






面向经济学家的双重机器学习:实用指南、最佳实践和常见陷阱
在数据驱动的时代,如何精准进行因果推断,突破传统模型的限制?双重/去偏机器学习(DML)框架为经济学研究带来了革命性工具!下面这篇文章不仅详解 DML 的核心原理和操作指南,还结合实践分享了模型选择和部署中的最佳实践与常见陷阱,例如指标选择不当、数据泄漏和过拟合超参数等问题。如果你希望在高维复杂数据中精准挖掘因果关系,同时规避常见错误,这篇文章将为你提供全面的理论与实操指南,助你在经济学与机器学习的结合中迈出坚实一步!
[1]Feyzollahi M, Rafizadeh N. Double/Debiased Machine Learning for Economists: Practical Guidelines, Best Practices, and Common Pitfalls[J]. Best Practices, and Common Pitfalls (January 23, 2024), 2024.
1.引言
1. 因果推理的双重重点
- 关系方向:不仅确定变量之间的因果方向。
- 影响大小:准确量化因果关系的强度,减少内生性和模型错误指定带来的偏差。
2. 模型错误指定的挑战
- 传统上,经济学家常用简单的线性模型来描述因果关系,但这可能无法捕捉复杂的实际模式。
- 以冰淇淋销售为例,温度与销售量的关系可能是非线性的(如倒U形),简单的线性模型无法准确拟合。
3. 机器学习在因果推理中的优势
- 处理复杂性:有效管理变量之间的复杂交互和非线性关系。
- 大数据处理:能够处理包含大量变量的大型数据集。
- 减少模型假设:无需对函数形式进行强假设,提升模型的灵活性和适用性。
- 处理缺失值:某些机器学习算法(如missForest)能够天然处理缺失数据,保留更多有用信息。
4. 双重/去偏机器学习(DML)的应用
- DML结合了传统因果推理方法和机器学习的优势,提升因果效应估计的准确性。
- 现有的工具和框架(如Causa1ML、EconML、DoubleML等)简化了DML的实现过程,但可靠的因果推理还需在使用这些工具之前和之后进行细致的工作。
5. 可靠实施DML的关键因素
- 充分论证ML的使用:确保机器学习模型显著优于线性模型,以验证其应用的合理性。
- 遵循最佳实践:严格的方法论以避免机器学习可能带来的误导性模式,确保结果的可靠性。
2.DML的数学模型
2.1 背景与目标
双重/去偏机器学习(DML)框架建立在计量经济学中的 Frisch-Waugh-Lovell (FWL) 定理 基础之上,旨在解决因果推断中的 高维复杂性 和 非线性特征。FWL 定理的核心思想是通过对控制变量的影响进行“剥离”或正交化,从而隔离主要因果变量与结果变量之间的净关系。DML 扩展了这一思想,通过引入 机器学习(ML) 模型来处理高维数据与复杂交互。
2.2 FWL定理的简要回顾
对于一个包含控制变量的多元回归模型:
Y
=
β
0
+
β
1
X
+
β
2
W
1
+
⋯
+
β
n
+
1
W
n
+
ϵ
,
Y = \beta_0 + \beta_1 X + \beta_2 W_1 + \cdots + \beta_{n+1} W_n + \epsilon,
Y=β0+β1X+β2W1+⋯+βn+1Wn+ϵ,
其中:
- X X X:主要因果变量
- W 1 , ⋯ , W n W_1, \cdots, W_n W1,⋯,Wn:干扰变量(控制变量)
- ϵ \epsilon ϵ:误差项
FWL 定理指出,估计系数 β 1 \beta_1 β1 有两种等价的方法:
- 直接估计:通过原始回归方程直接得到 β 1 \beta_1 β1。
- 间接估计:通过 正交化 过程去除干扰变量
W
W
W 的影响:
- 第一步:回归
X
X
X 与
W
W
W,得到残差
X
~
\tilde{X}
X~:
X = γ 0 + γ 1 W 1 + ⋯ + γ n W n + v ⇒ X ~ = X − X ^ . X = \gamma_0 + \gamma_1 W_1 + \cdots + \gamma_n W_n + v \quad \Rightarrow \quad \tilde{X} = X - \hat{X}. X=γ0+γ1W1+⋯+γnWn+v⇒X~=X−X^. - 第二步:回归
Y
Y
Y 与
W
W
W,得到残差
Y
~
\tilde{Y}
Y~:
Y = α 0 + α 1 W 1 + ⋯ + α n W n + u ⇒ Y ~ = Y − Y ^ . Y = \alpha_0 + \alpha_1 W_1 + \cdots + \alpha_n W_n + u \quad \Rightarrow \quad \tilde{Y} = Y - \hat{Y}. Y=α0+α1W1+⋯+αnWn+u⇒Y~=Y−Y^. - 第三步:将残差
Y
~
\tilde{Y}
Y~ 对残差
X
~
\tilde{X}
X~ 进行回归,估计因果效应
β
1
\beta_1
β1:
Y ~ = β 0 + β 1 X ~ + ϵ . \tilde{Y} = \beta_0 + \beta_1 \tilde{X} + \epsilon. Y~=β0+β1X~+ϵ.
