







课程学后感,以及自己的理解
目录
一、语音表征学习
Speech Representation Learning(语音表征学习)是一种自动从原始语音信号中学习有意义、可区分性和紧凑性表示的方法。这些表示可以用来解决各种语音处理任务,如语音识别、语音合成、说话者识别和情感识别等。语音表示学习的目标是发现隐藏在原始语音信号中的底层结构和模式,以便更好地理解、分析和操作语音。
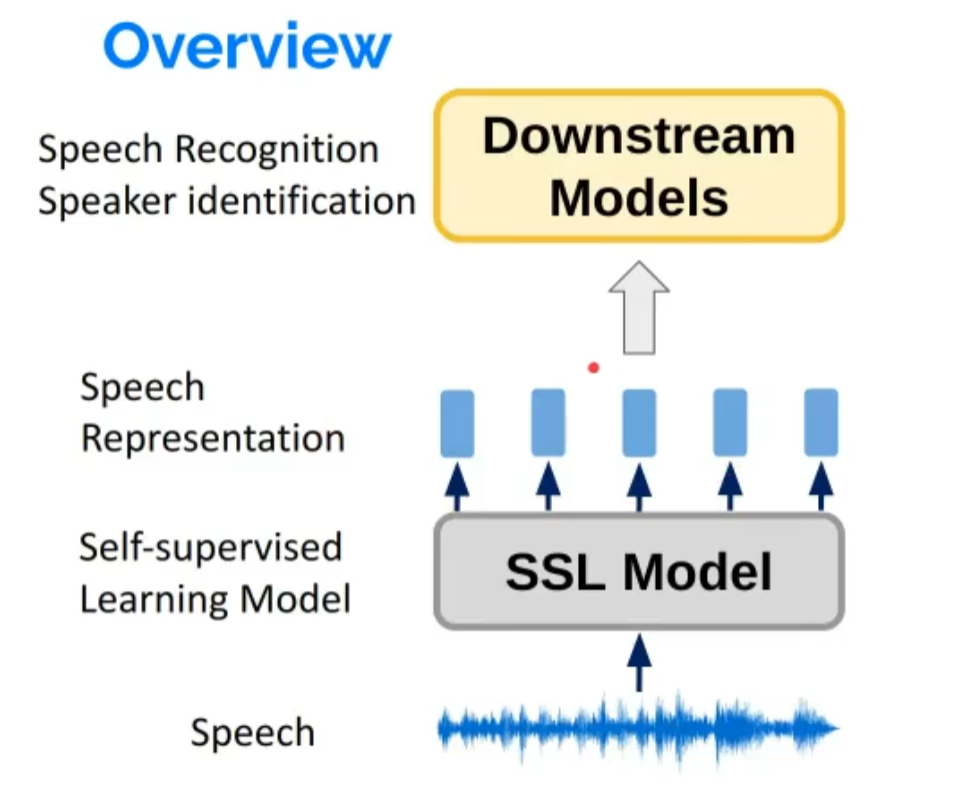
为什么要进行语音的表征学习?
