







使用TensorFlow快速实现图像风格迁移系统
资源地址:待更新
视频地址:待更新
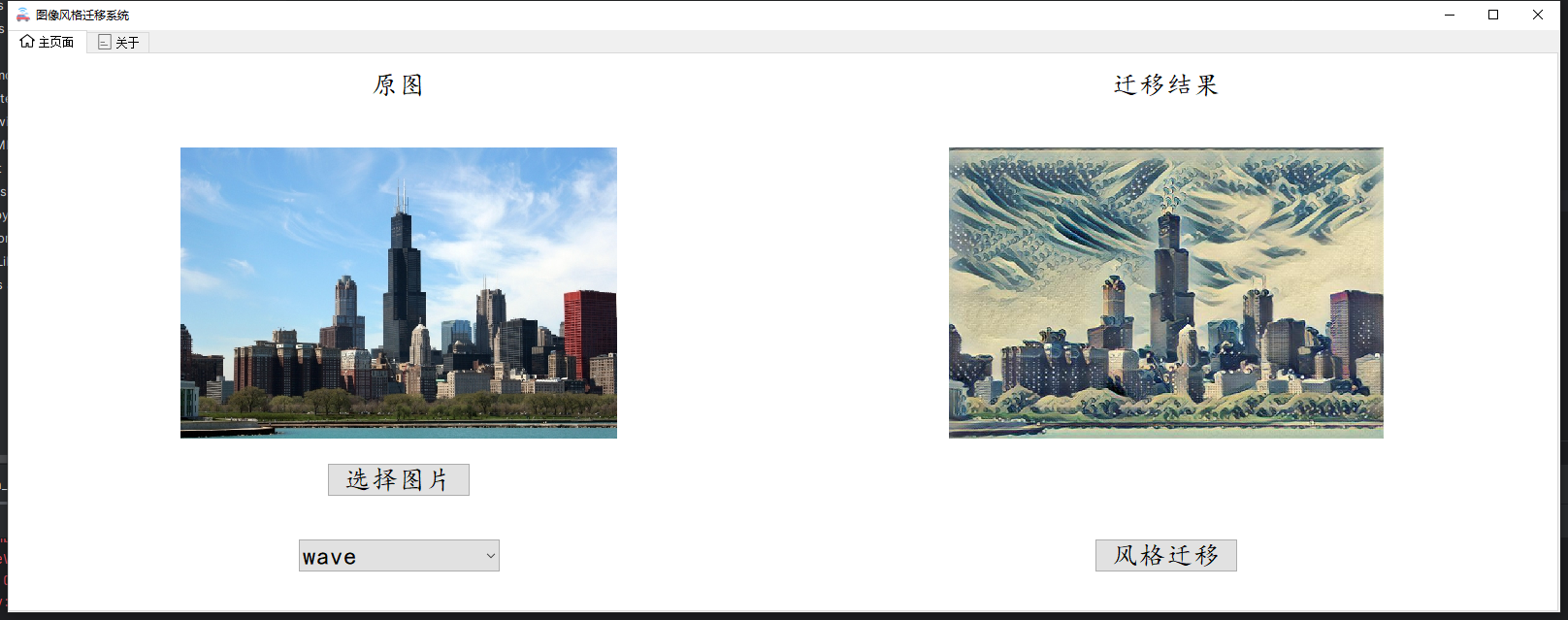
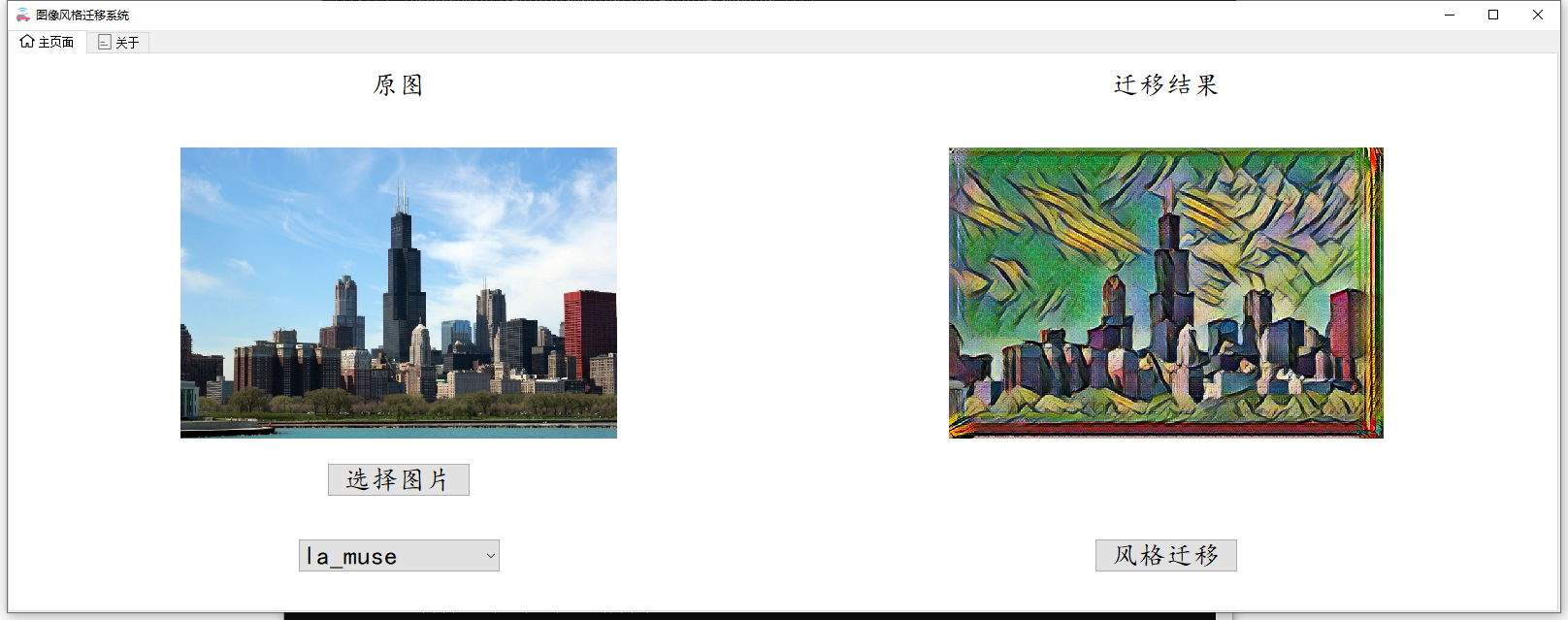
随着GPT的横空出世,生成式网络也越来越活,现在的大语言模型除了能回答文字上面的内容,并且在图像和视频创作中也表现除了巨大的潜力,今天我们继续大作业系列,以比较早的一篇李飞飞博士的快速风格迁移为例,给大家展示一下早期是如何利用卷积神经网络来进行图像风格迁移的。具体我们要实现的效果如下,通过tensorflow框架构建快速图像分割迁移的网络并利用训练好的四个模型实现对任意上传图片的风格迁移,并利用PyQt5构建图形化的界面来完成最终的系统。
先来一起看看效果吧。

背景与意义
图像风格迁移技术旨在将一幅图像(风格图像)的艺术风格应用到另一幅图像(内容图像)上,同时保留内容图像的主要内容。该技术在艺术创作、广告设计、游戏开发等多个领域具有广泛的应用价值。通过深度学习算法,图像风格迁移技术能够自动地识别和提取图像中的风格和内容特征,实现高效的风格转换。
图像风格迁移技术主要基于深度学习算法,尤其是卷积神经网络(CNN)。这些网络能够提取图像中的多层级特征,从而实现对图像内容和风格的分离与重组。在风格迁移过程中,通常使用预训练的CNN模型(如VGGNet、Inception等)来提取图像的特征。
发展历程
- 基于优化算法的风格迁移:最早的图像风格迁移方法是通过优化算法来最小化原始图像与目标图像在风格和内容上的差异。这种方法能够生成高质量的风格迁移图像,但计算成本较高且速度较慢。
