






CEEMDAN算法,即完全集成经验模态分解与自适应噪声,是在2011年由Torres等人提出的一个信号处理技术。这个算法的创新之处在于它不仅在原始信号中加入白噪声,而且在每一步的残差中也会加入白噪声。这种方法有效地解决了传统EMD(经验模态分解)中常见的模态混叠问题,也就是不同频率的信号成分互相干扰的问题。
目录
一、CEEMDAN简介
1.算法简介
CEEMDAN是Complete Ensemble Empirical Mode Decomposition with Adaptive Noise的缩写,即完全集成经验模态分解与自适应噪声。它是一种用于处理非线性和非平稳信号的先进信号分解技术。CEEMDAN算法通过引入自适应噪声和多次迭代的方式,有效地解决了传统经验模态分解(EMD)中的模态混叠问题,提高了分解的准确性和稳定性。

2.核心思想
CEEMDAN算法的核心思想是在每次迭代中,将白噪声添加到经EMD分解后的内禀模态函数(IMF)中,这种逐步添加噪声的方式,能够有效地减轻白噪声对分解结果的影响,从而提高分解的精度和稳定性。与EEMD和CEEMD通过对所有IMF分量进行总体平均不同,CEEMDAN在每一阶IMF分量获得后立即进行平均处理,这意味着每一阶IMF在计算后都会进行平均,以减少白噪声的影响。随后,处理残余部分并重复此过程,从而有效地解决了白噪声从高频到低频的转移问题。
3.应用场景
CEEMDAN算法在处理带噪声的信号时表现出色,它通过引入逐步噪声和逐阶平均处理,能够有效减轻噪声对信号分解的影响。在实际应用中,CEEMDAN算法可以广泛应用于各种信号处理和分析的场景,例如在机械故障诊断、生物医学信号处理、图像处理、语音识别等领域。
4.算法步骤(白话文版本)
CEEMDAN算法,全称是“完全集成经验模态分解与自适应噪声”,这名字听起来挺高大上的,其实它就像是一个高级的信号“过滤器”。这个过滤器是用来处理那些特别复杂、难以捉摸的信号,比如股市的波动、天气的变化,或者是机器运转时产生的各种震动。
这个算法的工作原理,可以想象成下面这样:

-
信号的“加料”过程:首先,我们有一段复杂的信号,就像是一碗混合了各种食材的汤。为了更好地分辨出这些食材,我们在汤里加入一些特别调制的“调料”——这里的“调料”就是自适应噪声。这种噪声是经过精心设计的,能够帮助我们更好地分离信号中的不同成分。
-
“过滤”过程:接下来,我们用一个筛子去筛这碗加了“调料”的汤。这个筛子就是经验模态分解(EMD)。通过这个筛子,我们可以把汤里的食材按照大小分成不同的部分,每一部分都对应信号中的一个特定频率范围。这个过程要重复很多次,每次都用不同的筛子(也就是每次都加入不同的噪声),以确保我们能够从各个角度把食材分得清清楚楚。
-
“平均”操作:因为筛了很多次,每次分出来的食材可能会有些差异。所以,我们把每次分出来的同一种食材平均一下,这样可以减少因为“调料”带来的误差,确保我们得到的食材(也就是信号的各个成分)是准确无误的。
-
迭代直到“清澈”:每次筛完,都会剩下一些汤渣,我们把这些汤渣收集起来,再放回锅里继续加“调料”,继续筛。这个过程要重复很多次,直到汤变得足够清澈,或者我们已经把食材分得差不多了。
-
最终“还原”:最后,我们把分出来的所有食材重新放回汤里,这样就能还原出原来的汤,但是这次的汤已经清清楚楚,每样食材都分得明明白白。
通过这个过程,CEEMDAN算法能够帮助我们从复杂的信号中提取出有用的信息,就像是从一碗混合了各种食材的汤中,把每一种食材都分离出来,让我们能够更清楚地看到每一样食材,也就是更准确地分析和理解信号。
