









文章目录
步骤
安装docker:https://www.docker.com/
安装ollama:https://ollama.com/
ollama部署deepseek:ollama run deepseek-r1:8b(我们跳过,使用在线deepseek api)
参考文章:https://ollama.com/library/deepseek-r1
安装Dify
参考步骤
参考安装步骤:https://github.com/langgenius/dify
git clone下载源码
https://github.com/langgenius/dify
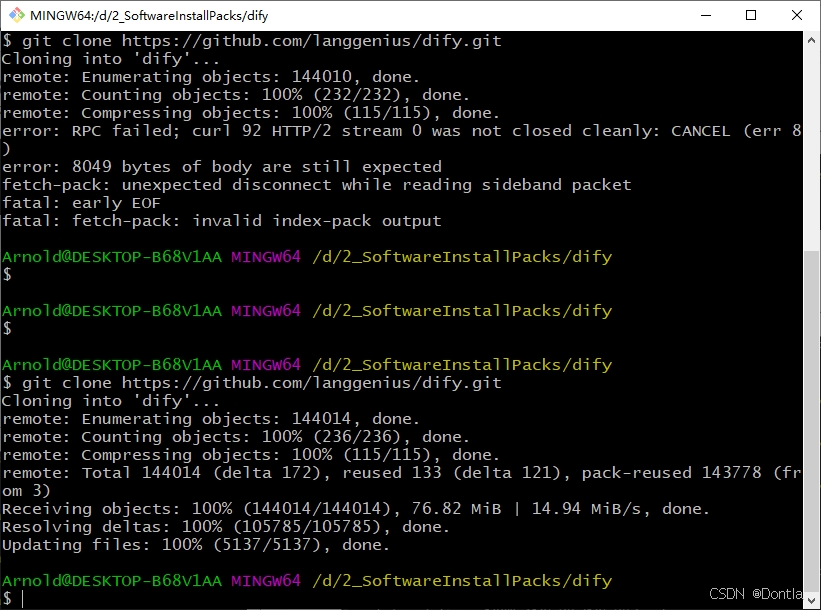
git clone https://github.com/langgenius/dify.git
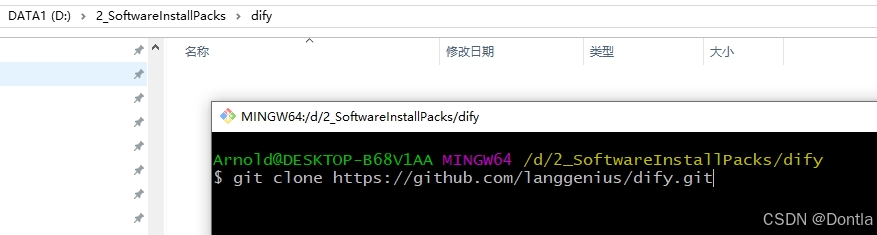
下了三次才下好:
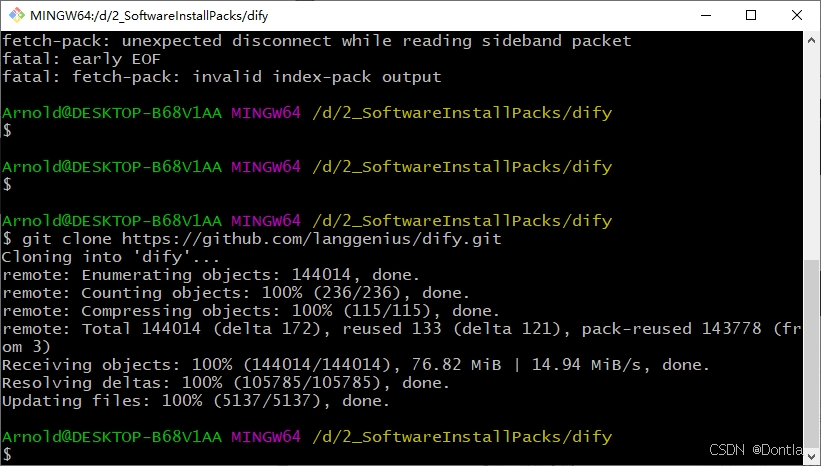
到这个目录
dify\docker
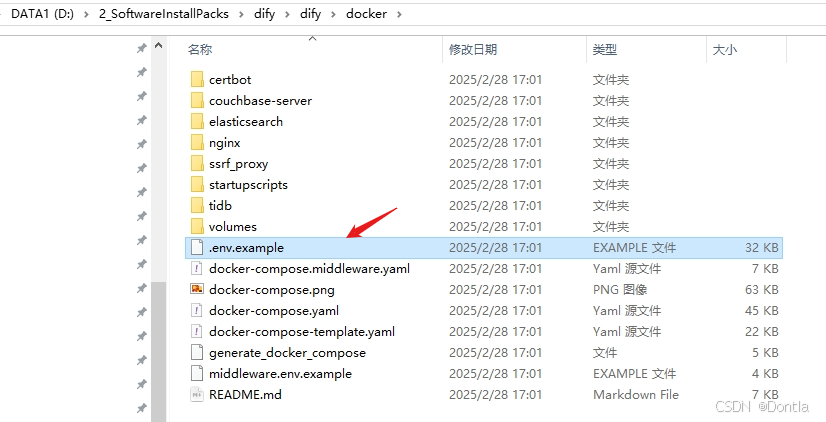
执行操作
cd dify