- 基于卷积神经网络的快速风格迁移:2015年,Gatys等人提出了基于CNN的图像风格迁移方法,大大提高了迁移效果和速度。随后,Huang等人提出了快速风格迁移网络,将原有的优化算法简化为一个前向神经网络,实现了实时的图像风格迁移。
- 循环一致性生成网络:2017年出现的CycleGAN、MUNIT等循环一致性生成网络,可以在不需要成对训练数据的情况下完成图像的风格迁移等任务。
技术原理
论文地址:[1603.08155] Perceptual Losses for Real-Time Style Transfer and Super-Resolution (arxiv.org)
我们要探讨的这篇论文是16年的一个工作,论文的地址如上。
这篇论文的标题是《Perceptual Losses for Real-Time Style Transfer and Super-Resolution》,作者是Justin Johnson, Alexandre Alahi, 和 Li Fei-Fei,来自斯坦福大学计算机科学系。论文主要研究了实时风格迁移和超分辨率图像重建的问题。
摘要
摘要的部分:作者探讨了图像转换问题,即如何将输入图像转换成输出图像。以往的方法通常训练前馈卷积神经网络,使用逐像素损失函数来衡量输出图像和真实图像之间的差异。但是,这些方法并没有捕捉到图像之间的感知差异。与此同时,也有研究通过定义和优化基于预训练网络提取的高级特征的感知损失函数来生成高质量图像。