X16X8,channel为256的feature map,再将其经过三次卷积,和拼接后得到的feature map相加。(这里代码和图片上的描述出现了一些出入,图片上表示的应该是将经过三次卷积处理的feature map和经过反卷积处理后的feature map相加)
相关代码如下:
out = self.relu1(self.bn1(self.up_conv(out)))
xcat = torch.cat((out, skipxdo), 1)
# self.ops是一个多次卷积处理操作
out = self.ops(xcat)
out = self.relu2(torch.add(out, xcat))
之后重复该过程直到得到大小为128X128X64,channel为32的feature map,在经过1X1X1的卷积处理得到大小不变,channel为2的feature map(channel为2的原因是因为V-Net是一个二分类网络)。最后经过Softmax处理得到结果。
注:整个网络都是使用keiming等人提出的PReLU非线性单元。
Dice loss layer
在医学图像中,我们感兴趣的部分通常只占扫描区域的很小一部分,只会使得网络学习过程陷入损失函数的局部最小值,从而产生一个预测严重偏向于背景的网络,从而导致前景元素经常丢失或只检测到部分。传统的方法采用基于样本加权的损失函数,使得前景区域在学习中比背景区域更重要。然而V-Net的作者提出了一个新的基于dice coefficient的目标函数,使用这个公式,我们不需要为不同类别的样本分配权重,就可以在前景体素和背景体素之间建立正确的平衡。
函数表达式如下:
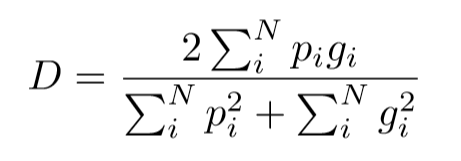
残差函数
使用残差函数的目的是使网络能够更快的收敛。而残差函数我们在上面的V-Net网络结构中已经提到了,就是element-wise sum操作——即将卷机层的输入和输出相加。
数据增强方法:
- 利用 2x2x2的网格控制点和B-spline得到密集形变场对图像进行随机形变。
- 直方图匹配
论文中关于这部分没有详细介绍。
训练
设置 momentum = 0.99,initial learning rate = 0.0001 ,每25K次迭代降低一个数量级。
参考资料
V-Net论文:https://arxiv.org/pdf/1606.04797.pdf
V-Net代码:https://github.com/mattmacy/vnet.pytorch















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









