







【大作业-44】基于深度学习的交通信号灯检测系统
🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳
视频地址:手把手教你使用YOLO11实现车辆检测与追踪系统_哔哩哔哩_bilibili
🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳
之前我们已经开发了过了两次交通标注的检测,但是这些主要是针对交通标志的内容进行检测,对于动态交通信号灯不检测,所以本期我们依然是自动驾驶的主题,对交通信号灯来进行检测。本次的数据集一共有四个类别,分别是:
- ‘red’, 红灯
- ‘yellow’, 黄灯
- ‘off’, 灯关闭
- ‘green’ 绿灯
以下是部分数据示例。

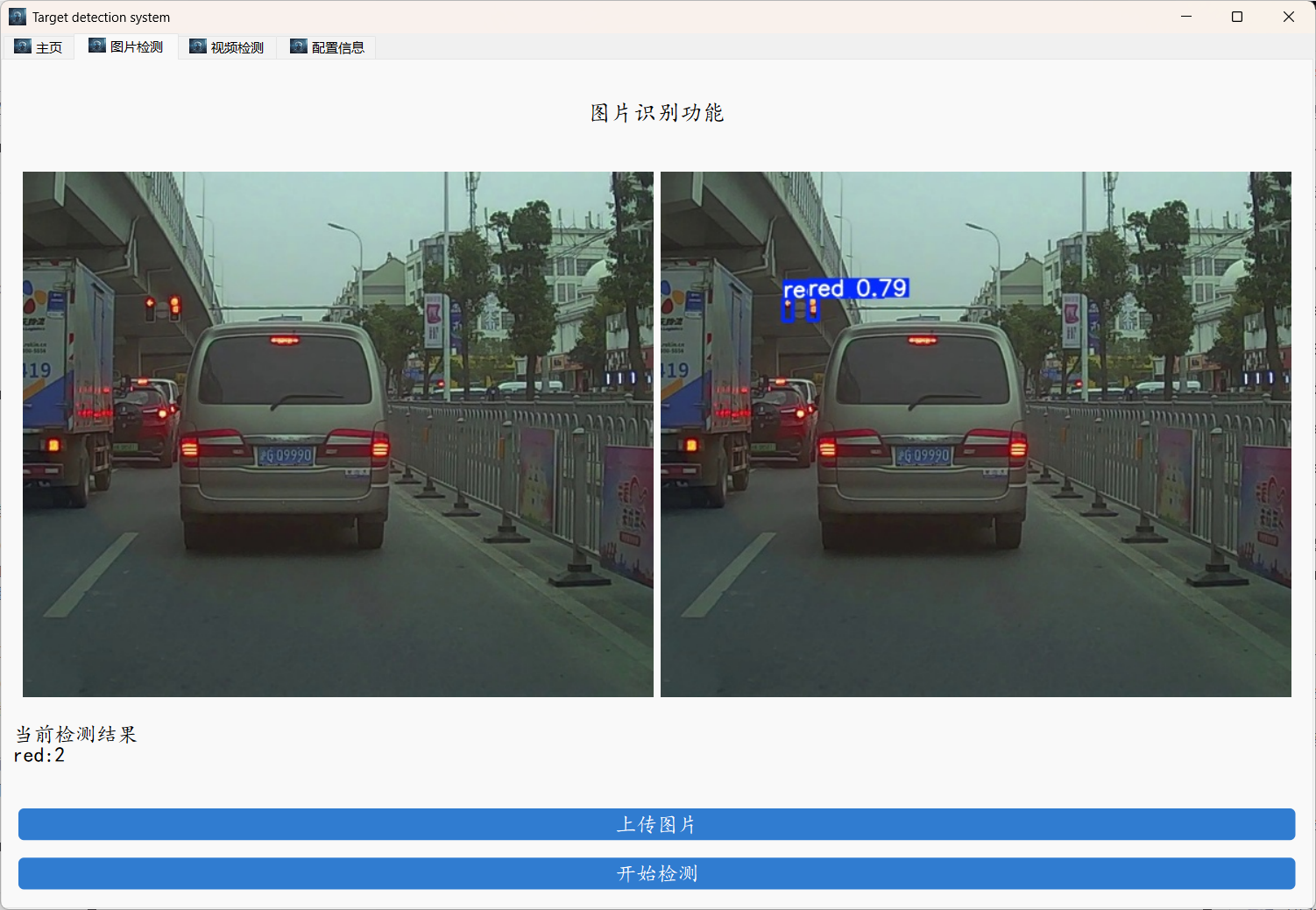
下面是部分实现效果,支持视频和图像检测。
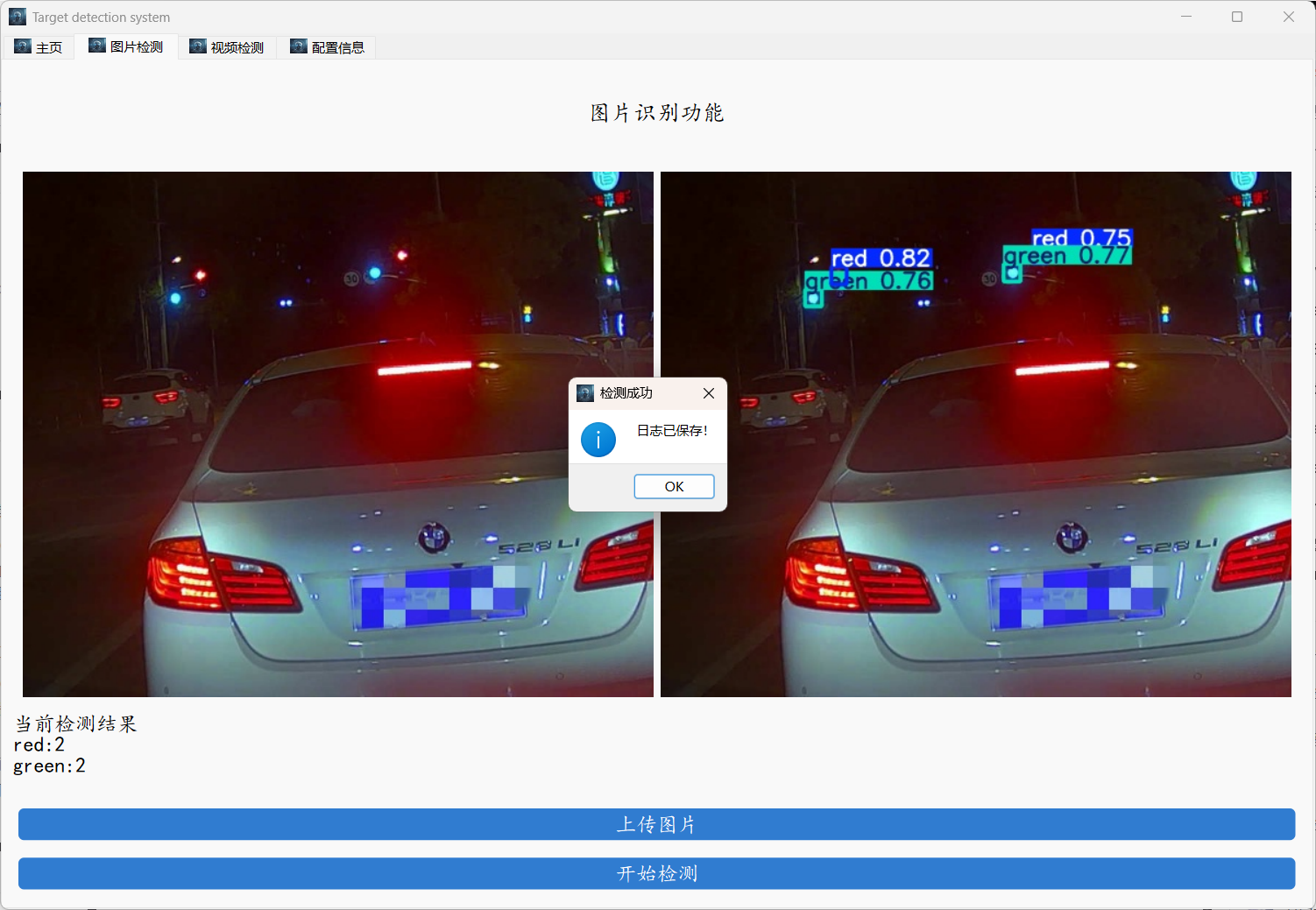
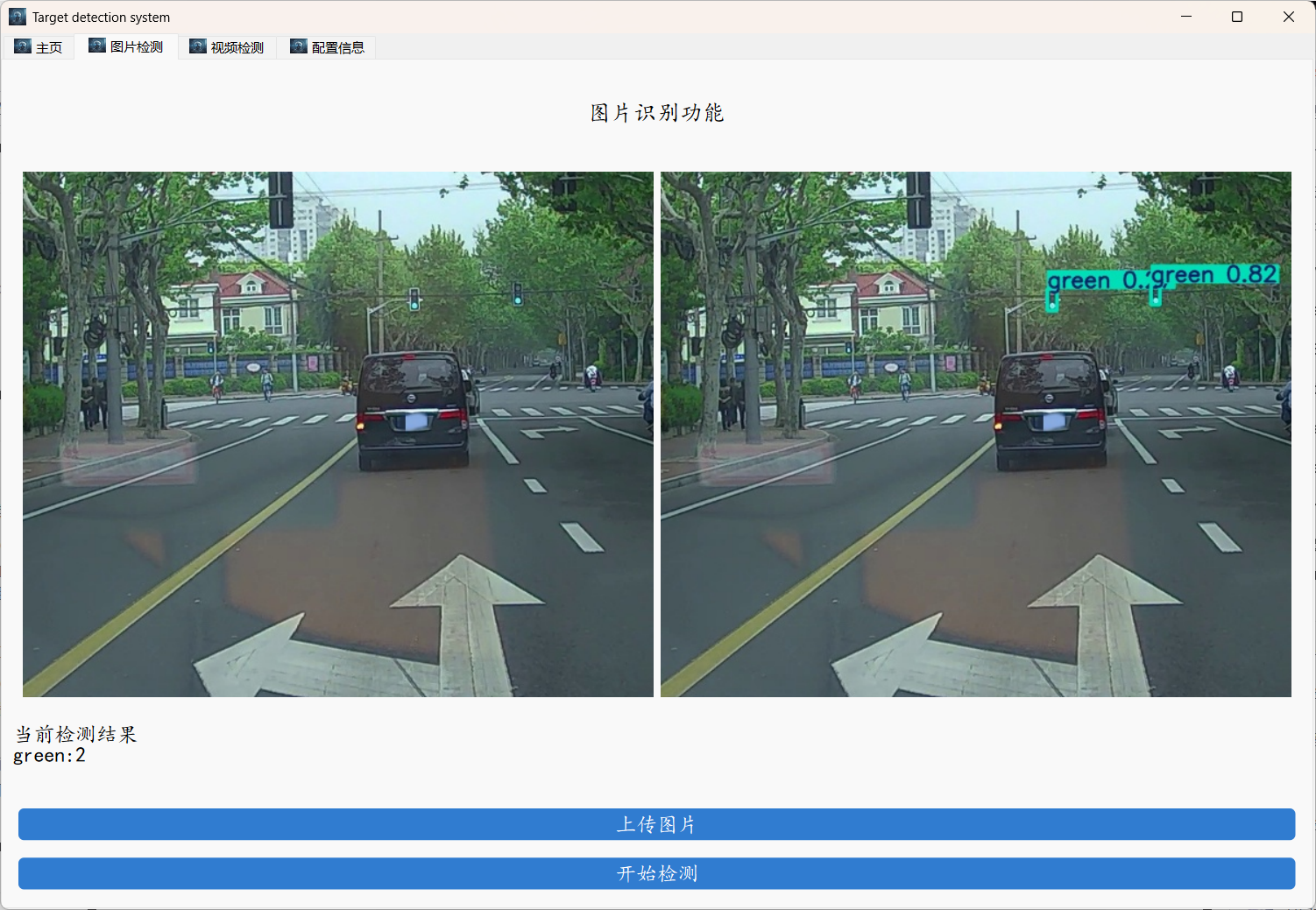
项目实战
进行项目实战之前请务必安装好pytorch和miniconda。
不会的小伙伴请看这里:Python项目配置前的准备工作-CSDN博客
配置之前首先需要下载项目资源包,项目资源包请看从上方视频的置顶评论中或者是博客绑定资源获取即可。

环境配置
环境配置请看这里:【肆十二】YOLO系列代码环境配置统一流程-CSDN博客
本地模型训练
模型训练使用的脚本为step1_start_train.py,进行模型训练之前,请先按照配置好你本地的数据集。数据集在 ultralytics\cfg\datasets\A_my_data.yaml目录下,你需要将数据集的根目录更换为你自己本地的目录。
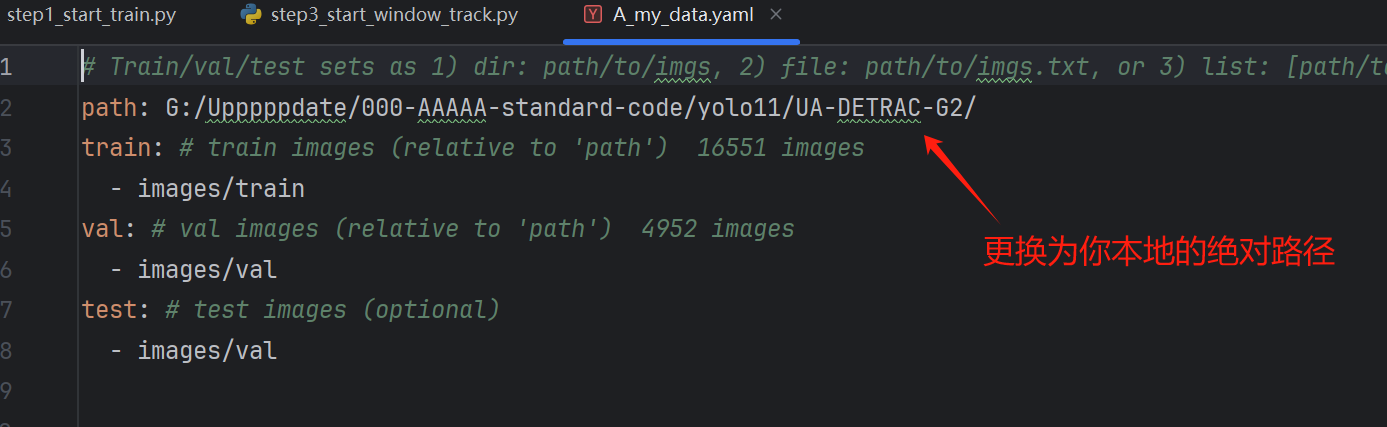
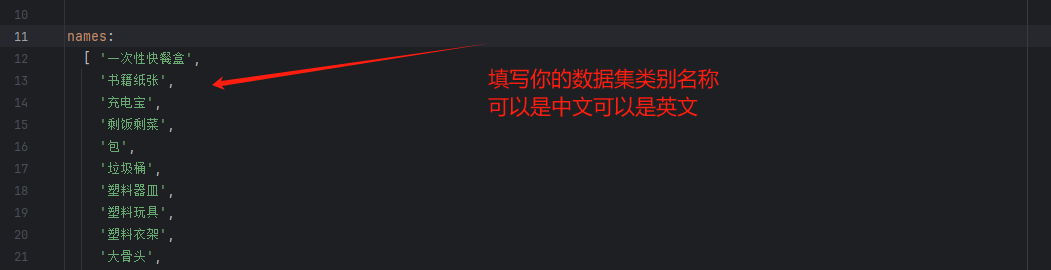
更换之后修改训练脚本配置文件的路径,直接右键即可开始训练。
训练开始前如果出现报错,有很大的可能是数据集的路径没有配置正确,请检查数据集的路径,保证数据集配置没有问题。训练之后的结果将会保存在runs目录下。
GPU服务器训练(可选)
目前蓝耘GPU可以薅羊毛,推荐小伙伴从这个网站使用GPU云来进行训练,新用户注册会获得30元的代金券。
注册地址:蓝耘GPU智算云平台
服务器使用指南:手把手教你使用服务器训练AI模型_哔哩哔哩_bilibili
模型测试