- 第一步:回归
X
X
X 与
W
W
W,得到残差
X
~
\tilde{X}
X~:
2.3 DML 对 FWL 定理的扩展
DML 在 FWL 定理的框架下引入 机器学习,将干扰变量 W W W 与主要变量 X X X、 Y Y Y 之间的复杂关系用 ML 模型进行估计。具体步骤如下:
-
干扰函数估计:通过 ML 模型分别估计 W W W 对 X X X 和 Y Y Y 的关联:
- 对
X
X
X:
X ^ = f ( W ) + v . \hat{X} = f(W) + v. X^=f(W)+v. - 对
Y
Y
Y:
Y ^ = g ( W ) + u . \hat{Y} = g(W) + u. Y^=g(W)+u.
其中, f ( W ) f(W) f(W) 和 g ( W ) g(W) g(W) 分别表示 ML 模型对高维控制变量 W W W 与 X X X、 Y Y Y 之间复杂关系的拟合函数。
- 对
X
X
X:
-
正交化过程:基于以上估计的干扰函数,计算残差 X ~ \tilde{X} X~ 和 Y ~ \tilde{Y} Y~:
X ~ = X − X ^ , Y ~ = Y − Y ^ . \tilde{X} = X - \hat{X}, \quad \tilde{Y} = Y - \hat{Y}. X~=X−X^,Y~=Y−Y^. -
因果效应估计:通过线性回归对残差 X ~ \tilde{X} X~ 与 Y ~ \tilde{Y} Y~ 进行回归,估计出因果效应:
Y ~ = β 0 + β 1 X ~ + ϵ . \tilde{Y} = \beta_0 + \beta_1 \tilde{X} + \epsilon. Y~=β0+β1X~+ϵ.
其中, β 1 \beta_1 β1 是目标因果变量 X X X 对结果变量 Y Y Y 的净影响。
2.4 DML 的优势与特点
-
处理高维与非线性关系:
- 传统线性模型在高维场景下容易受到 模型错误指定 的影响。
- DML 使用 ML 模型估计 f ( W ) f(W) f(W) 和 g ( W ) g(W) g(W),能够灵活捕捉非线性关系和高维交互效应。
-
正交化消除偏差:
- 通过正交化步骤剔除控制变量对主要因果变量与结果变量的影响,从而获得稳健且一致的因果效应估计。
-
透明性与可解释性:
- 尽管 ML 模型本身可能是“黑箱”,但在 DML 框架中,ML 仅用于估计干扰函数,而最终因果效应通过线性回归得到,保证了结果的透明性与可解释性。
-
减少过拟合风险:
- DML 强调在估计干扰函数时使用样本外性能(如交叉验证)来选择最佳 ML 模型,从而提高模型的泛化性。
3. 模型选择要点
本节深入探讨如何在 DML 框架 中选择合适的 机器学习模型,以实现高效的因果推断。选择合适的模型不仅取决于数据的特征和因变量类型,还需要理解 偏差-方差权衡 的核心概念,最终通过样本外性能标准评估模型的泛化能力。
3.1. 机器学习背景概述
机器学习(ML)模型通常分为以下两大类:
- 监督学习(Supervised Learning)
- 定义:使用带有标签的数据训练模型,目标是学习输入(自变量)与输出(因变量)之间的映射关系。
- 应用场景:DML 框架主要依赖监督学习来估计干扰函数,处理连续变量和离散变量的回归任务。
模型分类:
- 连续因变量:
- 线性回归类:包括 OLS、Lasso、Ridge、Elastic Net 等。
- 基于树的模型:如决策树(Decision Trees)、随机森林(Random Forests)、梯度提升树(Gradient Boosting)、XGBoost、LightGBM 等。
- 基于核的方法:如支持向量机(SVM)回归。
- 基于实例的模型:如 K 近邻法(KNN)。
- 神经网络与深度学习:如多层感知器(MLP)和其他回归型神经网络。
- 离散因变量:
- 分类模型:如 Logistic 回归、Brier 分数、Log Loss。
- 加权指标:如加权 Brier 分数、加权 Log Loss,特别适用于类别不平衡问题。
- 注意:在 DML 框架中,分类模型的输出仍然用于残差回归,强调回归而非简单分类。
-
无监督学习(Unsupervised Learning)
- 定义:使用无标签数据寻找数据结构或模式,如聚类和降维。
- 局限性:DML 框架不适用无监督学习,因为 DML 的目标是估计残差,需基于标记数据进行建模。
-
其他类型
- 半监督学习:结合监督与无监督学习的特点,较少应用于 DML。
- 强化学习:通过试错学习决策策略,不适用于 DML 框架。
术语差异
- 经济学术语:因变量(Dependent Variable)与自变量(Independent Variable)。
- 计算机科学术语:目标变量(Target)与特征(Features)。
3.2. 偏差-方差权衡
核心概念:偏差-方差权衡是机器学习中衡量模型性能与泛化能力的核心原则。它描述了模型复杂度与其泛化能力之间的关系:
- 泛化性(Generalization)
- 定义:模型在新数据(测试集)上保持良好表现的能力。
- 重要性:泛化性是评估模型实际应用效果的关键标准。
- 高偏差(Bias) - 欠拟合
- 原因:模型过于简单,无法捕捉数据中的真实模式。
- 表现:训练集和测试集上的误差都很大,泛化性差。
- 例子:线性回归无法拟合高度非线性数据。
- 高方差(Variance) - 过拟合
- 原因:模型过于复杂,过度学习训练数据中的噪声。
- 表现:训练集误差很小,但测试集误差很大,泛化性差。
- 例子:复杂的神经网络或过深的决策树。
- 平衡点:良好拟合
- 定义:模型复杂度适中,能够准确捕捉数据中的真实模式,同时忽略噪声。
- 目标:找到偏差与方差之间的最优平衡点,最大化模型的泛化性能。
图示说明
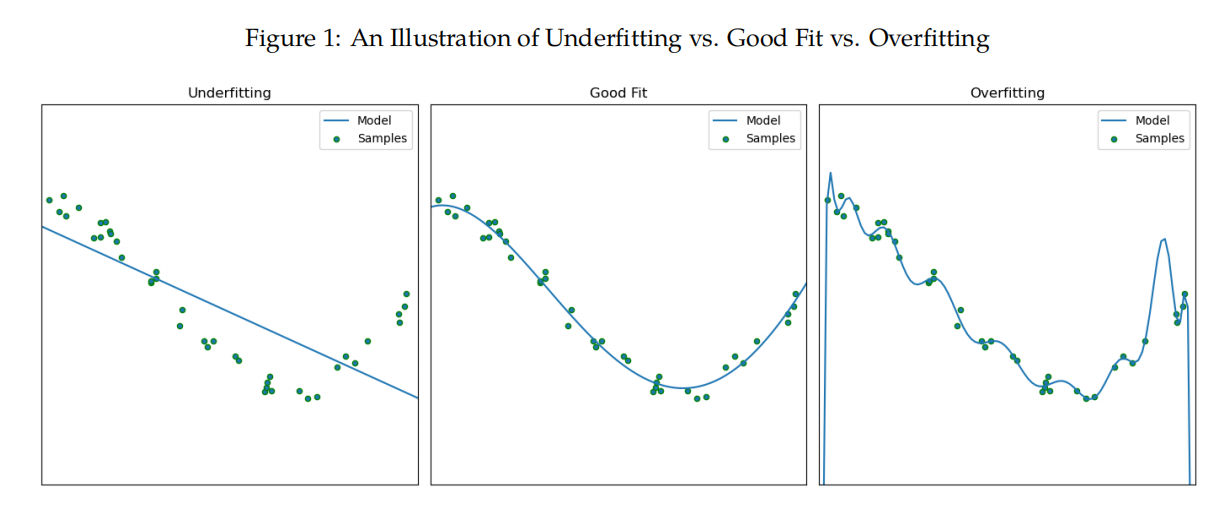
- (1)欠拟合:模型无法捕捉底层数据关系。
- (2)良好拟合:模型成功捕捉主要模式,噪声影响小。
- (3)过拟合:模型学习了训练数据的噪声,泛化性下降。
3.3. 模型选择标准
在 DML 框架中,模型选择的核心目标是找到能够提供 最优泛化性能 的模型。
1. 样本外性能(Out-of-Sample Performance)
- 定义:通过测试集评估模型在未见数据上的表现。
- 方法:
- 数据集分为训练集(用于模型训练)和测试集(用于性能评估)。
- 模型在训练集上学习,在测试集上评估性能。
- 理由:样本外性能直接衡量模型的泛化能力,是模型选择的金标准。
2. “No Free Lunch 定理”
- 来源:Wolpert(1996)。
- 含义:不存在一个模型在所有任务和数据集中都表现最优。
