







YOLO11模型指标解读-mAP、Precision、Recall
👆👆👆👆👆👆👆👆👆👆👆👆强烈推荐👆👆👆👆👆👆👆👆👆👆👆👆👆
使用yolo代码对自己的数据集训练之后在runs目录下会产生很多的图,有不少小伙伴对这些图的含义存在疑问,为了能够方便大家写报告或者论文,今天我们一起把这些图的含义在这篇博客中说明一下。
今天我将会以车辆检测这个任务为例进行说明,这里是使用的是yolo11的模型结构对数据集进行训练,这个数据集中一共包含了4类目标(car、bus、van、others),经过100轮的训练之后,现在在runs目录下产生了24个项目,下面我将对这些项目一一进行解读。
数据相关
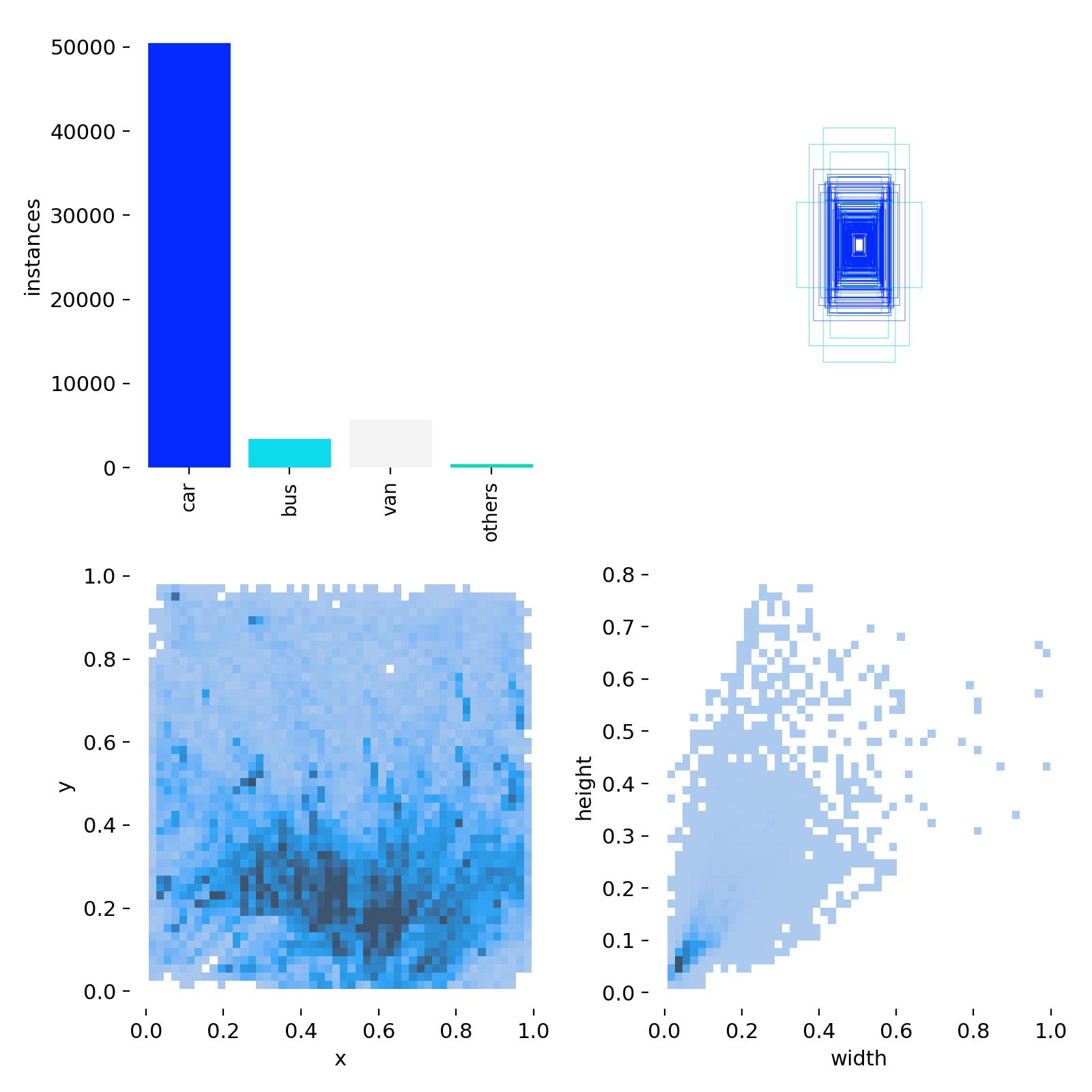
labels.jpg
这个图是用来描述你的数据分布的,其中左上角的图像是用来描述数据集的每个类别对应的样例个数的,右上角的图是用来描述图像中边界框的分布的,左下角的图像是描述你所有的样本中中心点的分布的,因为我们训练的数据集是车辆,车辆基本存在在马路上,所以你可以看到这里的中下方中的密度比较大一些。最后一幅图像是用来描述数据集中目标的宽高分布的。
labels_correlogram.jpg
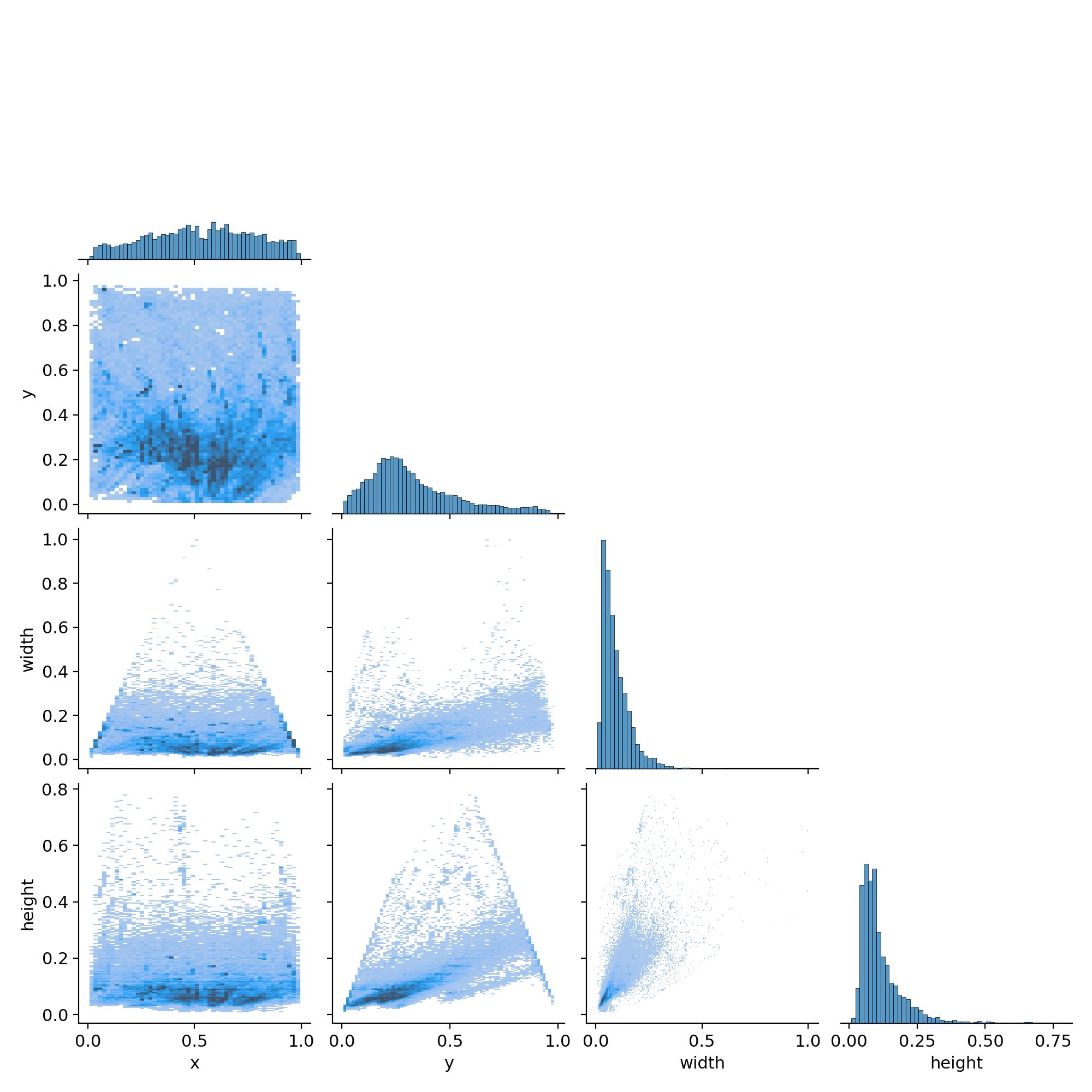
这幅图是用来描述数据集中中心点、宽高的相关性。比如在有的数据集中,如果目标位于中心,那这个图像的高度也可能比较高一些,主要是用来描述指标之间的关联性。
train_batchx.jpg
这里主要是用来描述数据是如何进入网络的,从下面的图像中也能看出数据集是如何进行数据增强的。比如下面所演示的图像中,进行了马赛克的数据拼接以及颜色的变化和随机的图像翻转,在描述数据增强的时候可以使用下面的图像进行演示。

模型训练相关
下面的几个内容主要是和模型的训练过程有关,可以用下面的图来描述你的模型是如何训练的。
args.yaml
args.yaml是一个配置文件,通常用来存储模型训练、验证和推理过程中需要的超参数和其他配置选项,他的内容如下。
task: detect # 任务类型,这里是目标检测
mode: train # 模式,这里是训练模式
model: runs\detect\train3\weights\last.pt # 预训练模型路径,或继续训练的模型路径
data: G:\Upppppdate\AAAAA-standard-code\yolo11\ultralytics-8.3.2\ultralytics\cfg\datasets\A_my_data.yaml # 数据集配置文件路径
epochs: 100 # 训练的轮数
time: null # 训练时长,通常设置为null,自动计算
patience: 100 # 提前停止的耐心度,训练中如果在指定轮次内没有提升,则提前停止
batch: 4 # 每批次训练样本的数量
imgsz: 640 # 输入图像的尺寸
save: true # 是否保存模型
save_period: -1 # 保存模型的周期,-1表示每次训练结束后保存
cache: true # 是否缓存数据集以加速训练
device: # 使用的设备,-1表示CPU,0表示第一张GPU,多个GPU可用列表表示
