







'The idea is to add permutated copies of the original features to the data set. These permutated copies are called shadow variables or pseudovariables and the permutation breaks any relationship with the target variable, making them useless for prediction. The subsequent search is similar to the sequential forward selection algorithm, where one new feature is added in each iteration of the algorithm. This new feature is selected as the one that improves the performance of the model the most. This selection is computationally expensive, as one model for each of the not yet included features has to be trained. The difference between shadow variable search and sequential forward selection is that the former uses the selection of a shadow variable as the termination criterion. Selecting a shadow variable means that the best improvement is achieved by adding a feature that is unrelated to the target variable. Consequently, the variables not yet selected are most likely also correlated to the target variable only by chance. Therefore, only the previously selected features have a true influence on the target variable.'
library(mlr3verse)
#no control parameters
optimizer = fs("shadow_variable_search")
task = tsk("pima")
#The data set contains missing values.
task$missings()
#impute the missing values
learner = po("imputehist") %>>% lrn("classif.svm", predict_type = "prob")
instance = fsi(
task = task,
learner = learner,
resampling = rsmp("cv", folds = 3),
measures = msr("classif.auc"),
terminator = trm("none") #shadow variable search algorithm terminates by itself.
)
optimizer$optimize(instance)
library(data.table)
library(ggplot2)
library(mlr3misc)
library(viridisLite)
data = as.data.table(instance$archive)[order(-classif.auc), head(.SD, 1), by = batch_nr][order(batch_nr)]
data[, features := map_chr(features, str_collapse)]
data[, batch_nr := as.character(batch_nr)]
ggplot(data, aes(x = batch_nr, y = classif.auc)) +
geom_bar(
stat = "identity",
width = 0.5,
fill = viridis(1, begin = 0.5),
alpha = 0.8) +
geom_text(
data = data,
mapping = aes(x = batch_nr, y = 0, label = features),
hjust = 0,
nudge_y = 0.05,
color = "white",
size = 5
) +
coord_flip() +
xlab("Iteration") +
theme_minimal()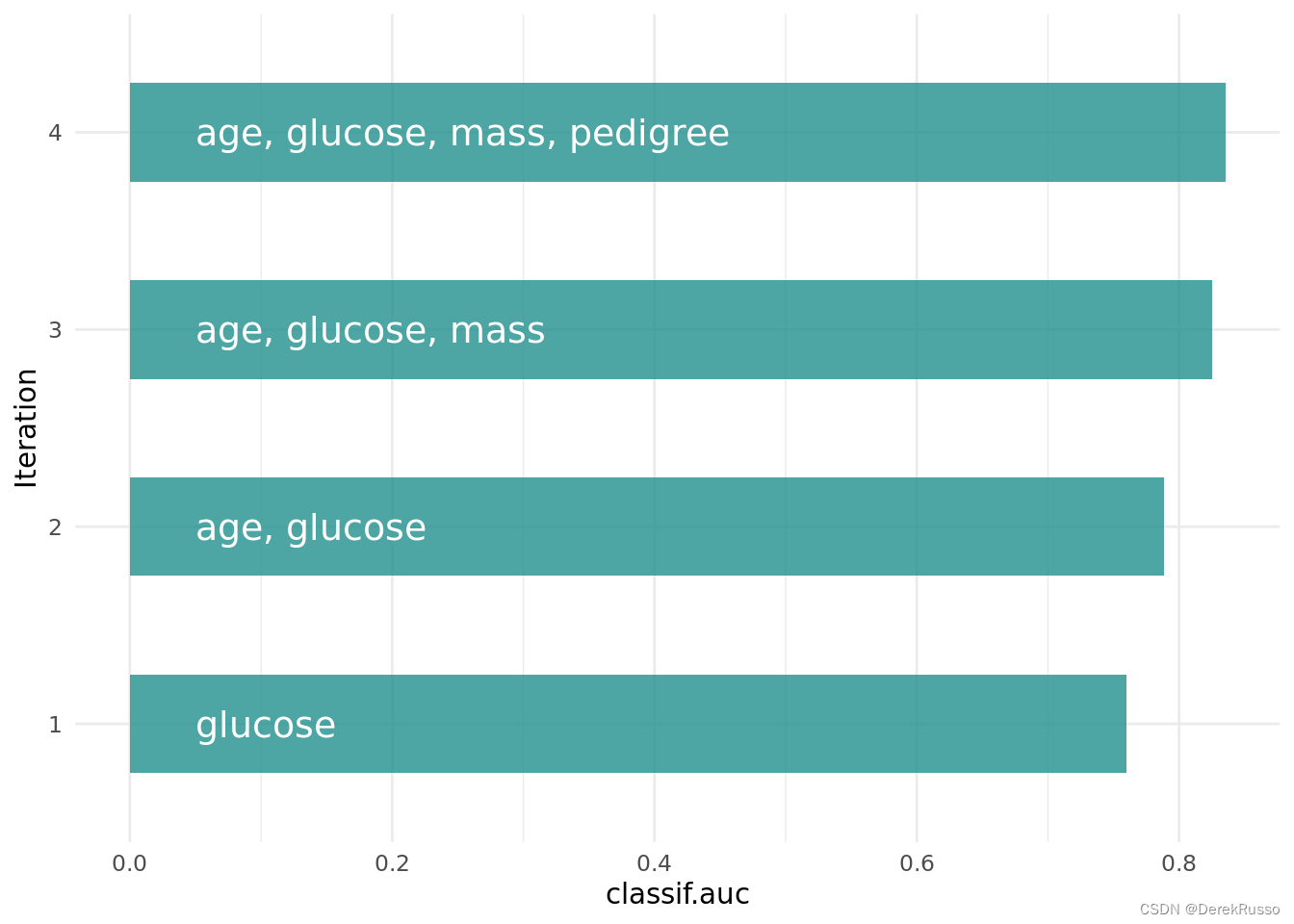
optimization path of the feature selection. The feature glucose was selected first and in the following iterations age, mass and pedigree. Then a shadow variable was selected and the feature selection was terminated.
task$select(instance$result_feature_set)
learner$train(task)
#The trained model can now be used to predict new, external data.














 1378
1378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