传统的大量带有标签的数据成本较高,未标识的数据使用自监督模型进行预训练,可以大大缩减成本。
模型代表
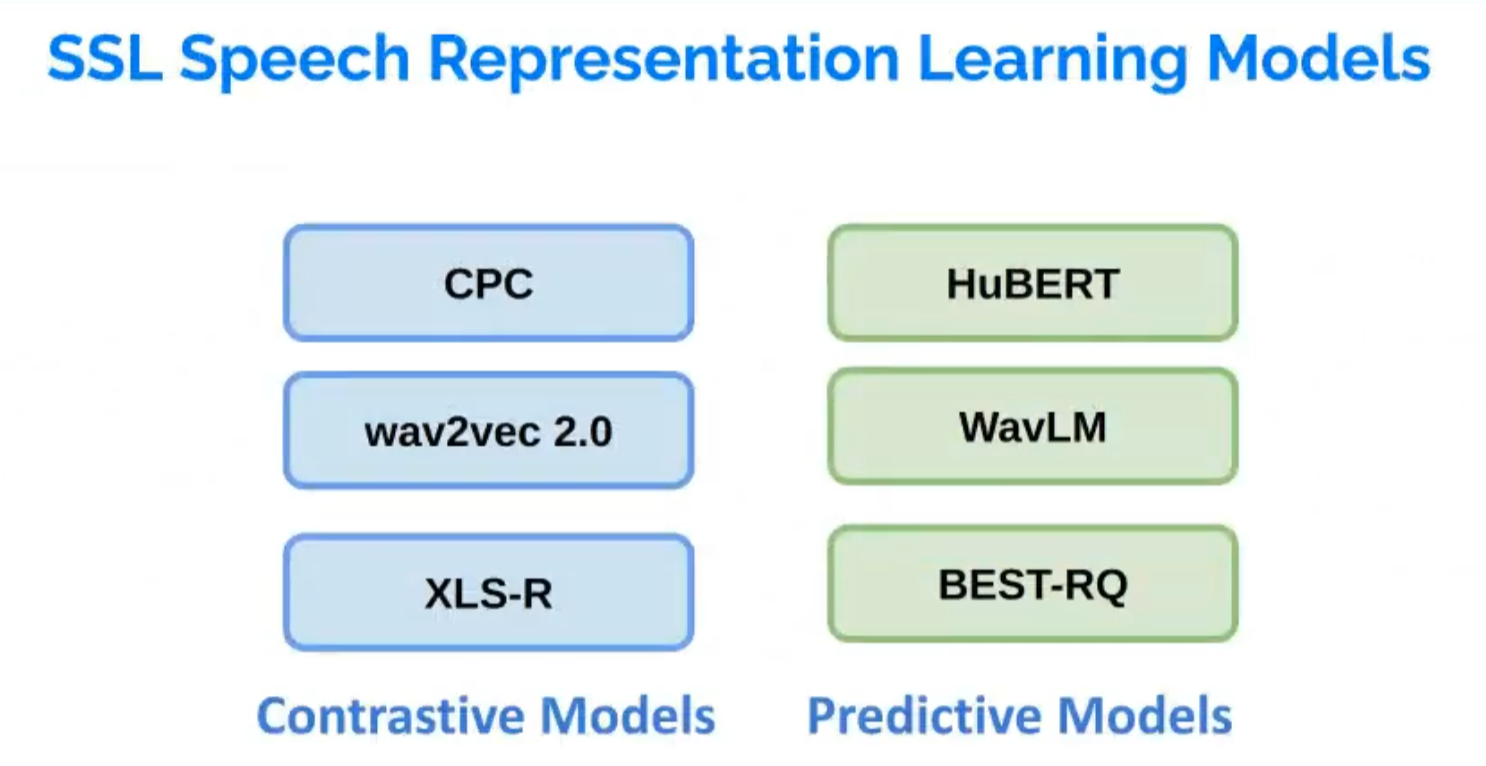
在语音模型中,对比模型(Contrastive Models)和预测模型(Predictive Models)都是用于从原始语音信号中学习有效表示的方法。它们的目标是揭示语音信号中的潜在结构和模式,以便在各种任务中(如语音识别、语音合成等)实现高性能。以下是对比模型和预测模型之间的区别和联系的概述:
对比模型(Contrastive Models):
对比模型通过比较不同的数据样本来学习数据表示。在语音表示学习中,这类方法通常利用对比损失(contrastive loss)来鼓励模型区分不同的数据点。对比模型的核心思想是,通过学习将相似的数据点映射到相近的表示,同时将不相似的数据点映射到远离的表示,可以获得具有区分性和鲁棒性的语音表示。一个典型的对比模型例子是Contrastive Predictive Coding(CPC),它将对比损失用于预测未来语音信号的表示,从而学习语音的底层结构。
预测模型(Predictive Models):
预测模型通过预测未来的数据点来学习数据表示。在语音表示学习中,这类方法通常利用预测损失(predictive loss)来鼓励模型准确地预测未来数据点。预测模型的核心思想是,通过学习数据点之间的潜在关系来预测未来的信息,可以揭示输入信号的底层结构和生成机制。基于预测的方法在自然语言处理和语音处理领域中广泛应用,例如循环神经网络(RNNs)和Transformer等模型。
