






目录
16. 最后生成annotation目录下面的train.csv以及pkl文件
3. 我是多卡训练,三张,分布式训练,我自己写了个bash脚本
一、本文章亮点
1. 使用videomae算法做时空行为检测,此算法鲁棒性远超slowfast
2. 使用yolox检测人体,比faster-rcnn鲁棒性高很多
3. 数据标注时可以自己调整框,手动增删框,避免yolov5框错。
二、鸣谢
此处鸣谢 CSPhD-winston-杨帆 ,发布的ava制作方法是我的启蒙方法,本人参透后才做了很多改进。文章链接:自定义ava数据集及训练与测试 完整版 时空动作/行为 视频数据集制作 yolov5, deep sort, VIA MMAction, SlowFast-CSDN博客文章浏览阅读3.5w次,点赞87次,收藏327次。前言这一篇博客应该是我花时间最多的一次了,从2022年1月底至2022年4月底。我已经将这篇博客的内容写为论文,上传至arxiv:https://arxiv.org/pdf/2204.10160.pdf欢迎大家指出我论文中的问题,特别是语法与用词问题在github上,我也上传了完整的项目:https://github.com/Whiffe/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset关于自定义ava数据集,也是后台_自定义ava数据集https://blog.csdn.net/WhiffeYF/article/details/124358725?spm=1001.2014.3001.5502
三、数据集制作
1. 下载项目
git clone https://gitee.com/YFwinston/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset.git2. 写裁剪脚本
a. 确认每个视频的时长,每个裁剪后的视频是10秒,比如视频长度为22.12秒,那么最后一个视频裁剪应该从12秒开始,(假设从13秒开始)否则后续帧裁剪会出错,缺帧。
b. 裁剪时,每个视频间隔7秒,可以让最后训练的choose_frame_middle不漏掉图片帧、也不重复。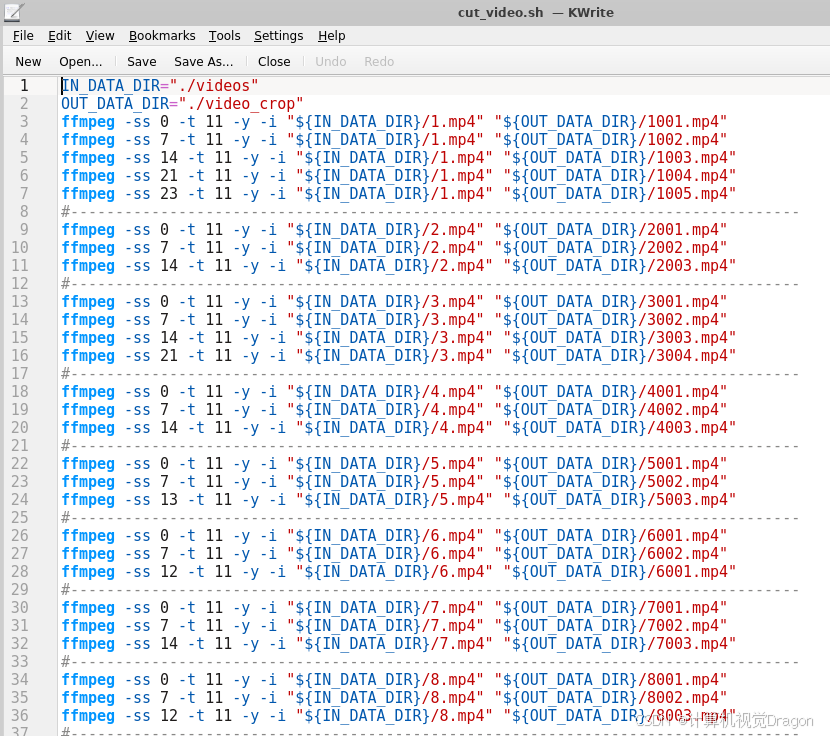
3.视频裁剪、抽帧
cd /home/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset/Dataset
sh cut_video.sh抽帧
cd /home/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset/Dataset
bash cut_frames.sh 4.整合缩减帧
cd /home/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset/Dataset
python choose_frames_all.py 10 0
python choose_frames.py 10 05.环境安装、搞定权重
cd /home/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset/yolovDeepsort
pip install -r requirements.txt
pip install opencv-python-headless==4.1.2.30
wget https://github.com/ultralytics/yolov5/releases/download/v6.1/yolov5s.pt -O /home/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset/yolovDeepsort/yolov5/yolov5s.pt