5.算法步骤(公式版本)
以下是CEEMDAN算法的详细步骤:
设 表示对序列进行EMD分解后的第
个IMF分量,
表示CEEMDAN在第
阶段对输入序列添加的噪声系数,
为CEEMDAN产生的第
个IMF分量。
(1) 向原始信号 中加入
次高斯白噪声,构造得到共
个预处理序列
,其中
。
式中:是高斯白噪声的权值系数;
是第
次处理时的高斯白噪声。
(2) 对所有的预处理序列 进行EMD分解,得到第一个IMF分量
,取其均值作为CEEMDAN分解得到的第一个IMF分量
,同时得到第一个残差序列
,分别如下所示。
(3) 同样将残差序列 加入高斯白噪声构造为
个新的序列
,对这
个序列继续进行EMD分解后,求其均值得到第二个IMF分量
,并做差得到
,如下所示。
类比推知,第阶段的残差如下式所示。
(4) 对 进行
次EMD分解,即得到CEEMDAN分解后的第
个IMF序列,如下所示。
(5) 重复以上步骤,直到分解停止,最后残余序列如下式所示。
即信号序列经CEEMDAN分解后的表达式如下式所示。
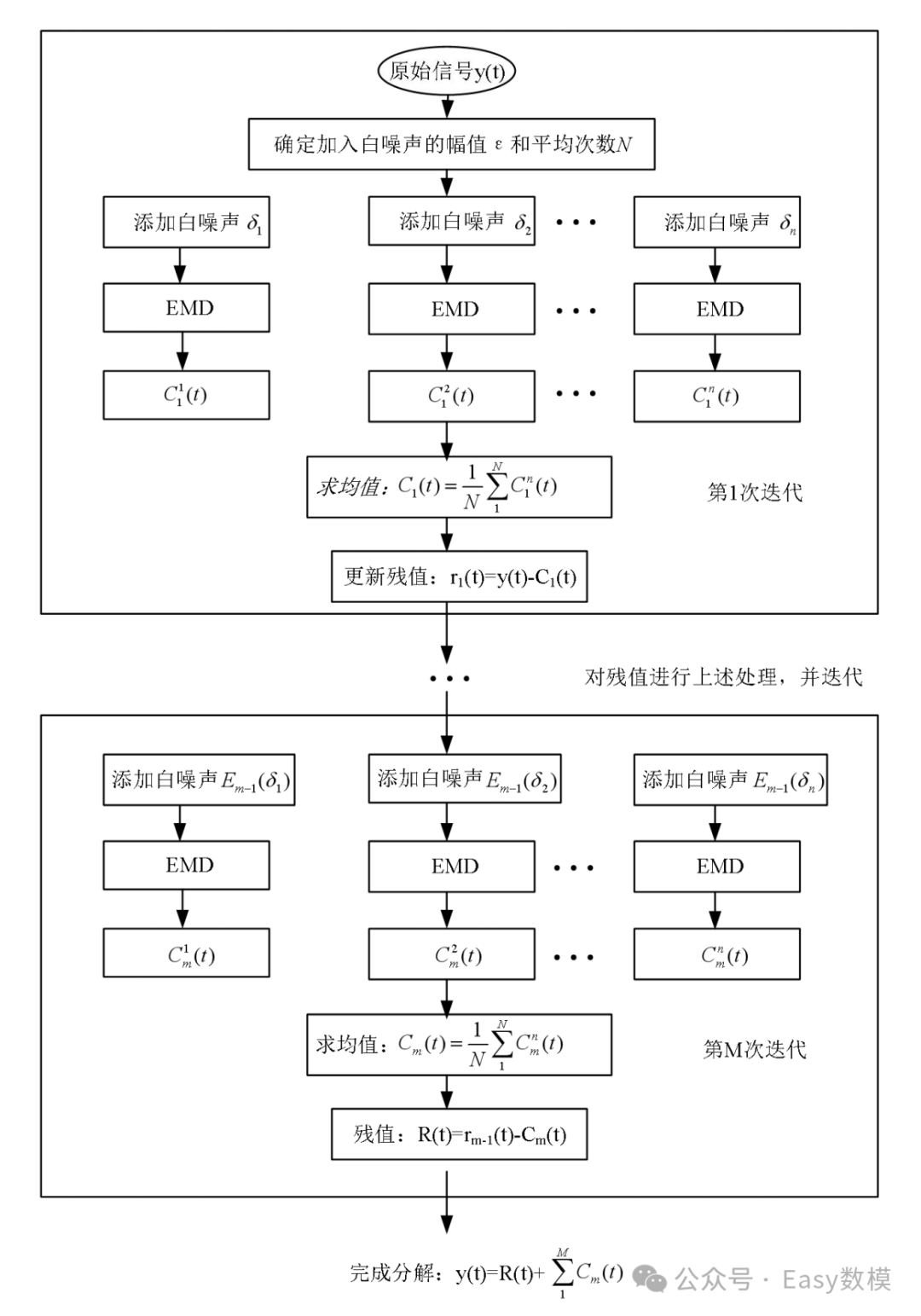
图示:CEEMDAN算法流程图
二、CEEMDAN算法python代码
用于对时间序列数据进行CEEMDAN(完全集成经验模态分解与自适应噪声)分解,并可视化及保存结果。以下是代码的详细解释:
下载相关库
pip install pyemd
pip install EMD-signal导入必要的库
import matplotlib.pyplot as plt
import tensorflow as tf
from PyEMD import EMD, EEMD, CEEMDAN
import pandas as pd
import warnings
warnings.filterwarnings("ignore")-
matplotlib.pyplot用于数据可视化。 -
tensorflow用于深度学习模型的构建和训练,但在此脚本中未使用。 -
PyEMD库中的EMD,EEMD,CEEMDAN用于模态分解。 -
pandas用于数据处理和分析。 -
warnings用于控制警告消息,设置为忽略警告。
设置GPU加速(可选)
gpus = tf.config.experimental.list_physical_devices(device_type='GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)-
检查可用的GPU设备,并设置内存增长以优化GPU使用。
配置matplotlib以正常显示中文和负号
plt.rcParams['font.sans-serif'] = ['Times New Roman']
plt.rcParams['axes.unicode_minus'] = False-
设置字体和负号显示,确保图表中的中文和负号可以正确显示。
读取数据
df_raw_data = pd.read_csv('测试数据.csv', encoding='gbk')
series_close = pd.Series(df_raw_data['power'].values, index=df_raw_data['time'])-
从CSV文件中读取数据,并将'power'列的值作为数据系列,'time'列的值作为索引。
定义CEEMDAN分解函数
def ceemdan_decompose(series=None, trials=10, num_clusters=3):
