







目录
目录
恕小菜鸟直言,长文章不放目录,纯纯耍流氓。
1.引言
本文章仅供自己学习参考,如有不当之处,请各位大佬多多指正。你说这又要当医学生,又要写代码的,真的很不容易;而且还没有人带,那就更头大了,发出来主要也就是想和志同道合的小伙伴们一起讨论。
参考数据知识来自于:metafor包列出的参考文献《meta with R》以及《R语言实战 第二版》,后者在我看来是最好的R入门书。当然我知道大佬可能随便找点参考视频,meta分析就已经拿捏住了。那么请略过此贴吧。
本书在开头就已经介绍了连续型数据的参考绘图方法,我用自己的数据展示了一下函数的写法,因为原文中的一些参数已经不能直接那么写了。因为后面这个包将主要介绍metagen功能下的数据处理模式(原书中参考的是哮喘的一组数据,我则是使用了一组不同椎弓根螺钉置钉方法术中出血量的数据)。
本人R版本4.2.1,写下此贴的时候4.2.2的大部分更新包都已经上线。后面的更新可能会导致包内的功能差异,表达一下大意,还是得自己多多摸索。
m <- metacont(n.e=Total, #此处是我自己修改的,因为版本更迭,各种参数的名称略有变化了
mean.e = Mean, #分别代表实验组:对照组的平均值,sd,总样本量
sd.e =SD,
n.c=Total.1,
mean.c =Mean.1,
sd.c=SD.1,
studlab=paste(study, year), #这两列分别是作者名字和年份
data=BLOOD) #数据是我自己随便从网上抄来的,换成大家自己的就行
settings.meta("Revman5") # 设置meta格式为经典的revman小绿图,嘿嘿
forest(m,
squaresize = 0.4, #设置方块大小
label.left = "Favours [Cortical screw]",
label.right = "Favours [Pedicle screw]",
fixed = F) #数据i方很大,只看随机效应模型就加此命令;反之为random =F那么实际做出来的森林图如下:
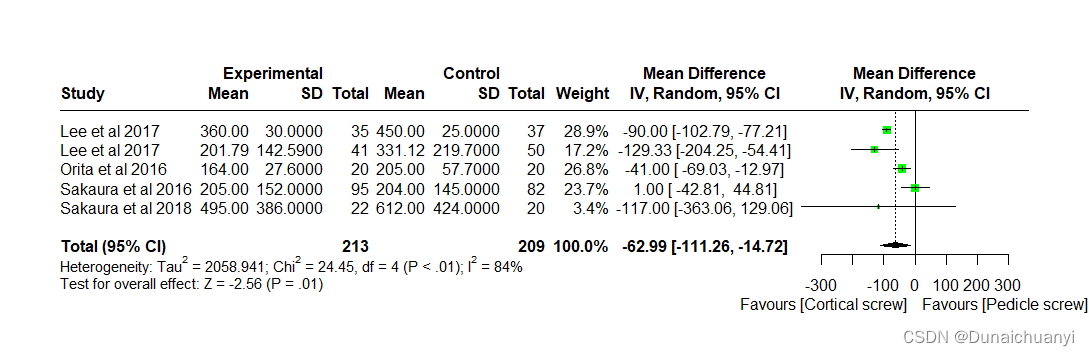
怎么样,加了设置格式的命令之后是不是非常的“revman”?尤其是异质性的计算部分,嘿嘿。
来个森林图开开胃,下面开始正文吧(正文中出示的数据来自:http://meta-analysis-with-r.org/ 网站上的dataset.csv数据集,比较奈多克罗米尔钠和安慰剂预防运动性支气管收缩的效果;doi号:10.1002/14651858.CD001183)。
2.安装,数据的读取和保存
不讲。这个有别的大佬讲了,没有创新点。
3.标准方法
3.1 固定效应模型与随机效应模型
在此处举例同引言部分的例子,做的是一个连续型变量。虽然觉得纯属多余,还是粘贴一下做meta前需要的数据表格。
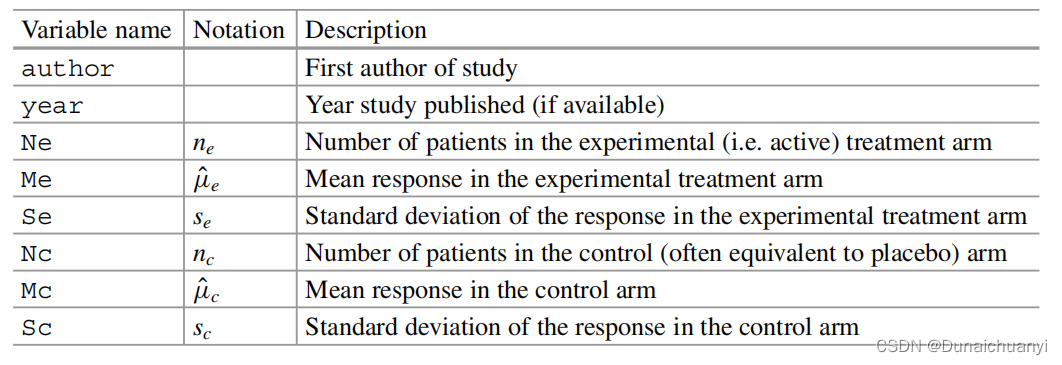
收集好这些数据,用R将数据读取,并且进行meta分析。
3.1.1 连续型结果的数据测量
①拳打SD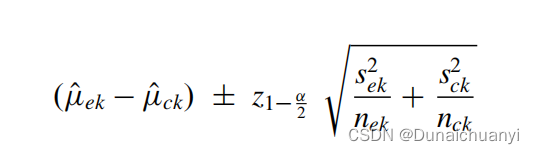
公式如图中所示,α为检验水平,正常的双尾计算都取95%置信区间,那么这个Z算得的值就是Z0.975 = 1.96,直接带入计算。作为一个受过专业训练的研究生,我当然是直接使用meta包中的metacont()命令来计算。这个公式纯纯当一个验算步骤,谁爱算谁算去。注意一点:metacont下默认的一个参数叫“sm = " " ”,如不加以限定,则默认为SD,不是算SMD或者WMD的,这两个需要自己调参数。
在某些特殊情况下,你可能想要从数据中删掉那么一行,那么请参考subset这个参数。