cd docker
cp .env.example .env
docker compose up -d
windows上直接用键盘鼠标手动操作就行。
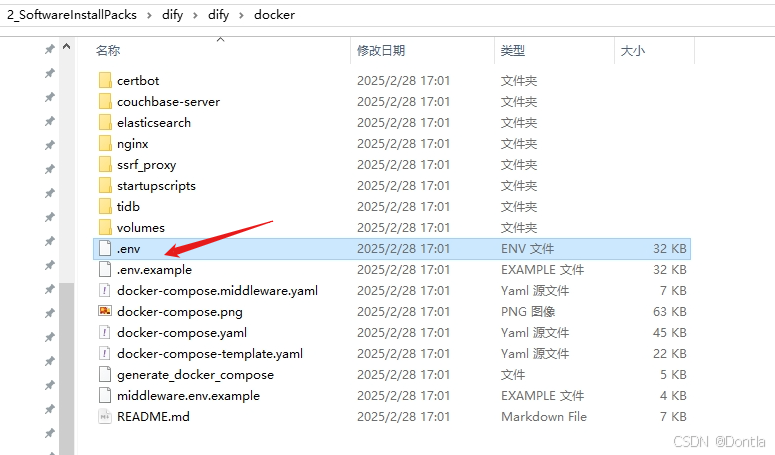
当前目录打开终端,执行:docker compose up -d
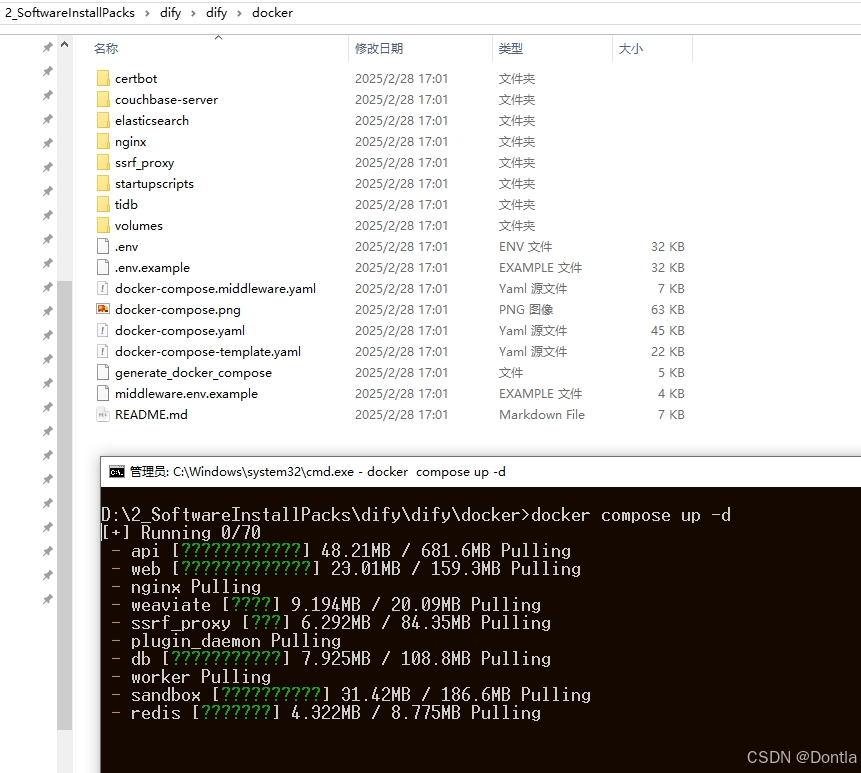
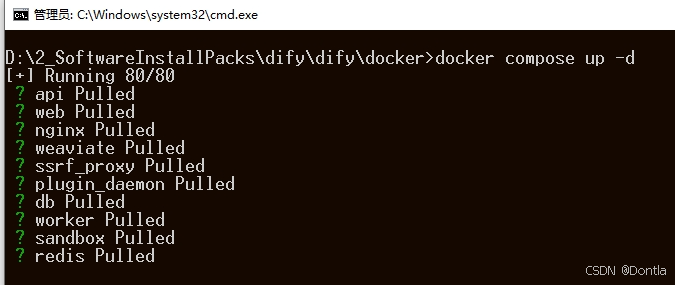
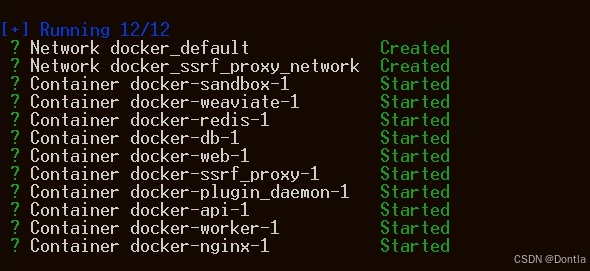