- 0
workers: 0 # 数据加载时的工作线程数
project: null # 项目名称,用于保存训练日志等
name: train3 # 实验名称,用于保存训练结果文件夹的命名
exist_ok: false # 如果指定的文件夹存在是否覆盖,false表示不会覆盖
pretrained: yolo11n.pt # 使用的预训练模型权重文件
optimizer: auto # 优化器,auto表示自动选择
verbose: true # 是否显示详细信息
seed: 0 # 随机种子,设置为0表示使用系统默认
deterministic: true # 是否使用确定性操作,保证结果可复现
single_cls: false # 是否单类检测
rect: false # 是否使用矩形训练数据(padding时使用矩形,而不是正方形)
cos_lr: false # 是否使用余弦学习率调度
close_mosaic: 10 # 控制Mosaic增强中的图像拼接方式,数值越大拼接的几率越低
resume: runs\detect\train3\weights\last.pt # 从哪个权重文件继续训练
amp: true # 是否启用自动混合精度训练
fraction: 1.0 # 使用数据集的比例
profile: false # 是否启用训练过程的性能分析
freeze: null # 冻结网络的层数,null表示不冻结
multi_scale: false # 是否启用多尺度训练
overlap_mask: true # 是否启用目标遮罩(适用于实例分割)
mask_ratio: 4 # 在分割中,遮罩的尺寸比例
dropout: 0.0 # Dropout正则化的比例
val: true # 是否进行验证
split: val # 验证集的划分方式(通常使用val集进行验证)
save_json: false # 是否保存验证结果为JSON格式
save_hybrid: false # 是否保存混合格式结果
conf: null # 置信度阈值
iou: 0.7 # Intersection over Union (IoU) 阈值,决定是否认为预测框是正确的
max_det: 300 # 每张图像最大检测框数量
half: false # 是否使用半精度浮点数(FP16)训练
dnn: false # 是否使用深度神经网络推理优化(例如ONNX)
plots: true # 是否绘制训练过程中的各种指标图
source: null # 推理时使用的数据来源,通常为空
vid_stride: 1 # 视频帧间隔步长
stream_buffer: false # 是否启用视频流缓冲
visualize: false # 是否可视化训练过程
augment: false # 是否启用数据增强
agnostic_nms: false # 是否启用类别无关的NMS(非极大值抑制)
classes: null # 指定要检测的类别,null表示检测所有类别
retina_masks: false # 是否启用RetinaNet样式的掩码分支
embed: null # 是否使用嵌入层