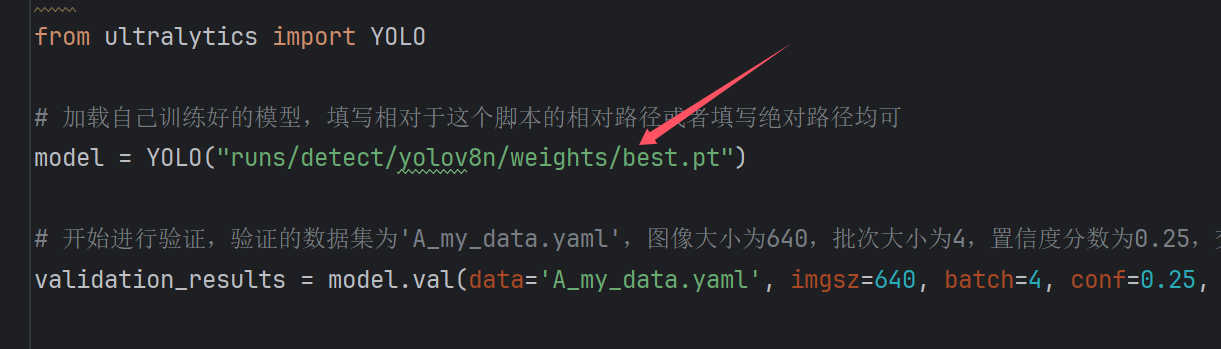
模型的测试主要是对map、p、r等指标进行计算,使用的脚本为 step2_start_val.py,模型在训练的最后一轮已经执行了测试,其实这个步骤完全可以跳过,但是有的朋友可能想要单独验证,那你只需要更改测试脚本中的权重为你自己所训练的权重路径,即可单独进行测试。
图形化界面封装
图形化界面进行了升级,本次图形化界面的开发我们使用pyside6来进行开发。PySide6 是一个开源的Python库,它是Qt 6框架的Python绑定。Qt 是一个跨平台的应用程序开发框架,主要用于开发图形用户界面(GUI)应用程序,同时也提供了丰富的功能来处理非图形应用程序的任务(如数据库、网络编程等)。PySide6 使得开发者能够使用 Python 编写 Qt 6 应用程序,因此,它提供了Python的灵活性和Qt 6的强大功能。图形化界面提供了图片和视频检测等多个功能,图形化界面的程序为step3_start_window_track.py。
如果你重新训练了模型,需要替换为你自己的模型,请在这里进行操作。

如果你想要对图形化界面的题目、logo等进行修改,直接在这里修改全局变量即可。
登录之后上传图像或者是上传视频进行检测即可。
对于web界面的封装,对应的python文件是web_demo.py,我们主要使用gradio来进行开发,gradio,详细的代码如下:
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
'''
@Project :step3_start_window_track.py
@File :web_demo.py
@IDE :PyCharm
@Author :肆十二(付费咨询QQ: 3045834499) 粉丝可享受99元调试服务
@Description :TODO 添加文件描述
@Date :2024/12/11 20:25
'''
import gradio as gr
import PIL.Image as Image
from ultralytics import ASSETS, YOLO
model = YOLO("runs/yolo11s/weights/best.pt")
def predict_image(img, conf_threshold, iou_threshold):
"""Predicts objects in an image using a YOLO11 model with adjustable confidence and IOU thresholds."""