区别:
对比模型主要关注区分不同数据点之间的差异,而预测模型主要关注预测未来数据点。这两种方法的损失函数和优化目标不同:对比模型使用对比损失来最大化不同类别之间的间距,而预测模型使用预测损失来最小化预测与真实值之间的误差。
联系:
尽管对比模型和预测模型的方法不同,但它们的目标是相似的:从原始数据中学习有效表示。在实际应用中,这两种方法可以结合使用,以更好地捕捉数据的结构和模式。例如,Contrastive Predictive Coding(CPC)模型就结合了对比和预测的方法,它使用对比损失来优化预测未来数据点的表示。
总之,对比模型和预测模型都是在语音模型中学习有效表示的方法。虽然它们关注的方面不同,但它们可以结合使用以更好地揭示原始语音信号中的潜在结构和模式。
1.wav2vec 2.0
论文:wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
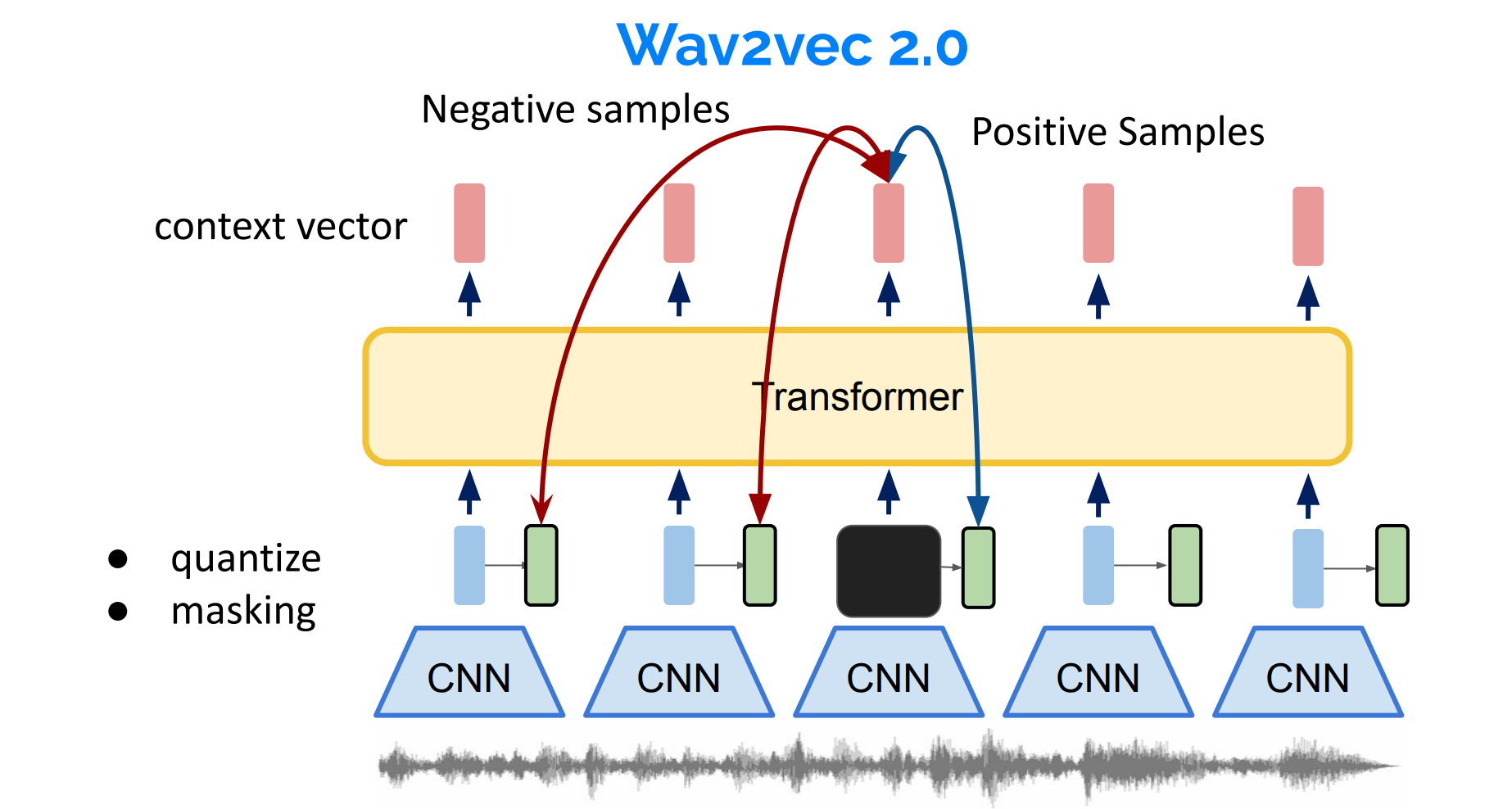
Wav2Vec 2.0 是一种基于自监督学习的语音表示学习模型,由 Facebook AI 在 2020 年提出。该模型旨在从原始音频信号中学习有效表示,这些表示可用于各种语音处理任务,例如自动语音识别(ASR)。Wav2Vec 2.0 的关键创新在于它可以在没有大量标记数据的情况下学习到有竞争力的表示。这对于低资源语言和应用领域尤为重要,因为手动标记数据的成本很高。
