







目录
4.2019数据融合比赛数据集(2019 data fusion contest dataset)
合理利用有效的数据集是充分发挥算法性能的重要环节。目前,许多研究机构为学者们提供公共可靠的、开源的三维数据集。数据集分为两类:合成数据集和真实场景数据集。
1.ModelNet——分类
Princeton ModelNet project 是为computer vision, computer graphics, robotics and cognitive science的研究者提供全面、干净的 3D CAD 模型集。包括ModelNet10、ModelNet40、Aligned- 40。一个很基础的点云分类数据集。
其作法是:
- 借用SUN Database的统计数据列出 the most common object categories;
- 然后在网上搜集 3D CAD models belonging to each object category;
- 然后人工使用in-house designed tool with quality control 检查每个CAD model 是否属于指定的类别;
- choose 10 个流行的对象类型,并删除其它models;
- aligned 这10类模型集的方向,形成>>ModelNet10.zip。
1.1ModelNet10
该数据集被用于train网络,3D ShapeNets: A Deep Representation for Volumetric Shapes
1.2ModelNet40
该数据集包含有40个categories的CAD模型。
1.3ModelNet40_Aligned
由NS等人提供,论文是Orientation-boosted Voxel Nets for 3D Object Recognition.
1.4modelnet40_ply_hdf5_2048
链接:https://pan.baidu.com/s/1IojvI2jI2PkxRVSQxeFOzw
1.5说明