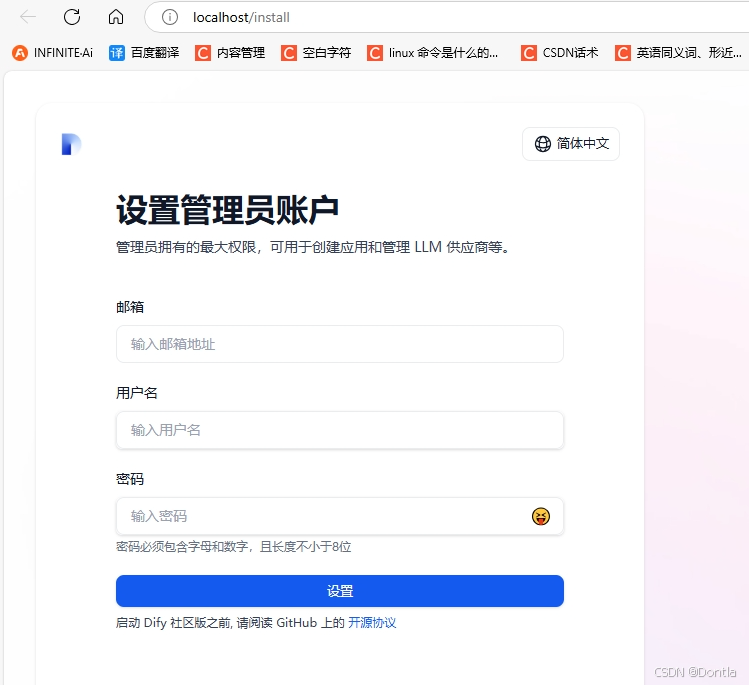
登录dify页面(先设置账户,然后登录)
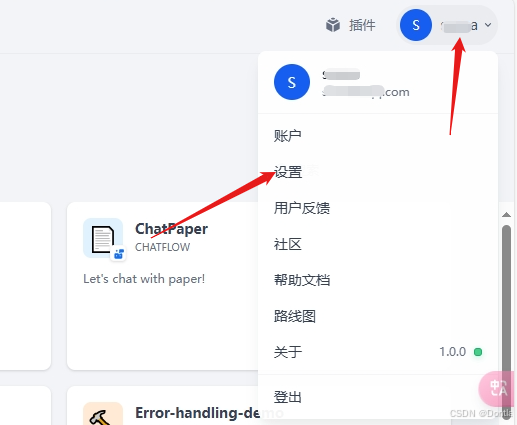
关联deeepseek api
右上角账户,点击设置
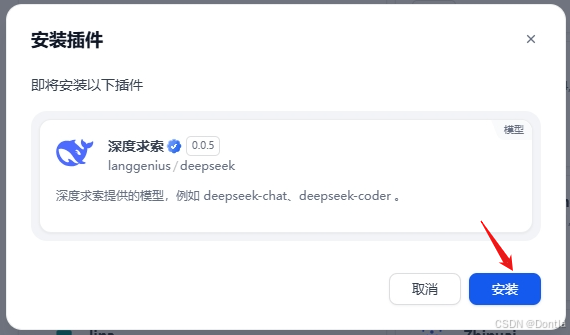
点击模型供应商,选择深度求索,点击安装

设置api key
点击设置:
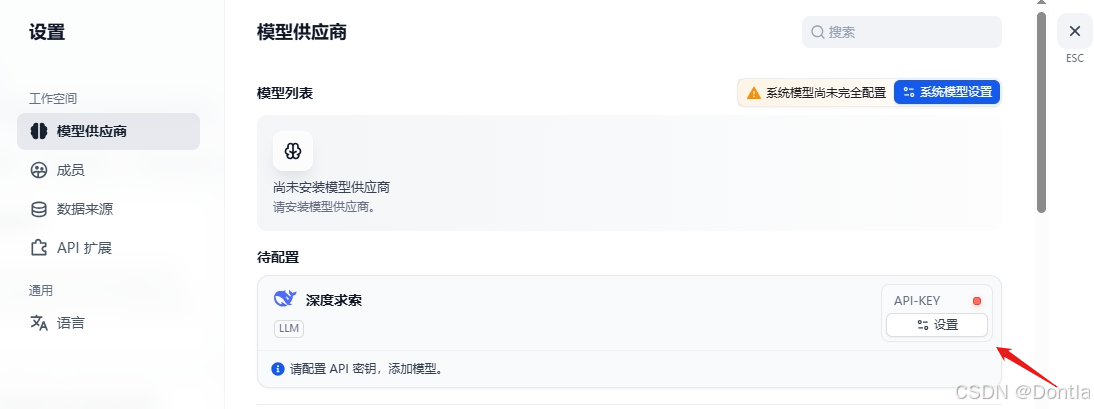
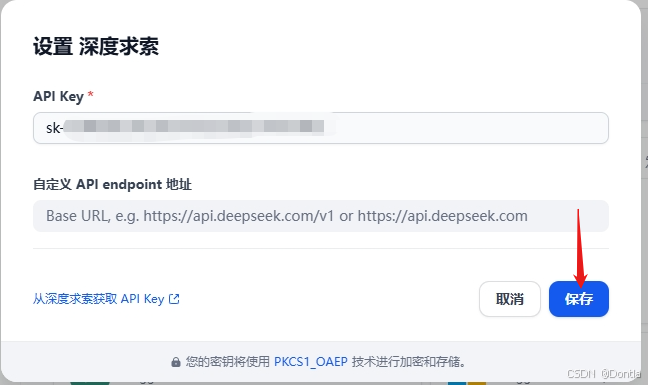