Wav2Vec 2.0 的架构分为两个主要部分:
- 特征提取器(Feature Extractor):特征提取器是一个卷积神经网络(CNN),它将原始音频信号作为输入,并将其映射到连续的潜在表示。这些表示被称为潜在语音(Latent Speech)。特征提取器的目标是捕捉音频信号中的关键信息,以便在后续步骤中进行处理。
- Context Network(上下文网络):上下文网络是一个Transformer模型,它将特征提取器提取的潜在语音作为输入,并学习预测未来音频表示。上下文网络使用对比损失来区分正确的未来预测(正例)和错误的未来预测(负例)。
Wav2Vec 2.0 的训练过程分为两个阶段:预训练和微调。在预训练阶段,模型通过大量无标签音频数据学习有效表示。在微调阶段,使用较小的标记数据集(如语音转录)来调整模型的参数,以便在特定任务(如语音识别)中实现更好的性能。
Wav2Vec 2.0 在各种语音识别基准测试中表现出了高性能,尤其是在低资源设置中。这表明,Wav2Vec 2.0 对于减少对标记数据的依赖以及在各种语言和领域中实现可扩展性具有巨大潜力。
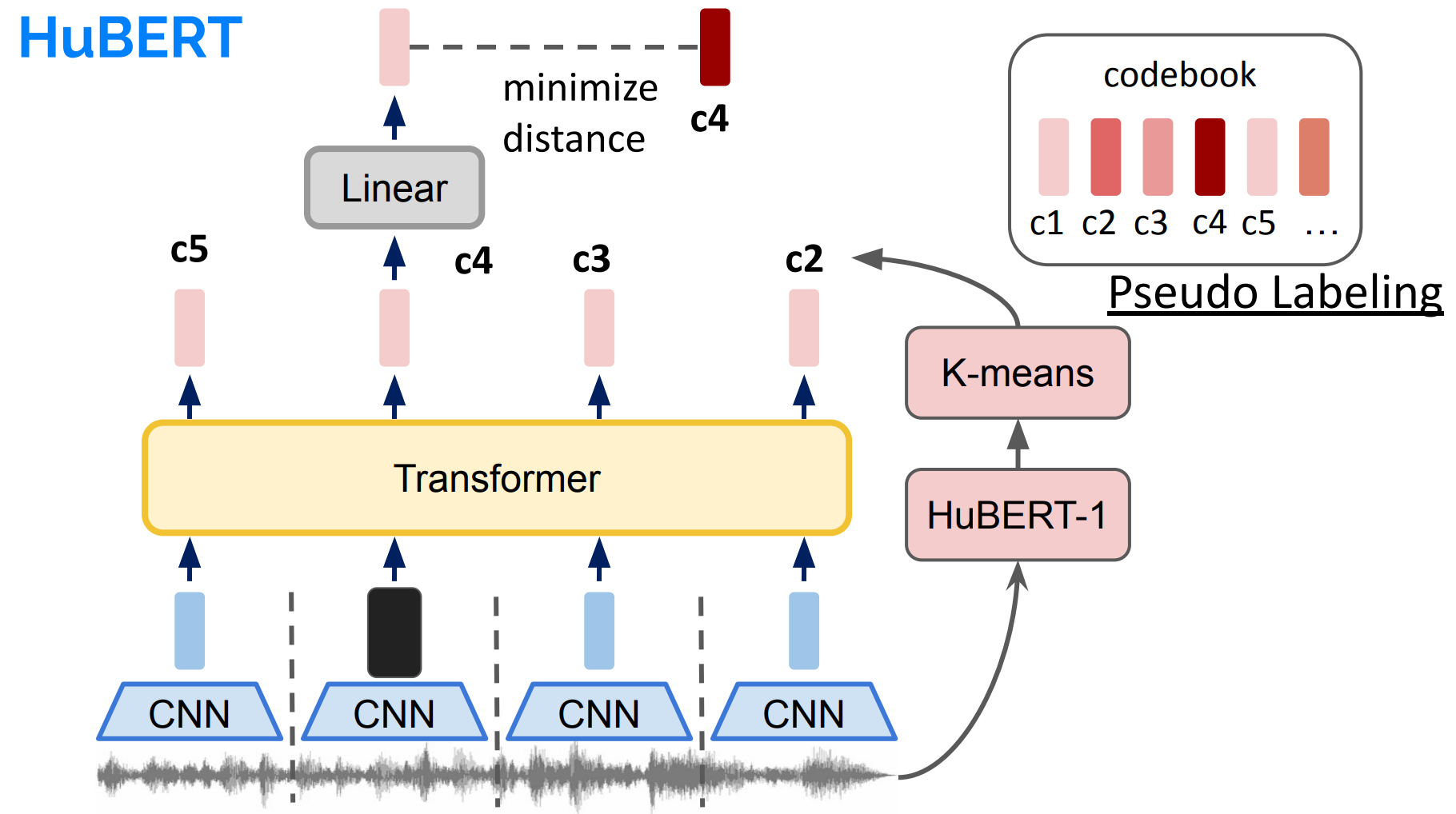
2.Hubert
BERT 和 HuBERT 分别是自然语言处理(NLP)领域和语音处理领域的两个自监督学习模型。以下是它们之间的区别和联系的概述:
BERT(Bidirectional Encoder Representations from Transformers):