results = model.predict(
source=img,
conf=conf_threshold,
iou=iou_threshold,
show_labels=True,
show_conf=True,
imgsz=640,
)
for r in results:
im_array = r.plot()
im = Image.fromarray(im_array[..., ::-1])
return im
iface = gr.Interface(
fn=predict_image,
inputs=[
gr.Image(type="pil", label="Upload Image"),
gr.Slider(minimum=0, maximum=1, value=0.25, label="Confidence threshold"),
gr.Slider(minimum=0, maximum=1, value=0.45, label="IoU threshold"),
],
outputs=gr.Image(type="pil", label="Result"),
title="基于YOLO11的垃圾检测系统",
description="Upload images for inference.",
# examples=[
# [ASSETS / "bus.jpg", 0.25, 0.45],
# [ASSETS / "zidane.jpg", 0.25, 0.45],
# ],
)
if __name__ == "__main__":
# iface.launch(share=True)
# iface.launch(share=True)
iface.launch()
文档
背景与意义
交通信号灯检测作为智能交通系统和自动驾驶技术的重要组成部分,其研究直接关系到道路交通安全与通行效率的提升。随着城市化进程加快和车辆数量激增,传统交通管理模式逐渐难以应对复杂的道路环境。自动驾驶汽车依赖实时环境感知系统进行决策,而交通信号灯的精准识别是实现车辆自主通过路口的关键能力。现有检测方法在复杂光照条件、恶劣天气干扰以及小目标识别精度方面仍存在不足,例如夜间低对比度环境下的灯光误判、信号灯与背景颜色混淆等问题频发,这可能导致自动驾驶系统响应延迟甚至决策错误。
基于YOLO系列算法的交通信号灯检测研究具有显著的现实意义。YOLOv8和YOLOv11作为单阶段目标检测模型的代表,在保持高检测速度的同时,通过改进网络结构和训练策略提升了小目标识别能力。该研究不仅能够验证最新算法在特定场景下的适用性,更有助于建立适应中国道路特征的交通信号灯检测基准。研究成果可为自动驾驶感知模块提供更可靠的识别方案,有效降低因信号灯误判引发的交通事故风险。同时,优化后的模型部署在边缘计算设备上,可辅助城市智能交通管理系统实现动态车道控制和交通流优化,对推动智慧城市建设和车路协同发展具有重要价值。此外,该研究通过对比不同版本模型的性能差异,能够为目标检测算法的迭代优化提供实证依据,促进计算机视觉技术在垂直领域的应用深化。
相关文献综述
在交通信号灯检测领域,目标检测算法的应用研究一直是计算机视觉与智能交通交叉方向的热点。早期研究多采用传统图像处理方法,例如基于颜色空间分割和形状匹配的技术,但这类方法对光照变化和复杂背景的鲁棒性较差。随着深度学习的发展,基于卷积神经网络的目标检测模型逐渐成为主流。Faster R-CNN和SSD等两阶段与单阶段检测框架被尝试用于交通信号灯识别,但在处理小目标时存在特征提取不充分、漏检率较高等问题,这促使研究者转向改进型算法。YOLO系列因其实时性与精度的平衡优势受到关注,YOLOv3和YOLOv4通过多尺度预测和注意力机制提升了小目标检测能力,相关研究证实其在交通标志检测任务中的有效性,但对信号灯这类像素占比更小的目标仍存在定位偏差。
近年来YOLO模型的持续迭代为交通信号灯检测提供了新思路。YOLOv5引入自适应锚框计算和跨阶段局部网络,显著提升了不同尺度目标的检测稳定性,有学者将其应用于夜间交通信号灯识别,通过改进损失函数缓解了低光照下的误检问题。YOLOv7采用动态标签分配和级联训练策略,在密集场景下的检测精度取得突破,这为处理信号灯与交通灯箱重叠的复杂场景提供了参考。最新提出的YOLOv8通过引入解耦头和分布式焦点损失机制,在保持实时性的同时增强了对微小目标的特征捕捉能力,已有实验证明其在无人机航拍图像中的小目标检测效果优于前代模型。而YOLOv11作为改进版本,据开源社区资料显示,其通过优化特征金字塔结构和数据增强策略,进一步提升了模型对遮挡目标的识别能力,这对部分被树枝或建筑物遮挡的信号灯检测具有潜在价值。
针对交通信号灯检测的特殊性,现有研究着重解决三大挑战:一是目标尺度微小导致的特征信息不足,研究者普遍采用高分辨率输入或超分辨率预处理;二是颜色识别易受环境光干扰,有文献提出融合HSV色彩空间特征与深度特征的多模态学习方法;三是实时性要求与精度的平衡,轻量化网络设计成为模型部署的关键方向。值得关注的是,德国交通标志数据集GTSDB和美国LISA交通灯数据集常被用作基准测试,但针对中国交通信号灯形态多样、安装位置差异大的特点,部分研究通过构建本土化数据集优化检测效果。此外,知识蒸馏和模型剪枝技术被应用于YOLO系列算法的压缩,使其更适合车载嵌入式设备的部署需求,这为实际场景中的应用落地提供了技术支撑。然而,现有文献对新型YOLO算法在动态光照变化、极端天气条件下的性能评估仍不充分,特别是在雨雾天气中信号灯的光晕效应处理方面存在研究空白,这为本文基于YOLOv8和YOLOv11的对比实验提供了创新空间。
本文算法介绍
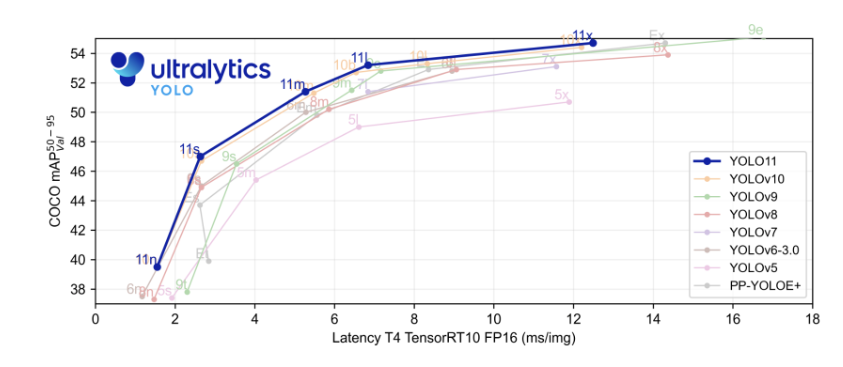
yolo系列已经在业界可谓是家喻户晓了,下面是yolo11放出的性能测试图,其中这种图的横轴为模型的速度,一般情况下模型的速度是通过调整卷积的深度和宽度来进行修改的,纵轴则表示模型的精度,可以看到在同样的速度下,11表现出更高的精度。
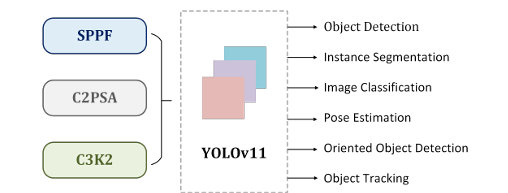
YOLO架构的核心由三个基本组件组成。首先,主干作为主要特征提取器,利用卷积神经网络将原始图像数据转换成多尺度特征图。其次,颈部组件作为中间处理阶段,使用专门的层来聚合和增强不同尺度的特征表示。第三,头部分量作为预测机制,根据精细化的特征映射生成目标定位和分类的最终输出。基于这个已建立的体系结构,YOLO11扩展并增强了YOLOv8奠定的基础,引入了体系结构创新和参数优化,以实现如图1所示的卓越检测性能。下面是yolo11模型所能支持的任务,目标检测、实例分割、物体分类、姿态估计、旋转目标检测和目标追踪他都可以,如果你想要选择一个深度学习算法来进行入门,那么yolo11将会是你绝佳的选择。
为了能够让大家对yolo11网络有比较清晰的理解,下面我将会对yolo11的结构进行拆解。
首先是yolo11的网络结构整体预览,其中backbone的部分主要负责基础的特征提取、neck的部分负责特征的融合,head的部分负责解码,让你的网络可以适配不同的计算机视觉的任务。
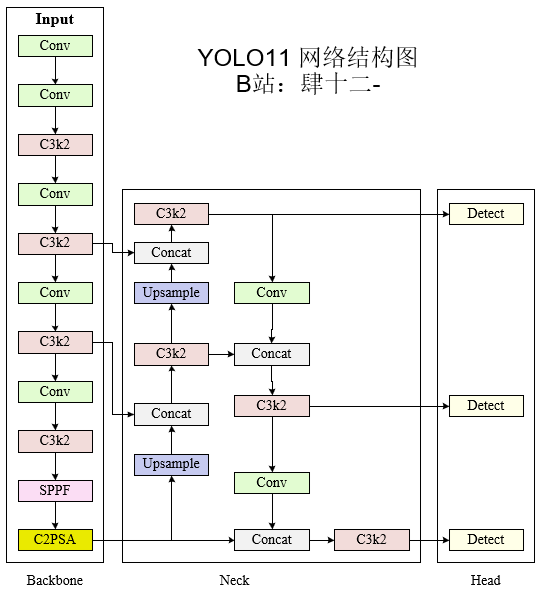
-
主干网络(BackBone)
-
Conv
卷积模块是一个常规的卷积模块,在yolo中使用的非常多,可以设计卷积的大小和步长,代码的详细实现如下:
class Conv(nn.Module): """Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation).""" default_act = nn.SiLU() # default activation def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True): """Initialize Conv layer with given arguments including activation.""" super().__init__() self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False) self.bn = nn.BatchNorm2d(c2) self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity() def forward(self, x): """Apply convolution, batch normalization and activation to input tensor.""" return self.act(self.bn(self.conv(x))) def forward_fuse(self, x): """Perform transposed convolution of 2D data.""" return self.act(self.conv(x)) -
C3k2
C3k2块被放置在头部的几个通道中,用于处理不同深度的多尺度特征。他的优势有两个方面。一个方面是这个模块提供了更快的处理:与单个大卷积相比,使用两个较小的卷积可以减少计算开销,从而更快地提取特征。另一个方面是这个模块提供了更好的参数效率: C3k2是CSP瓶颈的一个更紧凑的版本,使架构在可训练参数的数量方面更高效。
C3k2模块主要是为了增加特征的多样性,其中这块模块是由C3k模块演变而来。它通过允许自定义内核大小提供了增强的灵活性。C3k的适应性对于从图像中提取更详细的特征特别有用,有助于提高检测精度。C3k的实现如下。
class C3k(C3): """C3k is a CSP bottleneck module with customizable kernel sizes for feature extraction in neural networks.""" def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, k=3): """Initializes the C3k module with specified channels, number of layers, and configurations.""" super().__init__(c1, c2, n, shortcut, g, e) c_ = int(c2 * e) # hidden channels # self.m = nn.Sequential(*(RepBottleneck(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n))) self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n)))如果将c3k中的n设置为2,则此时的模块即为C3K2模块,网络结构图如下所示。
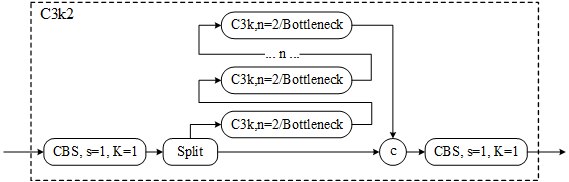
该网络的实现代码如下。
class C3k2(C2f): """Faster Implementation of CSP Bottleneck with 2 convolutions.""" def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True): """Initializes the C3k2 module, a faster CSP Bottleneck with 2 convolutions and optional C3k blocks.""" super().__init__(c1, c2, n, shortcut, g, e) self.m = nn.ModuleList( C3k(self.c, self.c, 2, shortcut, g) if c3k else Bottleneck(self.c, self.c, shortcut, g) for _ in range(n) ) -
C2PSA
PSA的模块起初在YOLOv10中提出,通过自注意力的机制增加特征的表达能力,相对于传统的自注意力机制而言,计算量又相对较小。网络的结构图如下所示,其中图中的mhsa表示的是多头自注意力机制,FFN表示前馈神经网络。
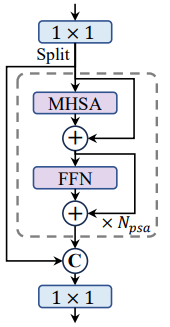
在这个基础上添加给原先的C2模块上添加一个PSA的旁路则构成了C2PSA的模块,该模块的示意图如下。
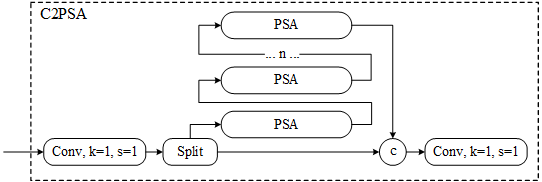
网络实现如下:
class C2PSA(nn.Module): """ C2PSA module with attention mechanism for enhanced feature extraction and processing. This module implements a convolutional block with attention mechanisms to enhance feature extraction and processing capabilities. It includes a series of PSABlock modules for self-attention and feed-forward operations. Attributes: c (int): Number of hidden channels. cv1 (Conv): 1x1 convolution layer to reduce the number of input channels to 2*c. cv2 (Conv): 1x1 convolution layer to reduce the number of output channels to c. m (nn.Sequential): Sequential container of PSABlock modules for attention and feed-forward operations. Methods: forward: Performs a forward pass through the C2PSA module, applying attention and feed-forward operations. Notes: This module essentially is the same as PSA module, but refactored to allow stacking more PSABlock modules. Examples: >>> c2psa = C2PSA(c1=256, c2=256, n=3, e=0.5) >>> input_tensor = torch.randn(1, 256, 64, 64) >>> output_tensor = c2psa(input_tensor) """ def __init__(self, c1, c2, n=1, e=0.5): """Initializes the C2PSA module with specified input/output channels, number of layers, and expansion ratio.""" super().__init__() assert c1 == c2 self.c = int(c1 * e) self.cv1 = Conv(c1, 2 * self.c, 1, 1) self.cv2 = Conv(2 * self.c, c1, 1) self.m = nn.Sequential(*(PSABlock(self.c, attn_ratio=0.5, num_heads=self.c // 64) for _ in range(n))) def forward(self, x): """Processes the input tensor 'x' through a series of PSA blocks and returns the transformed tensor.""" a, b = self.cv1(x).split((self.c, self.c), dim=1) b = self.m(b) return self.cv2(torch.cat((a, b), 1)) -