粘贴从deepseek官网拿到的api key,点击保存:
点击“系统模型设置”依次设置(如果没有显示就刷新下页面)

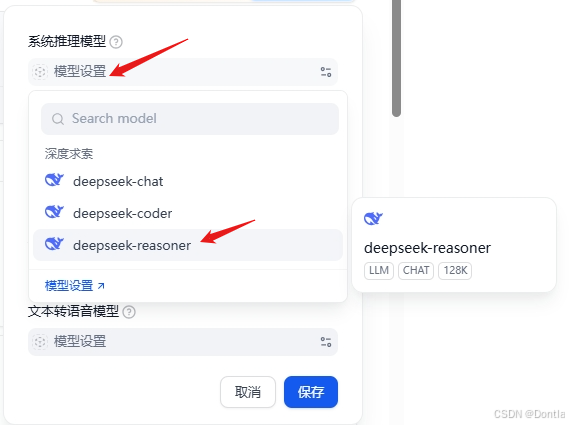
点击保存。
用ollama安装嵌入模型bge-m3

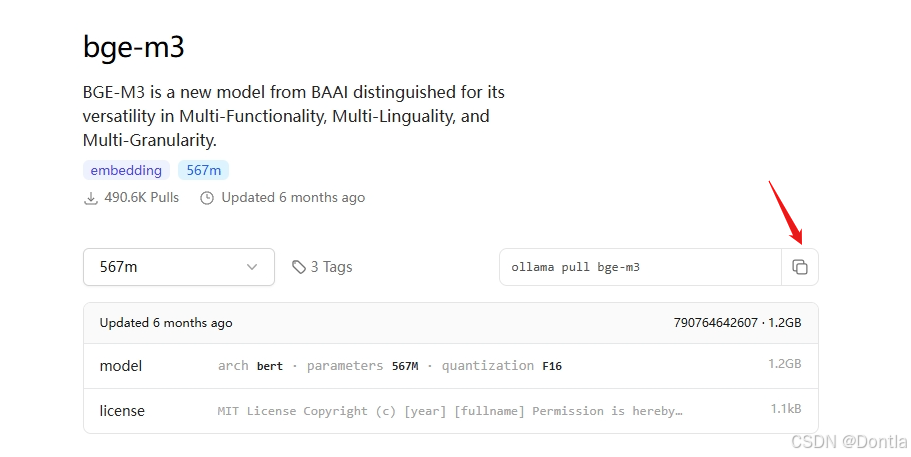
ollama pull bge-m3

dify添加嵌入模型
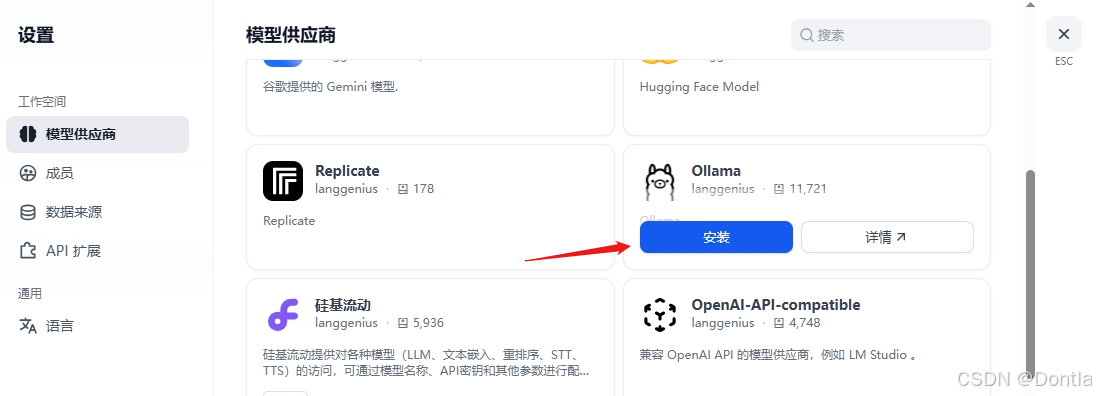