BERT 是一个用于自然语言处理任务的预训练 Transformer 模型,由 Google AI 于 2018 年提出。BERT 的主要创新在于采用了掩码语言建模(Masked Language Modeling)任务来学习上下文相关的词嵌入。在 BERT 中,单词被随机地替换为特殊的掩码符号,模型需要根据上下文预测这些掩码单词。事实证明,这种方法可以捕捉到文本数据中非常丰富的上下文信息。
HuBERT(HugeBERT,实际上是对 "huge BERT" 的缩写,不过也可以理解为 "Human-like BERT"):
HuBERT 是一个用于语音处理任务的预训练 Transformer 模型,由Facebook AI 于 2021 年提出。HuBERT 的设计灵感来源于 BERT 的成功。与 BERT 相比,HuBERT 将预训练的 Transformer 用于原始音频数据(而不是文本数据)。HuBERT 的目标是学习从原始音频信号到底层声学-语音特征的映射,用于各种语音任务,如自动语音识别(ASR)、说话者识别等。
区别:
- 领域:BERT 主要用于自然语言处理任务,例如情感分析、命名实体识别和问答系统等。而 HuBERT 则用于语音处理任务,例如语音识别、说话者识别和情感识别等。
- 输入数据:BERT 使用文本数据作为输入,而 HuBERT 使用原始音频数据作为输入。
联系:
- 都是基于 Transformer 的自监督学习模型,采用预训练和微调的策略。
