







以泰坦尼克数据集建立分类机器学习任务(预测生死)
数据清洗:
library(mlr3verse)
library(mlr3fselect)
set.seed(7832)
lgr::get_logger("mlr3")$set_threshold("warn")
lgr::get_logger("bbotk")$set_threshold("warn")
library(mlr3data)
data("titanic", package = "mlr3data")
titanic$age[is.na(titanic$age)] = median(titanic$age, na.rm = TRUE)
titanic$embarked[is.na(titanic$embarked)] = "S"
titanic$ticket = NULL
titanic$name = NULL
titanic$cabin = NULL
titanic = titanic[!is.na(titanic$survived),]
创建机器学习任务:
task = as_task_classif(titanic, target = "survived", positive = "yes")选择模型:
library(mlr3learners)
#logistic regression learner,
#To evaluate the predictive performance, we choose a 3-fold cross-validation and the classification error as the measure.
learner = lrn("classif.log_reg")
resampling = rsmp("cv", folds = 3)
measure = msr("classif.ce")
resampling$instantiate(task)
以上可以认为是全局设置,在随后的特征选择过程中,方法不尽相同。但是,task, learner, resampling, measure是相同的。terminator是何时终止,因算法而不同。
总的来讲,FSelectInstanceSingleCrit$new确定了特征筛选任务,提供机器学习任务、重抽样策略、评价指标,终止事件。查看特征筛选方法:
mlr_fselectors下面以Sequential Forward Selection为例展示这一过程。
library(mlr3verse)
library(mlr3fselect)
set.seed(7832)
lgr::get_logger("mlr3")$set_threshold("warn")
lgr::get_logger("bbotk")$set_threshold("warn")
library(mlr3data)
data("titanic", package = "mlr3data")
titanic$age[is.na(titanic$age)] = median(titanic$age, na.rm = TRUE)
titanic$embarked[is.na(titanic$embarked)] = "S"
titanic$ticket = NULL
titanic$name = NULL
titanic$cabin = NULL
titanic = titanic[!is.na(titanic$survived),]
task = as_task_classif(titanic, target = "survived", positive = "yes")
library(mlr3learners)
learner = lrn("classif.log_reg")
resampling = rsmp("cv", folds = 3)
measure = msr("classif.ce")
resampling$instantiate(task)
terminator = trm("stagnation", iters = 5)
instance = FSelectInstanceSingleCrit$new(
task = task,
learner = learner,
resampling = resampling,
measure = measure,
terminator = terminator)
fselector = fs("sequential")
fselector$optimize(instance)
fselector$optimization_path(instance)嵌套重抽样用于特征选择
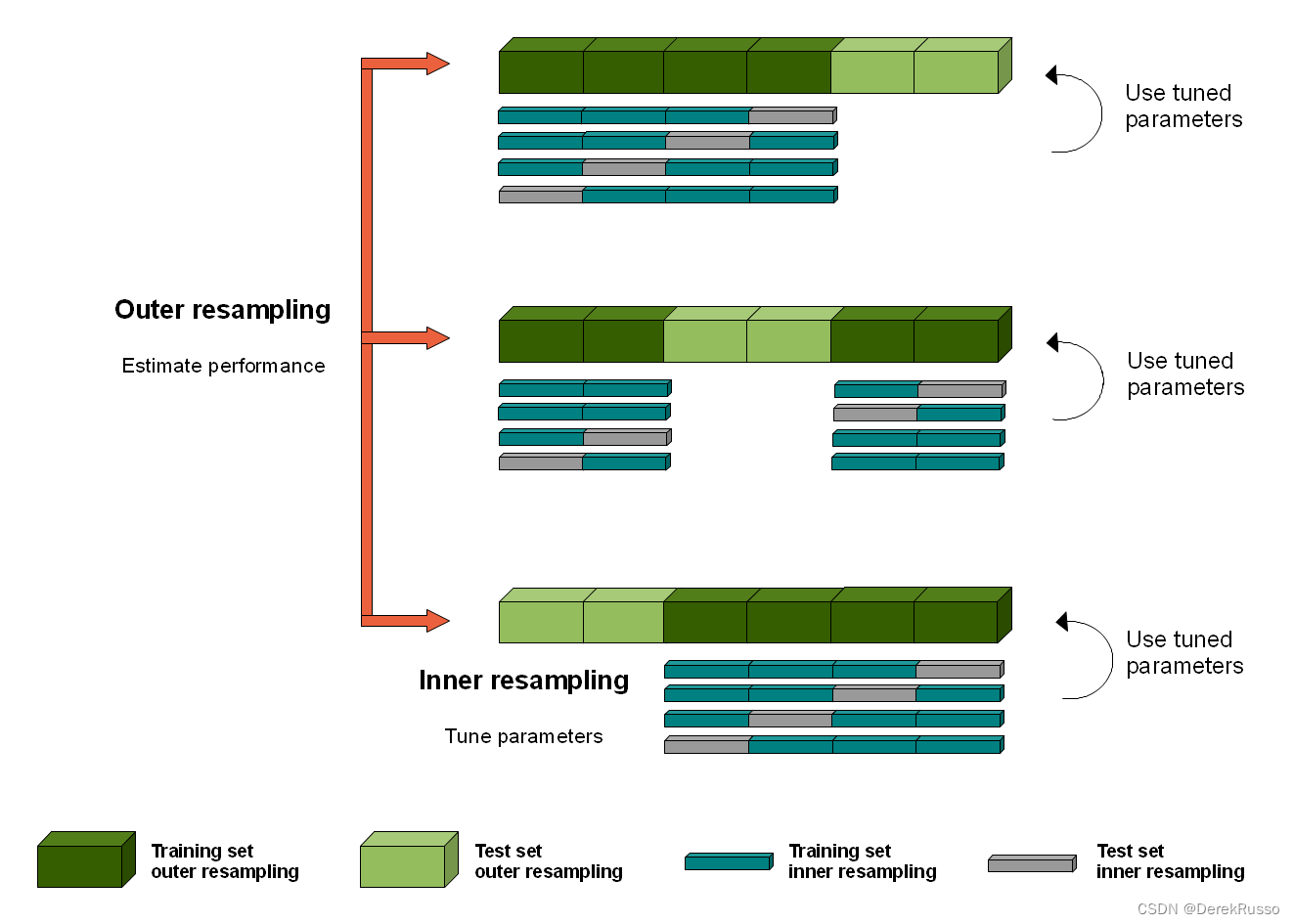
The graphic above illustrates nested resampling for parameter tuning with 3-fold cross-validation in the outer and 4-fold cross-validation in the inner loop.
The repeated evaluation of the model might leak information about the test sets into the model and thus leads to over-fitting and over-optimistic performance results. nested resampling uses an outer and inner resampling to separate the feature selection from the performance estimation of the model.
以上为原理步骤展示,实际中可简化代码:
# Nested resampling on Palmer Penguins data set
rr = fselect_nested(
fselector = fs("random_search"),
task = tsk("penguins"),
learner = lrn("classif.rpart"),
inner_resampling = rsmp ("holdout"),
outer_resampling = rsmp("cv", folds = 2),
measure = msr("classif.ce"),
term_evals = 4)
# Performance scores estimated on the outer resampling
rr$score()
# Unbiased performance of the final model trained on the full data set
rr$aggregate()














 3120
3120











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