- 实践应用:
- 模型选择应根据具体的数据特征、因变量类型和问题目标进行判断。
- 例如:高维数据适合基于树的模型,非线性关系适合神经网络。
3. 样本外性能与现实权衡
理想情况下,样本外性能应作为唯一标准,但在现实应用中需综合考虑以下权衡因素:
- 计算成本:
- 复杂模型(如神经网络)需要更多的计算资源与训练时间。
- 可解释性:
- 简单模型(如线性回归)更易于解释,适用于政策建议和经济学研究。
- 特定应用需求:
- 不同行业和问题对模型性能、速度、透明性的需求不同。
权衡原则:
- 在保证样本外性能最优的前提下,尽量选择 计算成本可控 且 可解释性良好 的模型。
4. 最佳实践和常见陷阱
本节讨论在 DML 框架下部署机器学习模型时的最佳实践,主要涵盖模型评估、验证方法和超参数优化三大领域,同时指出每个环节中可能出现的常见问题(Pitfalls)。通过这些方法可以增强模型的鲁棒性和泛化性,避免因常见错误导致性能下降或结果误导。
4.1. 选择合适的评估指标
评估指标的定义
根据因变量的类型,选择合适的评估指标来量化样本外性能。这是确保模型选择合理性和可靠性的第一步。
评估指标的分类
-
连续因变量(Regression Tasks)
- 平均绝对误差(MAE):
MAE = 1 n ∑ i = 1 n ∣ y i − y ^ i ∣ \text{MAE} = \frac{1}{n} \sum_{i=1}^n |y_i - \hat{y}_i| MAE=n1i=1∑n∣yi−y^i∣- 特点:简单易解释,对大误差不敏感。
- 均方根误差(RMSE):
RMSE = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 \text{RMSE} = \sqrt{\frac{1}{n} \sum_{i=1}^n (y_i - \hat{y}_i)^2} RMSE=n1i=1∑n(yi−y^i)2- 特点:对大误差更敏感,适合需要关注异常值的场景。
- 平均绝对百分比误差(MAPE):
MAPE = 100 % n ∑ i = 1 n ∣ y i − y ^ i y i ∣ \text{MAPE} = \frac{100\%}{n} \sum_{i=1}^n \left| \frac{y_i - \hat{y}_i}{y_i} \right| MAPE=n100%i=1∑n yiyi−y^i - 特点:以百分比表示误差,适合跨数据集比较。
- 平均偏差误差(MBE):
MBE = 1 n ∑ i = 1 n ( y i − y ^ i ) \text{MBE} = \frac{1}{n} \sum_{i=1}^n (y_i - \hat{y}_i) MBE=n1i=1∑n(yi−y^i)- 特点:衡量系统性偏差,正值表示高估,负值表示低估。
- 平均绝对误差(MAE):
-
离散因变量(Classification Tasks)
- Brier 分数:
Brier Score = 1 n ∑ i = 1 n ( f i − o i ) 2 \text{Brier Score} = \frac{1}{n} \sum_{i=1}^n (f_i - o_i)^2 Brier Score=n1i=1∑n(fi−oi)2- 衡量概率预测的准确性,适合二分类问题。
- Log Loss(对数损失):