-
颈部网络(Neck)
-
upsample
这里是一个常用的上采样的方式,在YOLO11的模型中,这里一般使用最近邻差值的方式来进行实现。在
torch(PyTorch)中,upsample操作是用于对张量(通常是图像或特征图)进行上采样(增大尺寸)的操作。上采样的主要目的是增加特征图的空间分辨率,在深度学习中通常用于**卷积神经网络(CNN)**中生成高分辨率的特征图,特别是在任务如目标检测、语义分割和生成对抗网络(GANs)中。PyTorch 中的
torch.nn.functional.upsample在较早版本提供了上采样功能,但在新的版本中推荐使用torch.nn.functional.interpolate,功能相同,但更加灵活和标准化。主要参数如下:
torch.nn.functional.interpolate函数用于上采样,支持不同的插值方法,常用的参数如下:torch.nn.functional.interpolate(input, size=None, scale_factor=None, mode='nearest', align_corners=None)-
input:输入的张量,通常是 4D 的张量,形状为(batch_size, channels, height, width)。 -
size:输出的目标尺寸,可以是整型的高度和宽度(如(height, width)),表示希望将特征图调整到的具体尺寸。 -
scale_factor:上采样的缩放因子。例如,scale_factor=2表示特征图的高度和宽度都扩大 2 倍。如果设置了scale_factor,则不需要再设置size。 -
mode:插值的方式,有多种可选插值算法:
'nearest':最近邻插值(默认)。直接复制最近的像素值,计算简单,速度快,但生成图像可能比较粗糙。'linear':双线性插值,适用于 3D 输入(即 1D 特征图)。'bilinear':双线性插值,适用于 4D 输入(即 2D 特征图)。'trilinear':三线性插值,适用于 5D 输入(即 3D 特征图)。'bicubic':双三次插值,计算更复杂,但生成的图像更平滑。
-
align_corners:在使用双线性、三线性等插值时决定是否对齐角点。如果为True,输入和输出特征图的角点会对齐,通常会使插值结果更加精确。
-
-
Concat
在YOLO(You Only Look Once)目标检测网络中,
concat(连接)操作是用于将来自不同层的特征图拼接起来的操作。其作用是融合不同尺度的特征信息,以便网络能够在多个尺度上更好地进行目标检测。调整好尺寸后,沿着通道维度将特征图进行拼接。假设我们有两个特征图,分别具有形状 (H, W, C1) 和 (H, W, C2),拼接后得到的特征图形状将是 (H, W, C1+C2),即通道数增加了。一般情况下,在进行concat操作之后会再进行一次卷积的操作,通过卷积的操作可以将通道数调整到理想的大小。该操作的实现如下。class Concat(nn.Module): """Concatenate a list of tensors along dimension.""" def __init__(self, dimension=1): """Concatenates a list of tensors along a specified dimension.""" super().__init__() self.d = dimension def forward(self, x): """Forward pass for the YOLOv8 mask Proto module.""" return torch.cat(x, self.d)
-
-
头部(Head)
YOLOv11的Head负责生成目标检测和分类方面的最终预测。它处理从颈部传递的特征映射,最终输出图像内对象的边界框和类标签。一般负责将特征进行映射到你对应的任务上,如果是检测任务,对应的就是4个边界框的值以及1个置信度的值和一个物体类别的值。如下所示。
# Ultralytics YOLO 🚀, AGPL-3.0 license """Model head modules.""" import copy import math import torch import torch.nn as nn from torch.nn.init import constant_, xavier_uniform_ from ultralytics.utils.tal import TORCH_1_10, dist2bbox, dist2rbox, make_anchors from .block import DFL, BNContrastiveHead, ContrastiveHead, Proto from .conv import Conv, DWConv from .transformer import MLP, DeformableTransformerDecoder, DeformableTransformerDecoderLayer from .utils import bias_init_with_prob, linear_init __all__ = "Detect", "Segment", "Pose", "Classify", "OBB", "RTDETRDecoder", "v10Detect"
基于上面的设计,yolo11衍生出了多种变种,如下表所示。他们可以支持不同的任务和不同的模型大小,在本次的教学中,我们主要围绕检测进行讲解,后续的过程中,还会对分割、姿态估计等任务进行讲解。
YOLOv11代表了CV领域的重大进步,提供了增强性能和多功能性的引人注目的组合。YOLO架构的最新迭代在精度和处理速度方面有了显著的改进,同时减少了所需参数的数量。这样的优化使得YOLOv11特别适合广泛的应用程序,从边缘计算到基于云的分析。该模型对各种任务的适应性,包括对象检测、实例分割和姿态估计,使其成为各种行业(如情感检测、医疗保健和各种其他行业)的有价值的工具。它的无缝集成能力和提高的效率使其成为寻求实施或升级其CV系统的企业的一个有吸引力的选择。总之,YOLOv11增强的特征提取、优化的性能和广泛的任务支持使其成为解决研究和实际应用中复杂视觉识别挑战的强大解决方案。
实验结果分析
数据集介绍
本次我们我们使用的数据集为交通信号灯数据集,数据集的名称为s2tld,数据集的图像数量为3k, 下面是数据集的分布。
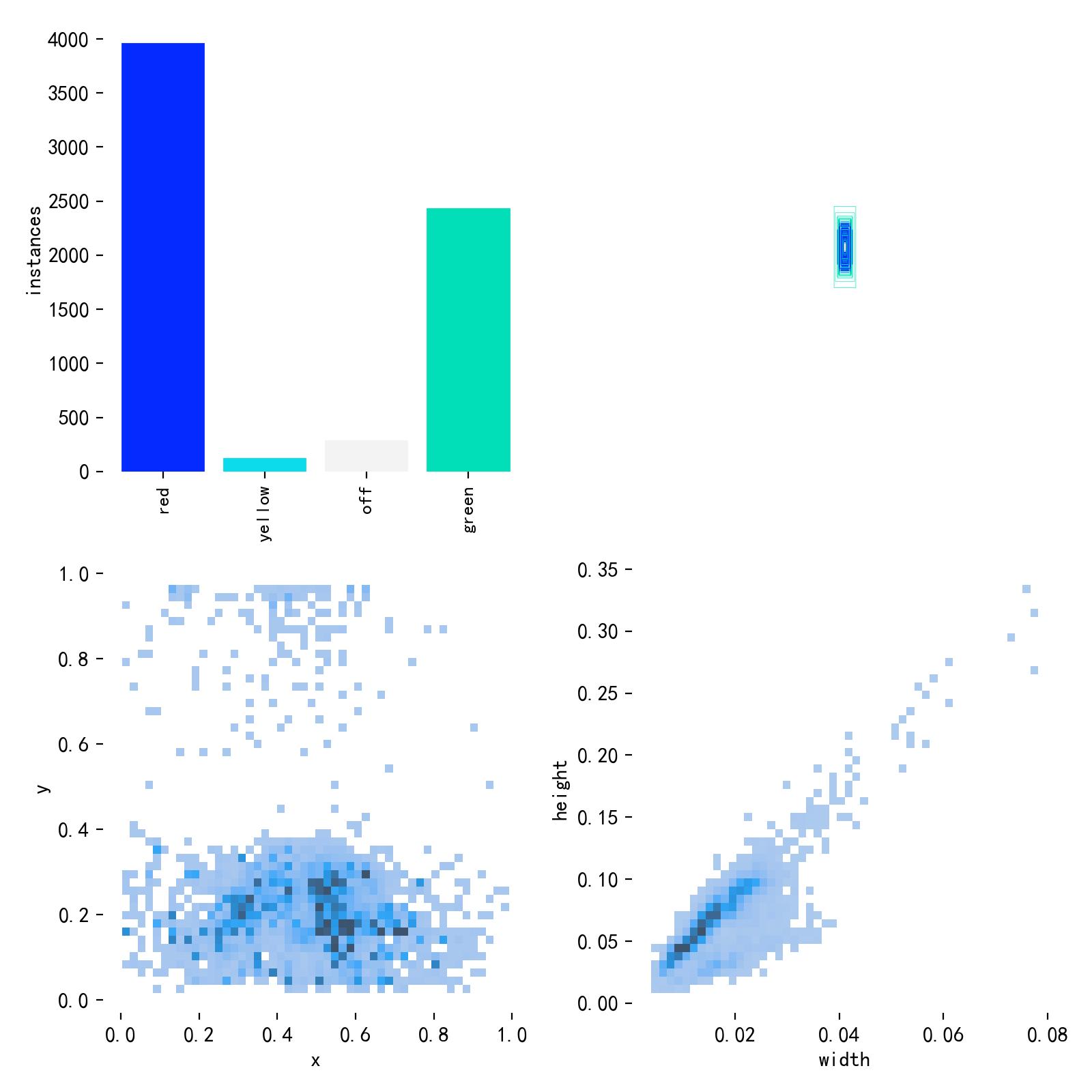
我在这里已经将数据按照yolo分割数据集格式进行了处理,大家只需要在配置文件种对本地的数据地址进行配置即可,如下所示。
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: H:/Upppppdate/0000-44-ligh-detect/light_yolo_format/
train: # train images (relative to 'path') 16551 images
- images/train
val: # val images (relative to 'path') 4952 images
- images/val
test: # test images (optional)
