







Dify 是一款开源的 AI 应用开发平台,旨在帮助开发者快速构建和部署基于大语言模型(LLM)的应用(如智能问答、知识库助手、客服机器人等)。它通过低代码/无代码的方式简化开发流程,同时支持灵活的自定义和扩展;
核心功能与特点:可视化编排、多模型支持、数据驱动与持续优化、一键部署、开源与安全;可以实现企业知识库助手,快速构建基于内部文档的智能问答系统;客服自动化,结合业务数据训练专属客服机器人;也可以作为内容生成工具,开发营销文案、代码生成等场景化应用;还可以制作AI 代理(Agent),创建多步骤任务自动执行的智能体;
Dify 适合希望快速落地 AI 应用的企业和开发者,平衡了易用性与灵活性。如需了解更多,可访问其 GitHub 仓库 ;这里我们通过搭建一个简单的工作流,一起来感受一下dify工具带来的便捷;
一、安装访问
Dify支持Docker部署,也可以访问这个网址注册账号进行访问,我选择后者;
# Docker部署
git clone https://github.com/langgenius/dify.git
cd dify
cd docker
cp .env.example .env
docker compose up -d二、 创建工作流
在我的这个案例里,我会用到三个模型,包括一个本地基于Ollama部署的大语言模型,一个本地基于Ollama部署的Emdding词嵌入模型,以及一个云端的大语言模型;两个大语言模型用于对用户提问以及RAG知识库信息的总结规划,Emdding词嵌入模型用于生成RAG知识库;不强制必须Ollama本地部署,只要有对应类型的模型即可,可以全部用云端模型;
2.1 创建RAG知识库
如下图所示,在导航栏点击‘知识库’,点击‘创建知识库’;
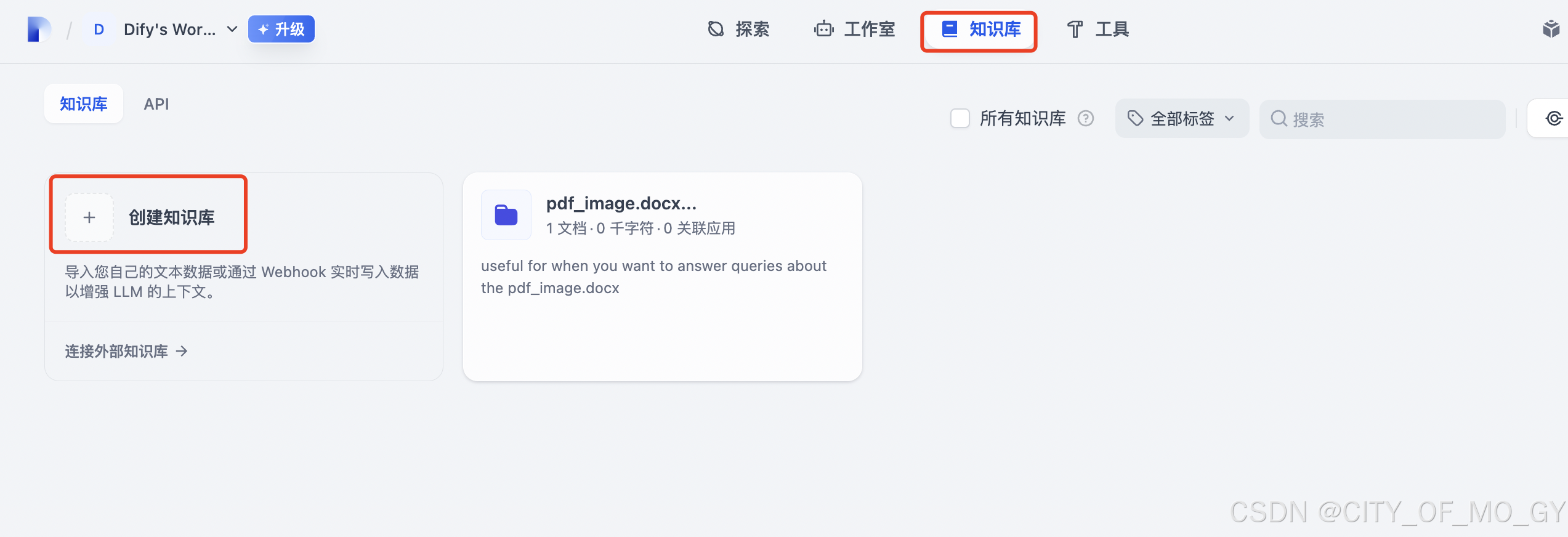
选择“导入已有文本”,选择本地文件进行上传,这里我提供一个简单的word文档;