show: false # 是否显示推理结果
save_frames: false # 是否保存推理结果的每一帧
save_txt: false # 是否保存每个检测结果的文本文件
save_conf: false # 是否保存每个检测框的置信度
save_crop: false # 是否保存裁剪后的目标图像
show_labels: true # 是否显示检测框的标签
show_conf: true # 是否显示检测框的置信度
show_boxes: true # 是否显示检测框
line_width: null # 检测框的线宽
format: torchscript # 导出格式,支持torchscript、onnx等
keras: false # 是否导出为Keras模型
optimize: false # 是否进行模型优化
int8: false # 是否启用int8量化
dynamic: false # 是否启用动态模型推理
simplify: true # 是否简化模型
opset: null # ONNX导出时的opset版本
workspace: 4 # ONNX导出时的工作区大小
nms: false # 是否使用非极大值抑制(NMS)
lr0: 0.01 # 初始学习率
lrf: 0.01 # 学习率衰减系数
momentum: 0.937 # 动量
weight_decay: 0.0005 # 权重衰减
warmup_epochs: 3.0 # 预热轮次
warmup_momentum: 0.8 # 预热时的动量
warmup_bias_lr: 0.0 # 预热时的偏置学习率
box: 7.5 # 目标框损失权重
cls: 0.5 # 类别损失权重
dfl: 1.5 # Distribution Focal Loss权重
pose: 12.0 # 姿态损失权重
kobj: 1.0 # 对象关键点损失权重
label_smoothing: 0.0 # 标签平滑
nbs: 64 # 每次训练的批次大小
hsv_h: 0.015 # 色相调整范围
hsv_s: 0.7 # 饱和度调整范围
hsv_v: 0.4 # 亮度调整范围
degrees: 0.0 # 图像旋转范围(角度)
translate: 0.1 # 图像平移范围
scale: 0.5 # 图像缩放范围
shear: 0.0 # 图像剪切范围
perspective: 0.0 # 透视变换范围
flipud: 0.0 # 是否进行上下翻转
fliplr: 0.5 # 左右翻转的概率
bgr: 0.0 # BGR通
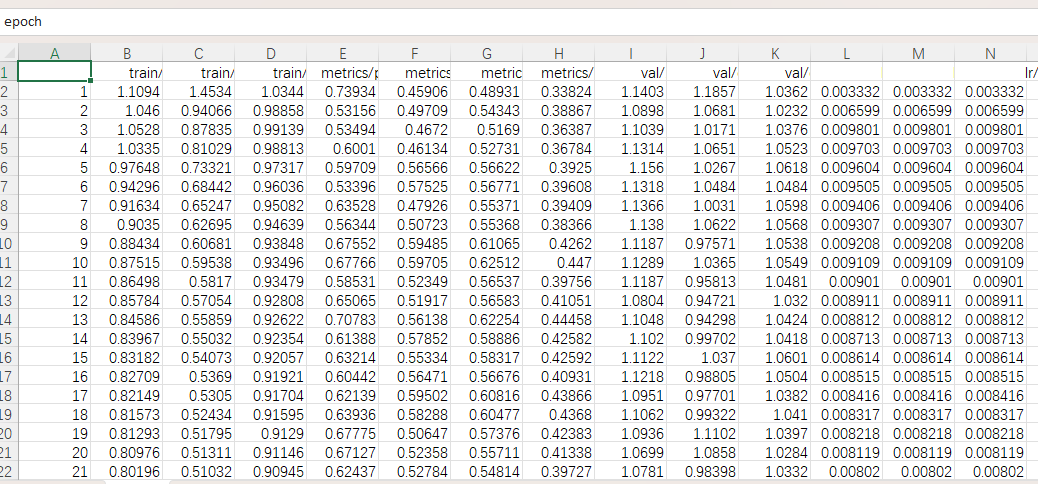
results.csv
这里的csv用文字的形式记录了训练过程中loss和准确率的变化,在实际使用中,我们最好还是使用results.png对图像的指标进行解读。
results.png
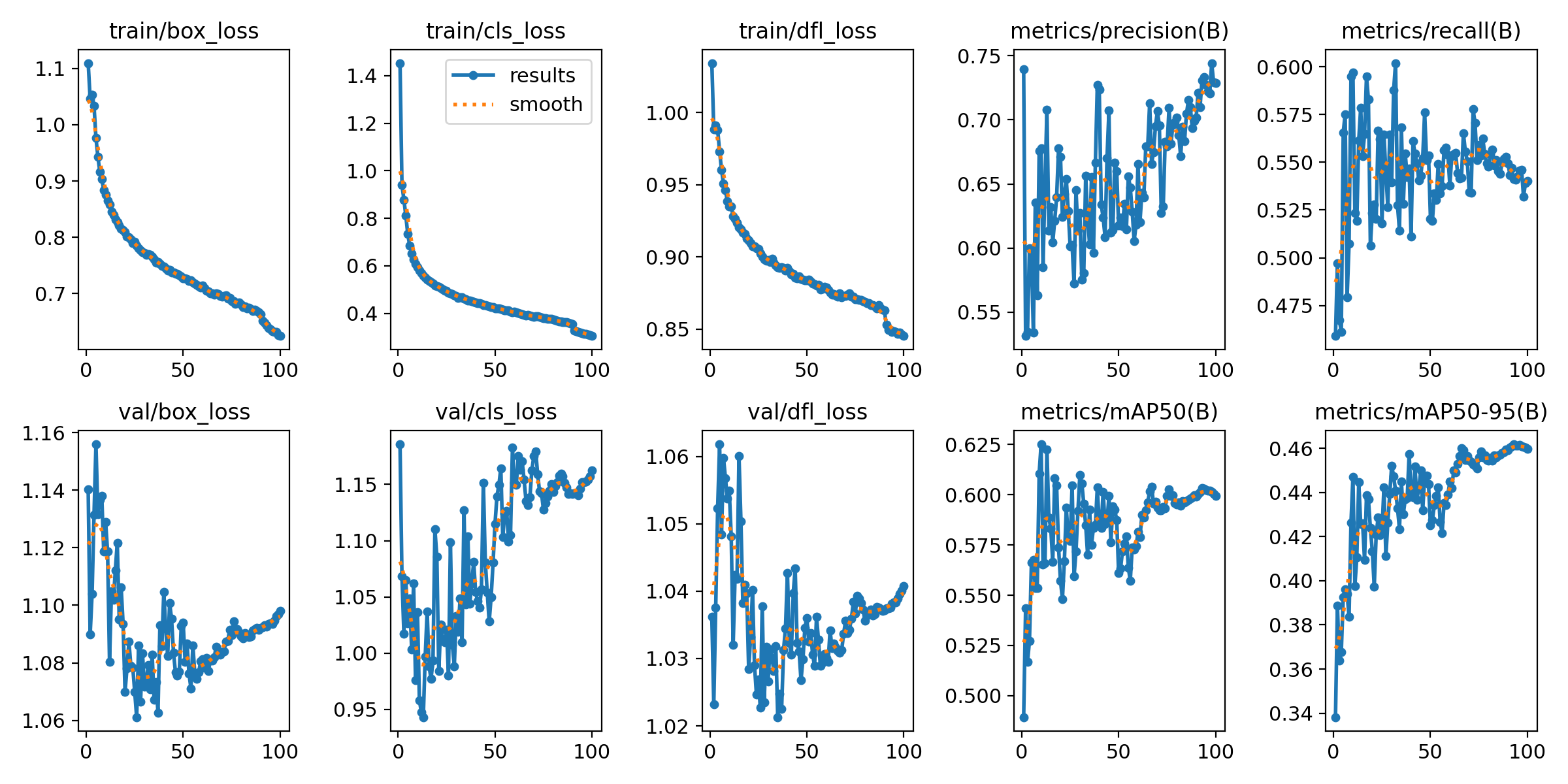
这张图相当于上面文本的图像绘制结果。主要包括损失函数(Loss)和精度(mAP)的变化情况,通常用于评估训练的效果和模型的性能,一般在描述模型训练的时候使用这张图,这张图的横坐标是训练的轮数,纵轴是具体的指标。大家在描述的时候基本对你的曲线变化的趋势进行一下描述即可。