mkdir -p /root/.config/Ultralytics/
wget https://ultralytics.com/assets/Arial.ttf -O /root/.config/Ultralytics/Arial.ttf6.对choose_frames_all进行检测
cd /home/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset/yolovDeepsort
python ./yolov5/detect.py --source ../Dataset/choose_frames_all/ --save-txt --save-conf 7.生成pkl
pkl文件是框的坐标信息。生成dense_proposals_train.pkl
cd /home/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset/yolovDeepsort/mywork
python dense_proposals_train.py ../yolov5/runs/detect/exp/labels ./dense_proposals_train.pkl show导入VIA
cd /home/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset/Dataset/
python choose_frames_middle.py8.处理动作标注
这里做一个映射,将自己实际需求的动作,映射到公开数据集的动作类别中,这样方便将自己的数据与公开数据集合并,大大增加训练数据量,可以更好发挥模型性能(videomae这种大参数算法需要更多的数据发挥其性能),并且大大减少自己构建大规模数据集的时间。

这里规定一下动作(根据实际需求制定),lie、sit、get up、stand、walk、弯腰bend、grab a person、fall down,那么就修改成如下:
与ava标准动作对应:lie/sleep(8) sit(11) get up(6) stand(12) walk(14) bend(1) grab a person(66) fall down(5)
9.去掉默认值然后打标:第一次打标只调整框!不勾选动作
去掉默认值:
cd /home/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset/Dataset
python chang_via_json.py 打标:
利用Winscp将choose_frames_middle从服务器传到笔记本win上。然后使用via进行标注
via官网:https://www.robots.ox.ac.uk/~vgg/software/via/
via标注工具下载链接:https://www.robots.ox.ac.uk/~vgg/software/via/downloads/via3/via-3.0.11.zip
点击 via_image_annotator.html
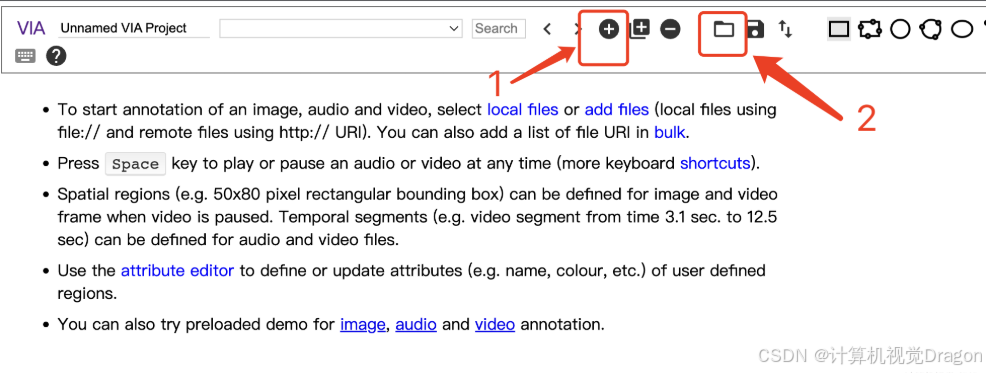
下图是via的界面,1代表添加图片,2代表添加标注文件
导入图片,打开标注文件(注意,打开x_proposal_s.json),最后结果:
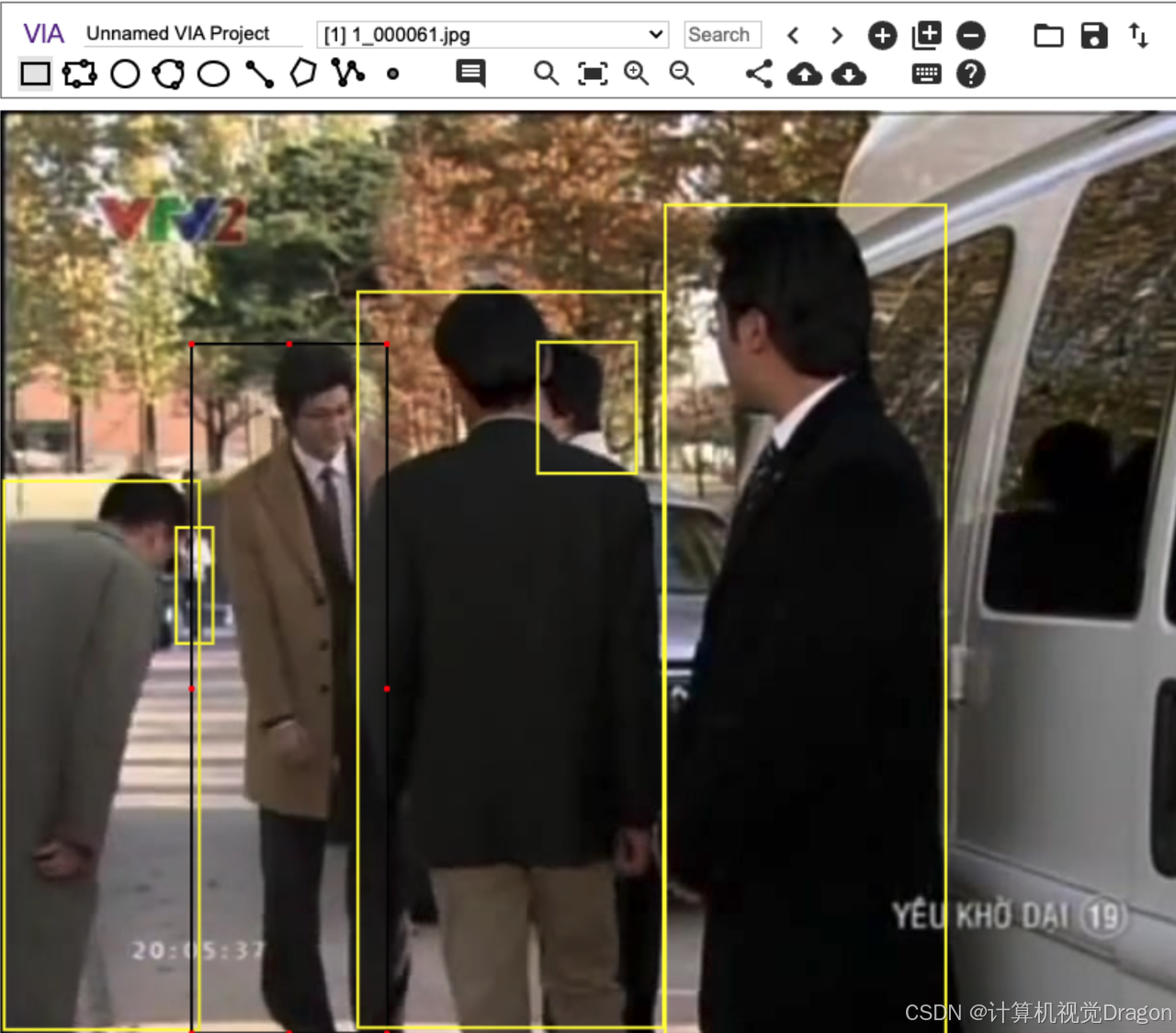
把人物框出来,框人不准的框调整一下,不想要的框DEL键删掉,这里的动作勾选全部去掉,不要对动作打标!