Log Loss = − 1 n ∑ i = 1 n [ o i log ( f i ) + ( 1 − o i ) log ( 1 − f i ) ] \text{Log Loss} = - \frac{1}{n} \sum_{i=1}^n [o_i \log(f_i) + (1-o_i) \log(1-f_i)] Log Loss=−n1i=1∑n[oilog(fi)+(1−oi)log(1−fi)]- 对分类错误的“高度自信”预测惩罚更大。
- 加权指标(Weighted Metrics):
- 适用于类别分布不均的数据集,通过调整权重提升少数类别的重要性。
- Brier 分数:
最佳实践
- 选择与实际问题目标最匹配的指标。
- 例如,在异常值敏感场景中,优先使用 RMSE。
- 在类别分布严重不平衡的数据中,使用加权指标如 Weighted Brier Score。
常见陷阱
-
错误选择指标:
- 未能根据具体问题选择合适的指标,可能导致模型优化方向偏离实际目标。
- 例如,库存管理中低估需求比高估需求影响更严重,应优先选择对大误差敏感的 RMSE。
-
过度依赖指标:
- 过度优化某一指标,可能导致对该指标的“过拟合”,忽略实际预测效果的全面性。
-
忽略类别不平衡问题:
- 在二分类问题中,若 99% 数据属于负类,简单模型只预测负类即可获得高精度,但无法识别少数类(正类)。
- 应采用加权指标评估模型性能。
4.2. K-Fold Cross-Validation(交叉验证)
定义与原理
- 定义:将数据分为 k k k 个不重叠的子集,每次用其中 k − 1 k-1 k−1 个子集训练模型,用剩余一个子集测试性能。重复 k k k 次后取平均结果作为模型性能。
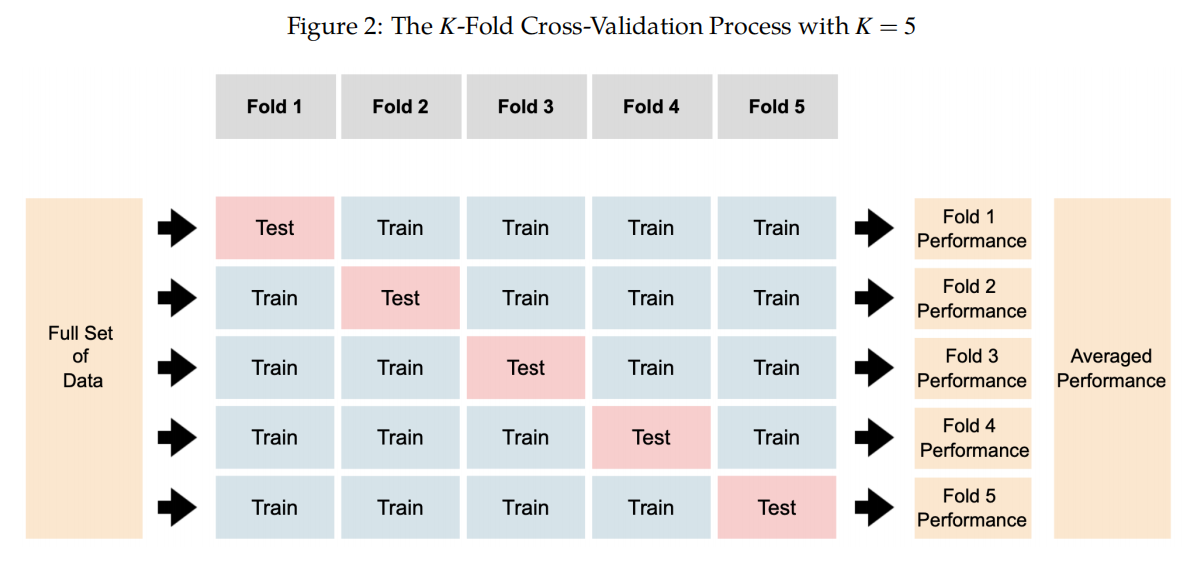
- 优点:
- 提高性能估计的稳定性,减少单次训练/测试划分的随机性影响。
- 在数据有限的情况下充分利用每一条数据。
最佳实践
-
选择合适的 k k k
- 默认值 k = 5 k=5 k=5 或 k = 10 k=10 k=10 是常用的平衡点:计算成本适中,估计结果稳定。
- 数据量较小时,较小的 k k k(如 k = 3 k=3 k=3)可以减少计算压力。
-
特殊数据的处理:
- 时间序列数据:使用扩展窗口或滑动窗口交叉验证,保持时间序列的顺序性。
- 类别不平衡数据:使用分层交叉验证(Stratified Cross-Validation),确保每个子集中类别分布与整体一致。
常见陷阱
-
数据泄漏:
- 在划分数据前对整个数据集进行归一化或特征选择,可能导致测试集信息泄露到训练集,破坏验证的独立性。
- 解决方案:每次交叉验证循环内分别处理归一化或特征选择。
-
不适当的 k k k 选择:
- k k k 过小:模型评估不充分,训练集不足以代表整体数据。
- k k k 过大:计算成本高,验证结果的方差可能降低过多,掩盖真实模型性能。
4.3. 超参数优化
定义与原理
- 超参数(Hyperparameter):训练前设定的模型外部参数(如决策树的最大深度、学习率等),决定模型的训练过程和性能。
- 调优目标:找到最佳的超参数组合,使模型性能达到最优。
调优方法
-
网格搜索(Grid Search):
- 穷举所有可能的超参数组合,评估每种组合的性能。