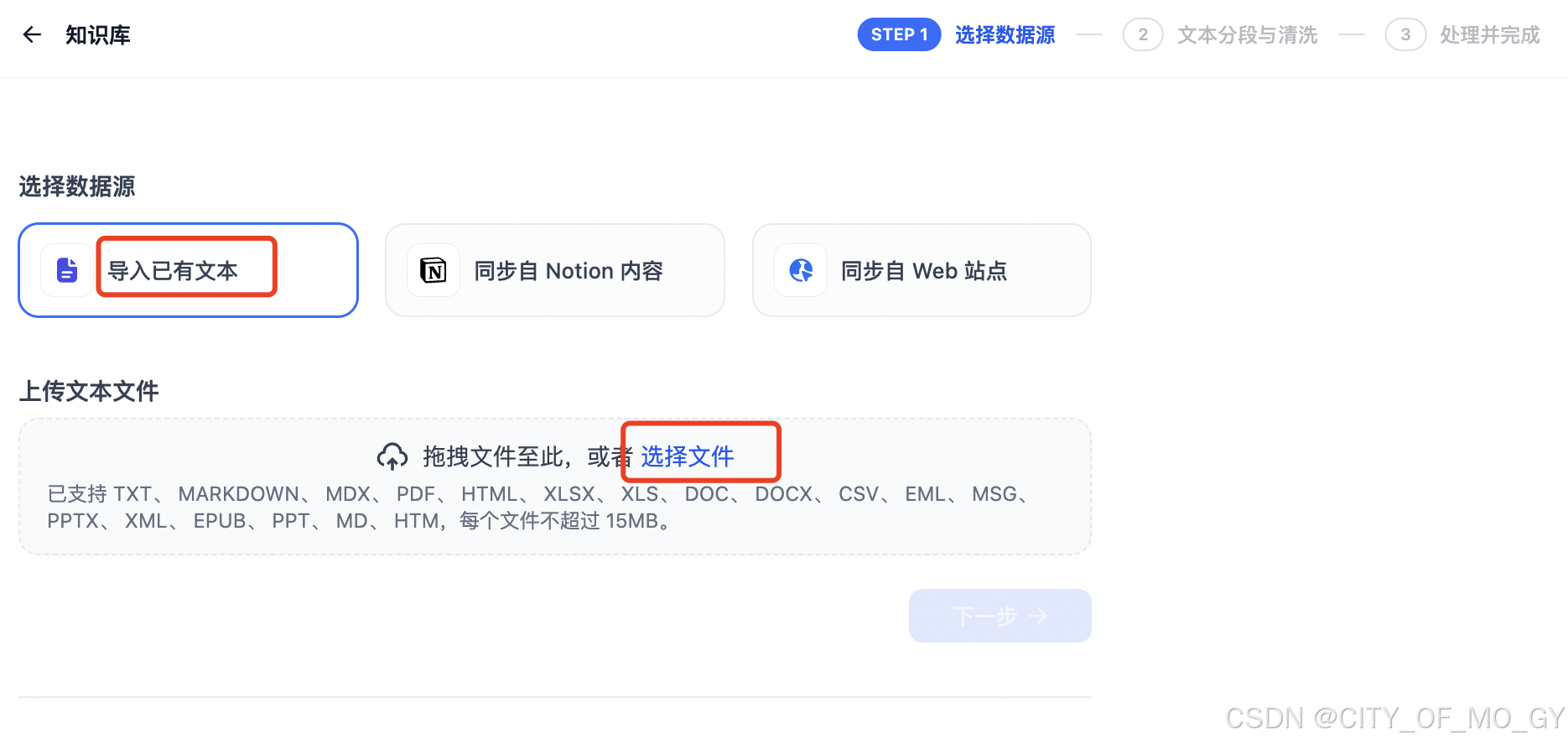
# word.docx
顺序刷题
1、 经营者收集、使用消费者个人信息,应当公开其收集、使用规则,不得违反法律、法规的规定和双方的约定收集、使用信息。
2、 经营者及其工作人员对收集的消费者个人信息必须严格保密,不得泄露、出售或者非法向他人提供。
3、 经营者应当采取技术措施和其他必要措施,确保信息安全,防止消费者个人信息泄露、丢失。在发生或者可能发生信息泄露、丢失的情况时,应当立即采取补救措施。
4、 经营者未经消费者同意或者请求,或者消费者明确表示拒绝的,不得向其发送商业性信息。
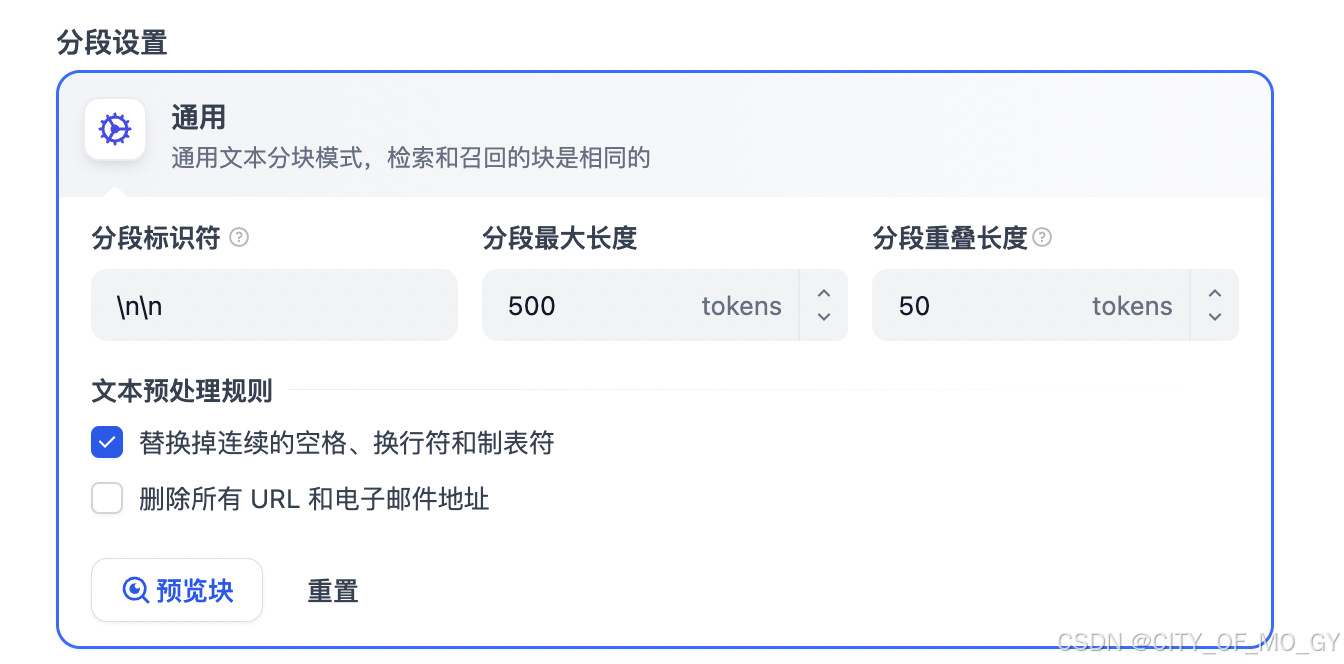
5、 金融机构应当将保护金融消费者合法权益纳入公司治理、()中统筹规划,落实企业文化建设和经营发展战略;人员配备和经费预算,完善金融消费者权益保护工作机制。