decom = CEEMDAN()
decom.trials = trials
df_ceemdan = pd.DataFrame(decom(series.values).T)
df_ceemdan.columns = ['imf' + str(i+1) for i in range(len(df_ceemdan.columns))]
return df_ceemdan-
定义一个函数,使用CEEMDAN方法对时间序列数据进行分解,返回分解后的DataFrame。
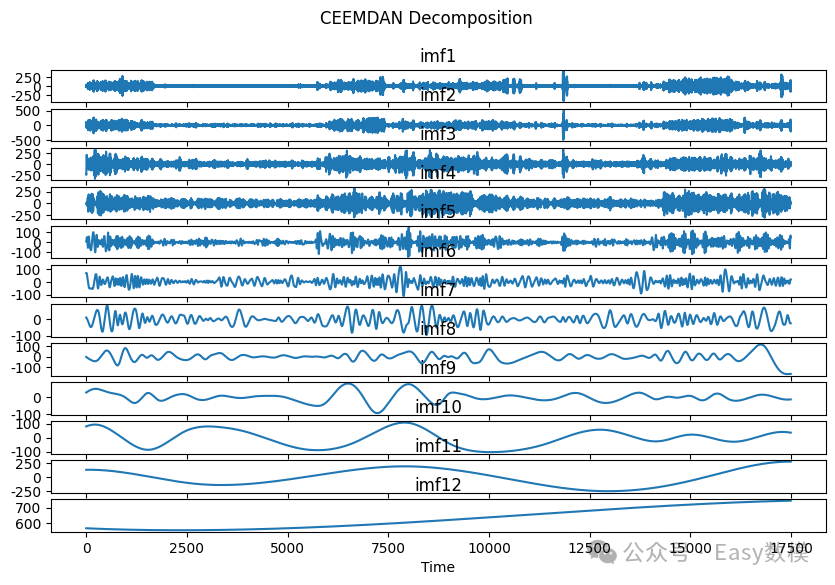
执行CEEMDAN分解并可视化结果
df_ceemdan = ceemdan_decompose(series_close)
fig, axs = plt.subplots(nrows=len(df_ceemdan.columns), figsize=(10, 6), sharex=True)
for i, col in enumerate(df_ceemdan.columns):
axs[i].plot(df_ceemdan[col])
axs[i].set_title(col)
plt.suptitle('CEEMDAN Decomposition')
plt.xlabel('Time')
plt.show()-
对
series_close进行CEEMDAN分解,并将分解结果存储在df_ceemdan中。 -
创建多个子图,每个子图显示一个模态函数(IMF)。
-
打印和保存分解结果
print(df_ceemdan)
df_ceemdan.to_excel("CEEMDAN.xlsx", index=False)-
打印分解后的DataFrame。
-
将分解结果保存为Excel文件。
三、国内文献综述
自适应噪声完备集成经验模态分解(CEEMDAN)算法作为一种高效的信号处理技术,近年来在国内得到了广泛的研究与应用。CEEMDAN算法通过在信号分解过程中添加自适应噪声,有效解决了传统经验模态分解(EMD)中的模态混叠问题,提高了信号分解的准确性和稳定性。
在风电功率预测领域,赵凌云等[1]提出了一种结合CEEMDAN和改进时间卷积网络的短期风电功率预测模型。该模型利用CEEMDAN对风电功率序列进行分解,得到子序列分量,并与关键气象变量数据构成训练集,然后使用基于时间模式注意力机制的时间卷积网络对子序列分量分别进行预测,最终通过重构预测结果得到最终的预测值,有效提高了风电功率的预测准确率。
在机械故障诊断方面,李怡等[2]提出了一种基于CEEMDAN多尺度熵与SSA-SVM相结合的故障诊断方法。该方法通过CEEMDAN算法分解信号,获得若干个固有模态函数(IMF),再采用相关系数方法选择有用IMF分量,并计算重构信号的多尺度熵作为特征向量,输入SSA优化的SVM进行故障分类,提高了轴承的故障分类准确率。
蒋玲莉等[3]利用CEEMDAN排列熵作为敏感特征量,结合SVM进行模式识别,实现了螺旋锥齿轮故障辨识的方法。该方法通过CEEMDAN分解振动信号,得到一系列从高频到低频的内禀模态函数(IMF),并采用重叠组合法对排列熵计算过程中的关键参数进行优选,以优选IMF的排列熵值组成特征向量,训练多分类SVM进行螺旋锥齿轮故障辨识。
在锂离子电池剩余使用寿命(RUL)预测方面,杨彦茹等[4]提出了一种结合CEEMDAN和支持向量回归(SVR)的锂离子电池RUL预测方法。该方法在放电过程中提取了一个可测量的健康因子,并使用CEEMDAN将健康因子进行分解,获得一系列相对平稳的分量,最后采用CEEMDAN分解后的健康因子作为SVR预测模型输入,实现了锂离子电池RUL预测。