这张图展示了YOLO训练过程中的几个关键指标,可以用来评估模型在训练期间的表现。虽然图像没有具体标签,但我可以根据常见的YOLO训练图像类型进行解读:
- 损失函数(Loss)
-
损失函数通常会在训练过程中逐渐下降,表示模型在训练数据上的误差不断减少。YOLO的损失函数通常由三个部分组成:边界框损失(Box Loss)、类别损失(Class Loss)和置信度损失(Confidence Loss)。
- Box Loss:表示预测边界框的位置和实际边界框之间的误差,通常用IoU(交并比)来衡量。
- Class Loss:表示模型预测的类别与实际类别之间的误差。
- Confidence Loss:表示预测的目标置信度与实际目标置信度之间的差异。
如果损失函数下降平稳,说明模型在学习目标检测任务。如果损失下降非常缓慢或者停滞,可能需要调整学习率、批量大小等超参数,或者尝试不同的优化器。
- 学习率(Learning Rate)
- 学习率是控制模型权重更新步幅的关键超参数。图中的学习率通常会在训练过程中变化(例如,逐渐衰减),这可以帮助模型在初期快速学习,后期则可以细化调整。
- 如果看到学习率的曲线在某些时刻有突然增加或波动,可能是由于训练中的调度策略(如余弦退火、StepLR等)所引起。
- 精度(Precision)和召回率(Recall)
-
精度(Precision):表示所有被模型预测为正样本(目标)的框中,有多少是真正的目标(即TP / (TP + FP))。精度值越高,说明模型对目标的误检较少。
-
召回率(Recall):表示所有真实目标中,有多少被模型正确识别出来(即TP / (TP + FN))。召回率越高,说明模型漏检的目标较少。
训练过程中,精度和召回率通常会有一个权衡关系。提高召回率通常会导致精度下降,反之亦然。观察图中的这两条曲线,可以分析模型是否偏向于过度检测目标(高召回率但低精度)或者只检测部分目标(高精度但低召回率)。
- mAP(Mean Average Precision)
-
mAP
(平均精度均值)是衡量目标检测模型整体性能的重要指标,它综合了精度和召回率。在不同的IoU(Intersection over Union)阈值下,mAP值通常会计算模型在多个类别上的检测性能。
- 如果mAP值上升,说明模型的整体检测效果在改善。
- 如果mAP值在训练过程中维持不变或下降,可能说明模型的训练效果不好,可能需要调整学习率、增加训练数据量或改善数据增强策略。
- 目标框数量(Number of Detections)
-
目标框数量
通常显示为每张图片检测到的目标数量。随着训练的进行,检测到的目标数量应该趋于稳定,且接近实际的目标数。
- 如果目标框数量逐渐增加,说明模型在不断提高对目标的检测能力。
- 如果目标框数量过少或过多,可能需要调整阈值或进一步优化模型。
- 训练/验证误差(Train/Val Loss)
- 训练误差和验证误差反映了模型在训练集和验证集上的表现。如果训练误差持续下降,但验证误差上升,说明模型可能过拟合了训练数据。
- 理想情况下,训练误差和验证误差都应该持续下降,并趋于平稳。如果验证误差在某一阶段停止下降,可能需要增加数据集的多样性或使用正则化技术(如Dropout)来防止过拟合。