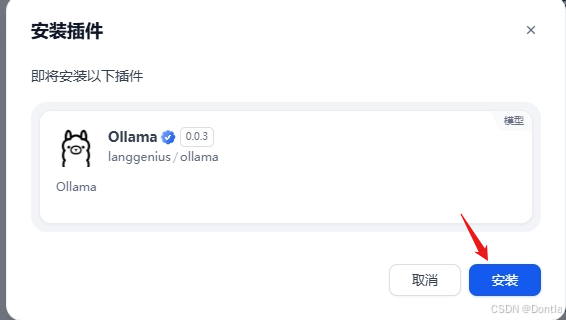
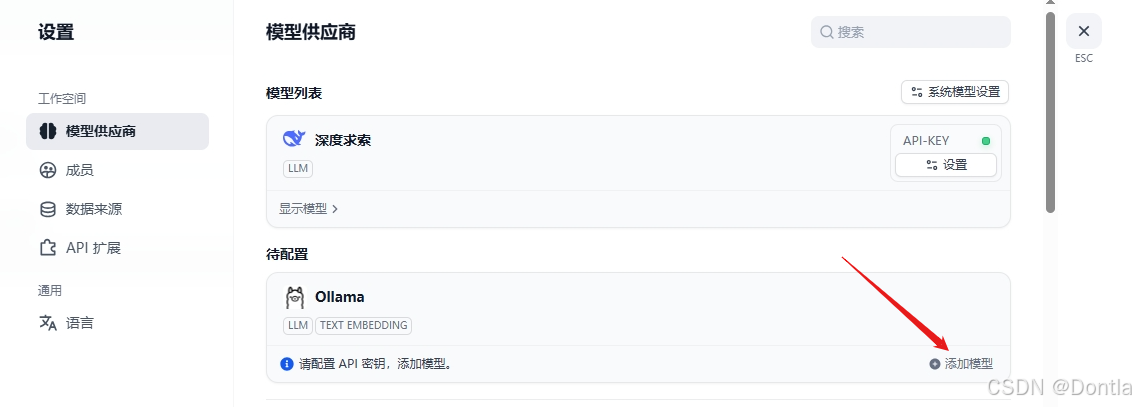
bge-m3
http://host.docker.internal:11434
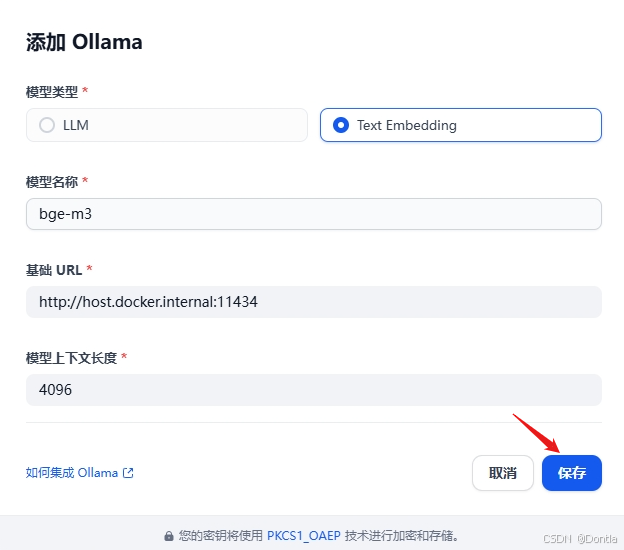
11434是ollama默认监听端口。
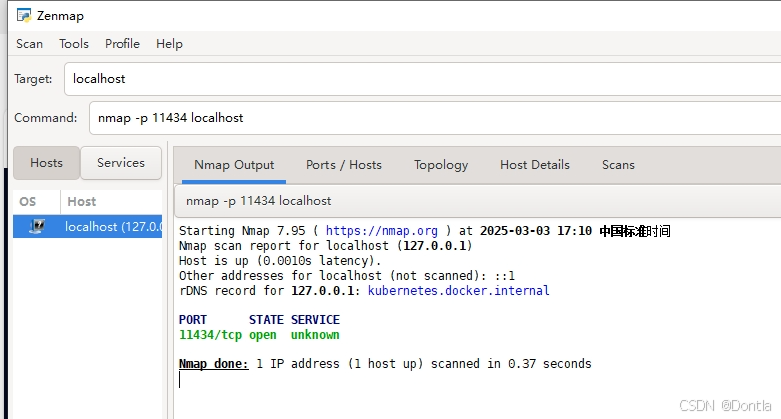
添加成功:
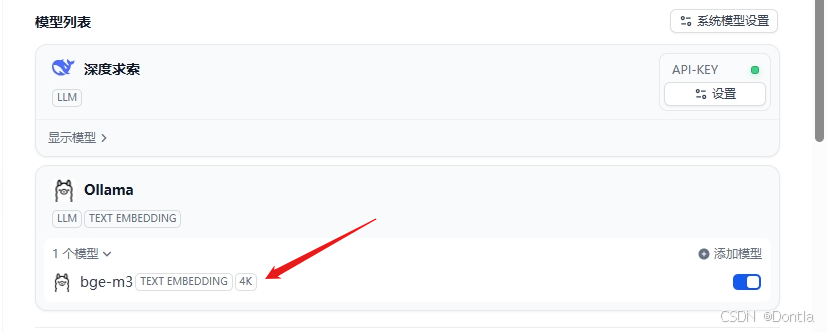