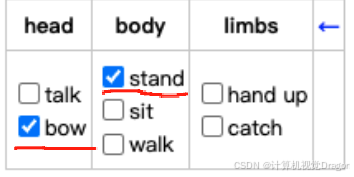
打完人体框的标注后,保存格式为x_finish.json(x是文件夹名称,一般形如10001_finish.json)。
10.下面理解即可,就不给代码了,因为在11点中做了升级
得到所有图片的框的信息,用工具解析json文件
https://c.runoob.com/front-end/53/
在metadata这里面,有坐标信息,把坐标信息按顺序输入python程序,python程序位于: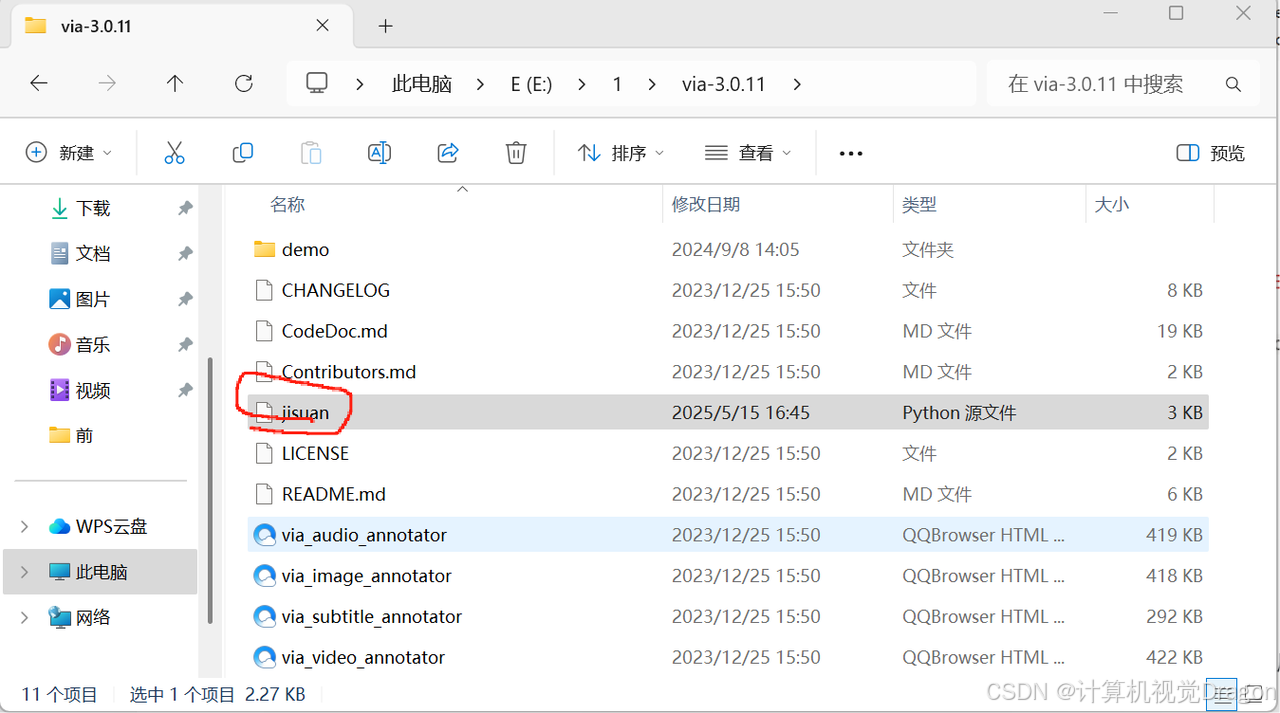
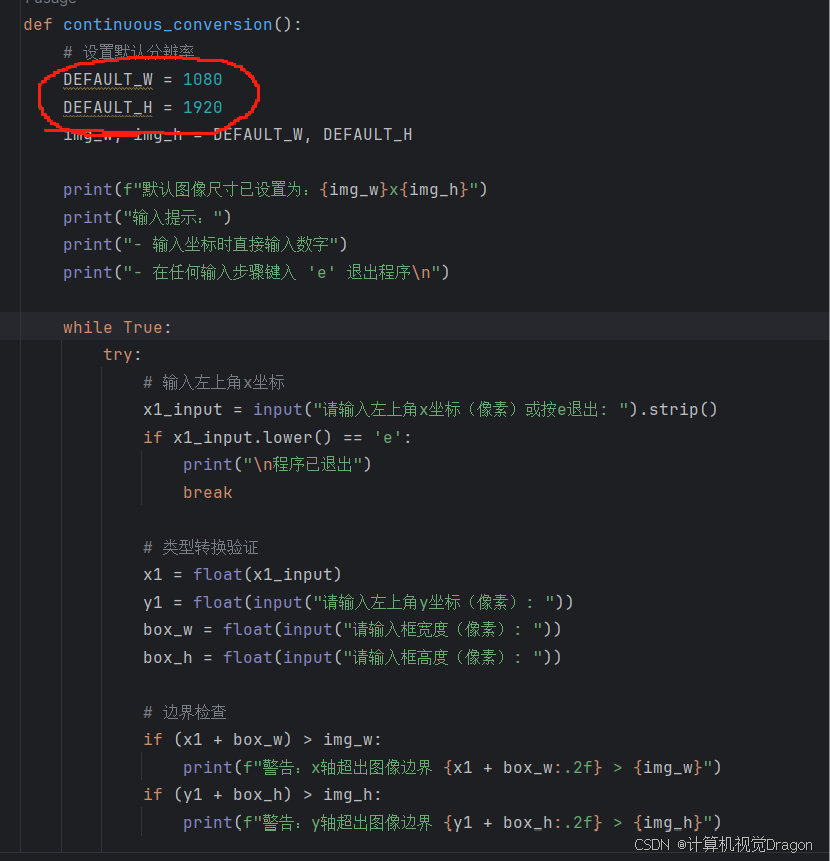
python程序需要修改默认分辨率,例如这次是这种竖屏,就把python代码分辨率改成1080×1920

坐标信息举例:
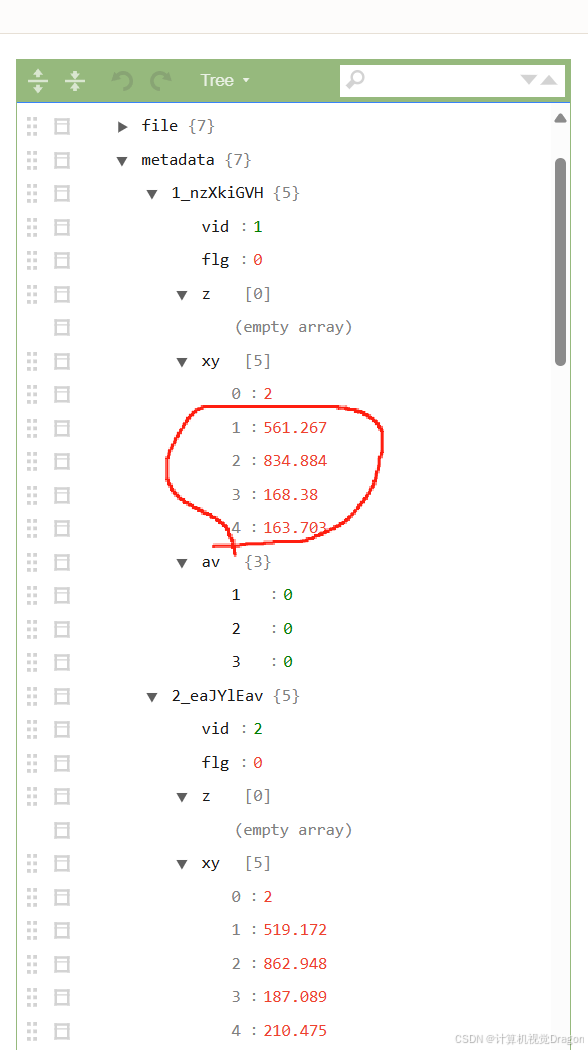
依次输入python程序得到归一化坐标:
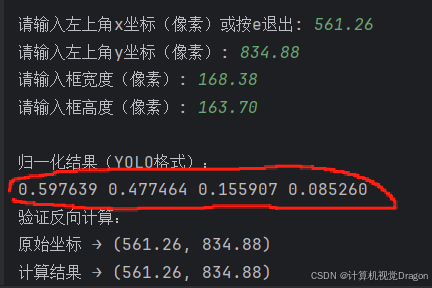
点开服务器,写入图片对应的txt文件:
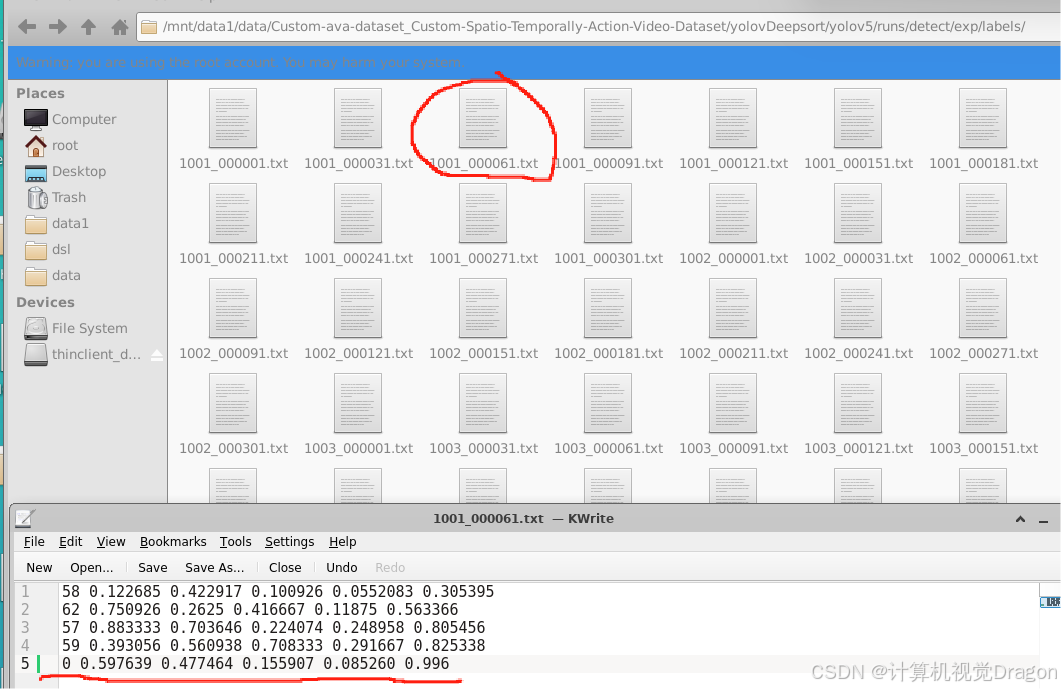
0是类别,除了归一化坐标,最后还有置信度,一共写6个值,置信度随便给。
所有图片,第一次打标检查框,然后查看json文件,转换坐标,写入txt文件
11.升级版
a. 一次打框后,生成json文件,之前的问题在于,需要手动将json文件输入解析的网站,然后查看其坐标,一个个输入坐标转换程序,非常麻烦,现在可以直接将json文件的内容也就是一组图片,输入升级版的坐标转换程序,然后将归一化坐标一次性全部输出,复制到labels的txt文件中。
b. 例如,假设打完框的标注,保存了1001_finish.json文件,利用记事本等工具打开,复制其内容,准备输入到python脚本中。
c. 这里需要安装pycharm,以及python,自行查阅资料。然后运行以下代码(自行更改分辨率!!!)
我是手机竖屏录制的,所以是1080*1920
import json
import random
import re
def parse_and_convert_coordinates(json_str):
# 设置默认分辨率
DEFAULT_W = 1080
DEFAULT_H = 1920
img_w, img_h = DEFAULT_W, DEFAULT_H
# 图片编号映射表(索引从1开始)
img_name_mapping = {
1: "61",
2: "91",
3: "121",
4: "151",
5: "181",
6: "211",
7: "241"
}
print(f"默认图像尺寸已设置为:{img_w}x{img_h}")
try:
# 解析JSON数据
data = json.loads(json_str)
metadata = data.get("metadata", {})
# 将metadata条目按图片编号排序
sorted_items = []
for key, value in metadata.items():
img_num = None
# 尝试从数字开头格式解析(如"1_nzXkiGVH")
if re.match(r'^\d+_', key):
img_num = int(key.split('_')[0])
# 尝试从image格式解析(如"image1_1")
elif re.match(r'^image\d+', key):
match = re.search(r'^image(\d+)', key)
if match:
img_num = int(match.group(1))
if img_num is not None:
sorted_items.append((img_num, key, value))
sorted_items.sort() # 按图片编号排序
# 按图片名称收集结果
results_by_image = {}
# 处理每个图片的坐标
for img_num, key, item in sorted_items:
# 获取映射后的图片名称
img_name = img_name_mapping.get(img_num, str(img_num))
xy = item.get("xy", [])
if len(xy) >= 5: # 确保xy数组有足够的元素
# 提取坐标 (x, y, width, height)
x1 = xy[1] # 左上角x坐标
y1 = xy[2] # 左上角y坐标
box_w = xy[3] # 宽度
box_h = xy[4] # 高度
# 计算中心点
center_x = x1 + box_w / 2
center_y = y1 + box_h / 2
# 执行归一化
norm_cx = round(center_x / img_w, 6)
norm_cy = round(center_y / img_h, 6)
norm_w = round(box_w / img_w, 6)
norm_h = round(box_h / img_h, 6)