总结
- 理想的训练过程:损失函数逐步下降,精度和召回率逐渐提高,mAP稳步提升,训练/验证误差差距较小。
- 不理想的训练过程:如果看到精度、召回率或mAP波动较大,可能是由于超参数选择不当(如学习率过大或过小),或者数据集本身的问题(如数据不平衡或标注错误)。
通过这些指标,可以全面了解YOLO模型的训练状态,帮助调试和优化模型。
weights
weights目录是训练之后的模型,其中best表示在训练过程中验证集上表现最好的模型,last表示训练过程中最后一轮的模型,如果你想要查看这个模型,可以通过netron.com来进行上传查看。
模型验证相关
下面的几张图用在模型的性能说明中,包含了模型的指标上的结果和可视化上的结果,一般写在你的结果和分析中。
confusion_matrix.png
这张图是混淆矩阵,可以用来看每个类的准确率。**混淆矩阵(Confusion Matrix)**是一种用于评估模型性能的可视化工具,通常用于展示模型预测结果与真实标签的对比情况。它扩展了分类任务中的混淆矩阵概念,以适应目标检测中更复杂的场景。
混淆矩阵是一个二维表格,其中:
- 行(纵轴):表示真实类别(Ground Truth)。
- 列(横轴):表示模型预测的类别。
- 每个单元格的值:表示模型将某个类别的样本预测为另一类别的次数。
例如:
| 真实类别 \ 预测类别 | 类别 A | 类别 B | 类别 C | 背景 |
|---|---|---|---|---|
| 类别 A | 50 | 10 | 5 | 35 |
| 类别 B | 8 | 70 | 2 | 20 |
| 类别 C | 4 | 3 | 90 | 10 |
| 背景 | 15 | 8 | 12 | 100 |
- 主对角线(如
A->A,B->B):表示模型的正确预测。 - 非对角线(如
A->B,B->C):表示模型的误分类。 - 背景行/列:表示模型对无目标区域(背景)的预测结果。
针对我们这个车辆检测的任务而言。
- 横轴 (True):
- 表示真实的类别标签,包括
car、bus、van、others和background。
- 表示真实的类别标签,包括
- 纵轴 (Predicted):
- 表示模型预测的类别,同样包括
car、bus、van、others和background。
- 表示模型预测的类别,同样包括
- 数值含义:
- 每个单元格的值表示特定类别的真实值与预测值的数量。例如:
- 左上角的
15469表示模型正确预测了15469个car。
- 左上角的
- 每个单元格的值表示特定类别的真实值与预测值的数量。例如:
- 颜色深浅:
- 颜色越深,代表对应单元格中的数量越大;颜色越浅,数量越小。
关键结果分析:
- 主对角线:
- 主对角线(从左上到右下)表示模型正确分类的数量。值越大,说明模型分类准确率越高。
- 如
car的正确分类数量是 15469,bus是 2322。
- 误分类情况(非对角线区域):
- 非对角线上的值表示模型的误分类。例如:
- 在真实类别为
car的样本中,模型将 4129 个误分类为background。 - 真实
van的样本中,模型错误预测为car的有 107。