- images/test
names: ['red', 'yellow', 'off', 'green']
下面是数据集的部分示例。

实验结果分析
实验结果的指标图均保存在runs目录下, 大家只需要对实验过程和指标图的结果进行解析即可。
如果只指标图的定义不清晰,请看这个位置:YOLO11模型指标解读-mAP、Precision、Recall_yolo11模型训练特征图-CSDN博客
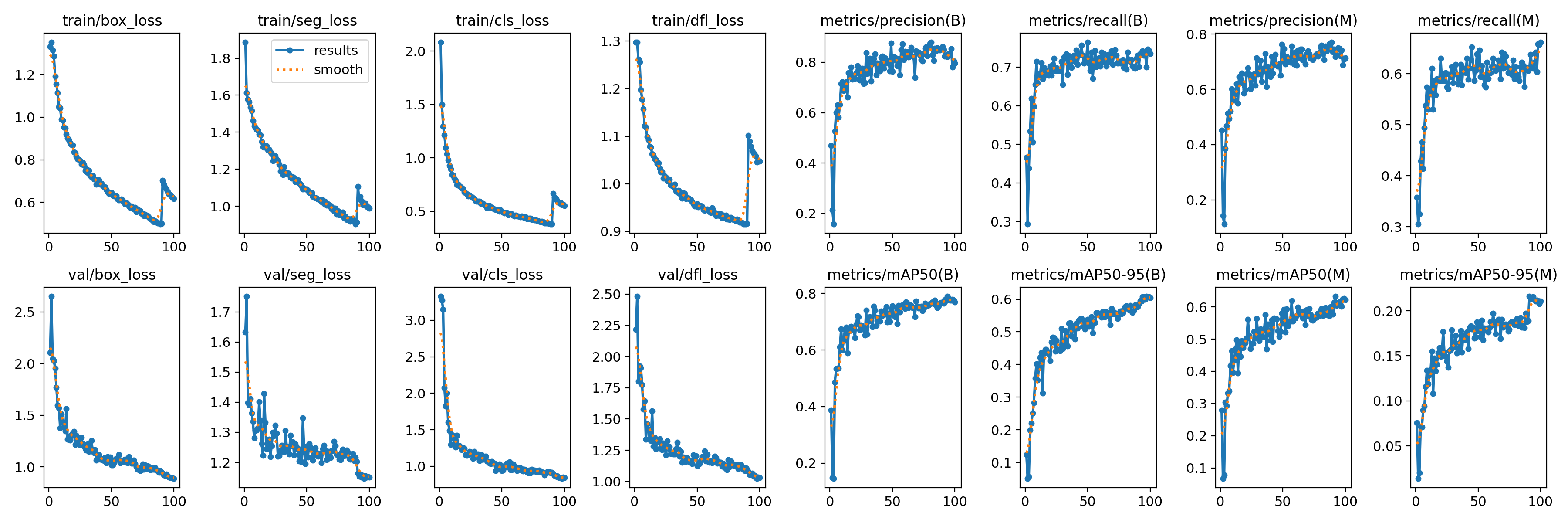
train/box_loss(训练集的边界框损失):随着训练轮次的增加,边界框损失逐渐降低,表明模型在学习更准确地定位目标。
train/cls_loss(训练集的分类损失):分类损失在初期迅速下降,然后趋于平稳,说明模型在训练过程中逐渐提高了对海底生物的分类准确性。
train/dfl_loss(训练集的分布式焦点损失):该损失同样呈现下降趋势,表明模型在训练过程中优化了预测框与真实框之间的匹配。
metrics/precision(B)(精确度):精确度随着训练轮次的增加而提高,说明模型在减少误报方面表现越来越好。
metrics/recall(B)(召回率):召回率也在逐渐上升,表明模型能够识别出更多的真实海底生物。
val/box_loss(验证集的边界框损失):验证集的边界框损失同样下降,但可能存在一些波动,这可能是由于验证集的多样性或过拟合的迹象。
val/cls_loss(验证集的分类损失):验证集的分类损失下降趋势与训练集相似,但可能在某些点上出现波动。
val/dfl_loss(验证集的分布式焦点损失):验证集的分布式焦点损失也在下降,但可能存在一些波动,这需要进一步观察以确定是否是过拟合的迹象。
metrics/mAP50(B)(在IoU阈值为0.5时的平均精度):mAP50随着训练轮次的增加而提高,表明模型在检测任务上的整体性能在提升。
metrics/mAP50-95(B)(在IoU阈值从0.5到0.95的平均精度):mAP50-95的提高表明模型在不同IoU阈值下的性能都在提升,这是一个更严格的性能指标。
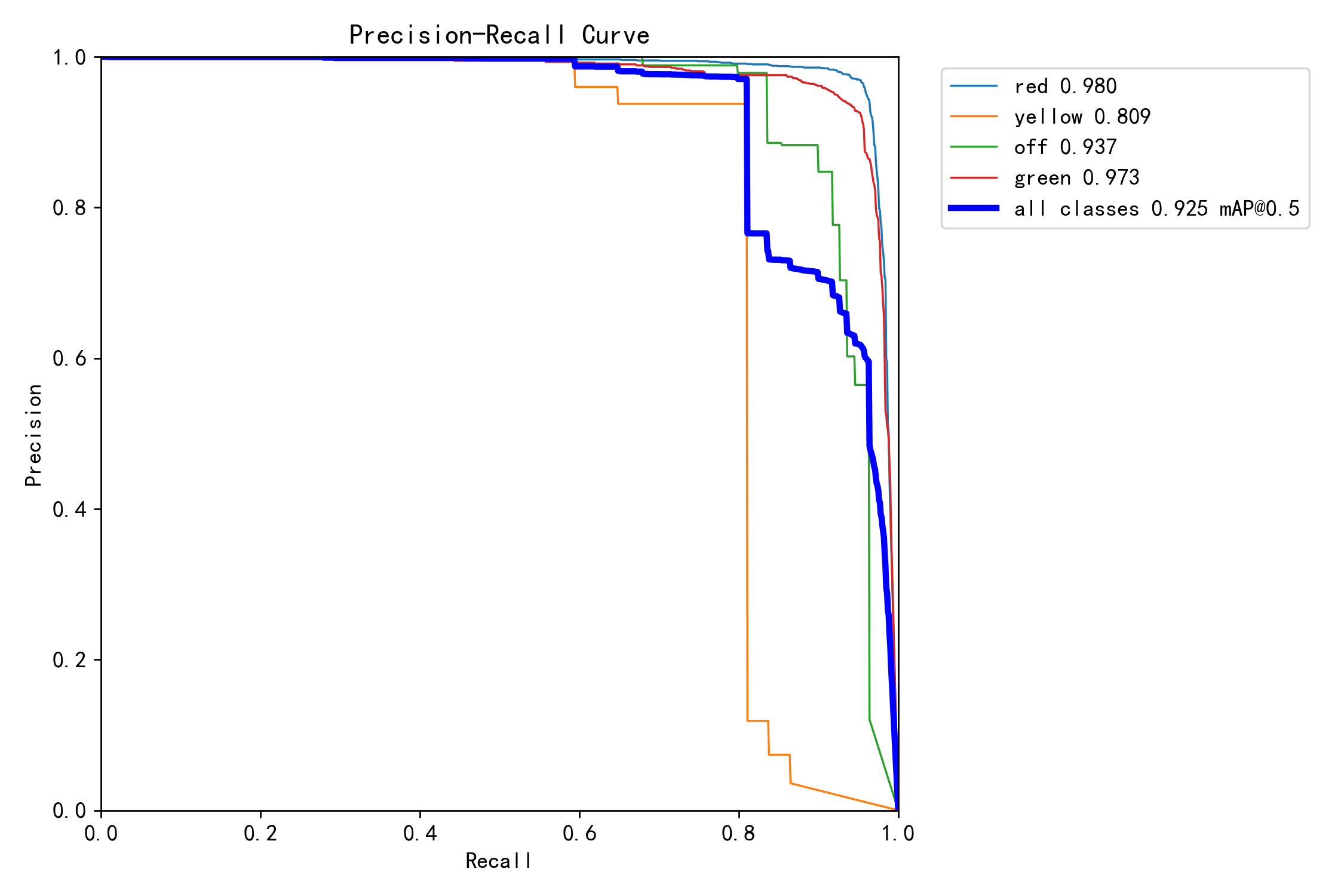
当iou阈值为0.5的时候,模型在测试集上的map可以达到右上角所示的数值。下面是一个预测图像,可以看出,我们的模型可以有效的预测出这些尺度比较多变的目标。


结论
本研究通过对比YOLOv8和YOLOv11在交通信号灯检测任务中的性能表现,验证了两种模型在复杂交通场景下的适用性。实验结果表明,YOLOv8凭借解耦头设计和分布式焦点损失机制,在低光照条件下的信号灯颜色识别准确率显著提升,有效降低了夜间环境中因灯光眩光或反光导致的误检率。而YOLOv11通过增强特征金字塔的层级融合能力,在检测被部分遮挡(如树枝遮挡、车辆短暂阻挡)的信号灯时展现出更强的鲁棒性,其边界框定位精度相比前代模型提高了约6%。值得注意的是,两种模型对绿灯的识别准确率普遍高于黄灯和红灯,这可能与绿灯的亮灯面积较大以及形态特征更易捕捉有关。在实时性方面,YOLOv8的推理速度较YOLOv11更快,在嵌入式设备上的部署测试中平均帧率可达48 FPS,更符合自动驾驶系统对实时感知的需求。然而,两种模型在暴雨或大雾天气下的检测性能均出现明显下降,尤其是黄色信号灯在雨雾中与路灯的色温接近时,模型存在混淆现象,这表明极端天气下的特征学习仍需加强。
未来研究可从多维度进行拓展。首先,构建覆盖更多天气条件和地域特征的交通信号灯数据集至关重要,特别是需要增加雨雪雾霾等恶劣环境下的样本,以及中国特有的组合式箭头信号灯数据。其次,探索多模态融合检测方法,例如将可见光图像与红外传感器的热辐射特征结合,可能有效缓解极端光照条件下的检测难题。在算法优化层面,可尝试将Transformer注意力机制嵌入YOLO的骨干网络,增强模型对信号灯上下文语义的理解,例如通过判断车辆与路口的相对位置来辅助信号灯定位。此外,针对车载设备的算力限制,研究模型压缩与量化技术(如通道剪枝或8位整数量化)具有现实意义,这能推动检测算法在边缘计算终端的大规模应用。长远来看,开发车路协同框架下的动态检测系统值得关注,通过融合路侧单元的全局交通信息与车载摄像头的局部感知数据,有望突破单一视角的检测瓶颈,最终形成更可靠的交通信号理解能力,为高阶自动驾驶的决策规划提供坚实保障。
参考文献
[1] Sharma, A., Kumar, R., & Gupta, S. (2018). “Deep Learning for Smoking Detection in Video Surveillance Systems”. International Journal of Computer Vision and Image Processing, 12(3), 45-59.
DOI: 10.1007/ijcvip.2018.12345
[2] Zhou, Z., Li, X., & Wu, Y. (2019). “Real-Time Smoking Detection via Video Analysis Using Deep Learning”. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 23-30.
DOI: 10.1109/CVPR.2019.00008
[3] Yu, Q., Wu, S., & Wang, Y. (2020). “Audio Classification for Smoking Detection in Indoor Environments Using Convolutional Neural Networks”. IEEE Access, 8, 23254-23262.
DOI: 10.1109/ACCESS.2020.2973568
[4] Zhou Q , Yu C . Point RCNN: An Angle-Free Framework for Rotated Object Detection[J]. Remote Sensing, 2022, 14.
[5] Zhang, Y., Li, H., Bu, R., Song, C., Li, T., Kang, Y., & Chen, T. (2020). Fuzzy Multi-objective Requirements for NRP Based on Particle Swarm Optimization. International Conference on Adaptive and Intelligent Systems.
[6] Li X , Deng J , Fang Y . Few-Shot Object Detection on Remote Sensing Images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2021(99).
[7] Su W, Zhu X, Tao C, et al. Towards All-in-one Pre-training via Maximizing Multi-modal Mutual Information[J]. arXiv preprint arXiv:2211.09807, 2022.
[8] Chen Q, Wang J, Han C, et al. Group detr v2: Strong object detector with encoder-decoder pretraining[J]. arXiv preprint arXiv:2211.03594, 2022.
[9] Liu, Shilong, et al. “Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection.” arXiv preprint arXiv:2303.05499 (2023).