本文结合了这两种方法的优点,提出使用感知损失函数来训练图像转换任务的前馈网络。实验结果表明,在风格迁移任务中,与基于优化的方法相比,所提出的网络在生成相似质量结果的同时,速度快了三个数量级。此外,作者还尝试了单图像超分辨率任务,发现用感知损失替换逐像素损失可以得到视觉上令人满意的结果。
主要内容概述
-
引言部分:介绍了图像转换任务的经典问题,如去噪、超分辨率和着色等,并讨论了使用逐像素损失函数训练前馈卷积神经网络的方法及其局限性。
-
相关工作:回顾了前馈图像转换、感知优化、风格迁移和图像超分辨率等领域的相关研究。
-
方法:介绍了系统由两部分组成:图像转换网络和用于定义多个损失函数的损失网络。详细阐述了网络结构、输入输出、下采样和上采样以及残差连接等内容。

-
感知损失函数:定义了两种感知损失函数——特征重建损失和风格重建损失,用于衡量图像之间的高级感知和语义差异。
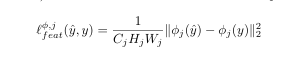

-
简单损失函数:除了感知损失外,还定义了依赖于低级像素信息的简单损失函数,如像素损失和总变分正则化。
-
实验:在风格迁移和单图像超分辨率两个图像转换任务上进行了实验,展示了所提方法与现有方法的比较,并讨论了结果。
-
结论:作者通过将前馈图像转换任务和基于优化的图像生成方法的优点结合起来,使用感知损失函数训练前馈转换网络,在风格迁移和单图像超分辨率任务上取得了显著的性能提升。
下面是一些实现效果的对比图,从图中可以看出,该方法实现的风格迁移从质量上均由于当时其他的方法,但是艺术这个东西实际上是不太好考量的,单纯从指标上来看迁移的好坏是不行滴。