- 在真实类别为
- 非对角线上的值表示模型的误分类。例如:
- 背景误检:
- 真实标签为
background的样本中,模型误预测为其他类别(如car)的数量较高(6164)。
- 真实标签为
- 类别之间的混淆:
- 模型容易将一些
van样本误预测为car(107),反映类别之间可能存在相似特征,影响了模型的判断。
- 模型容易将一些
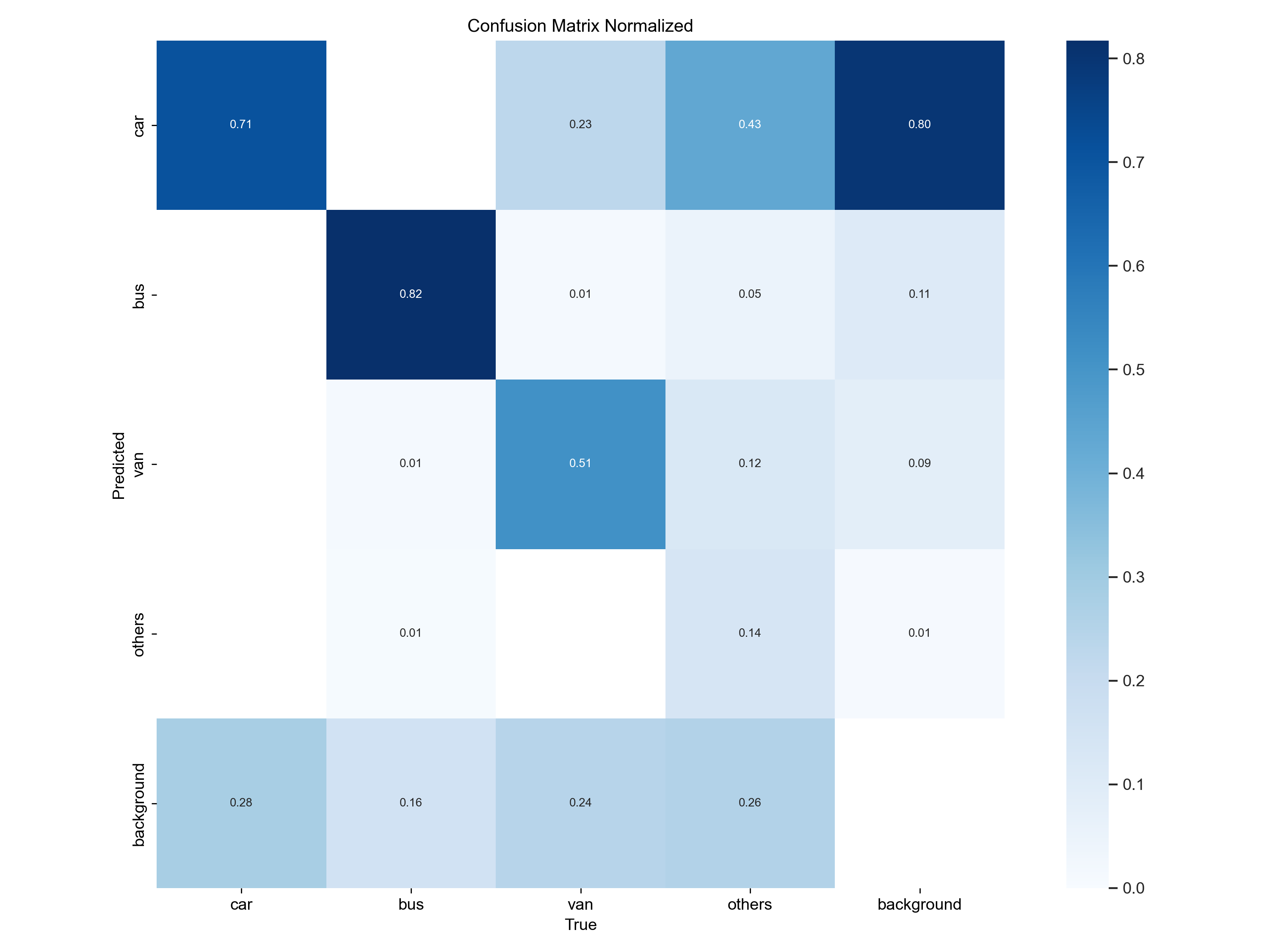
confusion_matrix_normalized.png
这个图是上面图像的归一化,也就是将上图的结果用当前数量分别除以每一列的总数之后得到的结果,表示的含义和上面的confusion_matrix一致。
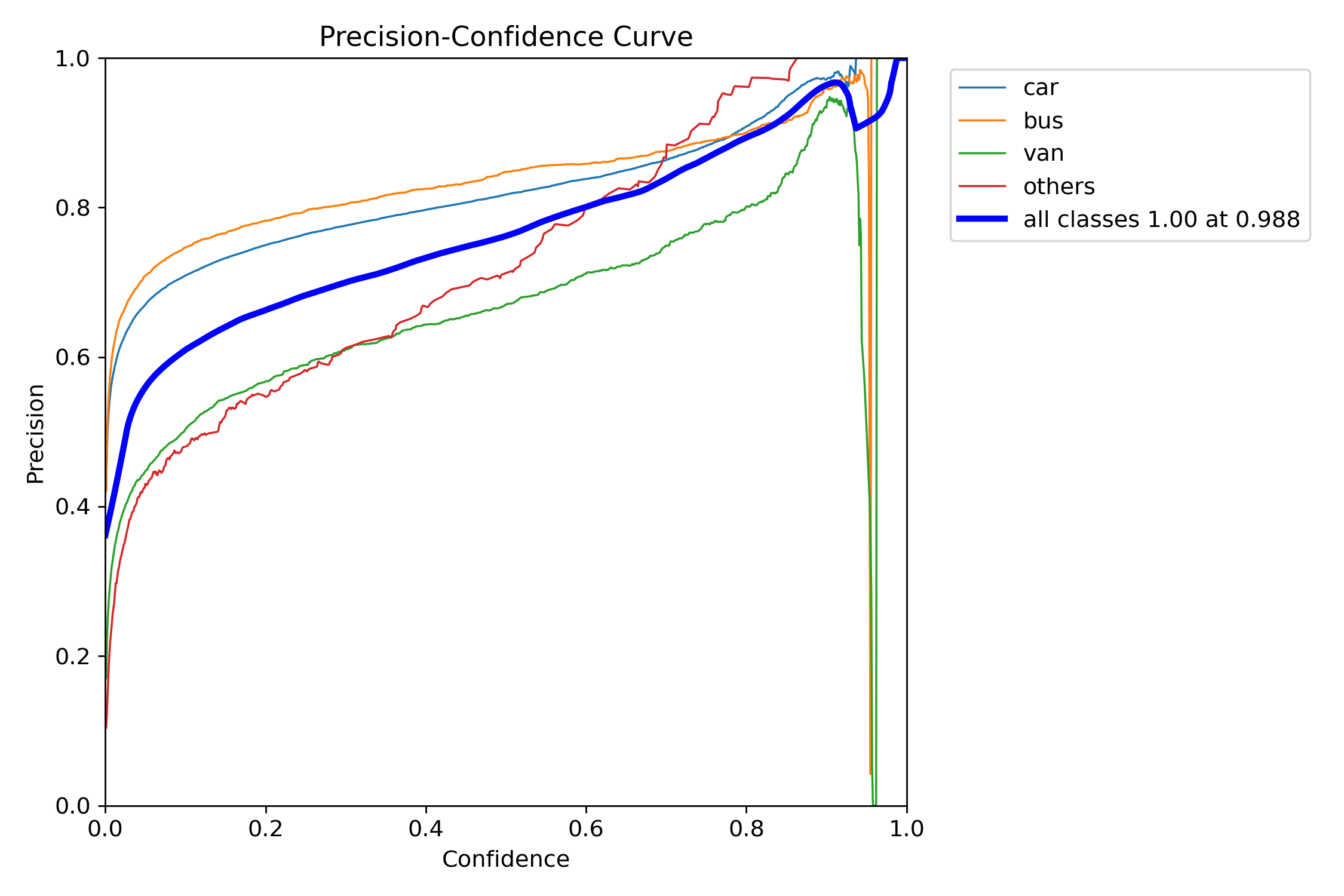
P_curve.png
搞懂下面几个图之前,让我们先学习一下什么是TP,什么是FP,这里是TP不是传送的意思奥,他是True Positive的简写。
TP (True Positive) - 真阳性
-
定义:指模型正确预测为正类的样本数量。
-
在目标检测中:
-
正确检测到目标
:模型预测出一个目标框,且:
- 预测的类别与真实类别一致。
- 预测框和真实框的重叠区域满足某个 IoU(Intersection over Union)阈值(如 IoU ≥ 0.5)。
-
-
示例
- 真实图片中有一辆车(真实类别是“car”),模型也预测出了一个框,且标记为“car”,这个检测就被视为一个TP。
FP (False Positive) - 假阳性
-
定义:指模型错误预测为正类的样本数量。
-
在目标检测中:
-
误检测
:模型检测到了一个目标框,但该框并不正确,可能是以下情况之一:
- 预测的类别与真实类别不一致。
- 预测框与真实框的 IoU 小于指定阈值(如 IoU < 0.5)。
- 实际上该区域没有目标,但模型错误地检测出了目标(即“背景”被错误预测为目标)。
-
-
示例
- 真实图片中没有车,但模型错误预测出一个“car”框。
- 真实图片中有一辆车,但预测框的位置与真实框严重不符(IoU 很小)
下面可以用一个简单的表格来表示一个这个指标。
| 预测 / 实际 | 正类(目标存在) | 负类(目标不存在) |
|---|---|---|
| 正类(预测为目标) | TP(True Positive) | FP(False Positive) |
| 负类(未预测为目标) | FN(False Negative) | TN(True Negative) |
对于目标检测任务而言,TP 和 FP 的定义基于以下两个标准:
- 类别正确性:
- 预测框的类别必须与真实目标的类别一致。
- IoU 阈值:
- 预测框和真实目标框之间的 IoU 值必须大于某个阈值(例如 0.5)。
- 如果预测框满足上述两个条件,则视为 TP。
- 如果预测框不满足上述任意一个条件,则视为 FP。
----------------------------------------------分割线-----------------------------------------
基于上面的基础知识,我们首先可以得到P的定义。
