







前言
随着多模态大模型的发展,其不仅限于文字处理,更能够在图像、视频、音频方面进行识别与理解。医疗领域中,医生们往往需要对各种医学图像进行处理,以辅助诊断和治疗。如果将多模态大模型与图像诊断相结合,那么这会极大地提升诊断效率。
项目目标
训练一个医疗多模态大模型,用于图像诊断。
刚好家里老爷子近期略感头疼,去医院做了脑部CT,诊断患有垂体瘤,我将尝试使用多模态大模型进行进一步诊断。
实现过程
1. 数据集准备
为了训练模型,需要准备大量的医学图像数据。通过搜索我们找到以下训练数据:
数据名称:MedTrinity-25M
数据地址:https://github.com/UCSC-VLAA/MedTrinity-25M
数据简介:MedTrinity-25M数据集是一个用于医学图像分析和计算机视觉研究的大型数据集。
数据来源:该数据集由加州大学圣克鲁兹分校(UCSC)提供,旨在促进医学图像处理和分析的研究。
数据量:MedTrinity-25M包含约2500万条医学图像数据,涵盖多种医学成像技术,如CT、MRI和超声等。
数据内容:
该数据集有两份,分别是 25Mdemo 和 25Mfull 。
25Mdemo (约162,000条)数据集内容如下:
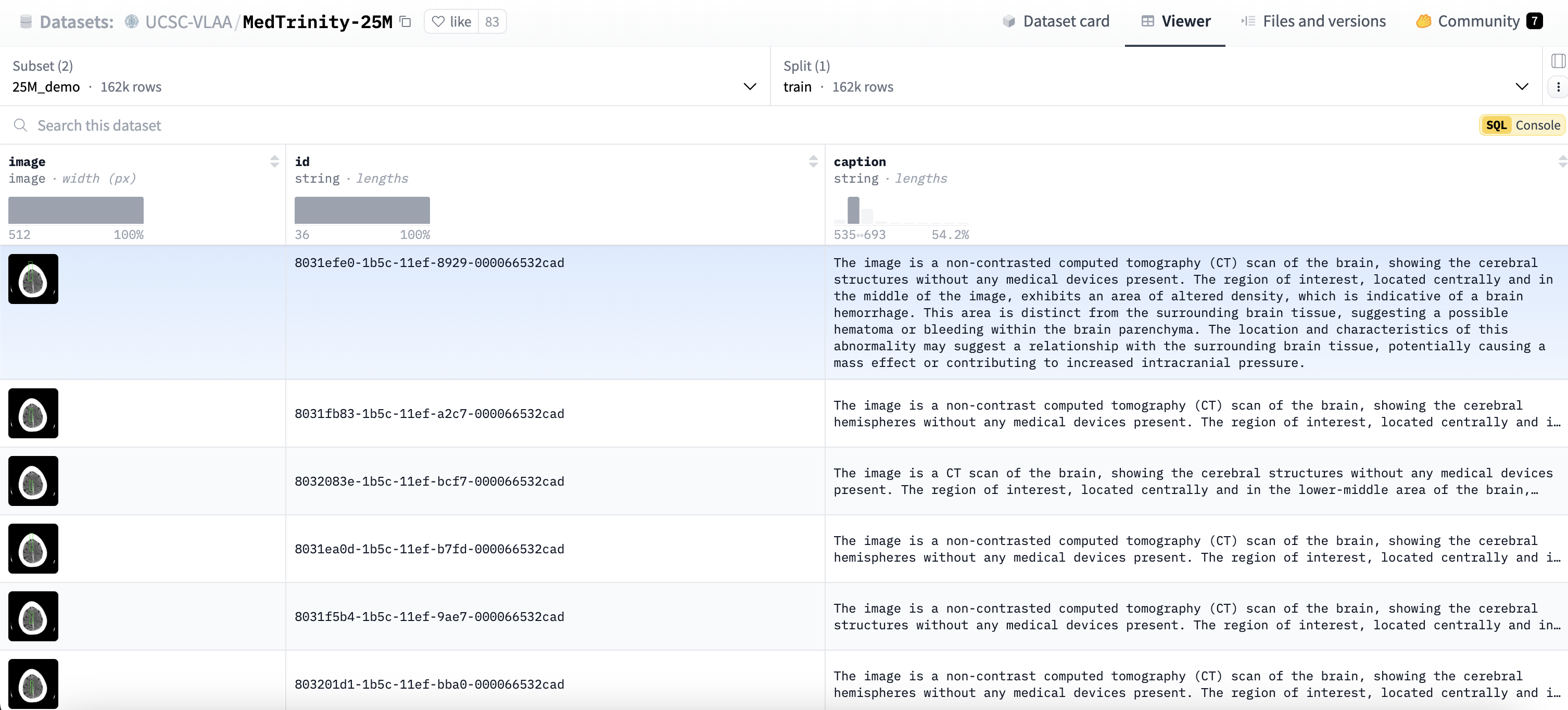
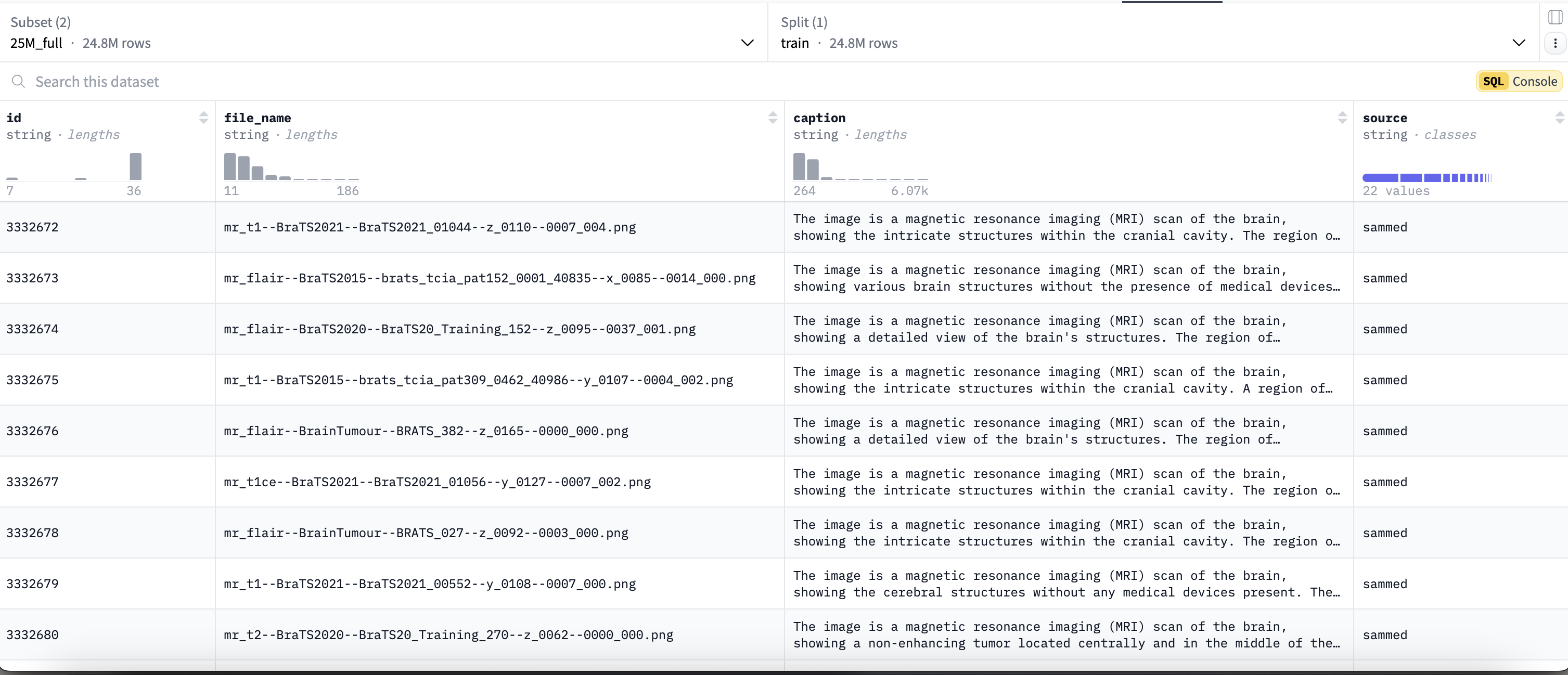
25Mfull (约24,800,000条)数据集内容如下:
2. 数据下载
2.1 安装Hugging Face的Datasets库
pip install datasets
2.2 下载数据集
from datasets import load_dataset
# 加载数据集
ds = load_dataset("UCSC-VLAA/MedTrinity-25M", "25M_demo", cache_dir="cache")
执行结果:
说明:
- 以上方法是使用HuggingFace的Datasets库下载数据集,下载的路径为当前脚本所在路径下的cache文件夹。
- 使用HuggingFace下载需要能够访问https://huggingface.co/ 并且在网站上申请数据集读取权限才可以。
- 如果没有权限访问HuggingFace,可以关注一起AI技术公众号后,回复 “MedTrinity”获取百度网盘下载地址。
2.3 预览数据集
# 查看训练集的前1个样本
print(ds['train'][:1])
运行结果:
{
'image': [<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=512x512 at 0x15DD6D06530>],
'id': ['8031efe0-1b5c-11ef-8929-000066532cad'],
'caption': ['The image is a non-contrasted computed tomography (CT) scan of the brain, showing the cerebral structures without any medical devices present. The region of interest, located centrally and in the middle of the image, exhibits an area of altered density, which is indicative of a brain hemorrhage. This area is distinct from the surrounding brain tissue, suggesting a possible hematoma or bleeding within the brain parenchyma. The location and characteristics of this abnormality may suggest a relationship with the surrounding brain tissue, potentially causing a mass effect or contributing to increased intracranial pressure.'
]
}
使用如下命令对数据集的图片进行可视化查看:
# 可视化image内容
from PIL import Image
import matplotlib.pyplot as plt
image = ds['train'][0]['image'] # 获取第一张图像
plt.imshow(image)
plt.axis('off') # 不显示坐标轴
plt.show()
运行结果:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1583
1583

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