代码实现
老规矩所有的代码实现都需要你了解Anaconda和Pycharm这两个工具,这两个工具的使用教程可以这期博客。
代码使用Tensorflow实现,考虑到大家设备的兼容性,我这边安装的时候CPU版本的Tensorflow,低配置的同学也可以进行尝试。
首先我们先实现主干的特征提取网络,这里的主干特征提取网络选择的是VGG网络。
# Copyright (c) 2015-2016 Anish Athalye. Released under GPLv3.
import tensorflow as tf
import numpy as np
import scipy.io
import pdb
# 定义全局均值像素数组
MEAN_PIXEL = np.array([123.68, 116.779, 103.939])
# 定义神经网络函数
def net(data_path, input_image):
# 定义网络各层的名称
layers = (
'conv1_1', 'relu1_1', 'conv1_2', 'relu1_2', 'pool1',
'conv2_1', 'relu2_1', 'conv2_2', 'relu2_2', 'pool2',
'conv3_1', 'relu3_1', 'conv3_2', 'relu3_2', 'conv3_3',
'relu3_3', 'conv3_4', 'relu3_4', 'pool3',
'conv4_1', 'relu4_1', 'conv4_2', 'relu4_2', 'conv4_3',
'relu4_3', 'conv4_4', 'relu4_4', 'pool4',
'conv5_1', 'relu5_1', 'conv5_2', 'relu5_2', 'conv5_3',
'relu5_3', 'conv5_4', 'relu5_4'
)
# 从MATLAB文件中加载数据
data = scipy.io.loadmat(data_path)
mean = data['normalization'][0][0][0]
mean_pixel = np.mean(mean, axis=(0, 1))
weights = data['layers'][0]
# 初始化一个空字典来保存每一层的输出
net = {}
current = input_image
for i, name in enumerate(layers):
kind = name[:4]
if kind == 'conv': # 卷积层
# 提取卷积核和偏置
kernels, bias = weights[i][0][0][0][0]
# matconvnet: weights are [width, height, in_channels, out_channels]
# tensorflow: weights are [height, width, in_channels, out_channels]
# 调整卷积核的维度顺序以适应TensorFlow
kernels = np.transpose(kernels, (1, 0, 2, 3))
bias = bias.reshape(-1)
current = _conv_layer(current, kernels, bias)
elif kind == 'relu':
current = tf.nn.relu(current)
elif kind == 'pool':
current = _pool_layer(current)
net[name] = current
# 确保字典中的层数与定义的层数一致
assert len(net) == len(layers)
return net
# 定义卷积层函数
def _conv_layer(input, weights, bias):
conv = tf.nn.conv2d(input, tf.constant(weights), strides=(1, 1, 1, 1),
padding='SAME')
return tf.nn.bias_add(conv, bias)
# 定义池化层函数
def _pool_layer(input):
return tf.nn.max_pool(input, ksize=(1, 2, 2, 1), strides=(1, 2, 2, 1),
padding='SAME')
# 定义图像预处理函数
def preprocess(image):
return image - MEAN_PIXEL
# 定义图像后处理函数
def unprocess(image):
# 将均值像素加回到图像中
return image + MEAN_PIXEL
迁移网络的实现如下:
import tensorflow as tf, pdb
# 用于初始化网络权重的标准差,设置为0.1。
WEIGHTS_INIT_STDEV = .1
# 该函数接受一个图像作为输入,并通过多个卷积层、残差块和反卷积层进行处理。
# 最终,通过tanh激活函数将输出限制在[-1, 1]范围内,并线性变换到[0, 255]范围,这可能是为了与图像像素值的常见范围相匹配。
def net(image):
conv1 = _conv_layer(image, 32, 9, 1)
conv2 = _conv_layer(conv1, 64, 3, 2)
conv3 = _conv_layer(conv2, 128, 3, 2)
resid1 = _residual_block(conv3, 3)
resid2 = _residual_block(resid1, 3)
resid3 = _residual_block(resid2, 3)
resid4 = _residual_block(resid3, 3)
resid5 = _residual_block(resid4, 3)
conv_t1 = _conv_tranpose_layer(resid5, 64, 3, 2)
conv_t2 = _conv_tranpose_layer(conv_t1, 32, 3, 2)
conv_t3 = _conv_layer(conv_t2, 3, 9, 1, relu=False)
preds = tf.nn.tanh(conv_t3) * 150 + 255. / 2
return preds
# 定义一个标准的卷积层,包括卷积操作、实例归一化和ReLU激活函数(可选)。
# num_filters:卷积核的数量。
# filter_size:卷积核的大小。
# strides:卷积步长。
# relu:是否在应用卷积后使用ReLU激活函数。
def _conv_layer(net, num_filters, filter_size, strides, relu=True):
weights_init = _conv_init_vars(net, num_filters, filter_size)
strides_shape = [1, strides, strides, 1]
net = tf.nn.conv2d(net, weights_init, strides_shape, padding='SAME')
net = _instance_norm(net)
if relu:
net = tf.nn.relu(net)
return net
# 定义一个反卷积(或称为转置卷积)层,通常用于上采样或扩大特征图的尺寸。
# 该函数与_conv_layer类似,但使用的是tf.nn.conv2d_transpose进行反卷积操作。
def _conv_tranpose_layer(net, num_filters, filter_size, strides):
weights_init = _conv_init_vars(net, num_filters, filter_size, transpose=True)
batch_size, rows, cols, in_channels = [i.value for i in net.get_shape()]