- 模型训练方法具有相似之处。BERT 通过掩码语言建模任务学习上下文相关的词嵌入,HuBERT 通过与 BERT 类似的自监督任务在语音领域获得表现良好的表示。
总之,BERT 和 HuBERT 分别是自然语言处理和语音处理领域的自监督预训练模型。它们都基于 Transformer 架构,并具有相似的训练方法。但是,它们在输入数据和应用领域方面有所不同。
SUPERB测试
SUPERB(Speech Understanding and Perceived Region Benchmarks)是一个多任务基准测试,用于评估自监督学习语音模型在多个任务上的通用性能。SUPERB 包括了一系列语音处理任务,旨在测试模型在各种语音场景下的性能。这些任务包括但不限于:
- 自动语音识别(ASR):将音频转换成文本序列。
- 说话者识别(SID):识别说话者的身份。
- 说话者验证(SV):验证说话者声称的身份是否正确。
- 语音命令识别(KWS):识别预定义的关键词或短语。
- 声学-语言单位检测(QbE):在给定的音频中检测音素或音节的存在。
- 情感识别(ER):识别音频中的情感表达。
- 对话语音充分理解(DS):识别音频中任务相关的关键信息。
SUPERB 的设计目标之一是帮助研究人员和开发者评估不同的自监督学习语音模型的通用性能。通过在多个任务上进行无监督或自监督的预训练和微调,模型可以学习从原始音频信号到更高级语义表示的映射,从而在各种场景中实现出色的性能。