ModelNet数据集内全为Object File Format (.off )文件,无法直接打开。可以使用MeshLab / CloudCompare打开。
Object File Format的格式如下,OFF numVertices的中间因存在space或者enter。否则meshlab打开出错。ModelNet40的部分模型存在该问题。
OFF numVertices numFaces numEdges
x y z
x y z
... numVertices like above
NVertices v1 v2 v3 ... vN
MVertices v1 v2 v3 ... vM
... numFaces like above
2.S3DIS——分割-室内
2.1 S3DIS简介
S3DIS数据集是斯坦福大学开发的带有像素级语义标注的语义数据集,包含了rgb,depth,3d点云、mesh等。该数据集被收录在2D-3D-S dataset内。一个室内点云语义分割和实例分割(实例单独标注)数据集。相关paper.
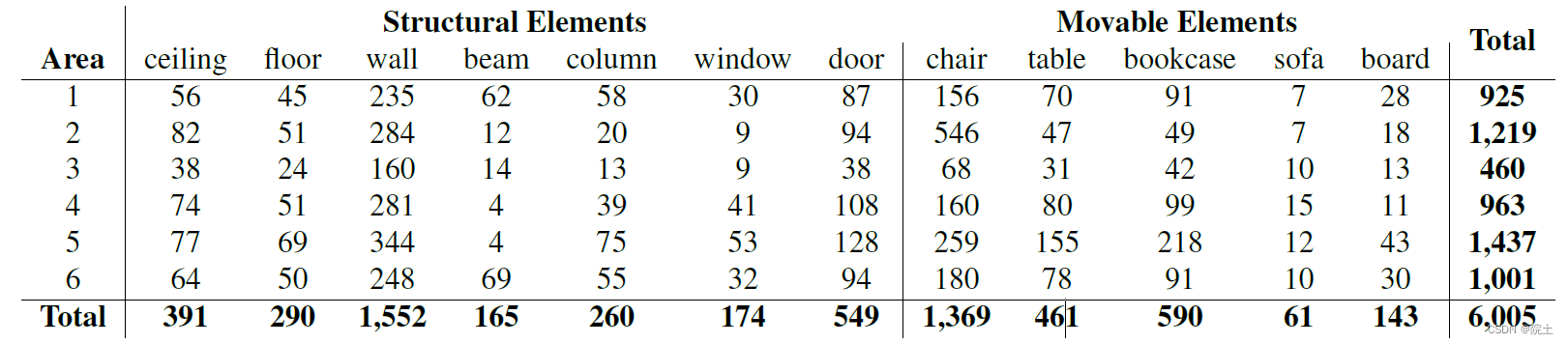
6个区域:Area1、Area2、Area3、Area4、Area5、Area6
11种场景(scene categories):office, conference room, hallway, auditorium, open space, lobby, lounge, pantry, copy room, storage, WC
13个结构元素(structural elements):ceiling、floor、wall、beam、column、window、door、table、chair、sofa、bookcase、board 、clutter (在Annotations内)
在6个区域中,每个区域包含有部分场景,每个场景包含有整体未标注的点云数据和Annotations的数据,对应Annotations内包含有独立的语义元素(xyzrgb)。
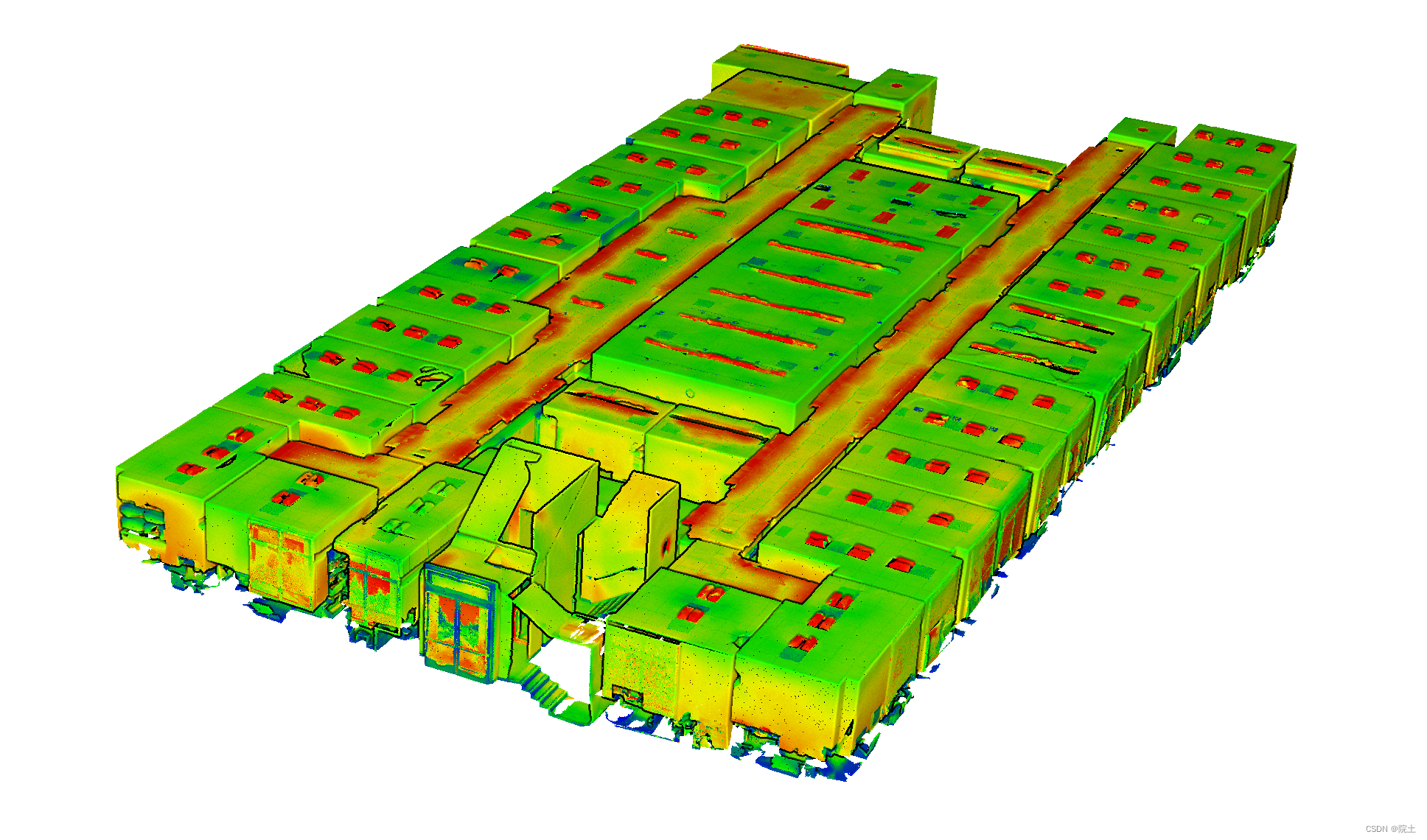
Area_1的整体点云效果如图:

2.2 Collection and Processing
使用Matterport相机收集数据,该相机结合了3个不同角度的结构光传感器,在每个扫描位置360°旋转期间捕捉18幅RGB和深度图像。每个位置以60°为增量进行360°扫描,获得raw RGB-D图像,以此为基础获取其他格式的rgbd数据,并通过sampling the meshes 获取点云,然后在点云上进行semantically annotated
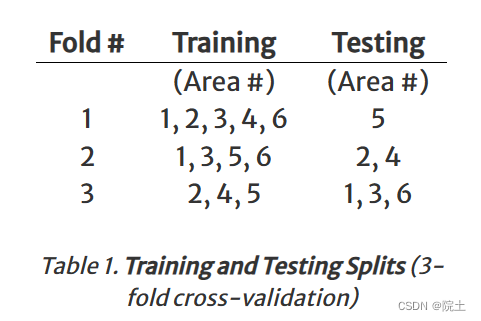
2.3 Train and Test splits
因为六个区域内的建筑类型外观特征是相似的,为了泛化,就defined standard training and testing splits. 并且遵循分层交叉验证(Cross-Validation)
3.ScanNet——分割-室内
3.1 ScanNet简介
该数据集是由斯坦福 Angela Dai 采用 RGB-D capture system 获取的视频室内场景数据集,通过1513次室内场景扫描获得 250 万个视图,分为 21 个类别。通过 3D camera poses, surface reconstructions, instance-level semantic segmentations进行了注释。该数据集可用于3D object classification, semantic voxel labeling, CAD model retrieval。

4.ShapeNet——分类、部件分割
4.1 ShapeNet 简介
ShapeNet is an ongoing effort to establish a richly-annotated, large-scale dataset of 3D shapes. We provide researchers around the world with this data to enable research in computer graphics, computer vision, robotics, and other related disciplines. 链接:ShapeNet
该数据集每个类别的点云数据规模都很小,大概在2000多个点左右。参考
- 类别丰富:ShapeNet 数据集涵盖了数十个常见物体类别,如椅子、汽车、飞机、人体等。每个类别都有大量的三维模型与之对应。
- 三维模型:每个模型由一组顶点和面构成,并包含了模型的几何信息和拓扑结构。
- 元数据:除了几何信息外,数据集还提供了对模型的丰富描述数据,如对模型的标签、类别、姿态、尺寸等的注释。

4.2 ShapeNet 组成
ShapeNet包括ShapeNetCore和ShapeNetSem
ShapeNetCore是完整ShapeNet的子集,具有单一干净的3D models以及手工标注的对齐的模型。包含55 common object categories,涉及到51300 unique 3D models。The 12 object categories of PASCAL 3D+, a popular computer vision 3D benchmark dataset, are all covered by ShapeNetCore.
ShapeNetSem是一个更小,标注信息更加全面的子集,涉及到270个种类,总计12000个模型。不仅具有类别标签,还备注有真实尺寸、材料、体积、重量等信息。
4.2019数据融合比赛数据集(2019 data fusion contest dataset)
数据集旨在利用深度学习完成城市场景的语义类 3D 重建和预测点云语义标签等研究。数据集中包括两所城市的多视图、多波段卫星图像和语义标签。其中,语义类包括地面、高植被、建筑、水、高架道路和桥梁等。
















 4062
4062











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