subset = -2 #从所有study中删掉第二个
subset = !(study == "Sakaura et al"&year == "2018")#定向删除某作者某年份的study
②脚踹标准化均差-SMD
可能有小伙伴要问了,为什么要使用标准化均差?什么情况用?
其实很简单。量纲不一样,或者说评分之类的使用的量表不一样,必须用SMD了。
公式只展示在代码,你们不会真有人手撕吧?
# 此处为原文实例代码,别问我,都很简单
# 1. Read in the data:
data2 <- read.csv("dataset02.csv")
# 2. As usual, to view an object, type its name:
data2
author Ne Me Se Nc Mc Sc
1 Blashki(75%150) 13 6.40 5.40 18 11.40 9.60
2 Hormazabal(86) 17 11.00 8.20 16 19.00 8.20
3 Jacobson(75-100) 10 17.50 8.80 6 23.00 8.80
4 Jenkins(75) 7 12.30 9.90 7 20.00 10.50
5 Lecrubier(100) 73 15.70 10.60 73 18.70 10.60
6 Murphy(100) 26 8.50 11.00 28 14.50 11.00
7 Nandi(97) 17 25.50 24.00 10 53.20 11.20
8 Petracca(100) 11 6.20 7.60 10 10.00 7.60
9 Philipp(100) 105 -8.10 3.90 46 -8.50 5.20
10 Rampello(100) 22 13.40 2.30 19 19.70 1.30
11 Reifler(83) 13 12.50 7.60 15 12.50 7.60
12 Rickels(70) 29 1.99 0.77 39 2.54 0.77
13 Robertson(75) 13 11.00 8.20 13 15.00 8.20
14 Rouillon(98) 78 15.80 6.80 71 17.10 7.20
15 Tan(70) 23 -8.50 8.60 23 -8.30 6.00
16 Tetreault(50-100) 11 51.90 18.50 11 74.30 18.50
17 Thompson(75) 11 8.00 8.10 18 10.00 9.70
> # 3. Calculate total sample sizes
summary(data2$Ne+data2$Nc)
#Min. 1st Qu. Median Mean 3rd Qu. Max.
#14.00 26.00 31.00 53.06 54.00 151.00
# 喜欢手撕?#####
# 1. Calculate standardised mean difference (SMD) and
# its standard error (seSMD) for study 1 (Blashki) of
# dataset data2:
N <- with(data2[1,], Ne + Nc)
SMD <- with(data2[1,],
(1 - 3/(4 * N - 9)) * (Me - Mc) / sqrt(((Ne - 1) * Seˆ2  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1133
1133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