# 生成随机值
rand_value = random.uniform(0.85, 0.9999)
# 保存结果
if img_name not in results_by_image:
results_by_image[img_name] = []
results_by_image[img_name].append({
"orig_coords": (x1, y1, box_w, box_h),
"yolo_format": f"0 {norm_cx:.6f} {norm_cy:.6f} {norm_w:.6f} {norm_h:.6f} {rand_value:.6f}",
"verify": (verify_x := norm_cx * img_w - box_w / 2, verify_y := norm_cy * img_h - box_h / 2)
})
# 输出结果,按图片名称顺序
print("\n处理结果:")
print("=" * 60)
for img_name in sorted(results_by_image.keys(), key=lambda x: int(x)):
results = results_by_image[img_name]
print(f"图片 {img_name}:")
# 先显示原始坐标
for i, result in enumerate(results):
x1, y1, box_w, box_h = result["orig_coords"]
print(f" 框{i + 1}原始坐标: x={x1:.2f}, y={y1:.2f}, w={box_w:.2f}, h={box_h:.2f}")
# 然后显示YOLO格式结果(方便复制)
print(" YOLO格式:")
for result in results:
print(result["yolo_format"])
# 最后显示验证结果
for i, result in enumerate(results):
x1, y1, box_w, box_h = result["orig_coords"]
verify_x, verify_y = result["verify"]
print(f" 框{i + 1}验证: 原始=({x1:.2f}, {y1:.2f}), 计算=({verify_x:.2f}, {verify_y:.2f})")
print("-" * 50)
except json.JSONDecodeError:
print("错误:无效的JSON数据")
except Exception as e:
print(f"处理时发生错误: {str(e)}")
def main():
print("YOLO坐标自动转换系统")
print("请粘贴JSON数据,完成后按回车两次:")
lines = []
while True:
line = input()
if line.strip() == "":
break
lines.append(line)
json_str = ''.join(lines)
parse_and_convert_coordinates(json_str)
if __name__ == "__main__":
main()d. 之前的json文件复制,运行python代码并输入

e. 执行完输出,需要注意画圈的地方,表示的是横线内容应该填入哪一个txt,横线部分,第一个0表示类别是人物,最后一位是概率,这个是随机生成的(范围是0.8-1.0),中间四个是框的归一化坐标,从打标完的像素值归一化成0-1之间,以便后续的代码识别。
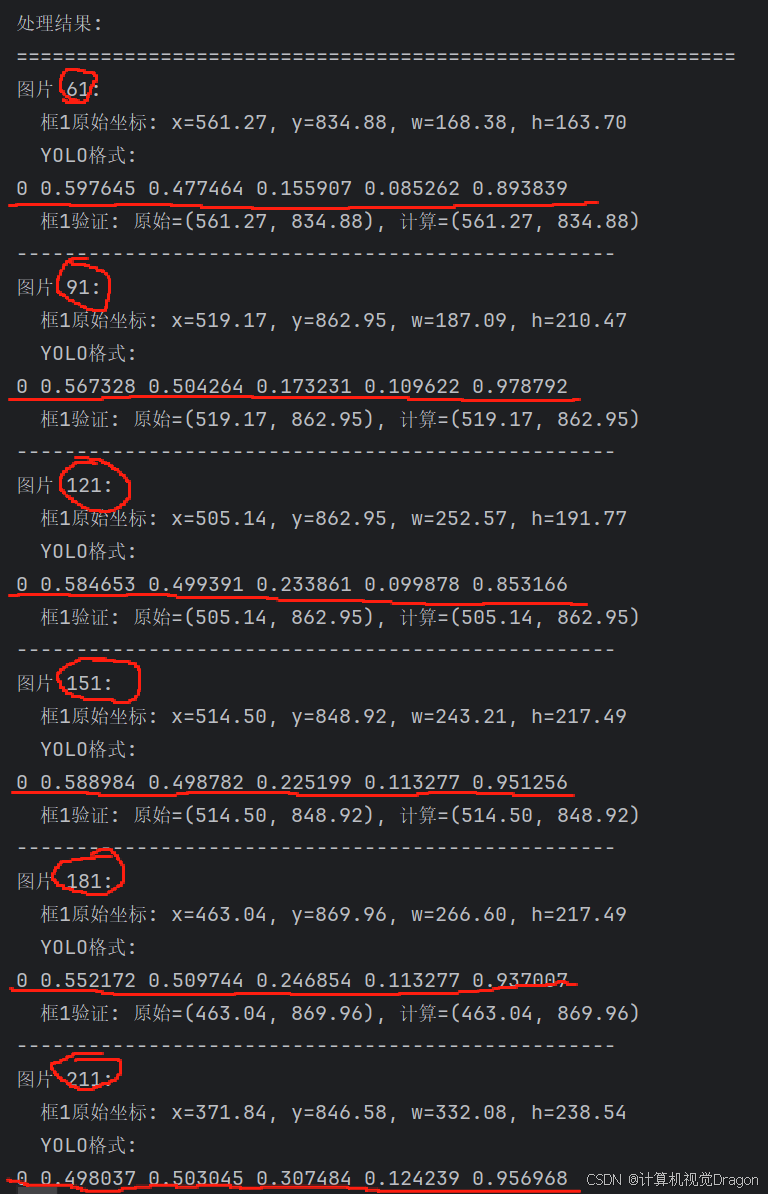
f. 如,刚才的图片61,yolo格式为:0 0.597645 0.477464 0.155907 0.085262 0.893839,直接复制到对应的1001_61里面
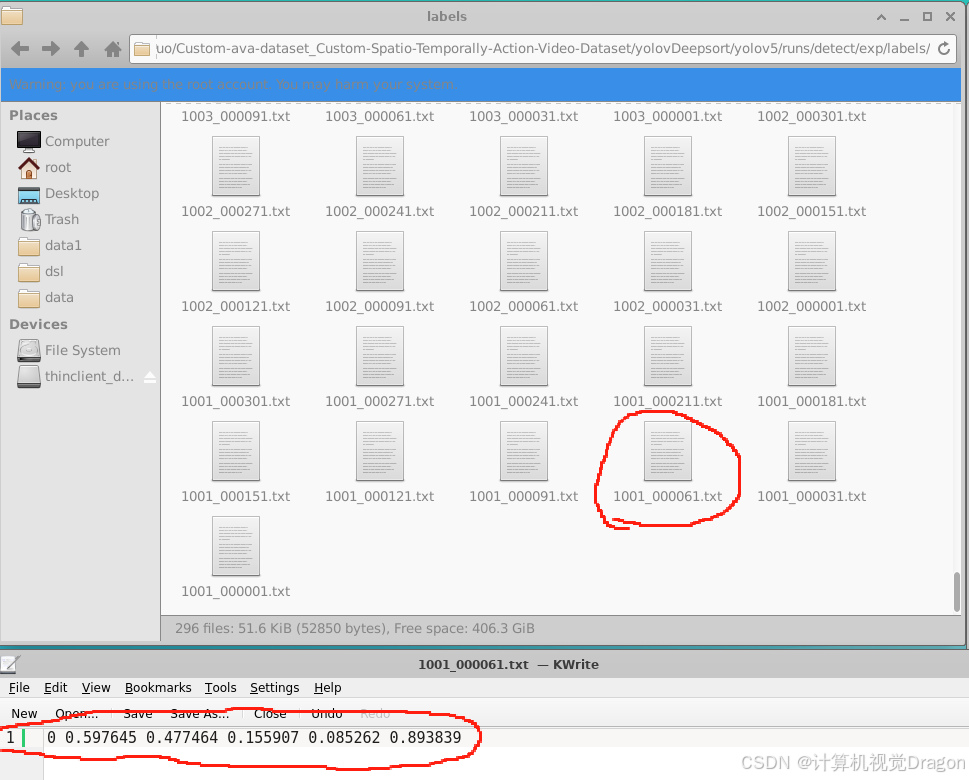
一直到1001_000241.txt修改完为止,前面的1、31以及后面的271、301不改。
12. 准备第二次打标
处理完labels的txt文件后,重新从这一步开始,接下来正常打标:
利用修改完的txt文件,生成正确的pkl文件。

cd /home/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset/yolovDeepsort/mywork
python dense_proposals_train.py ../yolov5/runs/detect/exp/labels ./dense_proposals_train.pkl show13. 生成标注文件、去掉默认值
生成标注文件
cd /home/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset/yolovDeepsort/mywork/
python dense_proposals_train_to_via.py ./dense_proposals_train.pkl ../../Dataset/choose_frames_middle/去掉默认值