在信号去噪领域,张培玲等[5]提出了一种基于改进小波阈值-CEEMDAN的去噪算法,用于剔除心电图(ECG)信号中的噪声。该算法首先对ECG信号进行CEEMDAN分解,得到一组由高频到低频分布的固有模态分量(IMF),然后根据相关系数法,对高频IMF分量进行改进阈值的小波去噪,对于低频IMF分量,再通过设定固定阈值,将低于该阈值的IMF分量确定为基线漂移信号并剔除,然后将去噪后的IMF分量和保留的IMF重构,实验结果表明,该算法相比EMD小波去噪和EEMD小波去噪算法效果更佳。
王海龙等[6]引入了一种基于CEEMDAN分解联合小波包分析的降噪方法,用于隧道爆破施工中采集到的实测振动信号的处理。该方法通过CEEMDAN分解得到多个本征模态分量,利用相关系数筛选出包含噪声的模态分量,并通过模态分量的频谱图及方差贡献率进行校核,然后利用小波包阈值降噪方法对含有噪声的模态分量进行处理,最后将未经处理的模态分量与去噪完成的分量重构得到最终纯净的爆破振动信号。
贺毅岳等[7]将CEEMDAN算法引入到股市指数预测建模中,结合长短期记忆网络(LSTM)对复杂序列中长期依赖关系高效的建模能力,提出了一种股市指数集成预测方法CEEMDAN-LSTM。该方法通过CEEMDAN对指数进行分解与重构,获得其高、低频分量及趋势项,分别构建各分量的LSTM预测模型并优化高频子序列IMF重组方式,进而通过加和集成各分量预测值获得指数的整体预测值。
赵书涛等[8]提出了一种基于CEEMDAN样本熵与FWA-SVM的高压断路器机械故障诊断方法。该方法通过CEEMDAN提取若干反映断路器操动过程机械状态信息的本征模态函数(IMF)分量,依据各IMF相关系数与能量分布,将前7阶IMF分量进行小波包软阈值去噪,计算其样本熵作为特征量,最后采用基于免疫浓度思想的烟花算法(FWA)优化支持向量机(SVM)分类器,对断路器不同运行状态进行分类识别。
岳有军等[9]提出了一种基于CEEMDAN-SE和DBN的短期电力负荷预测模型。该模型利用CEEMDAN-样本熵将原始负荷序列分解为多个特征互异的子序列,计算各子序列的样本熵,将熵值相近的子序列重组得到新序列,降低了原始非平稳序列对预测精度造成的影响并减小计算规模。
罗志增等[10]提出了一种基于CEEMDAN-ICA的单通道脑电信号眼电伪迹滤除方法。该方法首先将含伪迹脑电信号自适应分解成多维本征模态函数(IMF),以满足盲源分离方法对信号正定或超定要求,再对本征模态函数用ICA方法构建多维源信号,最后利用模糊熵阈值判据判别多维源信号中的伪迹信号,完成滤波并重构脑电信号。
舒畅等[11]提出了基于CEEMDAN的配电变压器放电故障噪声诊断方法。该方法首先采用CEEMDAN对所采集的声信号进行分解,得到若干个本征模态函数(IMF),求取各IMF的峭度值,并选取合适的IMF分量进行信号重构,从中提取放电故障声信号。
张建伟等[12]提出了一种基于CEEMDAN与SVD的泄流结构振动信号降噪方法。该方法对一维泄流振动信号时程进行CEEMDAN分解,将信号分解为一系列固有模态函数分量(IMF),运用频谱分析方法筛选包含主要振动信息的IMF分量,滤除低频水流噪声,实现信号的初次滤波。
李锋等[13]提出了一种CEEMDAN与支持向量机结合的故障诊断方法,用于液压泵故障诊断。该方法将传感器测得的液压泵故障振动信号进行CEEMDAN分解,得到多个固有模态函数(IMF),并计算其样本熵作为支持向量机的输入特征向量,以诊断液压泵的故障类型。