new_rows, new_cols = int(rows * strides), int(cols * strides)
# new_shape = #tf.pack([tf.shape(net)[0], new_rows, new_cols, num_filters])
new_shape = [batch_size, new_rows, new_cols, num_filters]
tf_shape = tf.stack(new_shape)
strides_shape = [1, strides, strides, 1]
net = tf.nn.conv2d_transpose(net, weights_init, tf_shape, strides_shape, padding='SAME')
net = _instance_norm(net)
return tf.nn.relu(net)
# 定义一个残差块,它包含两个卷积层,并将输入(即“残差”)添加到第二个卷积层的输出上。
# 这种结构有助于网络学习恒等映射,从而更容易地进行优化,并可能提高性能。
def _residual_block(net, filter_size=3):
tmp = _conv_layer(net, 128, filter_size, 1)
return net + _conv_layer(tmp, 128, filter_size, 1, relu=False)
# 实现实例归一化(Instance Normalization),这是一种在风格迁移等任务中常用的归一化技术。
# 它对每个样本的每个通道分别进行归一化,与批量归一化不同,它不依赖于批次中的其他样本。
def _instance_norm(net, train=True):
batch, rows, cols, channels = [i.value for i in net.get_shape()]
var_shape = [channels]
mu, sigma_sq = tf.nn.moments(net, [1, 2], keep_dims=True)
shift = tf.Variable(tf.zeros(var_shape))
scale = tf.Variable(tf.ones(var_shape))
epsilon = 1e-3
normalized = (net - mu) / (sigma_sq + epsilon) ** (.5)
return scale * normalized + shift
# 用于初始化卷积层的权重。
# 权重使用截断的正态分布进行初始化,标准差由WEIGHTS_INIT_STDEV定义。
def _conv_init_vars(net, out_channels, filter_size, transpose=False):
_, rows, cols, in_channels = [i.value for i in net.get_shape()]
if not transpose:
weights_shape = [filter_size, filter_size, in_channels, out_channels]
else:
weights_shape = [filter_size, filter_size, out_channels, in_channels]
weights_init = tf.Variable(tf.truncated_normal(weights_shape, stddev=WEIGHTS_INIT_STDEV, seed=1), dtype=tf.float32)
return weights_init
最后,我们将实现一个模型训练的代码,代码将完成的主要功能如下。
这段代码是一个用于图像风格迁移的Python脚本,它使用了TensorFlow框架和预训练的VGG网络。以下是代码的主要组成部分及其功能的解释:
- 导入模块:
print_function来自__future__用于保持兼容性。functools用于functools.reduce()函数。pdb,time是Python的内置模块,分别用于调试和时间测量。tensorflow,numpy,os是科学计算和操作系统相关的库。src.transform和src.vgg似乎是自定义模块,用于图像转换和加载VGG网络。src.utils中的get_img函数可能用于加载和处理图像。
- 定义风格和内容层:
STYLE_LAYERS: 存储风格迁移使用的风格层的名字。CONTENT_LAYER: 存储内容迁移使用的内容层的名字。DEVICES: 可能用于设置GPU环境变量。
- 优化函数
optimize:- 这个函数执行风格迁移的主要逻辑。
- 参数包括内容和风格图像的目标特征、权重、VGG模型的路径、训练轮数、打印间隔、批量大小、保存路径、学习率等。
- 根据是否使用
slow模式调整批量大小。 - 计算风格图像的Gram矩阵并存储在
style_features字典中。 - 创建TensorFlow图,定义风格和内容图像的占位符,加载VGG网络,并计算损失函数。
- 定义内容损失、风格损失和总变分正则化损失。
- 执行训练步骤,更新生成图像的预测。
- 迭代训练,打印损失并保存模型。
- TensorFlow图和会话:
- 使用
tf.Graph()和tf.Session()创建TensorFlow计算图和会话。 tf.device('/gpu:0')指定操作在GPU上执行。
- 使用
- 预处理和网络加载:
vgg.preprocess()函数用于预处理图像以匹配VGG网络的输入要求。vgg.net()加载预训练的VGG网络。
- 损失函数计算:
- 计算风格损失时,对每个风格层的特征图计算Gram矩阵,并与预先计算的风格图像的Gram矩阵比较。
- 内容损失计算当前图像与内容目标特征的差异。
- 总变分正则化损失鼓励生成图像的空间平滑性。
- 训练步骤:
- 使用
tf.train.AdamOptimizer定义优化器。 train_step运行优化器来最小化损失函数。
- 使用
- 迭代和输出:
- 函数通过迭代训练过程,每次迭代处理一批图像。
- 根据迭代次数打印损失信息,并在训练结束或达到打印间隔时输出。
- 辅助函数
_tensor_size:- 计算给定张量的大小。
from __future__ import print_function
import functools
import src.vgg as vgg
import pdb, time
import tensorflow as tf, numpy as np, os
import src.transform as transform
from src.utils import get_img
# 首先是确定风格层和内容层,这里的风格层使用多个,然后内容层仅仅使用一个
STYLE_LAYERS = ('relu1_1', 'relu2_1', 'relu3_1', 'relu4_1', 'relu5_1')
CONTENT_LAYER = 'relu4_2'
DEVICES = 'CUDA_VISIBLE_DEVICES'
# np arr, np arr
# 确定参数,内容图片、风格图片、各自的权重,vgg的路径,轮数,打印次数,batch_size的大小,保存路径和学习率
def optimize(content_targets, style_target, content_weight, style_weight,
tv_weight, vgg_path, epochs=2, print_iterations=1000,
batch_size=4, save_path='saver/fns.ckpt', slow=False,
learning_rate=1e-3, debug=False):
if slow:
batch_size = 1
mod = len(content_targets) % batch_size
if mod > 0:
# 对图片进行切割的操作
print("Train set has been trimmed slightly..")
