




深度人工智能

“深度人工智能”是成都深度智谷科技旗下的人工智能教育机构订阅号,主要分享人工智能的基础知识、技术发展、学习经验等。此外,订阅号还为大家提供了人工智能的培训学习服务和人工智能证书的报考服务,欢迎大家前来咨询,实现自己的AI梦!
一、引言
-
目标检测的重要性及其在计算机视觉中的地位
目标检测在计算机视觉领域内占据着极其重要的地位,它不仅是许多视觉任务的基础,也是连接学术研究与工业应用的关键桥梁。目标检测作为计算机视觉中的一个核心任务,它涉及到识别图像或视频中的特定对象并定位这些对象的位置。这一过程通常需要模型能够识别出多个类别的物体,并为每个检测到的物体画出边界框。
目标检测在现实生活和工作过场景中的应用非常广泛,比如目标检测技术已经被广泛应用的各种实际场景有智能交通系统(车辆识别、行人检测等)、安防监控(自动识别异常行为、如入侵检测等)、零售业(顾客行为分析、库存管理等)、医疗健康(辅助诊断,如肿瘤检测、疾病筛查等)、无人机技术(用于环境监测、作物管理、搜救任务等)
目标检测的进步推动了整个计算机视觉领域的发展。随着深度学习的兴起,基于卷积神经网络(CNNs)的目标检测算法取得了显著的成果,这不仅提高了检测的准确性,还加快了检测速度,使得实时应用成为可能。目标检测技术的发展更是促进了计算机科学与其他学科之间的合作,比如与机器人学、生物学、医学等领域的交叉应用,从而产生新的研究方向和应用场景。

从经济角度来看,高效且准确的目标检测技术能够为企业创造巨大的商业价值。同时,这项技术也在改善人们的生活质量,提高生产效率,保障公共安全等方面发挥着积极作用。目标检测不仅对于理论研究具有重要意义,而且其实际应用也对社会经济发展产生了深远影响。随着技术的不断进步,目标检测将继续保持其在计算机视觉中的核心地位,并且在未来的智能化世界中扮演更加重要的角色。
-
困难目标检测任务的定义及场景
在计算机视觉领域,"困难目标检测任务"是指那些由于某些因素导致目标检测算法难以准确识别和定位目标的情况。下面是一些常见的困难目标检测场景:
1.小目标检测
定义:当目标在图像中的像素占比非常小时,即为小目标。这类目标通常难以被检测到,因为它们提供的特征信息较少,容易被背景噪声掩盖。
挑战:小目标往往缺乏足够的细节特征,传统的检测方法可能无法有效地提取这些特征。

例子:远处的人或车辆,在航拍图像中的小型动物等。
2.遮挡目标检测
定义:当目标部分或全部被其他物体遮挡时,称为遮挡目标。
挑战:遮挡会减少可用于识别目标的信息量,使得目标的形状、颜色等特征发生改变,增加识别难度。
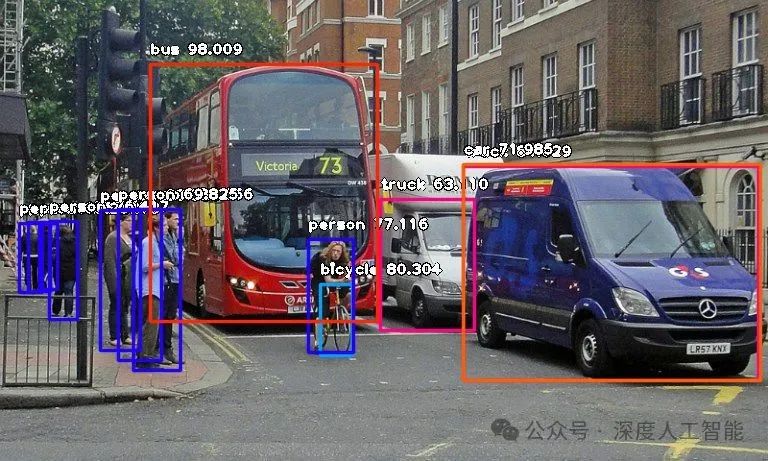
例子:行人被树木遮挡,车辆被其他车辆或建筑物遮挡等。
3.模糊目标检测
定义:当目标处于运动状态或相机移动时,可能会导致目标在图像中呈现模糊效果。
挑战:模糊会导致目标边界不清晰,纹理特征丧失,进而影响检测精度。