- 缺点:计算成本高,尤其在高维超参数空间中。
-
随机搜索(Random Search):
- 随机选择超参数组合,探索潜在的优质参数区域。
- 优点:比网格搜索更高效,适合超参数空间较大的场景。
-
贝叶斯优化(Bayesian Optimization, BO):
- 通过构建概率模型,逐步缩小参数空间以寻找最优解。
- 优势:计算效率高,尤其在复杂模型中表现优异。
最佳实践
- 使用随机搜索进行初步探索,结合贝叶斯优化深入挖掘最优超参数。
- 设置合理的超参数范围,避免计算资源浪费。
常见陷阱
-
过拟合超参数:
- 在特定数据集上过度调整超参数,可能导致模型泛化性下降。
- 解决方案:结合交叉验证避免过拟合。
-
忽视初始搜索:
- 直接使用贝叶斯优化,可能错过参数空间中的潜在全局最优区域。
- 解决方案:先用随机搜索进行初始探索,再结合贝叶斯优化。
5. 实施DML:分步指南
本节提供了双重/去偏机器学习(DML)的详细实施指南,描述了从数据预处理到最终因果效应估计的完整过程。该指南适用于需要控制混杂变量 W W W 来估计特定变量 X X X 对因变量 Y Y Y 因果影响的情景。
Step 1:干扰函数估计
此步骤的目标是估计
W
W
W 与
X
X
X 和
Y
Y
Y 之间的关系。公式如下:
X
^
=
f
(
W
)
+
v
\hat{X} = f(W) + v
X^=f(W)+v
Y
^
=
g
(
W
)
+
u
\hat{Y} = g(W) + u
Y^=g(W)+u
其中:
- X ^ \hat{X} X^ 是 X X X 的估计值,由 W W W 决定。
- Y ^ \hat{Y} Y^ 是 Y Y Y 的估计值,由 W W W 决定。
Step 1-1: 模型定义
- 根据因变量的类型选择适当的机器学习模型:
- 回归任务(如连续变量):线性回归、Lasso、随机森林、XGBoost、神经网络等。
- 分类任务(如离散变量):Logistic 回归、支持向量机(SVM)等。
Step 1-2: 模型优化
- 使用 k-fold 交叉验证 优化模型的超参数:
- 选定评估指标(如 RMSE、MAE、Log Loss)。
- 遍历不同的超参数组合(如树的深度、学习率、神经网络的层数和激活函数)。
- 计算每个超参数组合在 k k k 折中的平均性能,选择性能最优的超参数组合。
- 例如,对于神经网络,超参数可能包括隐藏层数、学习率和激活函数类型。
Step 1-3: 模型选择
- 比较所有优化后的模型,选择在交叉验证中表现最好的模型(具有最佳平均性能)。
- 例如,若随机森林、XGBoost 和神经网络均经过优化,选择性能最好的 XGBoost 模型。
Step 1-4: 函数估计
- 使用优化后的模型拟合干扰函数 f ( W ) f(W) f(W) 和 g ( W ) g(W) g(W),生成 X ^ \hat{X} X^ 和 Y ^ \hat{Y} Y^。
- 注意事项:
- 在本步骤中,最佳模型需要重新使用整个数据集进行训练,以确保估计的干扰函数充分利用了所有可用信息。
关键提示:
- 模型选择(Step 1-3)应基于交叉验证的平均性能,优先选择泛化性较强的模型。
- 避免在 Step 1-4 中重新训练所有模型并基于完整数据选择性能最好的模型,因为此方法可能导致过拟合。
Step 2: 残差计算