content_targets = content_targets[:-mod]
# 把风格图片的风格特征固定在字典中
style_features = {}
# 固定内容和风格的形状
batch_shape = (batch_size, 256, 256, 3)
style_shape = (1,) + style_target.shape
print(style_shape)
# precompute style features
# 启动训练过程,tensorflow的图和绘画
with tf.Graph().as_default(), tf.device('/gpu:0'), tf.Session() as sess:
# 转化为张量的形式进行训练
style_image = tf.placeholder(tf.float32, shape=style_shape, name='style_image')
# 对风格图片进行预处理,按照vgg的方式对图片进行预处理
style_image_pre = vgg.preprocess(style_image)
# 加载vgg网络
net = vgg.net(vgg_path, style_image_pre)
style_pre = np.array([style_target])
# 获取特征图的特征并计算相对应的gram矩阵
for layer in STYLE_LAYERS:
features = net[layer].eval(feed_dict={style_image: style_pre})
features = np.reshape(features, (-1, features.shape[3]))
gram = np.matmul(features.T, features) / features.size
style_features[layer] = gram
with tf.Graph().as_default(), tf.Session() as sess:
# 计算内容相对应的内容特征
X_content = tf.placeholder(tf.float32, shape=batch_shape, name="X_content")
X_pre = vgg.preprocess(X_content)
# precompute content features
content_features = {}
content_net = vgg.net(vgg_path, X_pre)
content_features[CONTENT_LAYER] = content_net[CONTENT_LAYER]
if slow:
preds = tf.Variable(
tf.random_normal(X_content.get_shape()) * 0.256
)
preds_pre = preds
else:
preds = transform.net(X_content / 255.0)
preds_pre = vgg.preprocess(preds)
net = vgg.net(vgg_path, preds_pre)
content_size = _tensor_size(content_features[CONTENT_LAYER]) * batch_size
assert _tensor_size(content_features[CONTENT_LAYER]) == _tensor_size(net[CONTENT_LAYER])
content_loss = content_weight * (2 * tf.nn.l2_loss(
net[CONTENT_LAYER] - content_features[CONTENT_LAYER]) / content_size
)
style_losses = []
for style_layer in STYLE_LAYERS:
layer = net[style_layer]
bs, height, width, filters = map(lambda i: i.value, layer.get_shape())
size = height * width * filters
feats = tf.reshape(layer, (bs, height * width, filters))
feats_T = tf.transpose(feats, perm=[0, 2, 1])
grams = tf.matmul(feats_T, feats) / size
style_gram = style_features[style_layer]
style_losses.append(2 * tf.nn.l2_loss(grams - style_gram) / style_gram.size)
style_loss = style_weight * functools.reduce(tf.add, style_losses) / batch_size
# total variation denoising
# 计算损失
tv_y_size = _tensor_size(preds[:, 1:, :, :])
tv_x_size = _tensor_size(preds[:, :, 1:, :])
y_tv = tf.nn.l2_loss(preds[:, 1:, :, :] - preds[:, :batch_shape[1] - 1, :, :])
x_tv = tf.nn.l2_loss(preds[:, :, 1:, :] - preds[:, :, :batch_shape[2] - 1, :])
tv_loss = tv_weight * 2 * (x_tv / tv_x_size + y_tv / tv_y_size) / batch_size
loss = content_loss + style_loss + tv_loss
# overall loss
train_step = tf.train.AdamOptimizer(learning_rate).minimize(loss)