李军等[14]提出了一种具有自适应噪声的完整集成经验模态分解(CEEMDAN)-排列熵和泄漏积分回声状态网络(LIESN)的组合预测方法,用于中期电力负荷预测。该方法采用CEEMDAN-排列熵方法将负荷时间序列分解为具有复杂度差异的不同子序列,通过分析各个子序列的内在特性,分别构建相应的LIESN预测模型,最终对预测结果进行叠加。
参考文献
Torres M E, Colominas M A, Schlotthauer G, et al. A complete ensemble empirical mode decomposition with adaptive noise[C]//2011 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2011: 4144-4147.
[1]赵凌云,刘友波,沈晓东,等.基于CEEMDAN和改进时间卷积网络的短期风电功率预测模型[J].电力系统保护与控制,2022,50(01):42-50.
[2]李怡,李焕锋,刘自然.基于CEEMDAN多尺度熵和SSA-SVM的滚动轴承故障诊断研究[J].机电工程,2021,38(05):599-604.
[3]蒋玲莉,谭鸿创,李学军,等.基于CEEMDAN排列熵与SVM的螺旋锥齿轮故障识别[J].振动.测试与诊断,2021,41(01):33-40+198-199.
[4]杨彦茹,温杰,史元浩,等.基于CEEMDAN和SVR的锂离子电池剩余使用寿命预测[J].电子测量与仪器学报,2020,34(12):197-205.
[5]张培玲,李小真,崔帅华.基于改进小波阈值-CEEMDAN算法的ECG信号去噪研究[J].计算机工程与科学,2020,42(11):2067-2072.
[6]王海龙,赵岩,王海军,等.基于CEEMDAN-小波包分析的隧道爆破信号去噪方法[J].爆炸与冲击,2021,41(05):125-137.
[7]贺毅岳,李萍,韩进博.基于CEEMDAN-LSTM的股票市场指数预测建模研究[J].统计与信息论坛,2020,35(06):34-45.
[8]赵书涛,马莉,朱继鹏,等.基于CEEMDAN样本熵与FWA-SVM的高压断路器机械故障诊断[J].电力自动化设备,2020,40(03):181-186.
[9]岳有军,刘英翰,赵辉,等.基于CEEMDAN-SE和DBN的短期电力负荷预测[J].电测与仪表,2020,57(17):59-65.
[10]罗志增,严志华,傅炜东.基于CEEMDAN-ICA的单通道脑电信号眼电伪迹滤除方法[J].传感技术学报,2018,31(08):1211-1216.
[11]舒畅,金潇,李自品,等.基于CEEMDAN的配电变压器放电故障噪声诊断方法[J].高电压技术,2018,44(08):2603-2611.
[12]张建伟,侯鸽,暴振磊,等.基于CEEMDAN与SVD的泄流结构振动信号降噪方法[J].振动与冲击,2017,36(22):138-143.
[13]李锋,林阳阳,赵辉,等.基于CEEMDAN-SVM的液压泵故障诊断方法研究[J].液压与气动,2016,(01):125-129.
[14]李军,李青.基于CEEMDAN-排列熵和泄漏积分ESN的中期电力负荷预测研究[J].电机与控制学报,2015,19(08):70-80.
往期推荐


















 686
686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









