








2024年8月29日,阿里发布了 Qwen2-VL!Qwen2-VL 是基于 Qwen2 的最新视觉语言大模型。与 Qwen-VL 相比,Qwen2-VL 具有以下能力:
- SoTA对各种分辨率和比例的图像的理解:Qwen2-VL在视觉理解基准上达到了最先进的性能,包括MathVista、DocVQA、RealWorldQA、MTVQA等。
- 理解 20 分钟+ 的视频:Qwen2-VL 可以理解 20 分钟以上的视频,以进行高质量的基于视频的问答、对话、内容创建等。
- 可以操作您的手机、机器人等的代理:Qwen2-VL 具有复杂的推理和决策能力,可以与手机、机器人等设备集成,根据视觉环境和文本指令进行自动操作。
- 多语言支持:为了服务全球用户,除了英文和中文外,Qwen2-VL 现在还支持理解图像中不同语言的文本,包括大多数欧洲语言、日语、韩语、阿拉伯语、越南语等。
Qwen2-VL-2B 和 Qwen2-VL-7B模型开源了, Qwen2-VL-72B只开源了API!开源模型已集成到 Hugging Face Transformers、vLLM 和其他第三方框架中。
一、性能
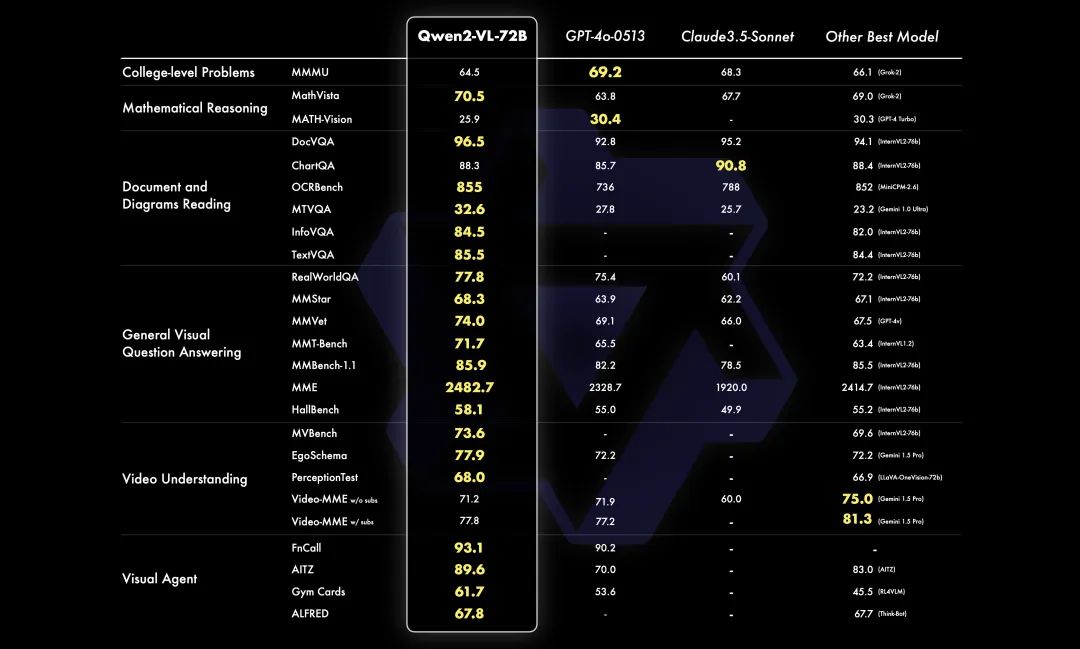
72B:
从六个关键维度评估模型的视觉能力:复杂的大学水平问题解决、数学能力、文档和表格理解、多语言文本图像理解、一般场景问答、视频理解和基于代理的交互。总体而言, 72B 模型在大多数指标上都展示了顶级性能,甚至超过了 GPT-4o 和 Claude 3.5-Sonnet 等闭源模型。值得注意的是,它在文档理解方面表现出显着优势。
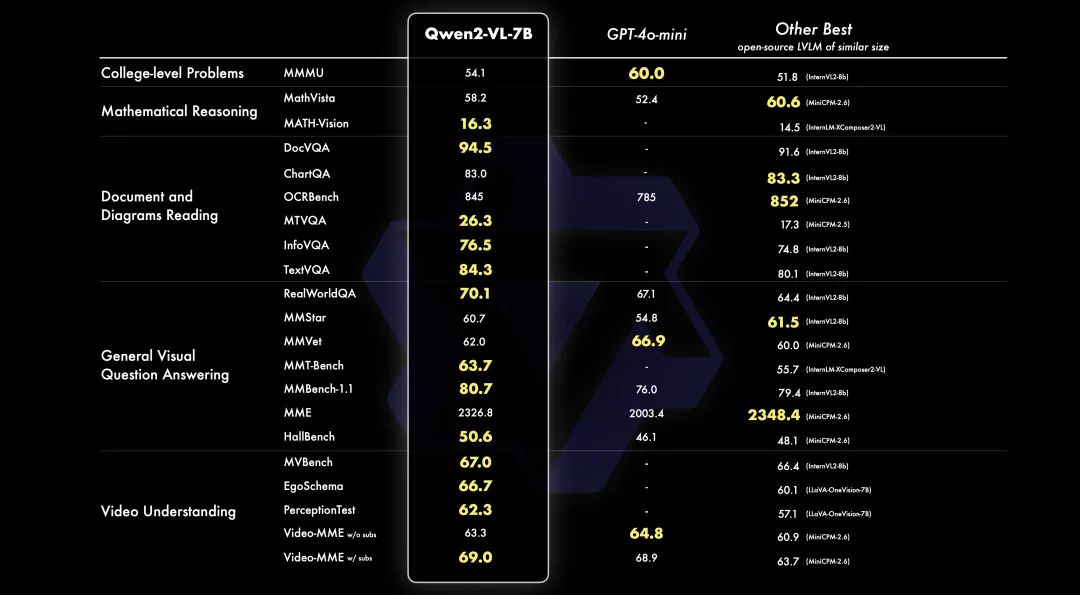
7B:
在 7B 模型上,保留了对图像、多图像和视频输入的支持,以更具成本效益的模型大小提供有竞争力的性能。具体来说,在 DocVQA 等文档理解任务和图像中的多语言文本理解方面表现出色。
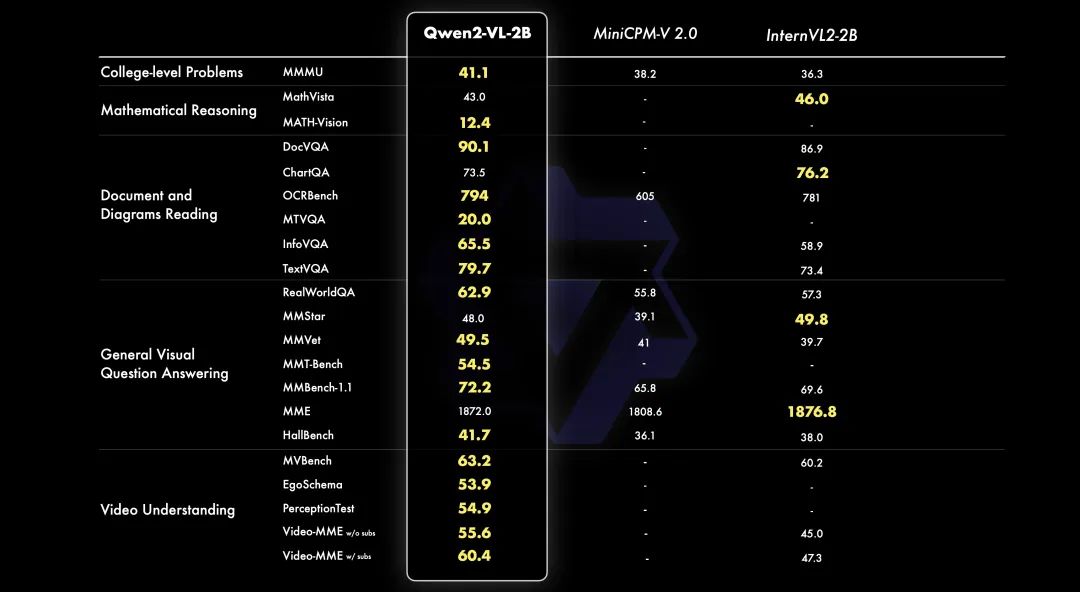
2B:
此外,更小的 2B 模型针对潜在的移动部署进行了优化。尽管体积小巧,但该模型在图像、视频和多语言理解方面拥有强大的性能。与其他类似规模的模型相比,它在与视频相关的任务、文档理解和一般场景问答方面尤其突出。
二、模型任务表现
2.1 增强的识别功能
Qwen2-VL 现在拥有改进的对象识别功能,超越了植物和地标,可以理解场景中多个对象之间的复杂关系。我们还显著提高了该模型识别图像中的手写文本和多种语言的能力,使其更易于全球用户访问。
示例:多对象识别
User:Output the color and number of each box.
输出每个框的颜色和编号。

Qwen2-VL:
The image shows a stack of colorful blocks with numbers on them. Here is the color and number of each block from top to bottom:
该图像显示了一堆带有数字的彩色块。以下是每个块的颜色和编号,从上到下:
-
Top row (single block): Blue with the
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 847
847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