精确率(Precision):
P表示模型预测的正样本中,有多少是正确的。
-
公式:
Precision = True Positives (TP) True Positives (TP) + False Positives (FP) \text{Precision} = \frac{\text{True Positives (TP)}}{\text{True Positives (TP)} + \text{False Positives (FP)}} Precision=True Positives (TP)+False Positives (FP)True Positives (TP) -
TP(真阳性):预测为正的目标,且真实为正。
-
FP(假阳性):预测为正的目标,但真实为负(误检)。
在我们的任务中,这张图表示在置信度为0.988的情况下,P值可以达到1.0
R_curve.png
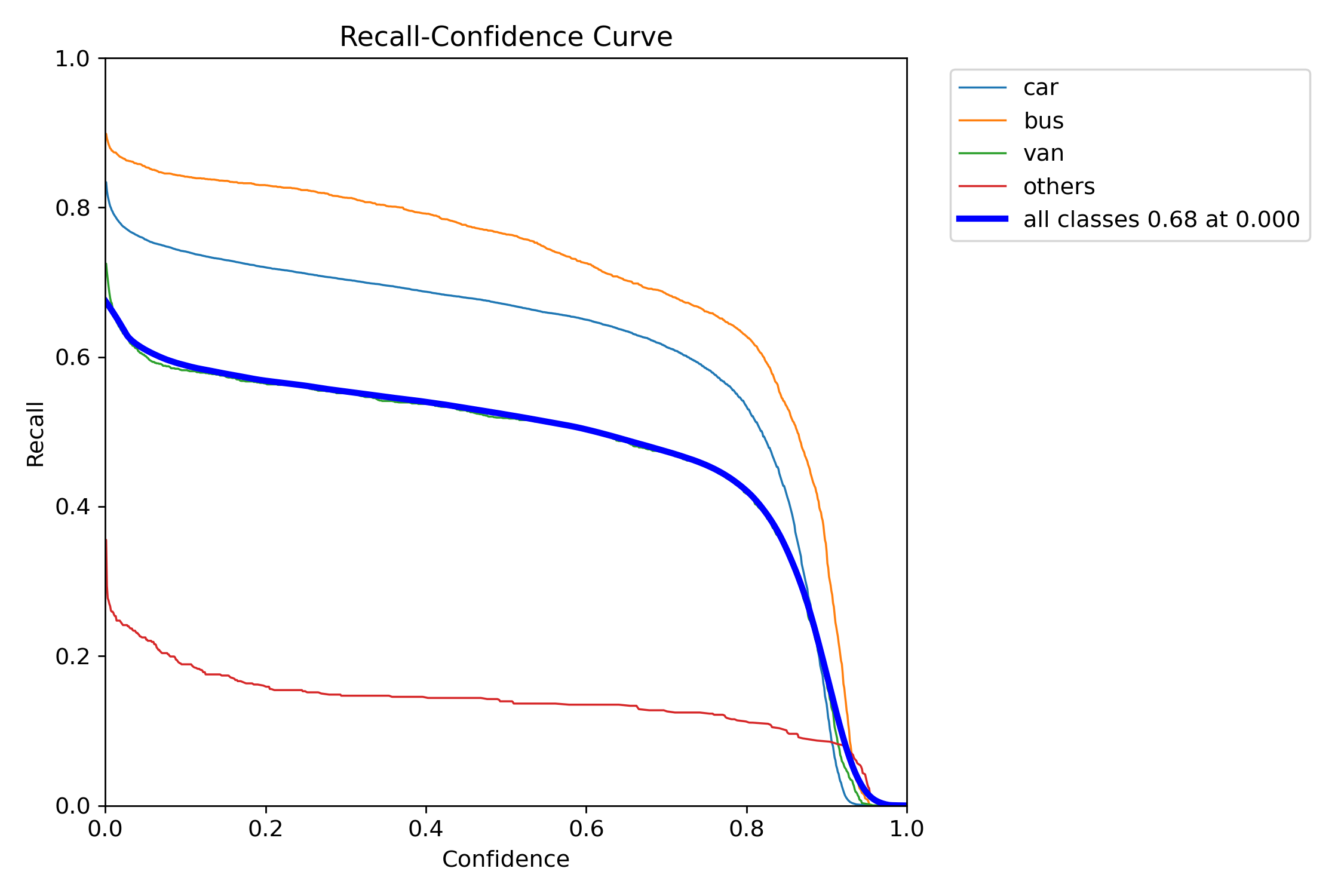
同样,基于上面的基础,我们也可以得到R的基本概念。
召回率(Recall):
R表示真实正样本中,有多少被正确预测。
-
公式:
Recall = True Positives (TP) True Positives (TP) + False Negatives (FN) \text{Recall} = \frac{\text{True Positives (TP)}}{\text{True Positives (TP)} + \text{False Negatives (FN)}} Recall=True Positives (TP)+False Negatives (FN)True Positives (TP) -
FN(假阴性):真实为正的目标,但未被检测到(漏检)。
在我们的任务重,当置信度阈值为0的时候,我们模型的召回率可以达到68.8%。
F1_curve.png
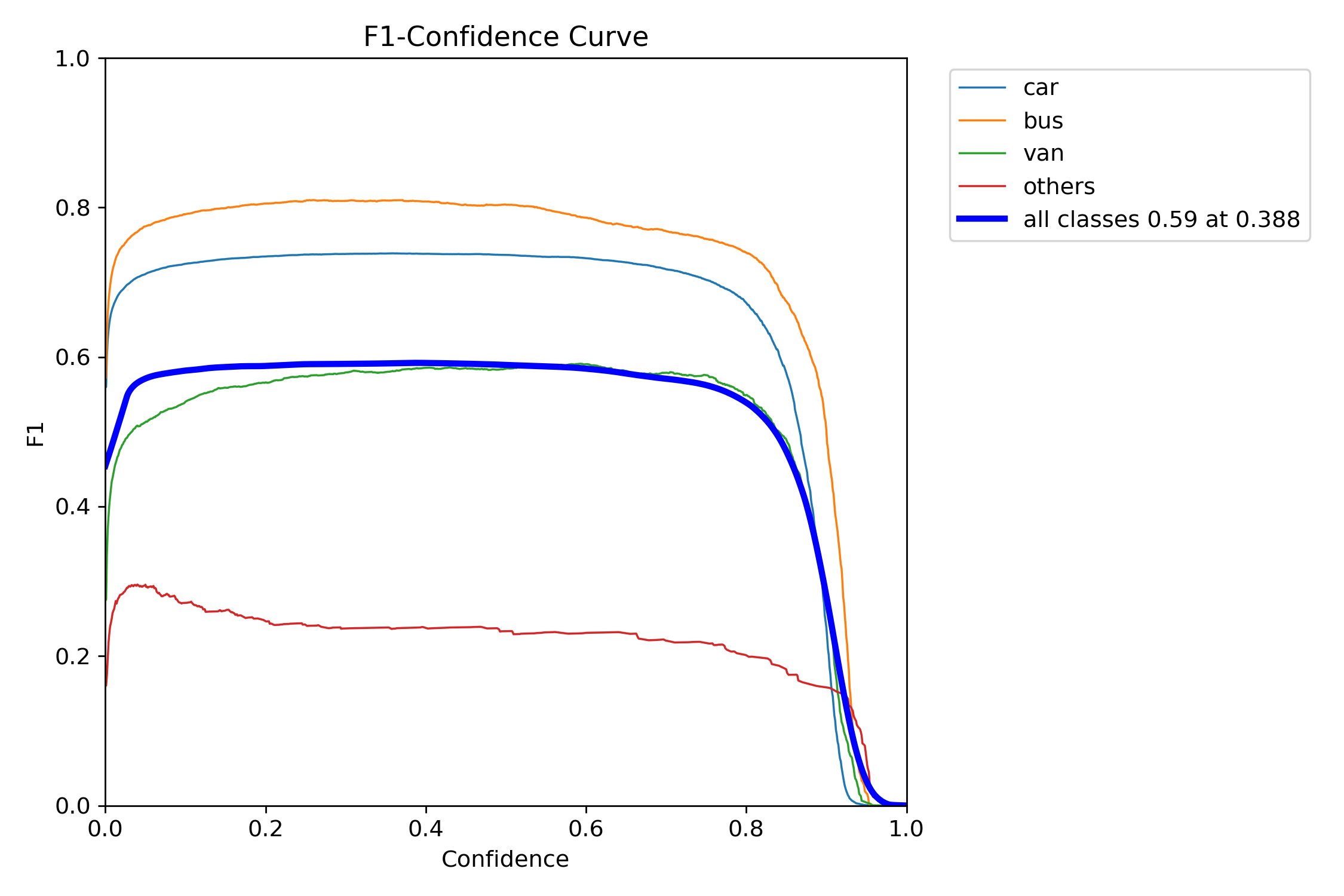
F1指标是精确率和召回率的调和平均值,其公式为:
F 1 = 2 ⋅ Precision ⋅ Recall Precision + Recall F1 = 2 \cdot \frac{\text{Precision} \cdot \text{Recall}}{\text{Precision} + \text{Recall}} F1=2⋅Precision+RecallPrecision⋅Recall
- 当模型的精确率和召回率不平衡时,F1值可以作为综合评估的指标。
- F1指标的值介于 0 和 1 之间,值越接近 1,说明模型性能越好。
对于我们本次的任务而言,这样图在置信度阈值为0.388的时候,所有类的F1指标可以达到59%。
PR_curve.png
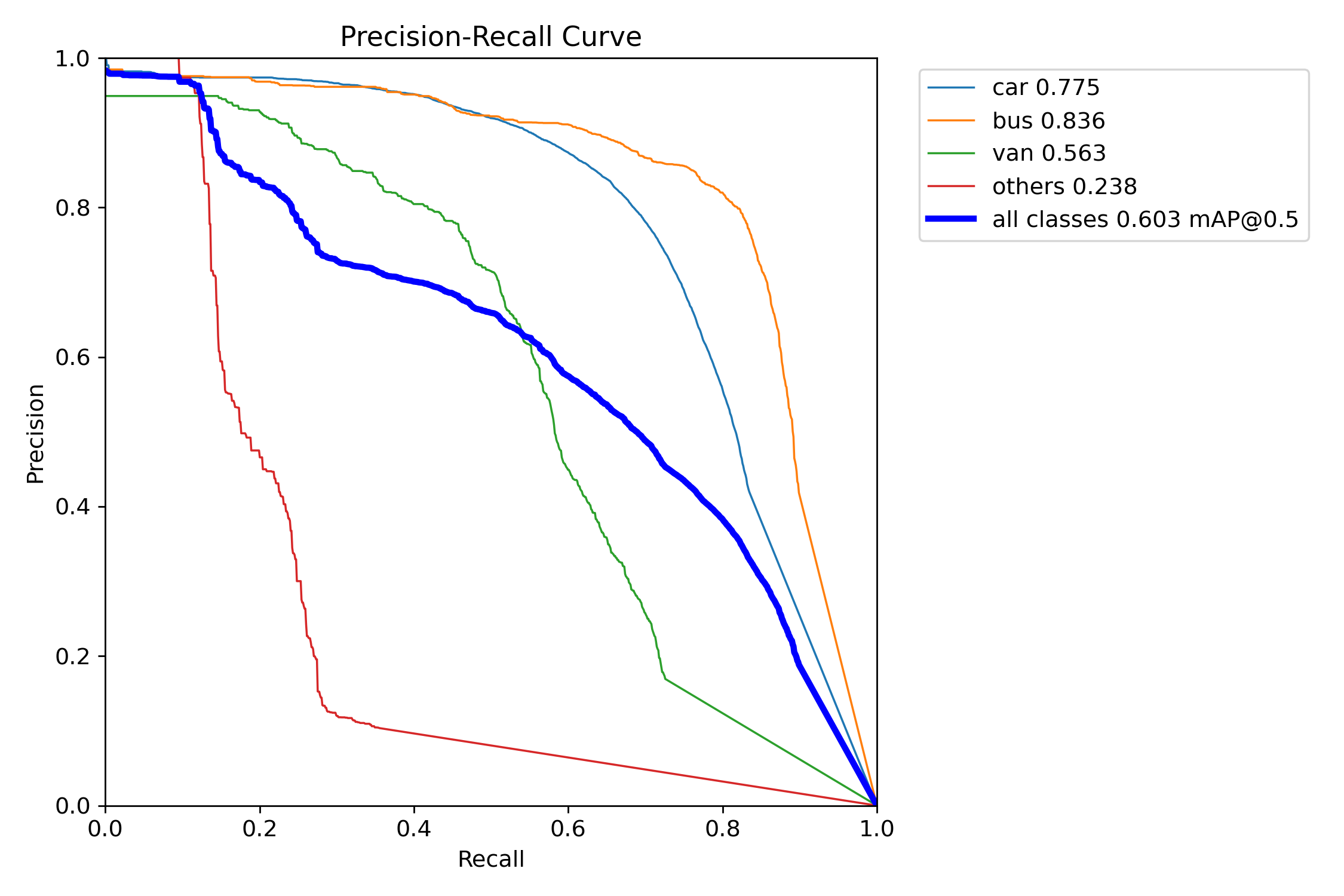
这里的这个指标是一个综合指标,用来衡量目标检测的综合性能,也是基于PR得到的。
首先是关于PR曲线的绘制。
PR曲线的绘制
-
模型预测输出
:
- 目标检测模型通常输出每个预测框的置信度分数(Confidence Score),表示模型对该预测的置信程度。
-
设置置信度阈值
:
- 从高到低调整置信度阈值。高置信度意味着更严格的标准(减少误检,但可能漏检),低置信度则更宽松(减少漏检,但可能增加误检)。
-
计算每个阈值下的 Precision 和 Recall
:
- 对每个阈值,根据 TP、FP 和 FN 的变化计算 Precision 和 Recall。
-
绘制曲线:
- 将不同阈值下的 Precision 和 Recall 作为点绘制,形成一条曲线。
PR曲线的特点:
- 横轴:Recall,范围 [0, 1]。
- 纵轴:Precision,范围 [0, 1]。
- PR曲线一般是单调递减的:随着召回率增加,精确率通常会降低,因为阈值变低会引入更多的误检。
有了单独每个类的PR曲线之后,我们就可以计算AP
平均精确率(AP, Average Precision)
PR曲线的面积(即积分值)被称为平均精确率(AP),它是目标检测的重要指标。
AP 的计算:
-
对 PR曲线下的面积进行积分,计算:
AP=∫01P® dRAP = \int_0^1 P® , dRAP=∫01P®dR
其中 P®P®P® 是精确率随召回率变化的函数。
-
通常用离散点近似计算(如 11 点插值法或更细化的点采样方法)。
AP 的意义:
- AP 的取值范围为 [0, 1],值越高,表示模型的检测性能越好。
- AP 反映了模型在不同阈值下的综合性能,而不仅仅关注单一的精确率或召回率。
将每个类的AP平均之后即可计算得到mAP
mAP(Mean Average Precision)
在目标检测中,通常需要检测多个类别,每个类别都有一个 AP 值。所有类别的平均值称为mAP:
mAP
=
1
N
∑
i
=
1
N
A
P
i
\text{mAP} = \frac{1}{N} \sum_{i=1}^N AP_i
mAP=N1i=1∑NAPi
其中 N是类别数,APi是第 i 类的平均精确率。
对于我们的案例而言,其中car的ap是77.5%,bus的是83.6,在IoU阈值为0.5的前提下,该模型所所有类上的map值为60.3%。
val_batchx_labels.jpg和val_batchx_pred.jpg
其中labels后缀的表示的是数据的真实标注,pred后缀的则表示模型的预测结果,通常你可以使用这两张图进行模型可视化效果的比较,看你的模型和真实结果相差多少,其中后面的小数表示的是置信度,也就是模型认为这里有多大的概率是一个目标。


模型速度
一般情况下, 我们还会去计算模型的速度,模型的速度在不同的硬件上表现出来的结果不一样,一般是直接使用模型的预测脚本对你的图像进行预测,预测之后每张图的时间会显示在下面,知道了推理一张图所有的时间,用1s的时间除以这个推理一张图所得到的数字就是FPS。

上面的指标表示,推理一张图像用时为16ms,前处理使用了3ms,推理是10ms,后处理是3ms。1s相当于是1000ms,1000/16≈63,所以这个模型在这个设备上的运行的fps就是63fps,电影的fps是25,所以这里已经足够实时。


















 4848
4848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