cd /home/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset/Dataset
python chang_via_json.py 将choose_frames_middlle文件夹传输到笔记本上,准备动作标注
这次标注,只需选中框,标记动作即可。
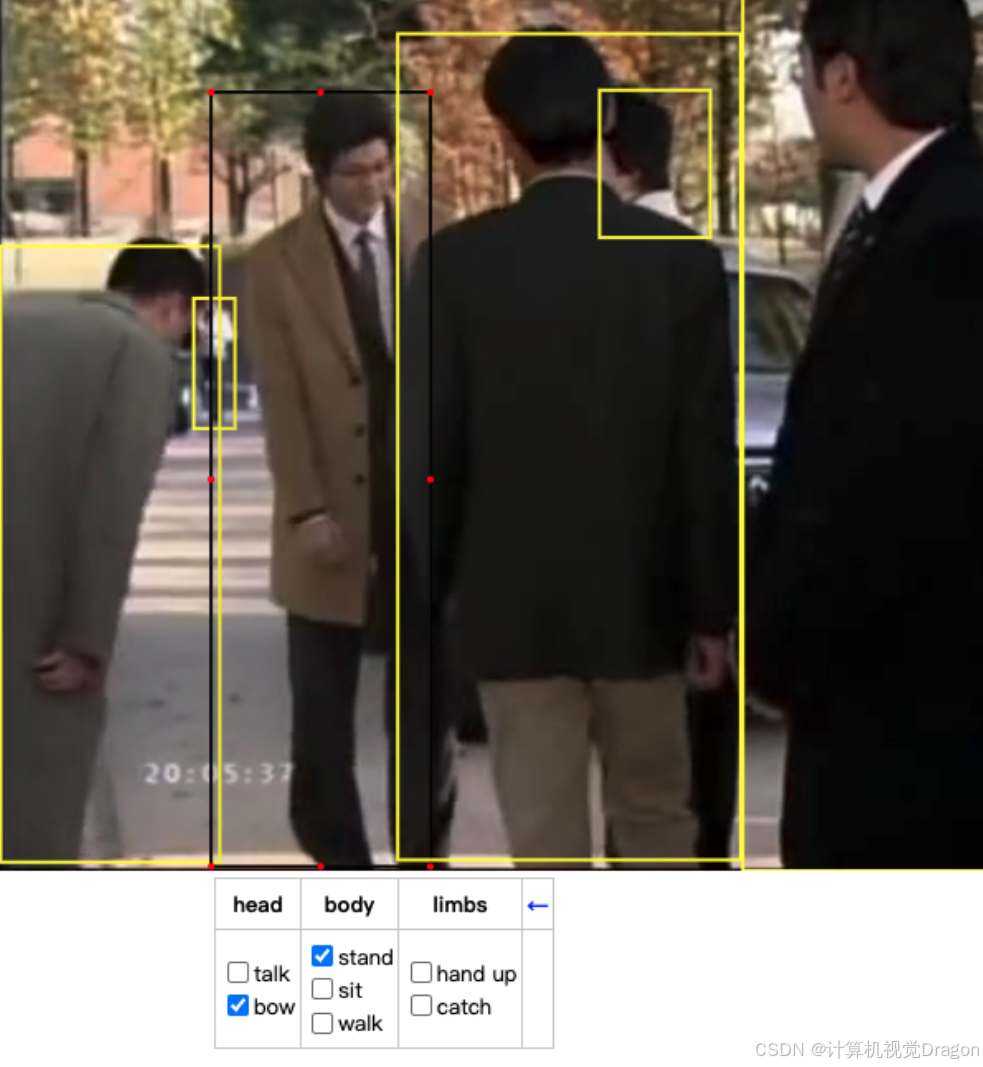
打标完一律保存为x_finish.json格式文件
14. 标注后处理
a. 在/home/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset/Dataset/下执行
cd /home/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset/Dataset/
python json_extract.py会在/home/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset/Dataset/下生成: train_without_personID.csv
b. 由于deepsort需要提前送入2帧图片,然后才能从第三帧开始标注人的ID,dense_proposals_train.pkl是从第三张开始的(即缺失了0,1),所以需要将0,1添加。在/home/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset/yolovDeepsort/mywork下执行
cd /home/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset/yolovDeepsort/mywork
python dense_proposals_train_deepsort.py ../yolov5/runs/detect/exp/labels ./dense_proposals_train_deepsort.pkl showc. 接下来使用deep sort来关联人的ID将图片与yolov5检测出来的坐标,送入deep sort进行检测
在/home/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset/yolovDeepsort/执行命令如下:
cd /home/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset/yolovDeepsort/
wget https://drive.google.com/drive/folders/1xhG0kRH1EX5B9_Iz8gQJb7UNnn_riXi6 -O ./deep_sort_pytorch/deep_sort/deep/checkpoint/ckpt.t7
python yolov5_to_deepsort.py --source /home/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset/Dataset/frames结果在/home/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset/Dataset/train_personID.csv
d. 融合csv,修正内容
目前已经有2个文件了:
1,train_personID.csv
包含 坐标、personID
2,train_without_personID.csv
包含 坐标、actions
所以现在需要将两者拼在一起
cd /home/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset/Dataset/
python train_temp.py
#最后结果:home/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset/Dataset/train_temp.csv
#运行结束后,会发现有些ID是-1,这些-1是deepsort未检测出来的数据,原因是人首次出现或者出现时间过短,deepsort未检测出ID。e. 针对train_temp.csv中存在-1的情况,需要进行修正
在/home/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset/Dataset/下执行
cd /home/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset/Dataset/
python train.py
#结果在:/home/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset/Dataset/annotations/train.csv15. 复制pkl文件,然后修正文件
#复制