首先会对上传的文本文档进行拆分,拆文为若干个块(chunk);分段标识符【\n\n】表示换行为拆分的分隔符,分段最大长度表示拆分后的每个块最长为500tokens,多出来的另作为新的块;为了防止切分导致语义存在歧义,进行分段重叠拆分,分段重叠长度表示连续块之间的tokens重叠量为50;拆分完成后可以点击‘预览块’在右侧进行查看;
 接下来就是定义索引方式,因为我们需要通过emdding模型做词嵌入向量转化,所以选择高质量索引;下面选择需要使用的词嵌入模型,我这边选择的是自己本地Ollama部署的一个emdding模型;检索设置可以选择输出检索到的前N个块进行输出,也可以设置置信度来筛选掉相似度计算较低的块;
接下来就是定义索引方式,因为我们需要通过emdding模型做词嵌入向量转化,所以选择高质量索引;下面选择需要使用的词嵌入模型,我这边选择的是自己本地Ollama部署的一个emdding模型;检索设置可以选择输出检索到的前N个块进行输出,也可以设置置信度来筛选掉相似度计算较低的块;
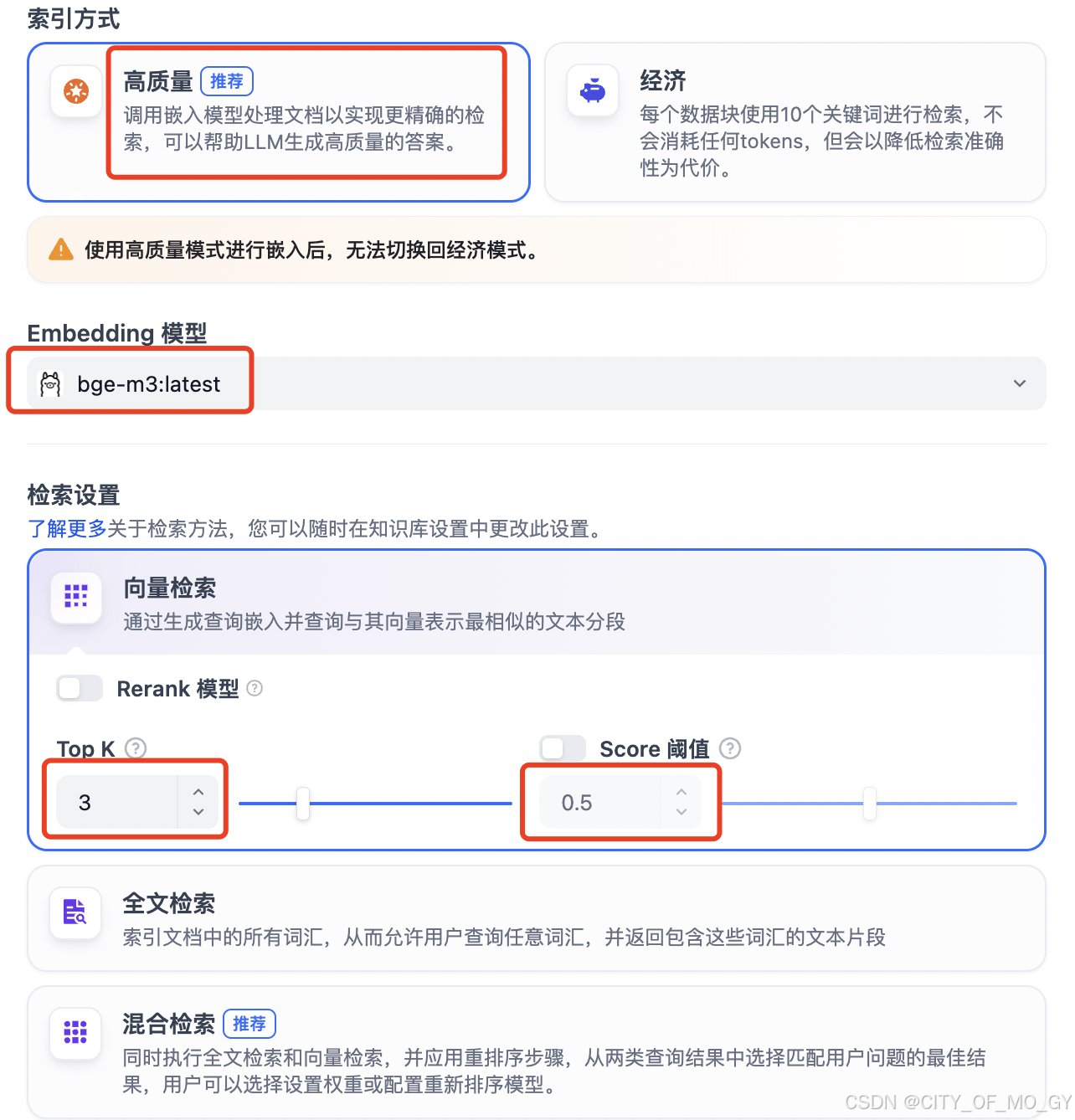
全部设置完成后点击‘保存并处理’就创建好RAG知识库了;

2.2 创建工作流
点击‘工作室’,点击‘创建空白应用’;
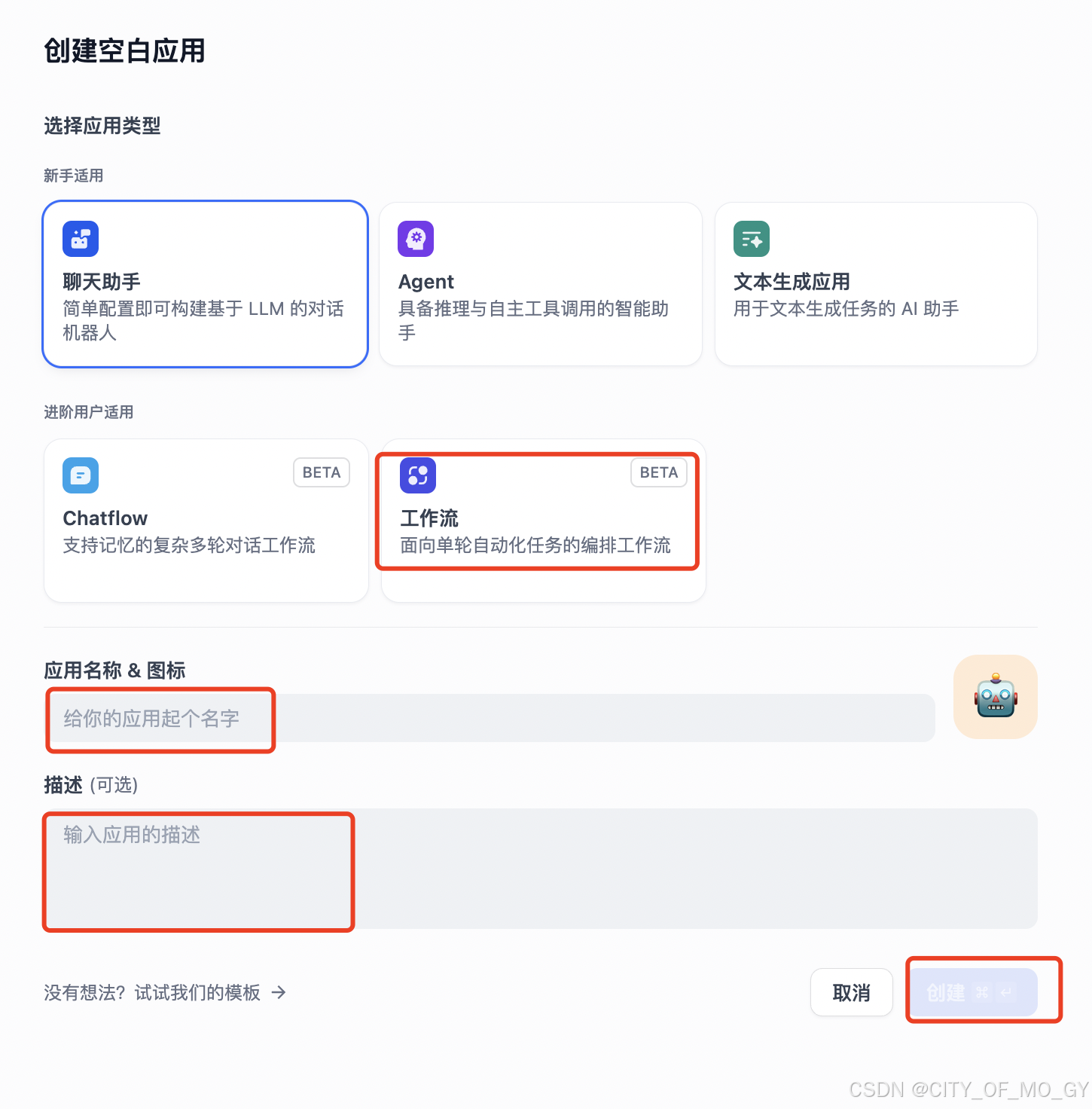
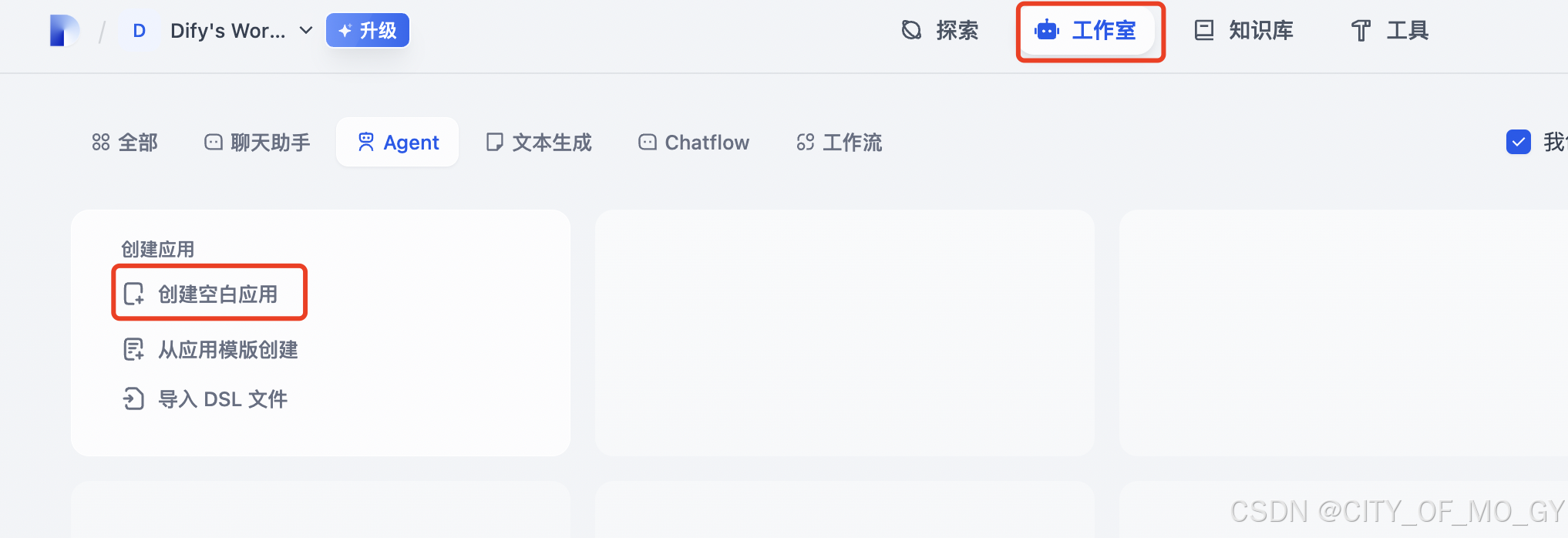 按照对应要求,选择‘工作流’,设置工作流名字及描述,点击‘创建’;
按照对应要求,选择‘工作流’,设置工作流名字及描述,点击‘创建’;
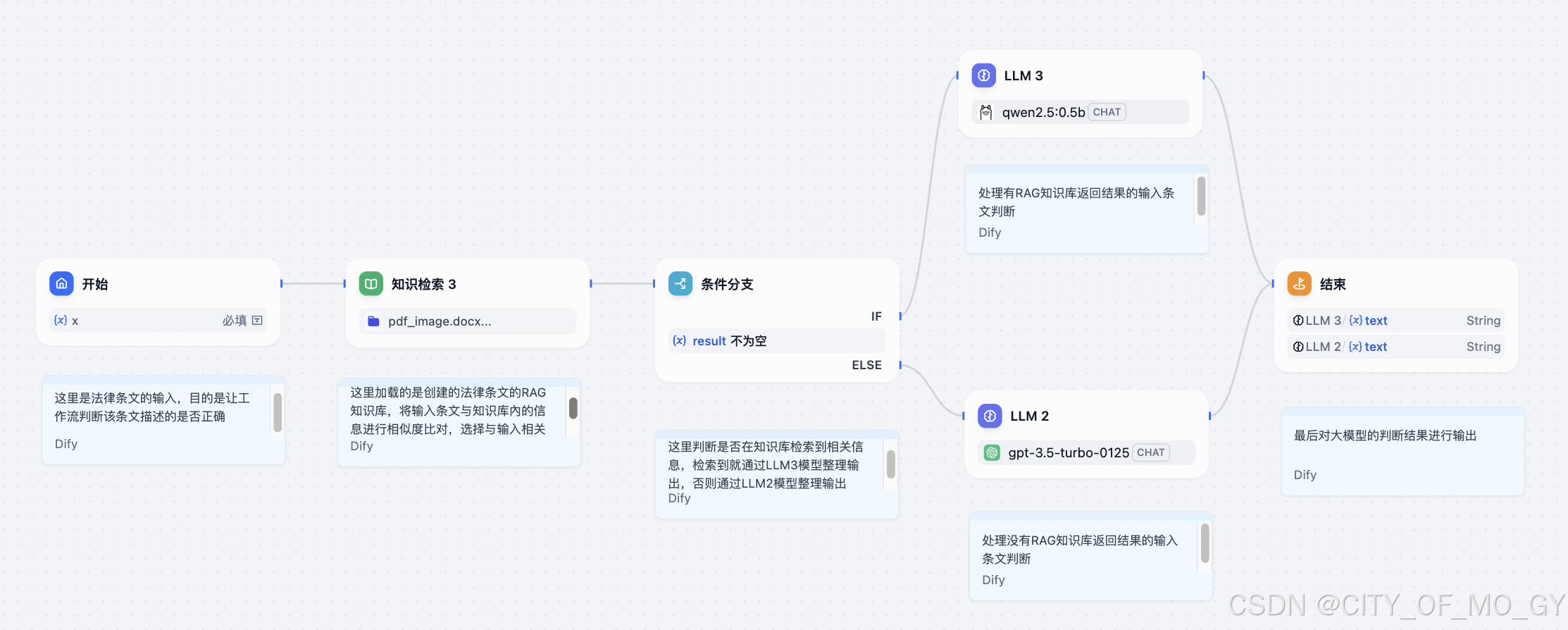
下面是整个工作流的全貌,通过这个流程可以很明了的看出它的工作逻辑;接下来我们就一个一个节点的创建;
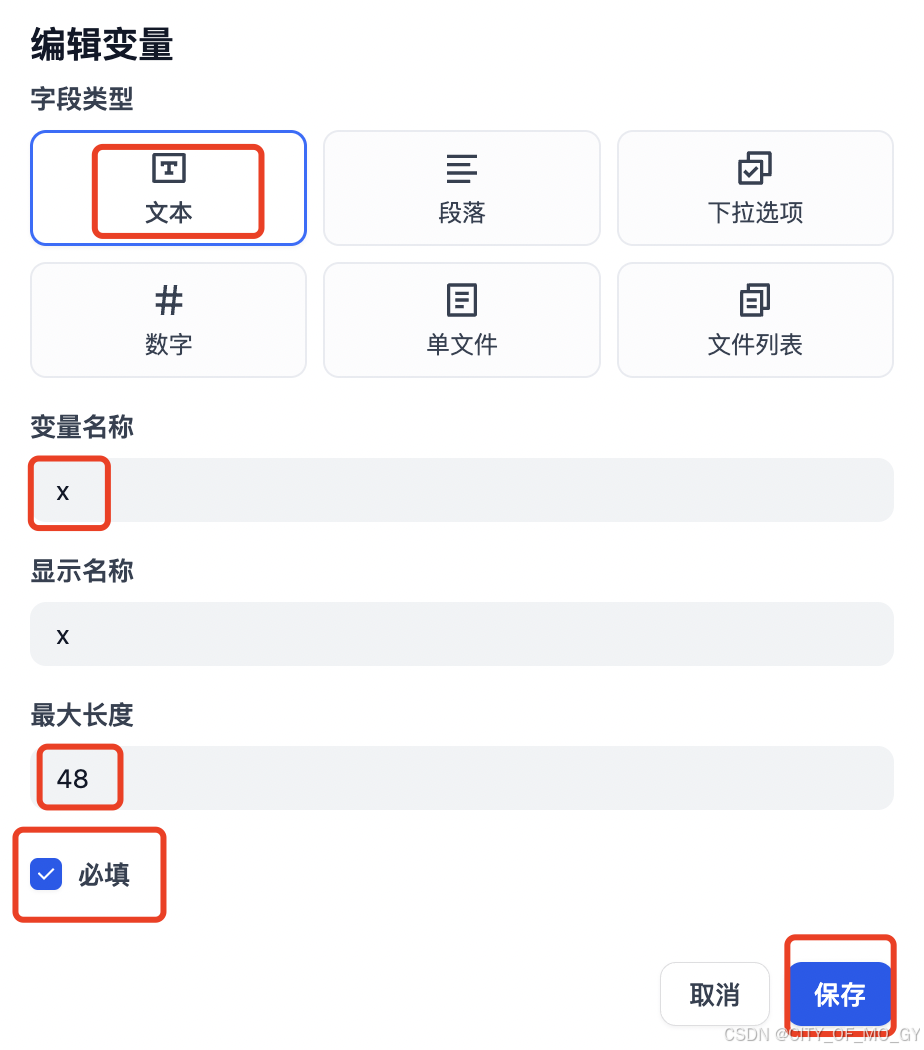
2.2.1 创建开始节点
开始节点需要定义整个工作流的输入,这里我们的输入是需要判断是否正确的相关法律条文,属于文本信息,所以进行如下设置,变量名称可以自己定义,最大长度表示输出文本字符串的最大长度,可以设置的大一点;