与其他基准测试类似,SUPERB 提供了一个公共平台,研究人员可以在该平台上比较不同模型的性能,从而推动语音技术的发展。此外,SUPERB 还有助于了解语音模型的通用性和适应性,为实际应用提供参考。

一些有趣的发现:模型越大效果越好;在其他任务上效果比较好的模型,在语音任务上效果一定也好。
二、语音大语言模型
Textless NLP
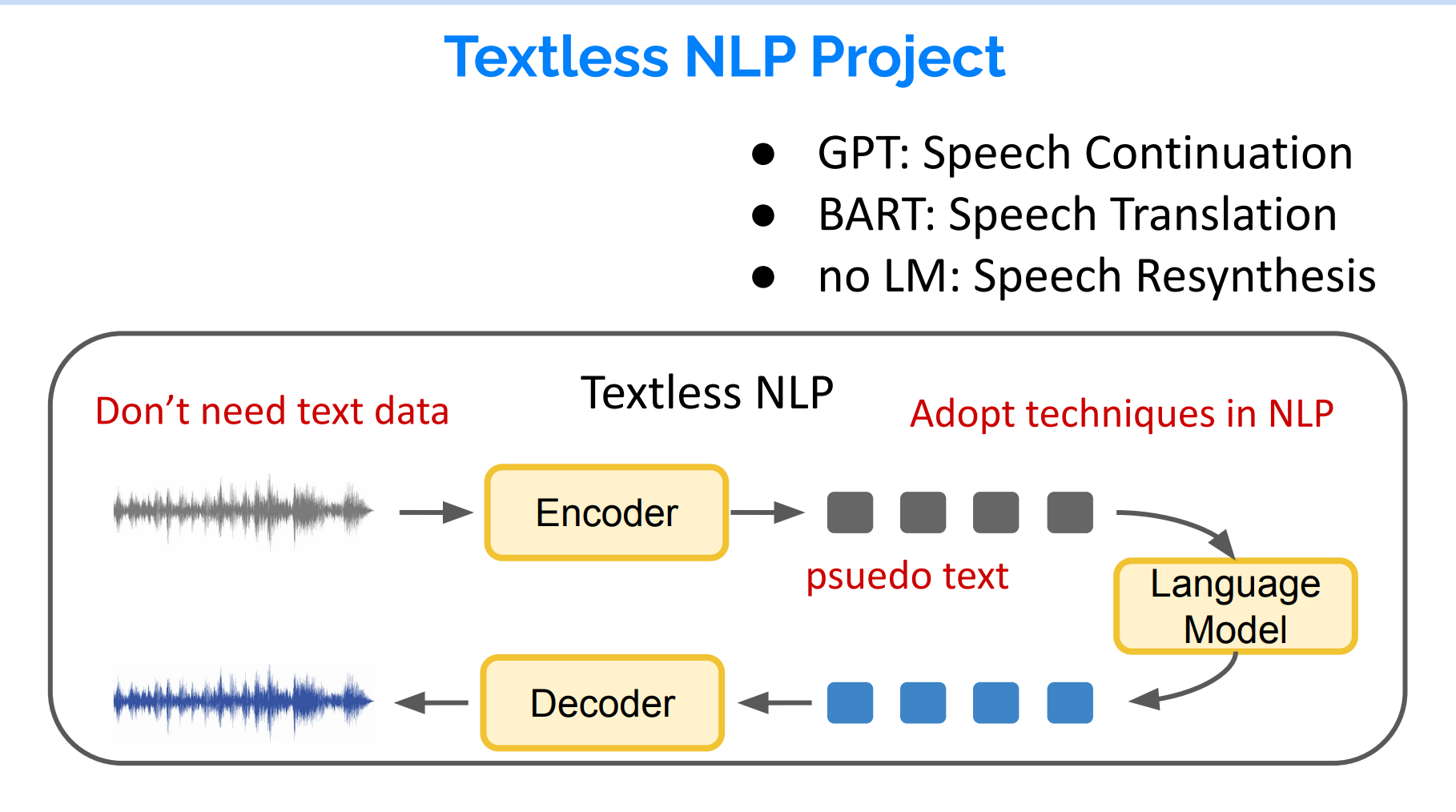
Textless NLP(无文本自然语言处理)指的是直接在原始音频数据上进行自然语言处理任务的方法,而无需将音频数据转换为文本。Textless NLP 的目标是开发能够直接理解和处理音频信号的模型,以实现更直接、更精确的语音信息处理。
在传统的自然语言处理(NLP)任务中,通常先将音频数据转换为文本,然后再应用 NLP 技术。这种方法可能会导致信息丢失,因为音频中的一些关键信息(如说话者的语调、情感以及口音等)在转换为文本时可能无法保留。Textless NLP 直接处理原始音频数据,以便在处理过程中捕捉到这些关键信息。
Textless NLP 的应用包括:
- 语音情感识别:在不转换为文本的情况下,直接从音频信号中识别说话者的情感(例如,快乐、悲伤或生气)。
- 说话者识别和验证:识别或验证说话者的身份,而无需将音频转换为文本。
- 音频关键词检测:直接在音频信号中识别预定义的关键词或短语。