在完成干扰函数估计后,计算残差以剔除混杂变量的影响:
X
~
=
X
−
X
^
\tilde{X} = X - \hat{X}
X~=X−X^
Y
~
=
Y
−
Y
^
\tilde{Y} = Y - \hat{Y}
Y~=Y−Y^
其中:
- X ~ \tilde{X} X~ 是自变量 X X X 剔除了 W W W 影响后的残差。
- Y ~ \tilde{Y} Y~ 是因变量 Y Y Y 剔除了 W W W 影响后的残差。
意义:
- 通过残差计算,将 W W W 的干扰从 X X X 和 Y Y Y 中剔除,为后续因果效应估计提供更纯净的数据。
Step 3: 因果效应估计
最终步骤是通过残差回归估计
X
X
X 对
Y
Y
Y 的因果效应:
Y
~
=
β
0
+
β
1
X
~
+
ϵ
\tilde{Y} = \beta_0 + \beta_1 \tilde{X} + \epsilon
Y~=β0+β1X~+ϵ
其中:
- β 1 \beta_1 β1 为 X X X 对 Y Y Y 的因果效应估计值,已控制 W W W 的影响。
- ϵ \epsilon ϵ 是误差项。
解释:
- 该回归估计了剔除混杂变量后 X X X 与 Y Y Y 之间的净效应,保证了因果推断的稳健性。
关键技术与注意事项
1. 正交化的作用
- 正交化通过残差计算剔除了 W W W 的影响,确保估计的因果效应不受混杂变量干扰。
- 该步骤对于提高估计的稳健性和一致性至关重要。
2. 泛化性能的优先级
- 模型的选择与优化应以泛化性能为核心,而非仅在训练数据上的表现。
- 在交叉验证中表现最优的模型应优先使用,并在完整数据集上重新训练。
3. 数据泄漏风险
- 所有数据预处理(如标准化、特征选择)必须在交叉验证的训练集中独立完成,避免测试集信息泄漏。
研究结论
双重/去偏机器学习(DML)框架作为一种结合机器学习进行因果推断的方法,为经济分析提供了一种前景广阔的途径。本文的主要目标是通过简化其复杂性,使 DML 框架对经济学家和实践者更加直观易懂。
本文首先通过提供对 DML 的清晰直观理解,将理论概念与实际应用联系起来。随后,文章重点探讨了如何稳健地部署机器学习模型。为此,文章首先阐明了为什么泛化能力 应作为评估模型的首要标准,以及其与样本外性能的关系。接着,文章提供了开发具备更强泛化能力模型的最佳实践,同时指出了常见的陷阱。具体包括强调选择正确的评估指标、实施 k 折交叉验证 和高效调优超参数的重要性。
在评估指标的讨论中,文章强调了将指标与因变量类型及模型目标对齐的重要性。同时,文章对选择 k 折交叉验证的折数时应保持谨慎,以及避免训练集和测试集之间的数据泄漏提出了建议。此外,文章建议采用专门的交叉验证技术,例如针对时间序列数据的时间序列交叉验证和针对离散数据的分层交叉验证,以确保模型评估更稳健、更具代表性。在超参数调优方面,文章推荐了平衡的调优方法,包括结合随机搜索和贝叶斯优化的策略。
本文后半部分提供了详细的 DML 实施分步指南。这一指南对于那些希望将机器学习技术整合到工作的应用经济学家和实践者尤为有用。通过这些内容,本文旨在提升经济分析的准确性和在不断演变的领域中的相关性。


















 1191
1191

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