sess.run(tf.global_variables_initializer())
import random
uid = random.randint(1, 100)
print("UID: %s" % uid)
for epoch in range(epochs):
num_examples = len(content_targets)
iterations = 0
while iterations * batch_size < num_examples:
start_time = time.time()
curr = iterations * batch_size
step = curr + batch_size
X_batch = np.zeros(batch_shape, dtype=np.float32)
for j, img_p in enumerate(content_targets[curr:step]):
X_batch[j] = get_img(img_p, (256, 256, 3)).astype(np.float32)
iterations += 1
assert X_batch.shape[0] == batch_size
feed_dict = {
X_content: X_batch
}
train_step.run(feed_dict=feed_dict)
end_time = time.time()
delta_time = end_time - start_time
if debug:
print("UID: %s, batch time: %s" % (uid, delta_time))
is_print_iter = int(iterations) % print_iterations == 0
if slow:
is_print_iter = epoch % print_iterations == 0
is_last = epoch == epochs - 1 and iterations * batch_size >= num_examples
should_print = is_print_iter or is_last
if should_print:
to_get = [style_loss, content_loss, tv_loss, loss, preds]
test_feed_dict = {
X_content: X_batch
}
tup = sess.run(to_get, feed_dict=test_feed_dict)
_style_loss, _content_loss, _tv_loss, _loss, _preds = tup
losses = (_style_loss, _content_loss, _tv_loss, _loss)
if slow:
_preds = vgg.unprocess(_preds)
else:
saver = tf.train.Saver()
res = saver.save(sess, save_path)
yield (_preds, losses, iterations, epoch)
def _tensor_size(tensor):
from operator import mul
return functools.reduce(mul, (d.value for d in tensor.get_shape()[1:]), 1)
核心代码就是这样咯,需要更详细的解释大家可以借助一些AI模型执行哟。
环境配置
开始之前记得将源切换为国内的用于加速,指令如下
conda config --remove-key channels
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
conda config --set show_channel_urls yes
pip config set global.index-url https://mirror.baidu.com/pypi/simple
安装匹配的虚拟环境
创建虚拟环境并激活

激活使用conda activate tf37指令,如果命令行左侧出现环境名称表示你激活成功。

之后需要看你是否在你的项目目录下,如果不在代码目录下请通过cd指令cd到对应的代码目录下,通过dir指令查看你这个目录下,如果出现req.txt文件表示你当前步的操作是没有问题的。

接下来,直接通过执行下列指令即可完成所有依赖库的安装。
pip install -r req.txt

执行完毕之后可以执行下面指令进行测试,如果出现图形化界面即表示运行成功。

最后使用pycharm打开并选择你激活的虚拟环境你就可以享受这份代码了。
挑战与未来方向
图像风格迁移是一个活跃的研究领域,未来有望理论和应用两方面都取得更多的突破,为艺术和设计等带来更多的可能性,未来可能的研究方向包括。
- 多模态风格迁移: 未来的研究可能会探索将不同模态的风格(如视频、3D模型等)迁移到图像上,创造更为丰富的视觉效果。
- 用户交互性: 提高用户交互性,允许用户通过更直观的方式(如草图、手势等)来控制风格迁移过程,可能是未来研究的一个方向。
- 风格迁移的可控性: 研究如何让用户能够控制风格迁移的程度和区域,实现更加精细的风格迁移效果。
- 跨域风格迁移: 探索跨域风格迁移,例如将绘画作品的风格应用到摄影图像上,或者将古代艺术风格迁移到现代图像上。
- 风格迁移的可解释性: 提高风格迁移过程的可解释性,帮助用户理解网络是如何学习和应用不同风格的。
- 应用拓展: 将风格迁移技术应用于更广泛的领域,如影视后期制作、虚拟现实、增强现实等。
- 鲁棒性和泛化能力: 提高模型的鲁棒性和泛化能力,使其能够适应不同的风格和内容,减少对特定训练数据集的依赖。
- 计算效率: 进一步优化算法,减少计算资源消耗,使风格迁移技术能够在更多设备上实时运行。
















 2091
2091











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