例子:快速移动的物体,如飞行中的鸟类或奔跑中的人物,在低速快门拍摄下的物体等。
4.其他困难情况
低对比度目标:目标与背景之间的颜色或亮度差异很小。
光照变化:不同光照条件下,同一目标的外观会发生变化。
视角变化:从不同角度观察同一目标可能导致其外观形态的变化。
密集目标检测:当多个目标紧密排列在一起时,分离个体变得困难。
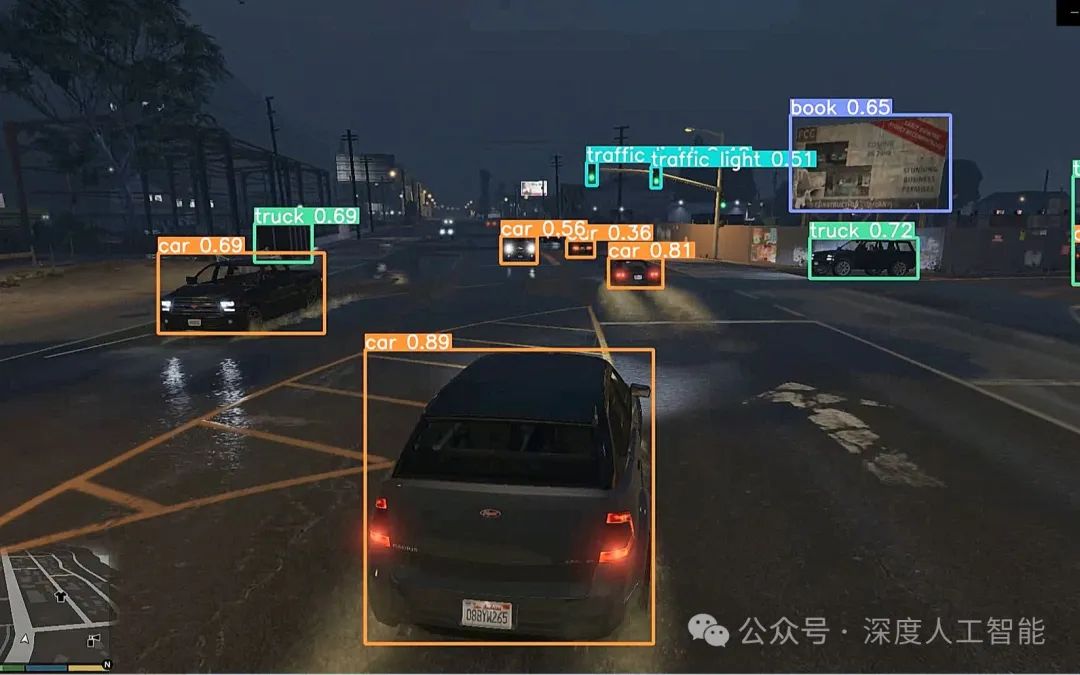
解决这些困难目标检测问题通常需要更复杂的模型设计、更强的数据增强技术以及更有效的特征提取方法。此外,结合多模态信息或者利用上下文信息也有助于提升检测性能。随着技术的发展,研究人员正在不断地探索新的方法来应对这些挑战。
二、目标检测的背景与概述
目标检测是计算机视觉中的一个基本任务,旨在识别图像或视频帧中的特定对象,并确定这些对象的位置。下面是目标检测的基本概念及流程的详细介绍:
-
基本概念
候选区域(Region Proposal):目标检测的第一步通常是生成图像中可能包含感兴趣对象的区域,这些区域被称为候选区域。
特征提取:从候选区域内提取有用的特征,以便进行分类和定位。
分类器:用于判断候选区域内是否存在特定类别的对象。
边界框回归(Bounding Box Regression):调整候选区域的位置和大小,使其更精确地围绕目标对象。
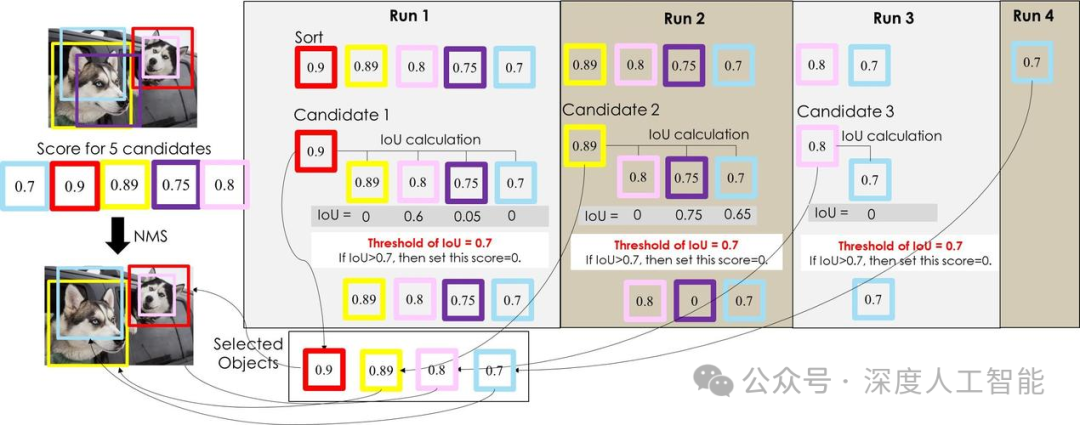
非极大值抑制(Non-Maximum Suppression, NMS):去除重叠的边界框,只保留最有可能的对象检测结果。
-
检测流程
1.输入图像预处理
图像可能需要进行缩放、裁剪等操作以满足模型输入的要求。
可能还会
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 310
310

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