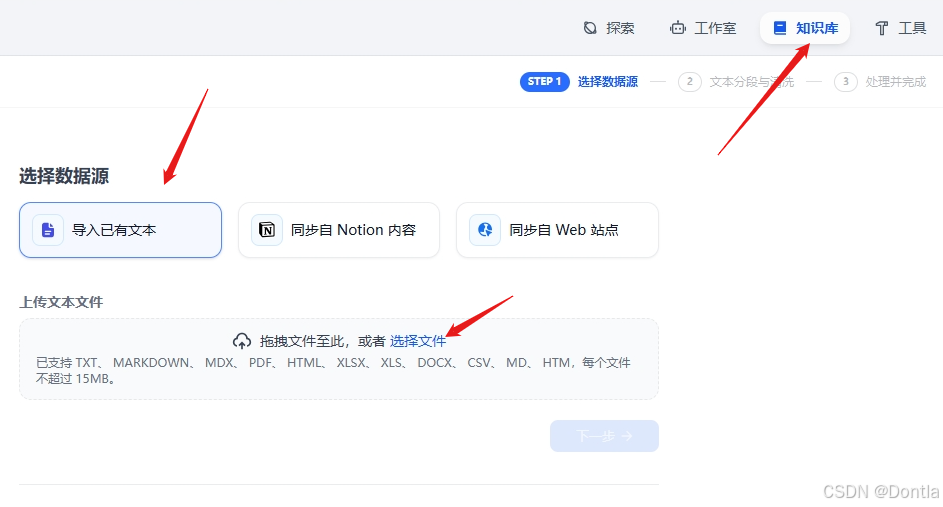
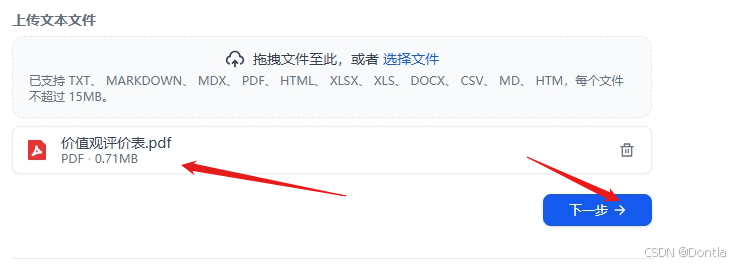
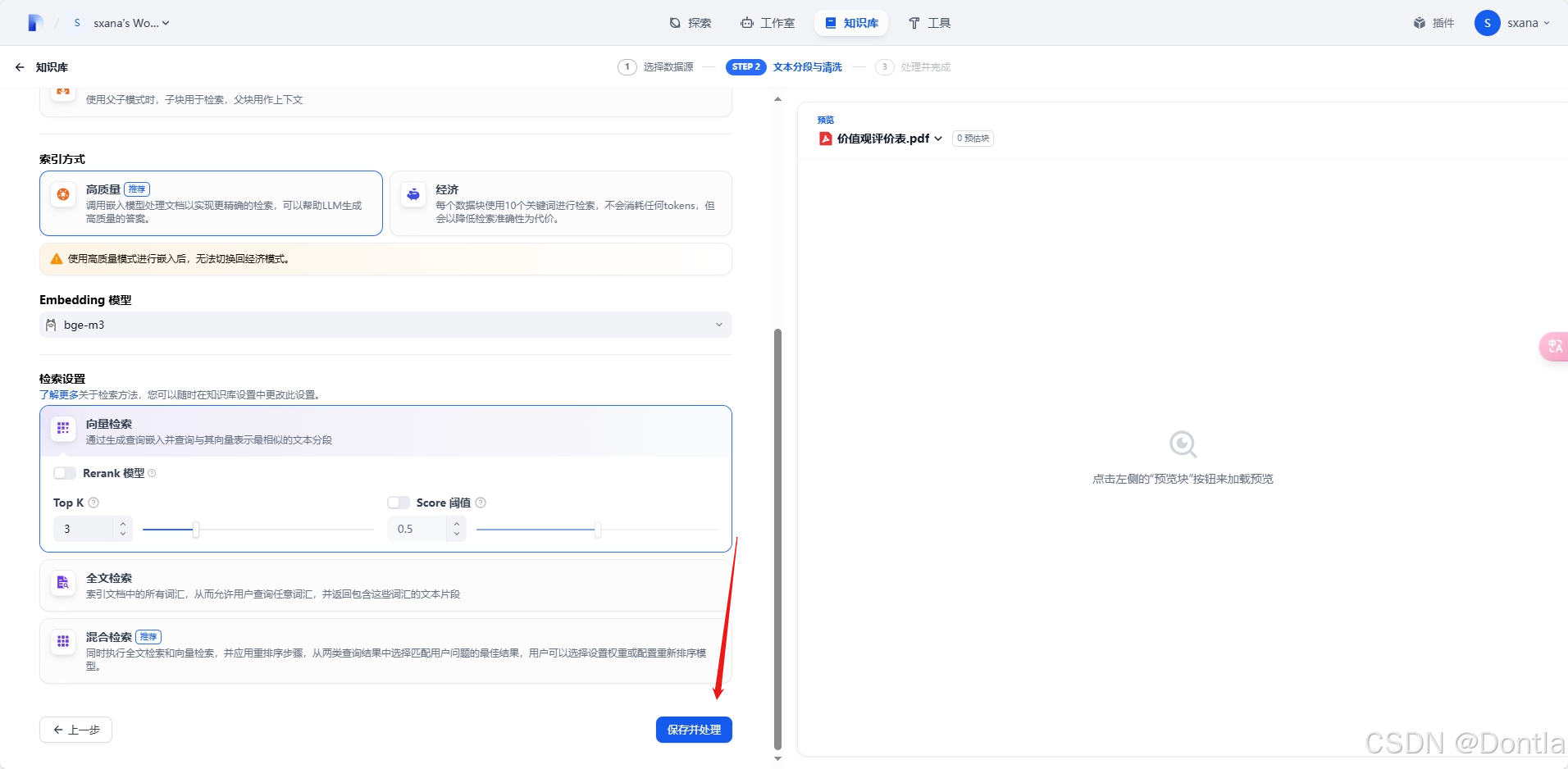
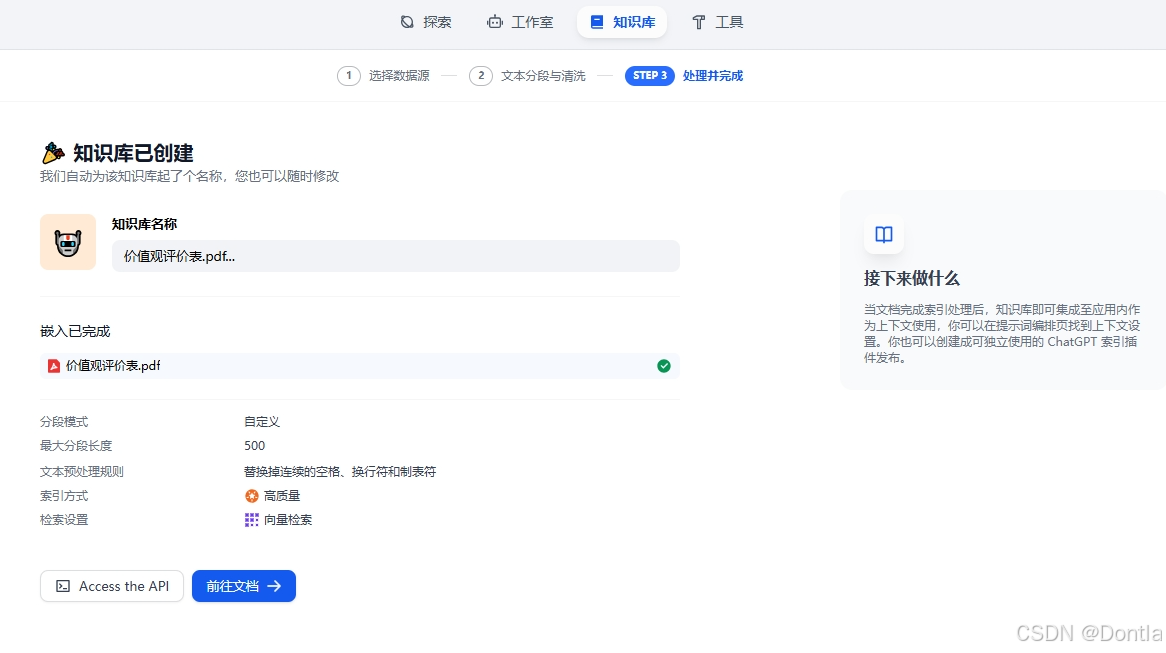
创建知识库
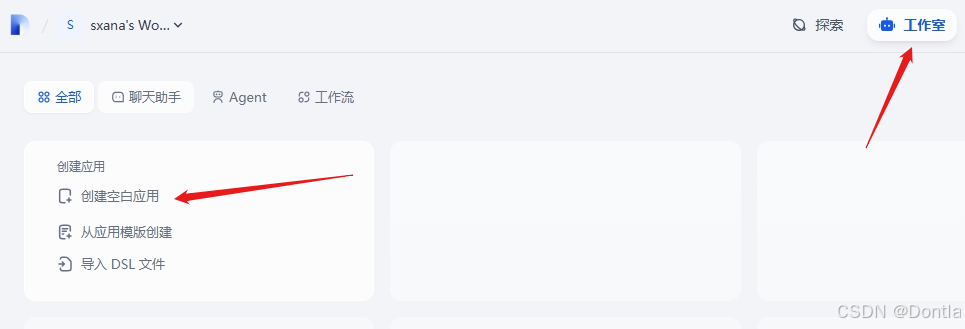
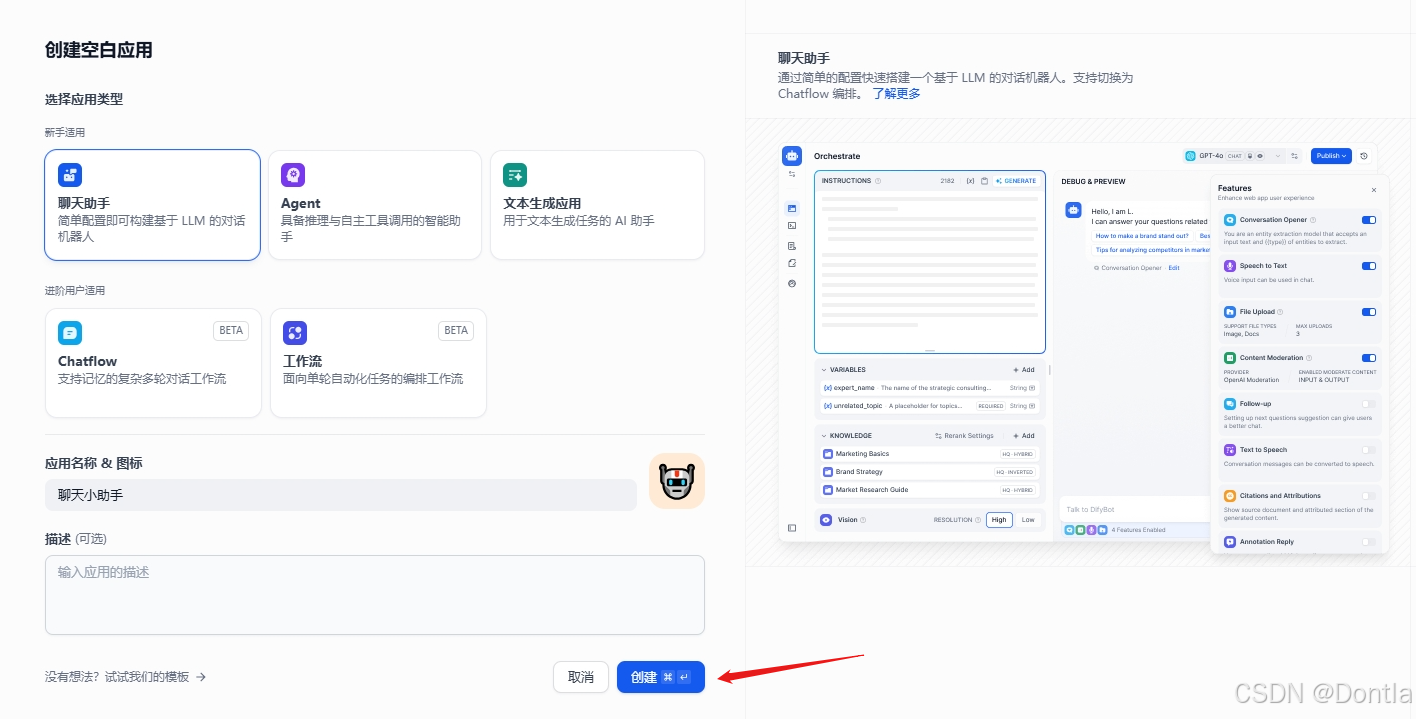
创建助手
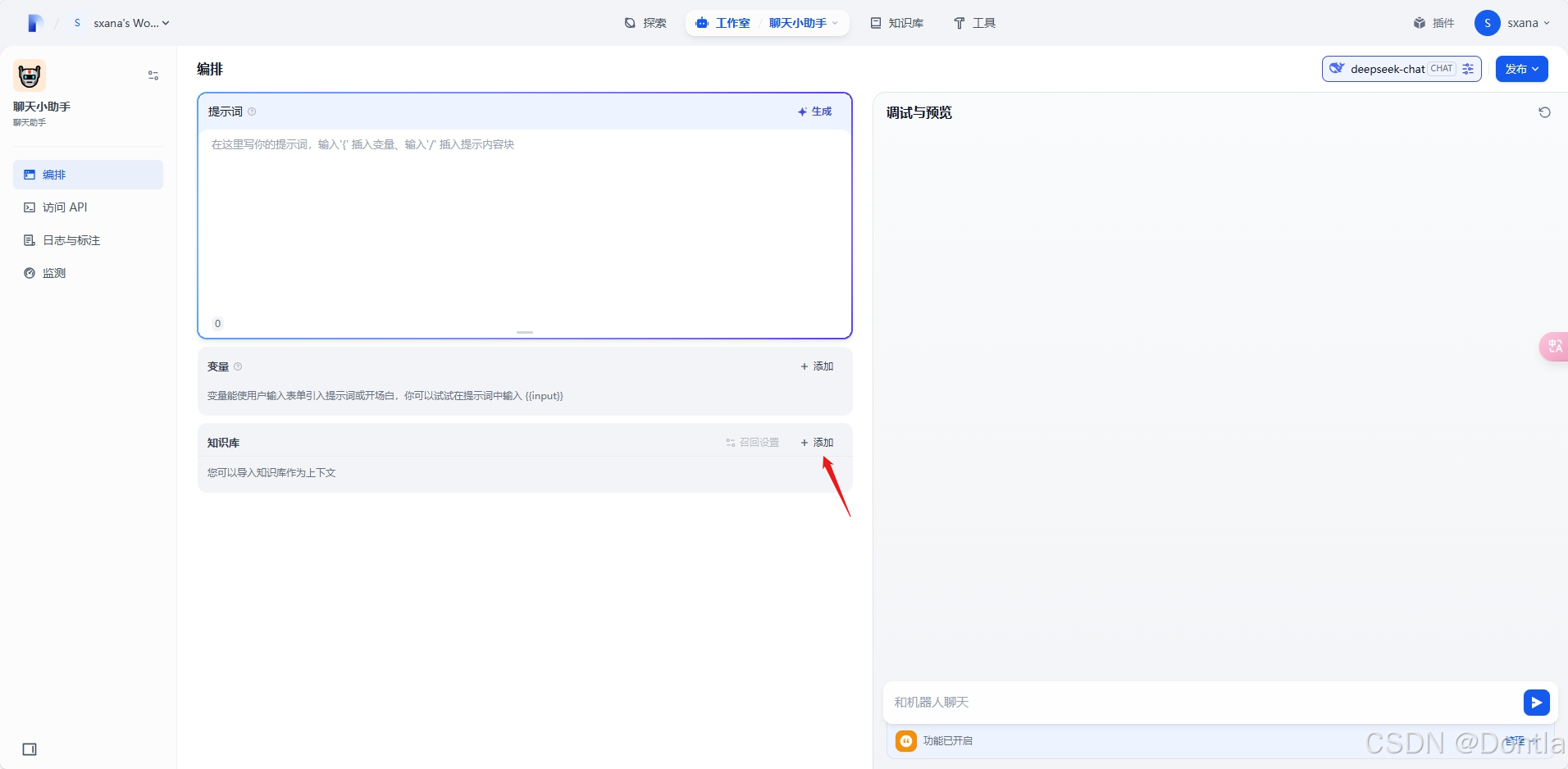