cp /home/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset/yolovDeepsort/mywork/dense_proposals_train.pkl /home/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset/Dataset/annotations#修正
cd /home/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset/yolovDeepsort/mywork
python change_dense_proposals_train.py16. 最后生成annotation目录下面的train.csv以及pkl文件

17. 动作id的映射问题
利用脚本进行映射,将自己定义的动作,映射到公开数据集的动作标准上
#与前面提前相好的对应起来,与ava标准动作对应:lie/sleep(8) sit(11) get up(6) stand(12) walk(14) bend(1) grab a person(66) fall down(5)
import csv
# 定义数字替换规则
replace_map = {
'1': '8',
'2': '11',
'3': '6',
'4': '12',
'5': '14',
'6': '1',
'7': '66',
'8': '5'
}
# 输入和输出文件
input_file = 'train.csv' # 替换为你的CSV文件名
output_file = 'train_jiu_zheng.csv'
# 处理文件
with open(input_file, 'r', encoding='utf-8') as infile, open(output_file, 'w', encoding='utf-8', newline='') as outfile:
reader = csv.reader(infile)
writer = csv.writer(outfile)
for row in reader:
# 检查第七列是否为数字并进行替换
if len(row) >= 7 and row[6] in replace_map:
row[6] = replace_map[row[6]]
writer.writerow(row)
print(f"处理完成!结果已保存到 '{output_file}'")
这里的映射标准是根据第9步来的,并且要使用的话,记得修改输入和输出文件的路径
18. 修改一下人物id
这里我+400,具体+多少根据你下载的公开数据集最大的人物id决定,也可以不改,我感觉没啥用
import csv
with open('train_jiu_zheng.csv', 'r') as infile, open('train_jiu_zheng_person_id.csv', 'w', newline='') as outfile:
reader = csv.reader(infile)
writer = csv.writer(outfile)
for row in reader:
if len(row) == 8:
row[-1] = str(int(row[-1]) + 400)
writer.writerow(row)19. 制作rawframes
cp -r /home/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset/Dataset/frames/* /home/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset/Dataset/rawframes
cd /home/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset/yolovDeepsort/mywork/
python change_raw_frames.py20. 总结
至此,准备好了train.csv、pkl文件、rawframes,可以进行数据集融合了
四、数据集融合
1. 手动融合train.csv和val.csv
2. pkl文件合并
import os
import pickle
import numpy as np
import argparse
from mmengine.fileio import load
from typing import Dict, Any
from typing import Optional
def get_pickle_protocol(file_path: str) -> int:
"""自动检测pickle文件的协议版本"""
with open(file_path, 'rb') as f:
# 仅读取协议头,不完全加载数据
header = f.read(4)
if header[0:2] == b'\x80\x04':
return 4 # 最常见的协议版本
elif header[0:2] == b'\x80\x03':
return 3
else:
return pickle.DEFAULT_PROTOCOL