2.2.2 创建知识检索节点
如下图添加知识检索节点;
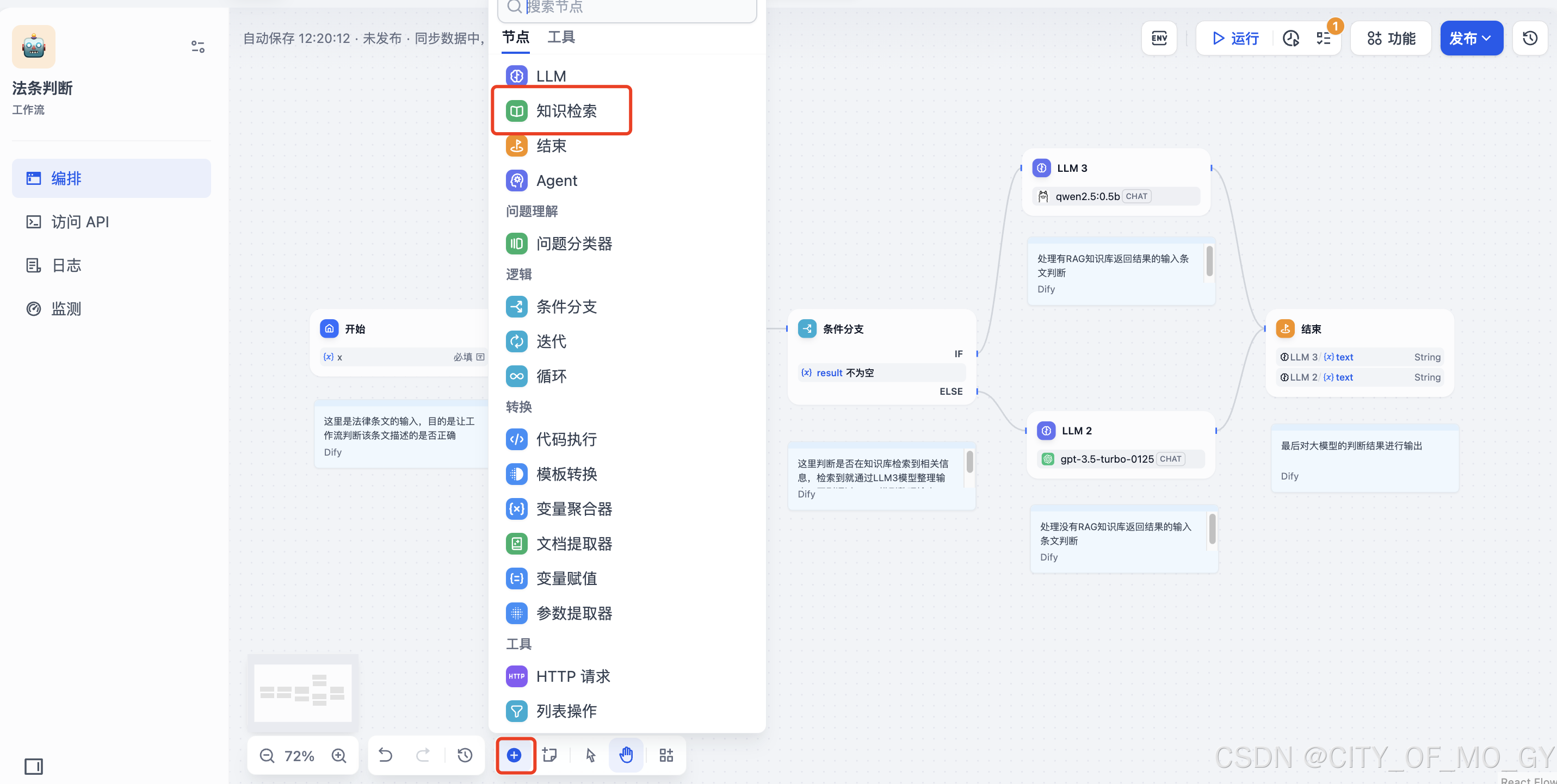
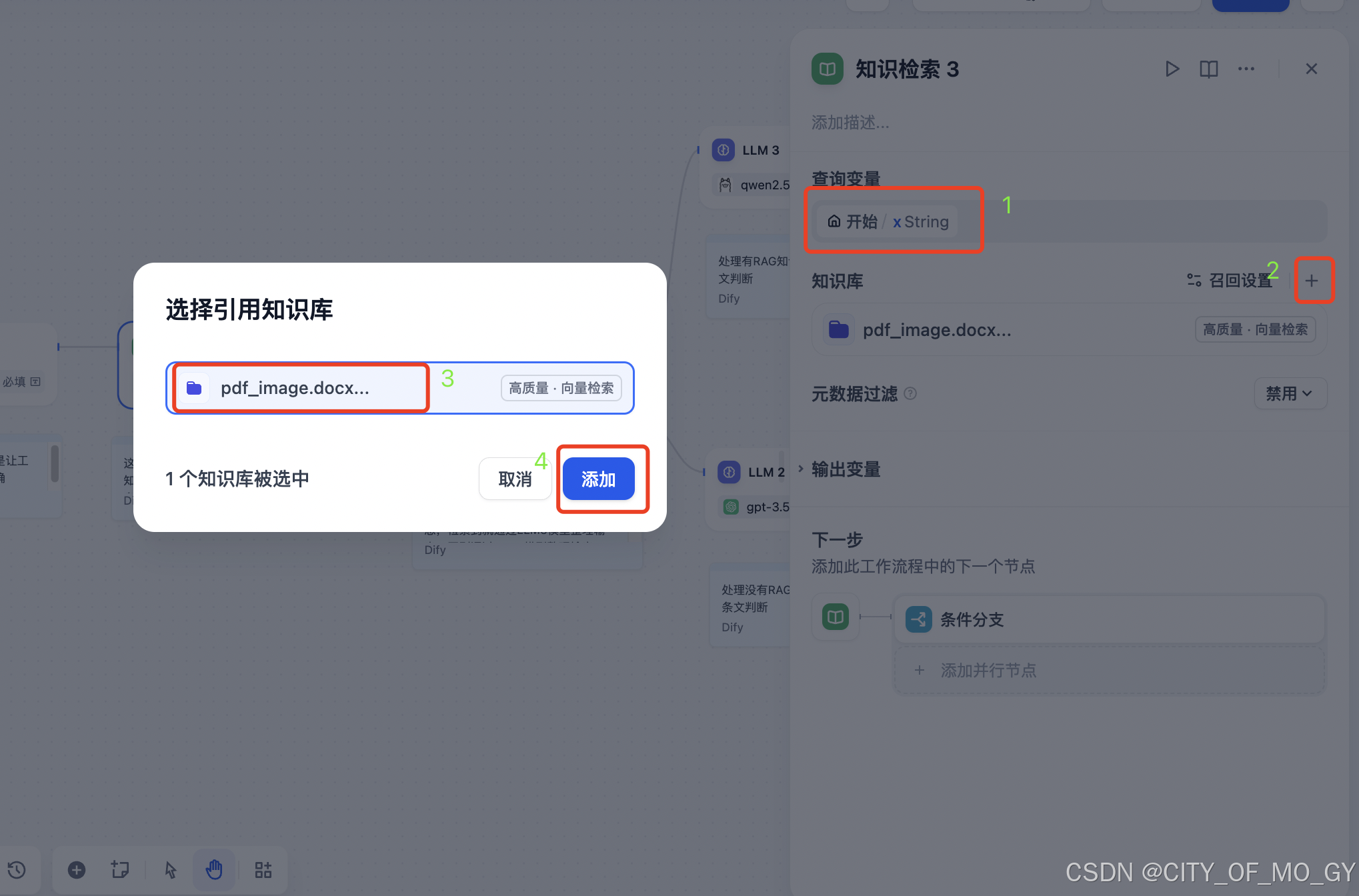
如下图设置查询变量为开始节点的输入变量,点击‘+’添加知识库,选择上面创建好的知识库进行添加;
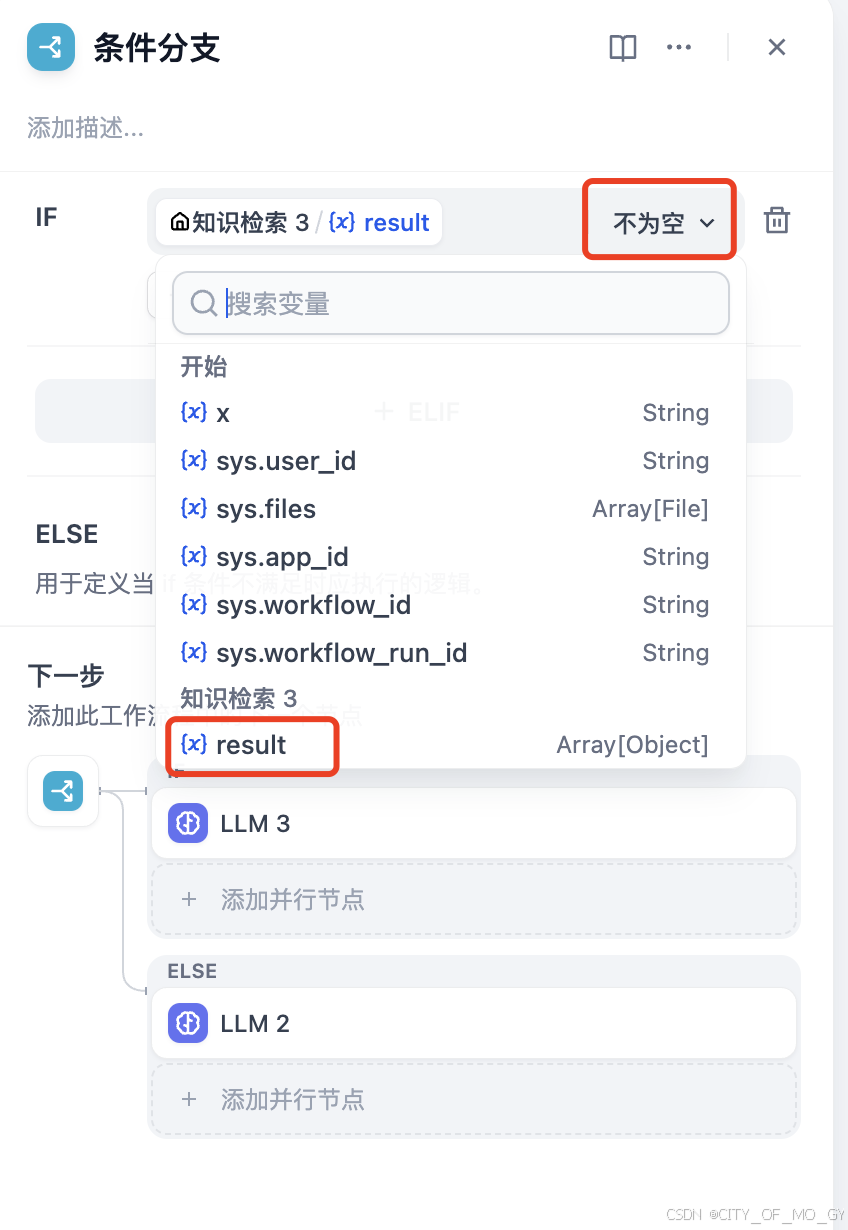
2.2.3 创建条件分支节点
和创建知识检索节点一样如法炮制,选择知识检索节点的输出变量作为条件判断;
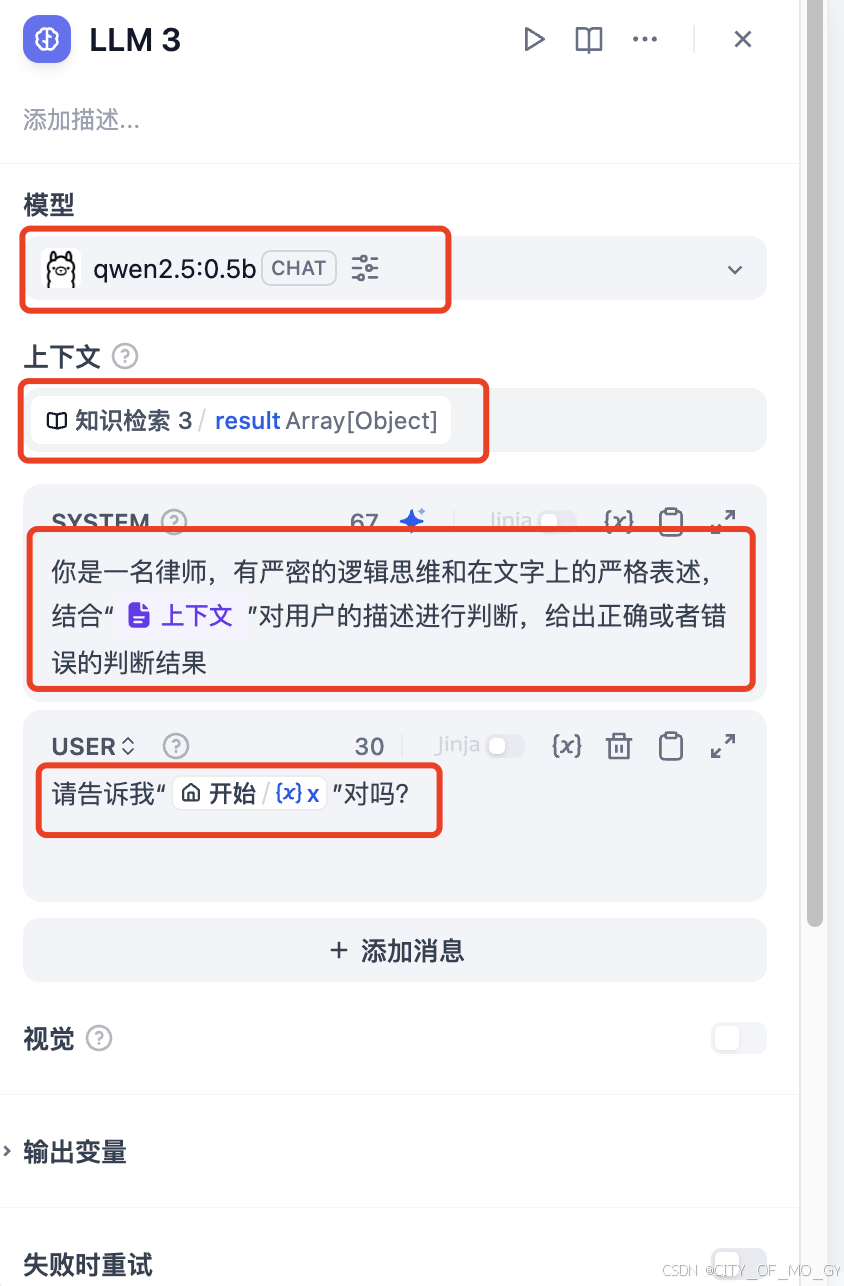
2.2.4 创建大模型节点
还是同样的方式,添加两个大模型节点;
2.2.4.1 处理RAG的大模型