在聊天助手中导入知识库数据
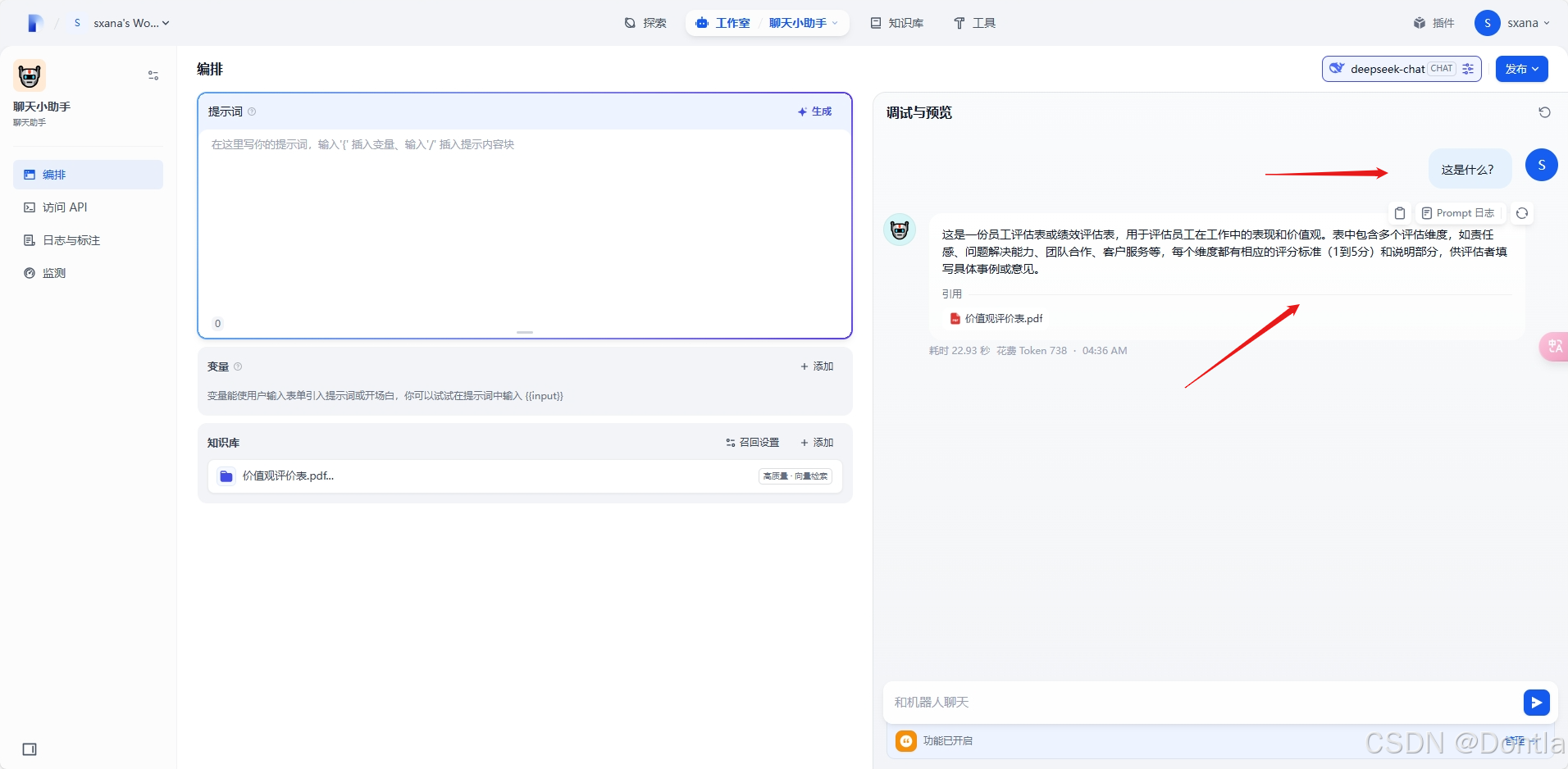
提问
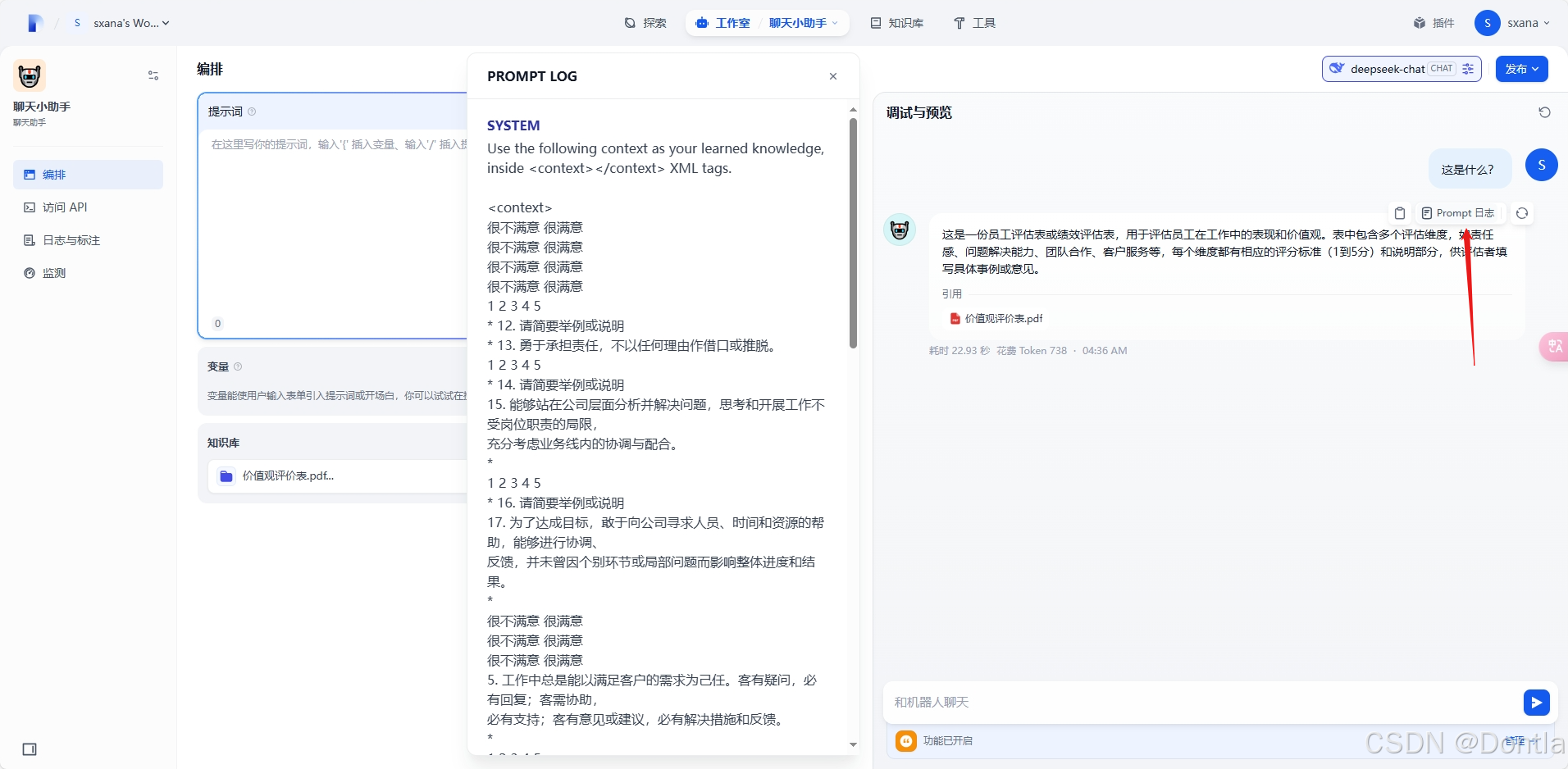
查看prompt日志
查看引用信息
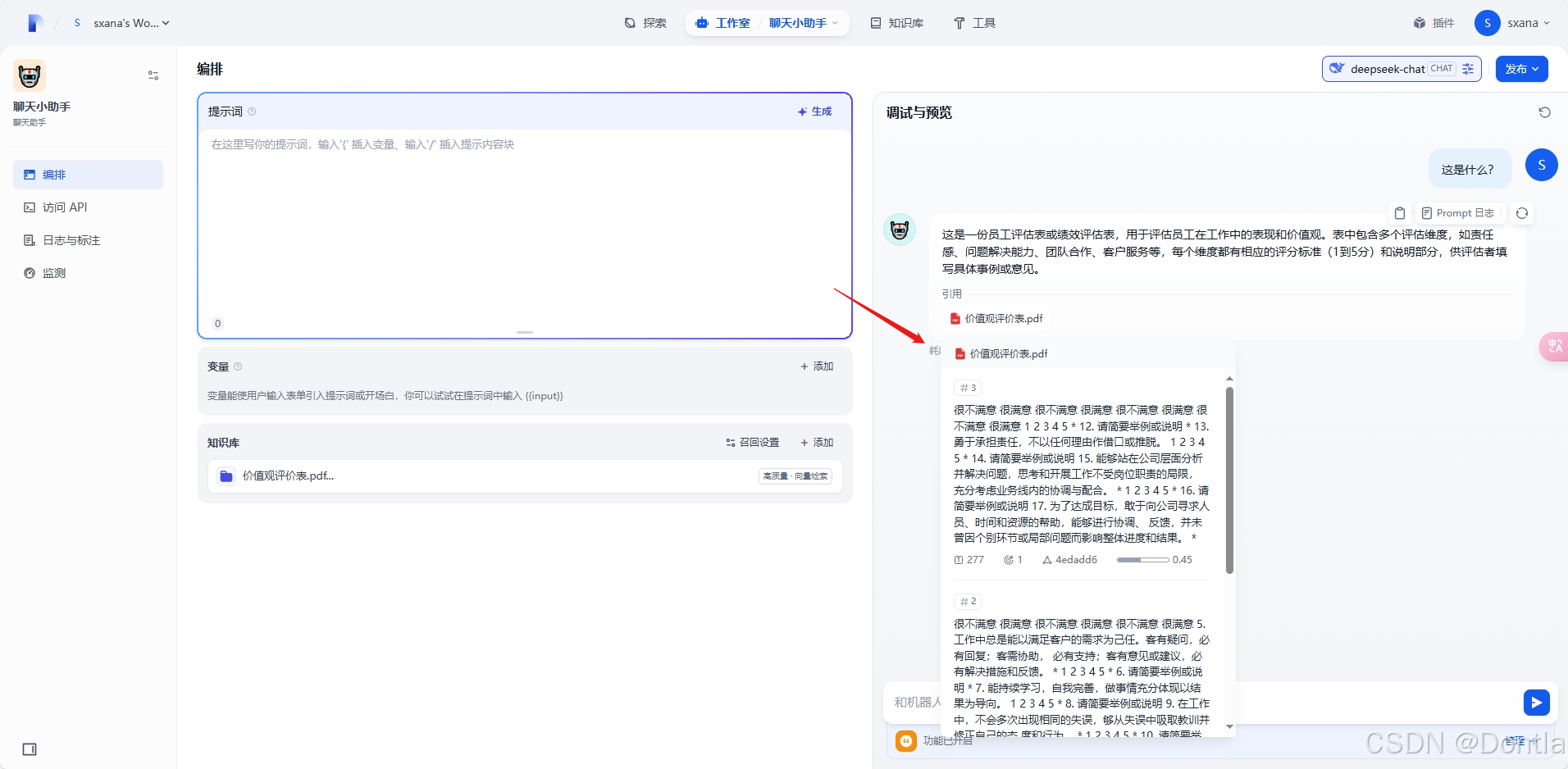
点击更新保存配置


















 3192
3192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