def merge_pkl_files(
pkl1_path: str,
pkl2_path: str,
output_path: str,
protocol: Optional[int] = None
) -> None:
"""合并两个.pkl文件,完全保留原始数据"""
# 加载数据(使用mmengine的load确保兼容性)
try:
data1: Dict[str, np.ndarray] = load(pkl1_path)
data2: Dict[str, np.ndarray] = load(pkl2_path)
except FileNotFoundError as e:
raise ValueError(f"文件不存在: {str(e)}")
# 逐键合并,禁用所有优化
merged = data1.copy()
for key in data2:
if key in merged:
# 直接拼接数组,不排序、不去重、不截断
merged[key] = np.concatenate([merged[key], data2[key]])
else:
merged[key] = data2[key]
# 自动检测协议版本(若未指定)
if protocol is None:
protocol = max(
get_pickle_protocol(pkl1_path),
get_pickle_protocol(pkl2_path)
)
# 确保输出目录存在
os.makedirs(os.path.dirname(output_path), exist_ok=True)
# 以二进制模式写入,保持协议一致
with open(output_path, 'wb') as f:
pickle.dump(merged, f, protocol=protocol)
# 验证合并结果
_verify_merge(data1, data2, output_path)
def _verify_merge(
original1: Dict[str, np.ndarray],
original2: Dict[str, np.ndarray],
merged_path: str
) -> None:
"""验证合并结果完整性"""
merged = load(merged_path)
# 检查键的数量
expected_keys = set(original1.keys()) | set(original2.keys())
assert set(merged.keys()) == expected_keys, "键数量不匹配!"
# 随机抽样验证数据完整性
sample_key = next(iter(original2))
if sample_key in original1:
expected_len = len(original1[sample_key]) + len(original2[sample_key])
else:
expected_len = len(original2[sample_key])
actual_len = len(merged[sample_key])
assert actual_len == expected_len, (
f"键 '{sample_key}' 数据长度异常: {actual_len} vs {expected_len}"
)
print(f"✅ 合并验证通过!输出文件: {merged_path}")
if __name__ == "__main__":
# 命令行参数配置
parser = argparse.ArgumentParser(
description='合并AVA proposal的.pkl文件(完全保留原始数据)')
parser.add_argument('--pkl1', type=str, required=True,
help='第一个.pkl文件路径')
parser.add_argument('--pkl2', type=str, required=True,
help='第二个.pkl文件路径')
parser.add_argument('--output', type=str, required=True,
help='合并后的输出路径')
parser.add_argument('--protocol', type=int, default=None,
help='指定pickle协议版本(默认自动检测)')
args = parser.parse_args()
# 执行合并
try:
merge_pkl_files(
pkl1_path=args.pkl1,
pkl2_path=args.pkl2,
output_path=args.output,
protocol=args.protocol
)
except Exception as e:
print(f"❌ 合并失败: {str(e)}")
exit(1)
使用时
python hebing.py --pkl1 '路径' --pkl2 '路径' --output '输出路径'3. 总结
至此,准备好了两个合并的csv以及两个pkl文件,再准备以下格式的内容
videos_15min