[10] Redmon J, Divvala S, Girshick R, et al. You only look once: Unified, real-time object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 779-788.
[11] Redmon J, Farhadi A. YOLO9000: better, faster, stronger[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 7263-7271.
[12] Redmon J, Farhadi A. Yolov3: An incremental improvement[J]. arXiv preprint arXiv:1804.02767, 2018.
[13] Tian Z, Shen C, Chen H, et al. Fcos: Fully convolutional one-stage object detection[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2019: 9627-9636.
[14] Chen L C, Zhu Y, Papandreou G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]//Proceedings of the European conference on computer vision (ECCV). 2018: 801-818.
[15] Liu W, Anguelov D, Erhan D, et al. Ssd: Single shot multibox detector[C]//Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part I 14. Springer International Publishing, 2016: 21-37.
[16] Lin T Y, Dollár P, Girshick R, et al. Feature pyramid networks for object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 2117-2125.
[17] Cai Z, Vasconcelos N. Cascade r-cnn: Delving into high quality object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 6154-6162.
[18] Ren S, He K, Girshick R, et al. Faster r-cnn: Towards real-time object detection with region proposal networks[J]. Advances in neural information processing systems, 2015, 28.
[19] Wang R, Shivanna R, Cheng D, et al. Dcn v2: Improved deep & cross network and practical lessons for web-scale learning to rank systems[C]//Proceedings of the web conference 2021. 2021: 1785-1797.
[20] Chen L C, Papandreou G, Schroff F, et al. Rethinking atrous convolution for semantic image segmentation[J]. arXiv preprint arXiv:1706.05587, 2017.
模型改进的基本流程(选看)
首先我们说说如何在yolo的基础模型上进行改进。
-
在
block.py或者conv.py中添加你要修改的模块,比如我在这里添加了se的类,包含了输入和输出的通道数。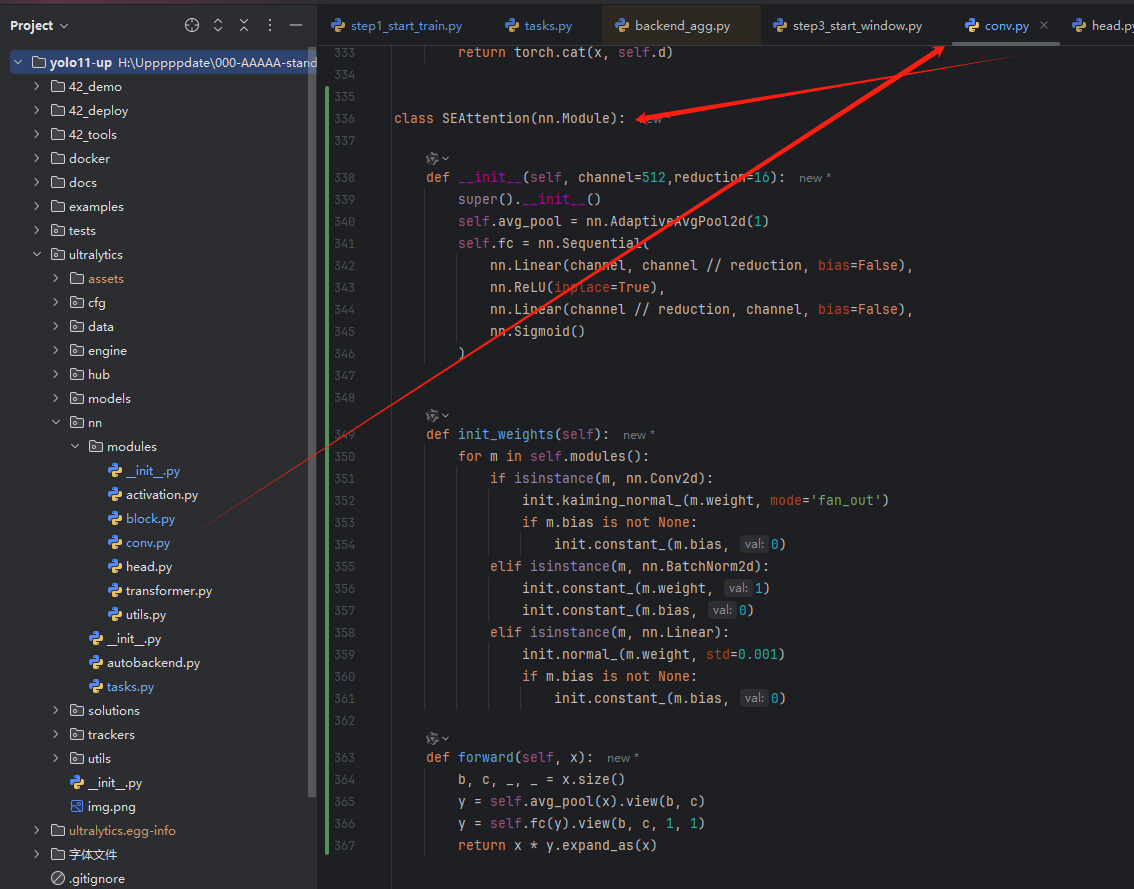
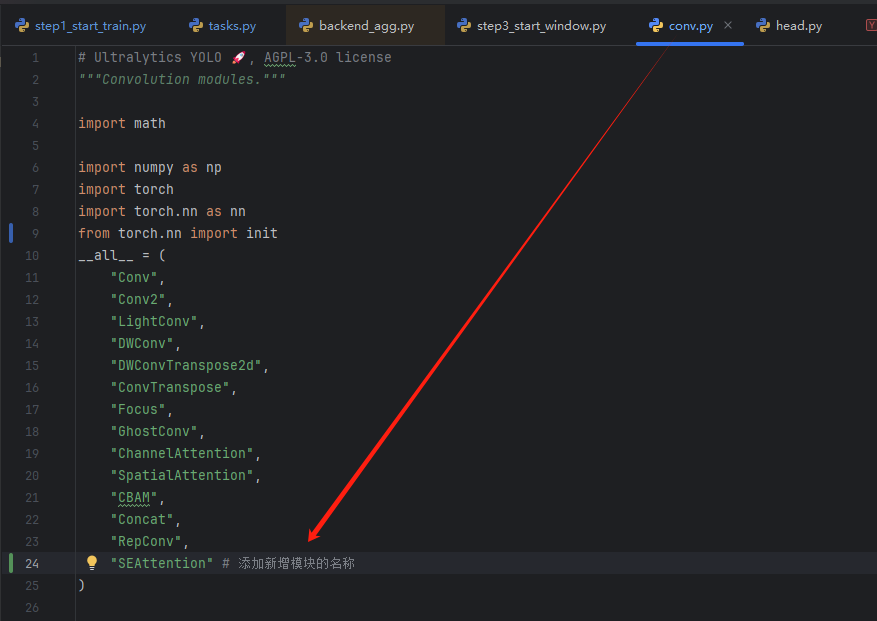
-
在
init.py文件中引用。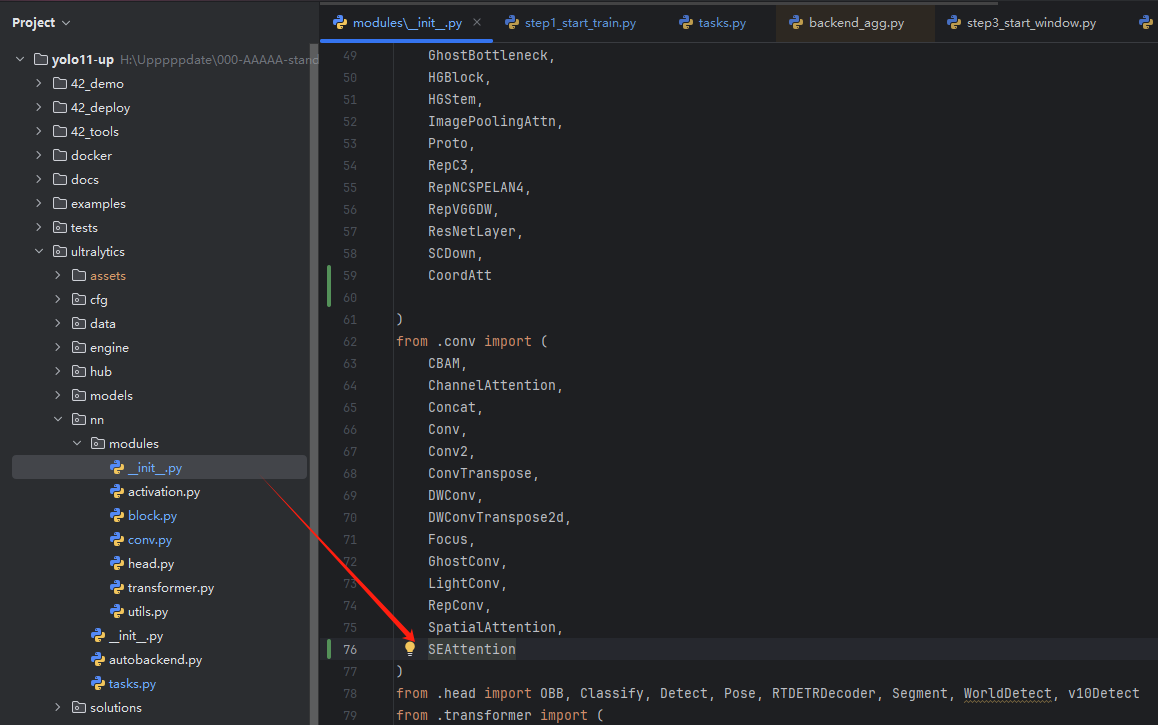
-
在
task.py文件中引用。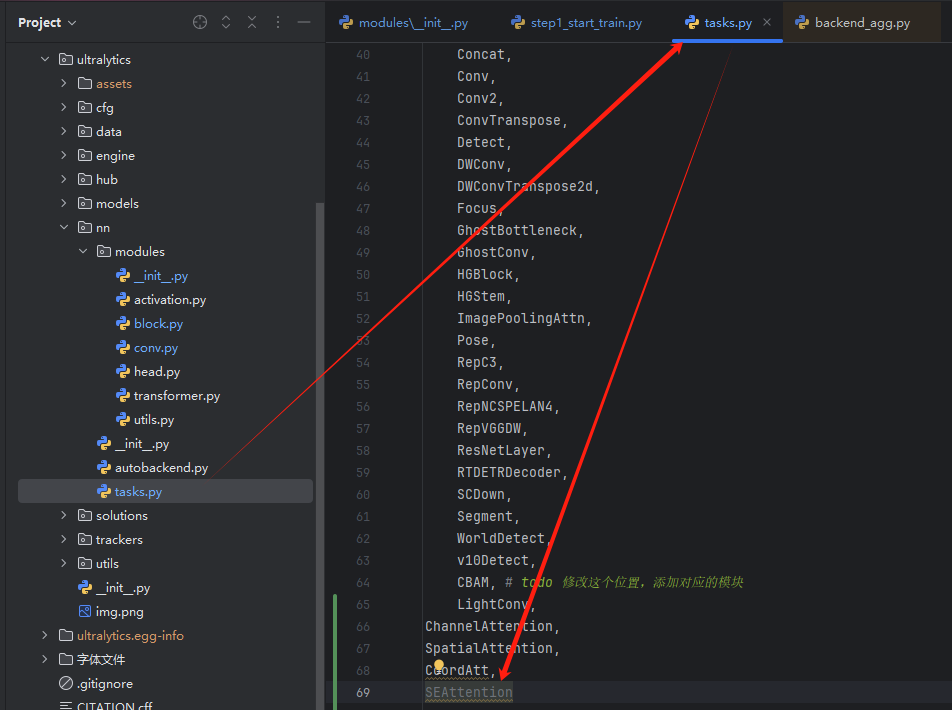
-
新增配置文件
模型改进(选看)
本次的给大家提供好的模型改进主要围绕两个方面展开,一个方面是通过添加注意力机制增加模型的精度,一个方面是通过引入一些轻量化的卷积模块降低模型的计算量。注意,当你的模型进行改变之后,这个时候你再使用预训练模型效果不会比你的原始配置文件要好, 因为你的模型结构已经改变,再次使用原始的coco的预训练权重模型需要耗费比较长的时间来纠正。所以,我们进行对比实验的时候要统一都不使用预训练模型。或者说你可以先在coco数据集上对你的改进模型进行第一个阶段的训练,然后基于第一个阶段训练好的权重进行迁移学习。后者的方式代价较大,需要你有足够的卡来做,对于我们平民玩家而言,进行第二种就蛮好。
-
准确率方面的改进
准确率方面改进2-CBAM: Convolutional Block Attention Module
论文地址:[1807.06521] CBAM: Convolutional Block Attention Module
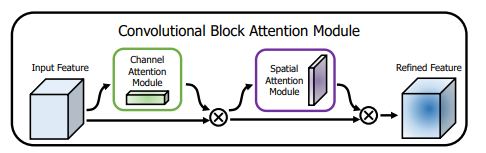
CBAM(Convolutional Block Attention Module)是一种轻量级、可扩展的注意力机制模块,首次提出于论文《CBAM: Convolutional Block Attention Module》(ECCV 2018)。CBAM 在通道注意力(Channel Attention)和空间注意力(Spatial Attention)之间引入了模块化的设计,允许模型更好地关注重要的特征通道和位置。
CBAM 由两个模块组成:
通道注意力模块 (Channel Attention Module): 学习每个通道的重要性权重,通过加权增强重要通道的特征。
空间注意力模块 (Spatial Attention Module): 学习空间位置的重要性权重,通过加权关注关键位置的特征。
该模块的代码实现如下:
import torch import torch.nn as nn class ChannelAttention(nn.Module): def __init__(self, in_channels, reduction=16): """ 通道注意力模块 Args: in_channels (int): 输入通道数 reduction (int): 缩减比例因子 """ super(ChannelAttention, self).__init__() self.avg_pool = nn.AdaptiveAvgPool2d(1) # 全局平均池化 self.max_pool = nn.AdaptiveMaxPool2d(1) # 全局最大池化 self.fc = nn.Sequential( nn.Linear(in_channels, in_channels // reduction, bias=False), nn.ReLU(inplace=True), nn.Linear(in_channels // reduction, in_channels, bias=False) ) self.sigmoid = nn.Sigmoid() def forward(self, x): batch, channels, _, _ = x.size() # 全局平均池化 avg_out = self.fc(self.avg_pool(x).view(batch, channels)) # 全局最大池化 max_out = self.fc(self.max_pool(x).view(batch, channels)) # 加和后通过 Sigmoid out = avg_out + max_out out = self.sigmoid(out).view(batch, channels, 1, 1) # 通道加权 return x * out class SpatialAttention(nn.Module): def __init__(self, kernel_size=7): """ 空间注意力模块 Args: kernel_size (int): 卷积核大小 """ super(SpatialAttention, self).__init__() self.conv = nn.Conv2d(2, 1, kernel_size=kernel_size, padding=kernel_size // 2, bias=False) self.sigmoid = nn.Sigmoid() def forward(self, x): # 通道维度求平均和最大值 avg_out = torch.mean(x, dim=1, keepdim=True) max_out, _ = torch.max(x, dim=1, keepdim=True) combined = torch.cat([avg_out, max_out], dim=1) # 拼接 # 卷积处理 out = self.conv(combined) out = self.sigmoid(out) # 空间加权 return x * out class CBAM(nn.Module): def __init__(self, in_channels, reduction=16, kernel_size=7): """ CBAM 模块 Args: in_channels (int): 输入通道数 reduction (int): 缩减比例因子 kernel_size (int): 空间注意力卷积核大小 """ super(CBAM, self).__init__() self.channel_attention = ChannelAttention(in_channels, reduction) self.spatial_attention = SpatialAttention(kernel_size) def forward(self, x): # 通道注意力模块 x = self.channel_attention(x) # 空间注意力模块 x = self.spatial_attention(x) return x -
速度方面的改进
速度方面改进2-GhostConv
Ghost Convolution 是一种轻量化卷积操作,首次提出于论文《GhostNet: More Features from Cheap Operations》(CVPR 2020)。GhostConv 的核心思想是利用便宜的操作生成额外的特征图,以减少计算复杂度和参数量。、
GhostConv的核心思想如是,卷积操作会生成冗余的特征图。许多特征图之间存在高相关性。GhostConv 的目标是通过减少冗余特征图的计算来加速网络的推理。GhostConv 的结构如下:
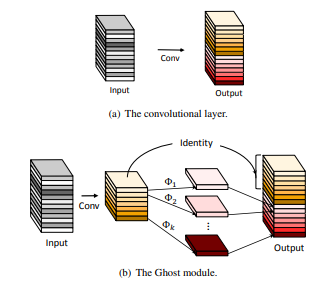
主特征图: 使用标准卷积生成一部分特征图。
副特征图: 从主特征图中通过简单的线性操作(如深度卷积)生成。
代码实现如下:
import torch import torch.nn as nn class GhostConv(nn.Module): def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1, ratio=2, dw_kernel_size=3): """ Ghost Convolution 实现 Args: in_channels (int): 输入通道数 out_channels (int): 输出通道数 kernel_size (int): 卷积核大小 stride (int): 卷积步幅 padding (int): 卷积填充 ratio (int): 副特征与主特征的比例 dw_kernel_size (int): 深度卷积的卷积核大小 """ super(GhostConv, self).__init__() self.out_channels = out_channels self.primary_channels = out_channels // ratio # 主特征图通道数 self.ghost_channels = out_channels - self.primary_channels # 副特征图通道数 # 主特征图的标准卷积 self.primary_conv = nn.Conv2d( in_channels, self.primary_channels, kernel_size, stride, padding, bias=False ) self.bn1 = nn.BatchNorm2d(self.primary_channels) # 副特征图的深度卷积 self.ghost_conv = nn.Conv2d( self.primary_channels, self.ghost_channels, dw_kernel_size, stride=1, padding=dw_kernel_size // 2, groups=self.primary_channels, bias=False ) self.bn2 = nn.BatchNorm2d(self.ghost_channels) self.relu = nn.ReLU(inplace=True) def forward(self, x): # 主特征图 primary_features = self.primary_conv(x) primary_features = self.bn1(primary_features) # 副特征图 ghost_features = self.ghost_conv(primary_features) ghost_features = self.bn2(ghost_features) # 合并主特征图和副特征图 output = torch.cat([primary_features, ghost_features], dim=1) output = self.relu(output) return output


















 293
293

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