对于处理有RAG知识库返回的大模型的设置,选择适合的大模型,上下文输入选择RAG知识检索节点的输出;然后在系统指令里给大模型指定任务,包含RAG的输出结果;然后在用户指令里填写对大模型的提问请求,包含开始节点的条文输入;
2.2.4.2 处理RAG为空的大模型
对于处理没有RAG知识库返回的大模型的设置,同样选择适合的大模型,不同的是这里的上下文选择开始节点的输入变量;系统指令里给大模型制定任务,但无需包含上下文信息;用户指令里向大模型提出请求,包含上下文变量,即开始节点输入的法律条文变量;
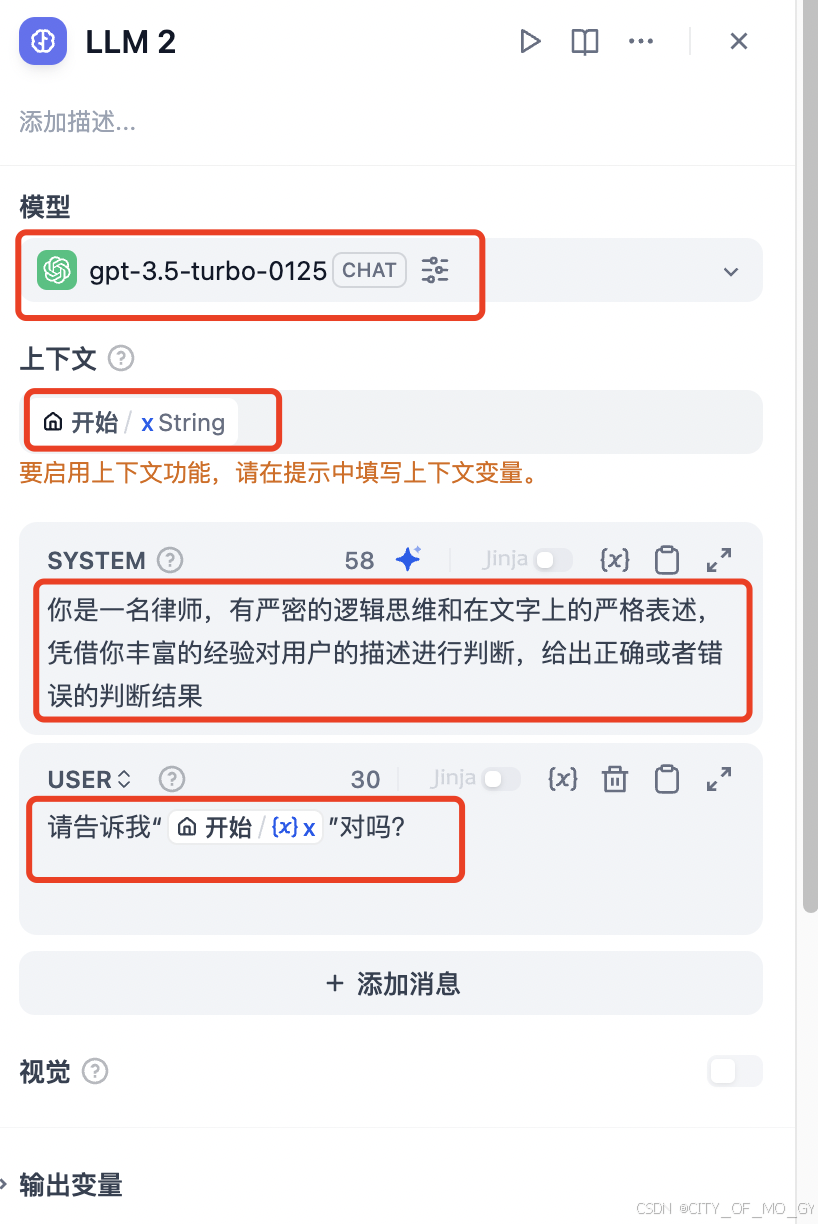
2.2.5 创建结束节点
添加两个大模型的输出,注意输出变量名要相同,因为两个模型的输出是相互独立的,不存在同时输出结果的情况;
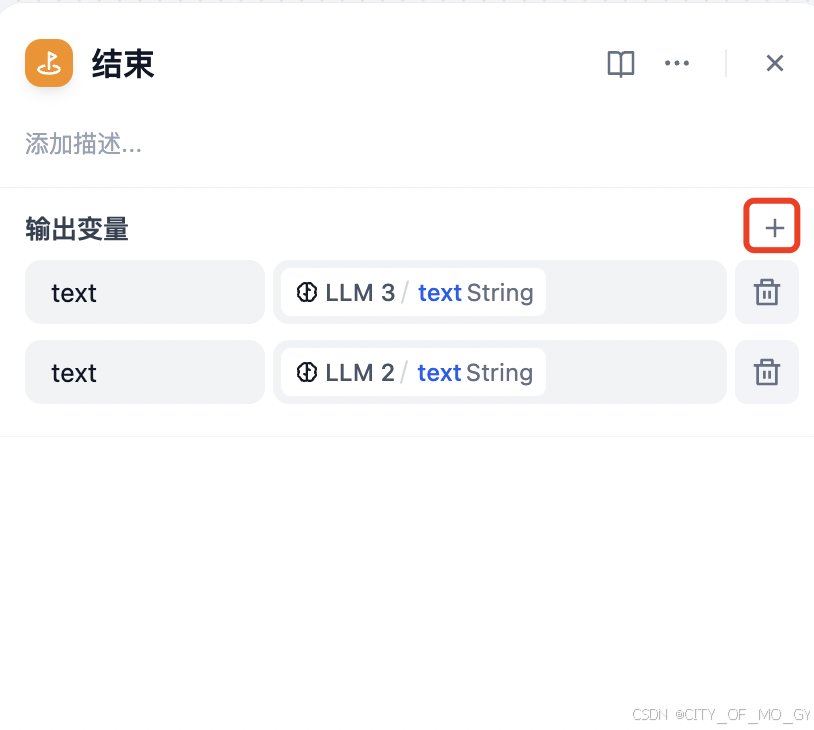
三、运行工作流
3.1 测试RAG知识库有信息的案例
3.1.1 测试案例