Videos
Rawframes
annotations
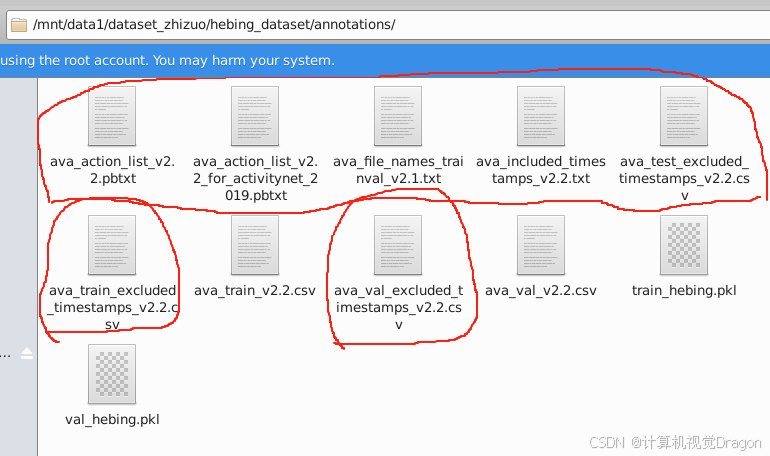
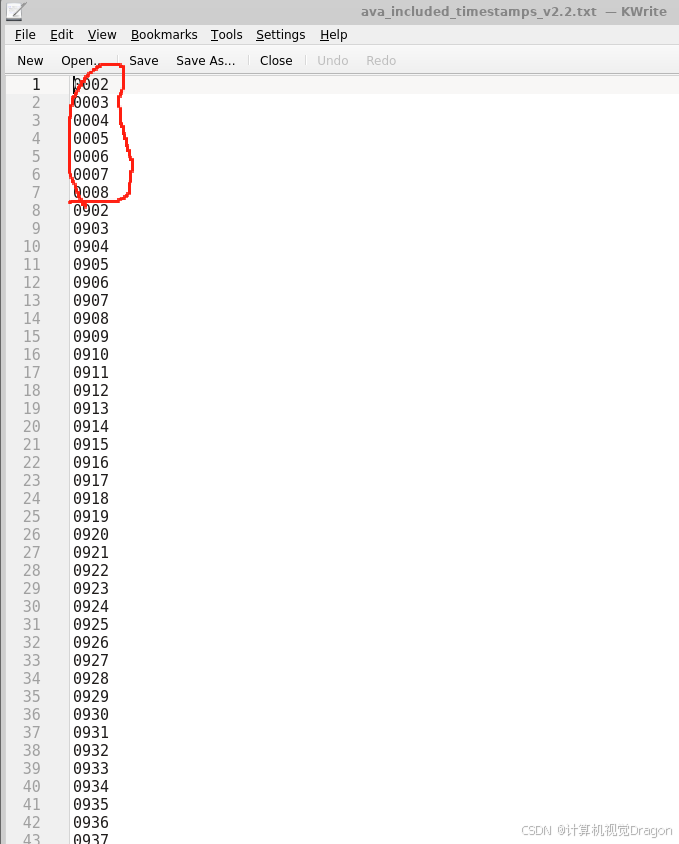
这里的文件复制即可,第四个文件include_timestamps中,需要包含
五、模型训练
1. 训练时,这里记得修改配置文件的数据集路径。
2. 原本训练代码
python tools/train.py configs/detection/ava_kinetics/vit-base-p16_videomae-k400-pre_8xb8-16x4x1-20e-adamw_ava-kinetics-rgb.py \
--cfg-options randomness.seed=0 randomness.deterministic=True
'''
如果报错就用:python tools/train.py configs/detection/ava_kinetics/vit-base-p16_videomae-k400-pre_8xb8-16x4x1-20e-adamw_ava-kinetics-rgb.py \
--cfg-options randomness.seed=0'''3. 我是多卡训练,三张,分布式训练,我自己写了个bash脚本
export CUDA_VISIBLE_DEVICES=1,2,3#我的第一张卡ID为0,但是用来运行系统了,就用后三张
torchrun --nproc_per_node=3 --master_port=29500 \
tools/train.py /mnt/data1/mmaction/configs/detection/videomae/vit-base-p16_videomae-k400-pre_8xb8-16x4x1-20e-adamw_ava-kinetics-rgb.py \
--resume \
--launcher pytorch \
--work-dir /mnt/data1/mmaction/work_dirs \六、测试代码
1.yolox
官方给的代码用的人体框检测器是faster crnn,太垃圾了,换成yolo
对比faster-rcnn与yolox,yolox效果好很多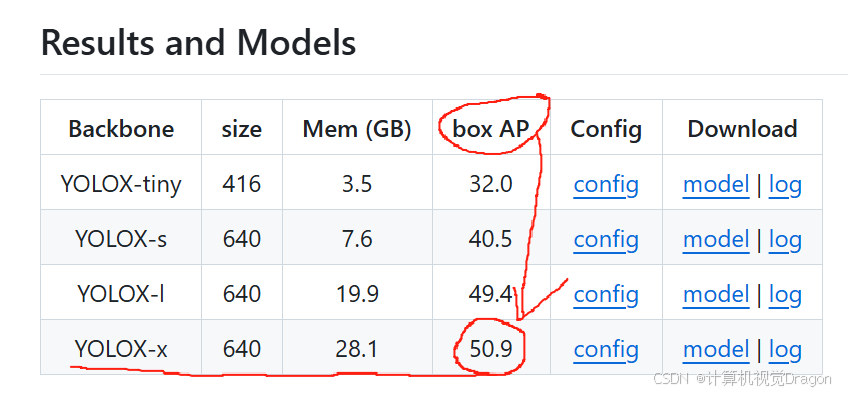
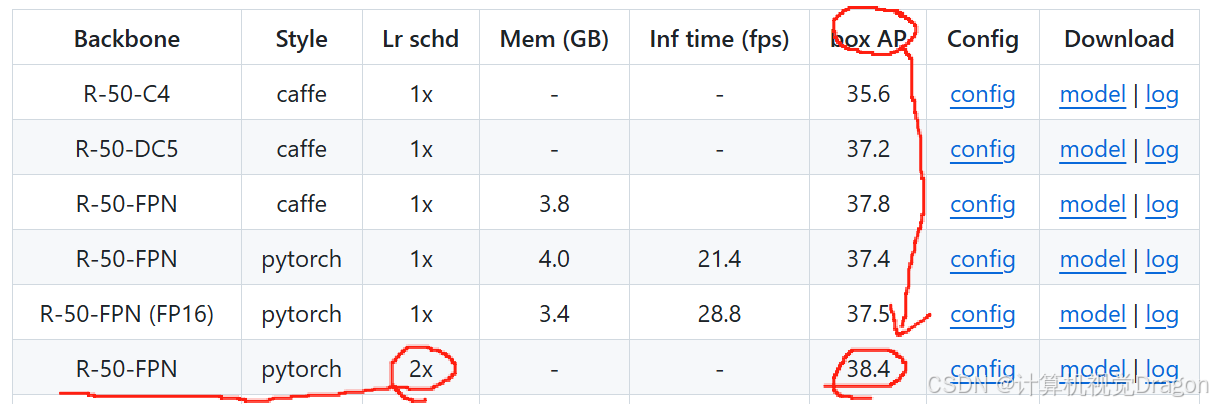
下载yolox的config以及checkpoint:https://github.com/open-mmlab/mmdetection/tree/main/configs/yolox

2. 测试代码
其中,python demo/demo_spatiotemporal_det.py前的参数,表示调用第2张显卡跑,后面第一个参数,表示输入视频路径,第二个参数是输出视频路径,第三个是训练时的配置文件,第四个是我们训练好的ckpt,第五个是检测框的,yolox的配置文件路径,第六个是检测框的ckpt路径,后面的参数,不懂可问ai。
CUDA_VISIBLE_DEVICES=1 python demo/demo_spatiotemporal_det.py /mnt/data1/dataset_zhizuo/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset/Dataset/videos/8.mp4 /mnt/data1/dataset_zhizuo/Custom-ava-dataset_Custom-Spatio-Temporally-Action-Video-Dataset/Dataset/video_crop/finish/8.mp4 --config /mnt/data1/mmaction/configs/detection/videomae/vit-base-p16_videomae-k400-pre_8xb8-16x4x1-20e-adamw_ava-kinetics-rgb.py --checkpoint /mnt/data1/mmaction/work_dirs/best_mAP_overall_epoch_20.pth --det-config /mnt/data1/mmaction/det/config/yolox/yolox_x_8xb8-300e_coco.py --det-checkpoint /mnt/data1/mmaction/det/ckpt/yolox_x_8x8_300e_coco_20211126_140254-1ef88d67.pth --det-score-thr 0.5 --action-score-thr 0.5 --label-map tools/data/ava/label_map.txt --predict-stepsize 8 --output-stepsize 1 --output-fps 30
















 820
820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