点击‘运行’,输入需要判断是否正确的相关法律条文,例如:“经营者及其工作人员对收集的消费者个人信息无需保密,可以向他人提供”,点击‘开始运行’;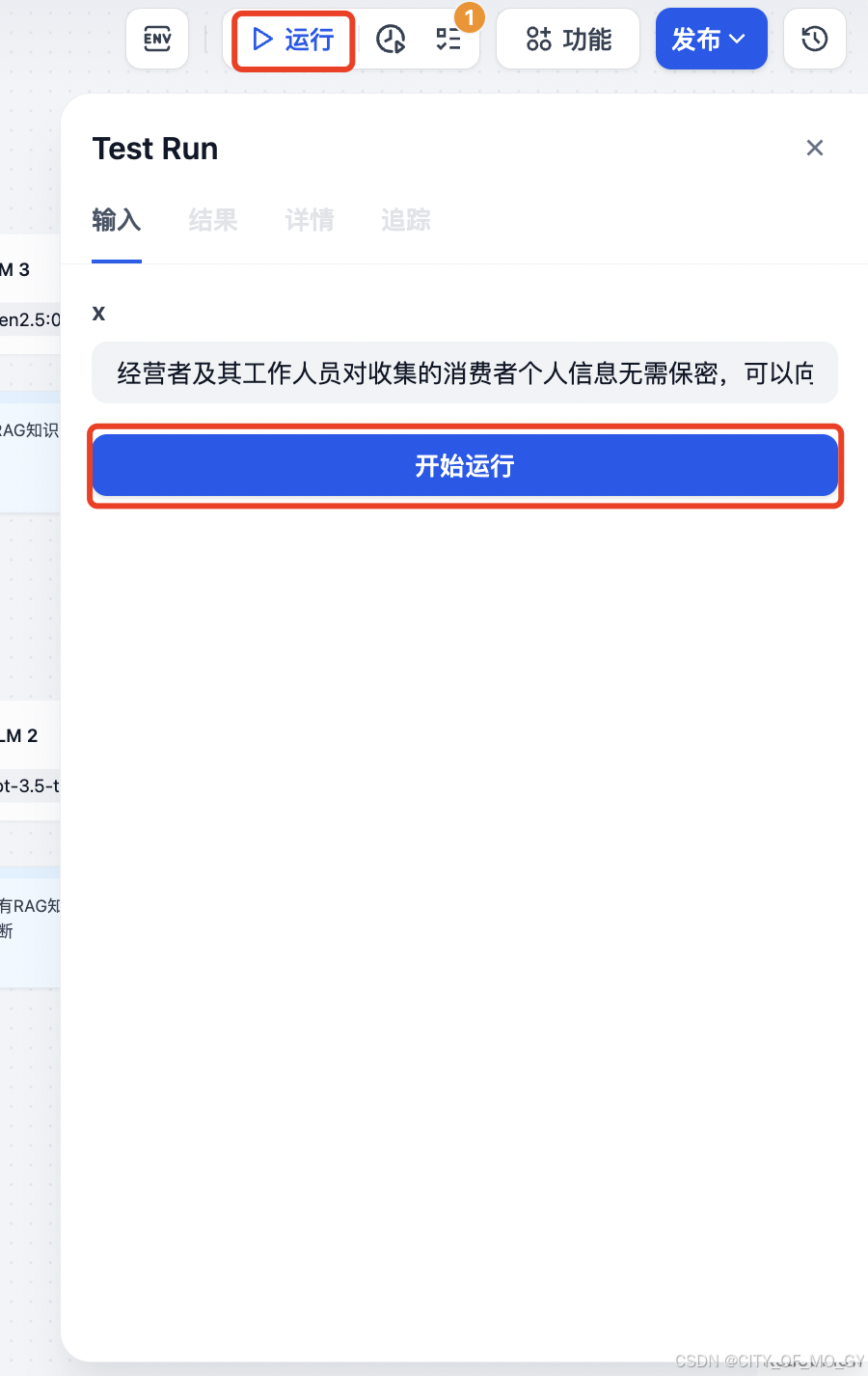
3.1.2 测试结果
我们可以看到工作流经过上面的大模型进行信息整理很判断,最终给出了对应结果;
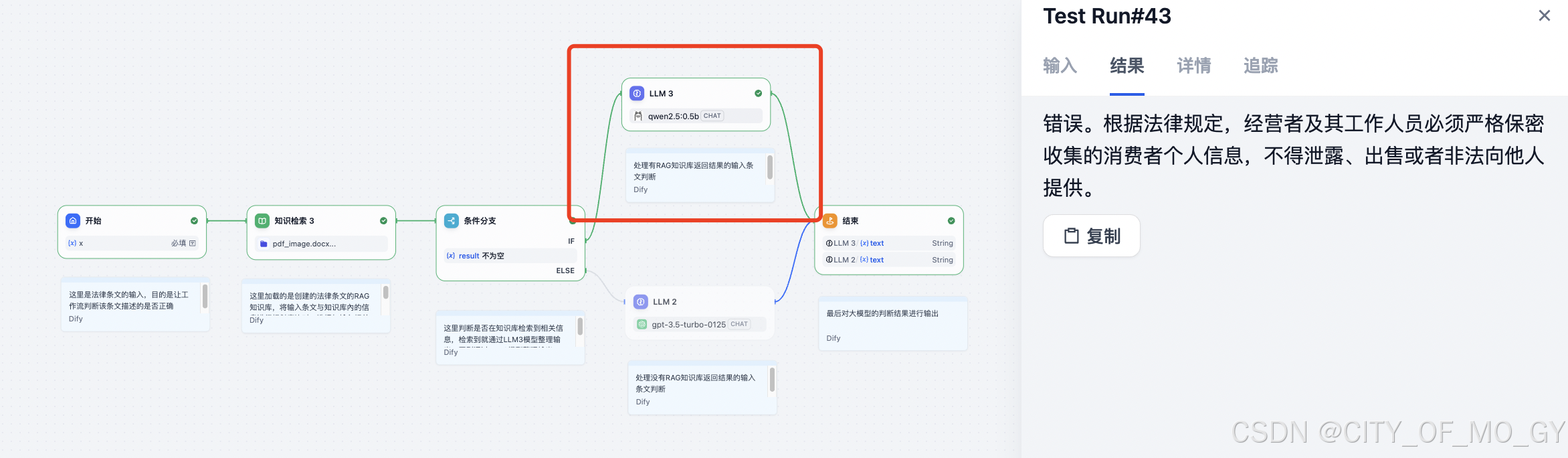
3.2 测试RAG知识库没有信息的案例
3.2.1 测试案例
点击‘运行’,输入需要判断是否正确的相关法律条文,例如:“融机构应当对金融产品和服务的风险及专业复杂程度进行评估并实施分级动态管理”,点击‘开始运行’;
3.2.2 测试结果
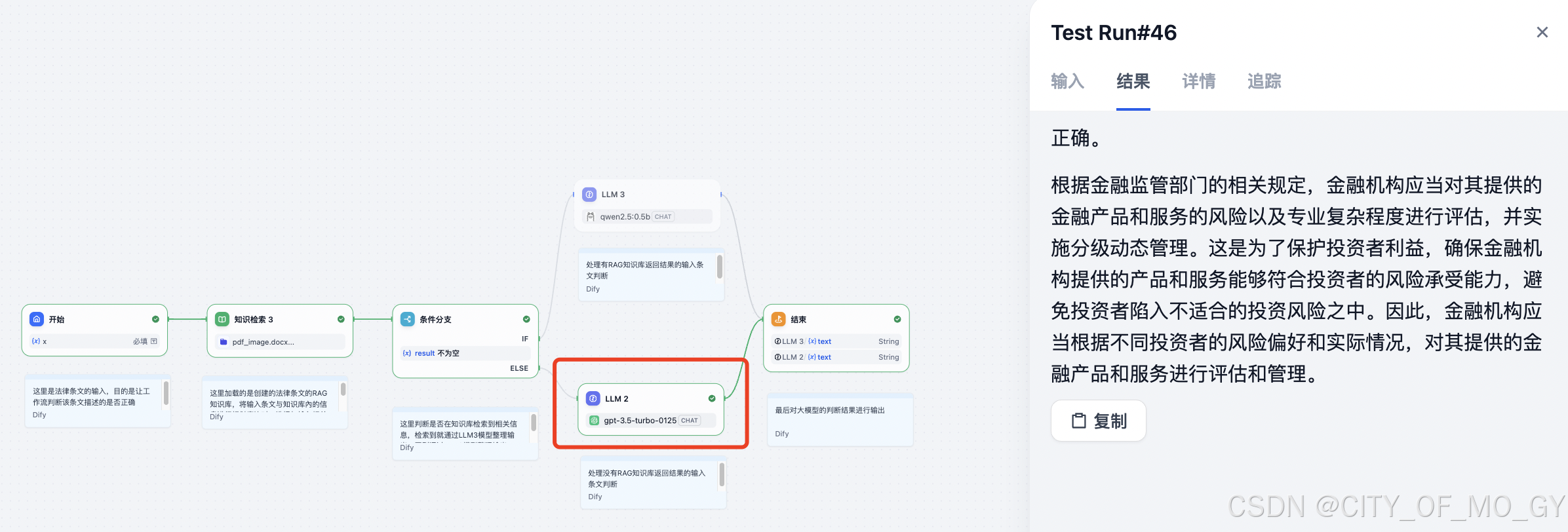
我们可以看到工作流经过下面的大模型进行信息整理很判断,最终给出了对应结果;

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