Textless NLP 的一些关键技术包括深度学习模型(如卷积神经网络和循环神经网络)和自监督学习方法(如 Wave2Vec 和 HuBERT 等)。总之,Textless NLP 是一种在原始音频数据上直接进行自然语言处理任务的方法,具有更直接、更精确的语音信息处理优势。
重要指标temperature
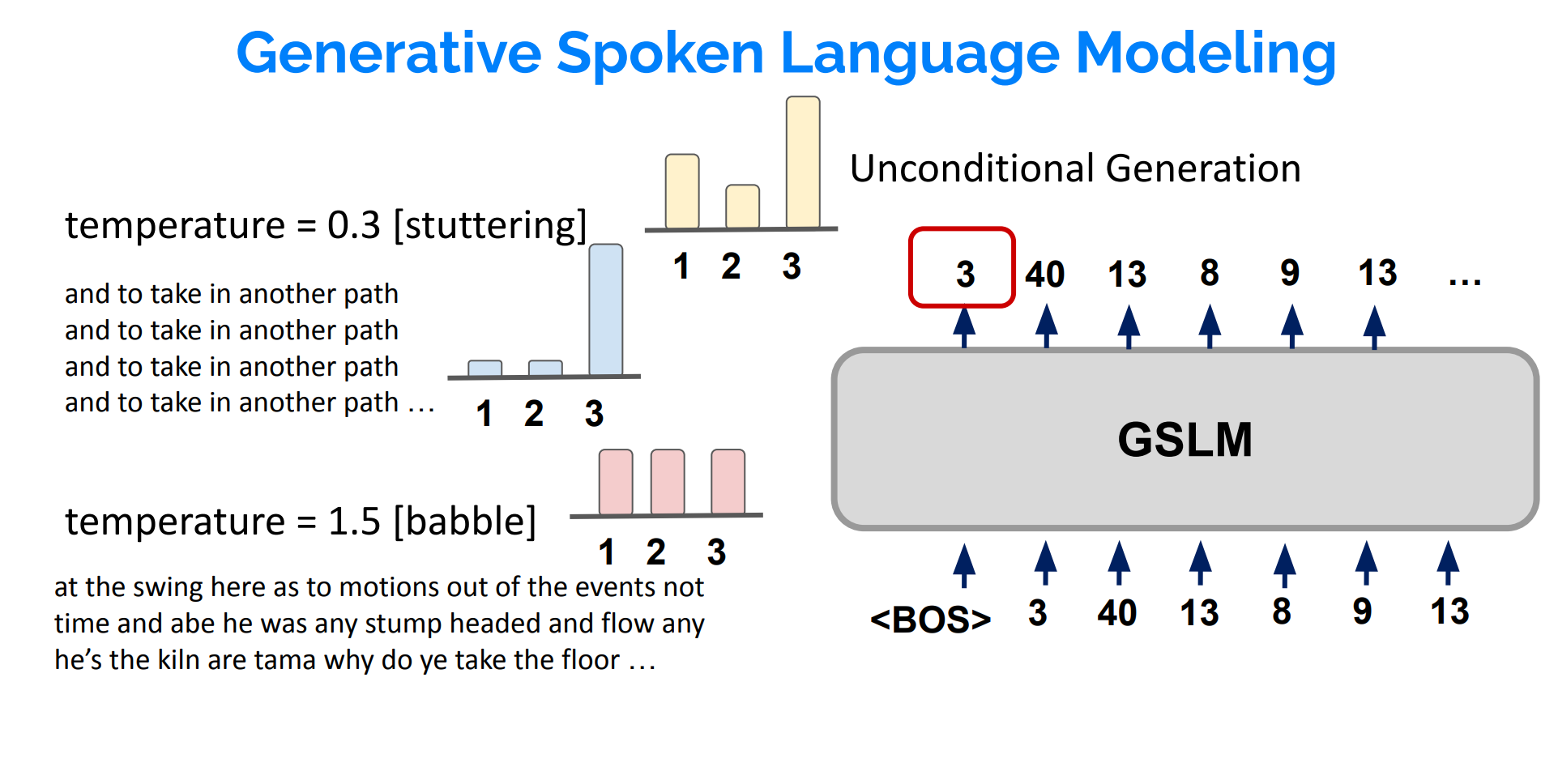
当temperature越大,生成结果的多样性就越大;反之,生成结果的多样性就越小。
AudioLM
AudioLM 是一种基于音频数据的语言模型,它通过学习音频数据的潜在结构和信息来实现自然语言处理任务。与传统的基于文本的语言模型不同,AudioLM 直接针对原始音频信号进行学习,从而更好地捕获音频中的丰富信息,如说话者的口音、语调、情感以及发音等。
AudioLM 的核心思想是以无监督或自监督的方式从大量未标记的音频数据中学习音频表示。这些表示可以捕获到音频信号中的各种语义、声学和语言信息。然后,AudioLM 利用这些表示来实现各种自然语言处理任务,如自动语音识别(ASR)、说话者识别(SID)、情感识别(ER)等。
实现 AudioLM 可以采用诸如卷积神经网络(CNN)、循环神经网络(RNN)以及Transformer 等深度学习模型。近年来,基于音频的自监督学习模型(如 Wave2Vec 和 HuBERT 等)已经取得了重要进展,并在多个任务上实现了出色的性能。
总之,AudioLM 是一种基于音频数据的语言模型,在直接处理音频信号的同时,捕获音频中的丰富信息。AudioLM 通过无监督或自监督学习方法提取音频表示,应用于自然语言处理任务。
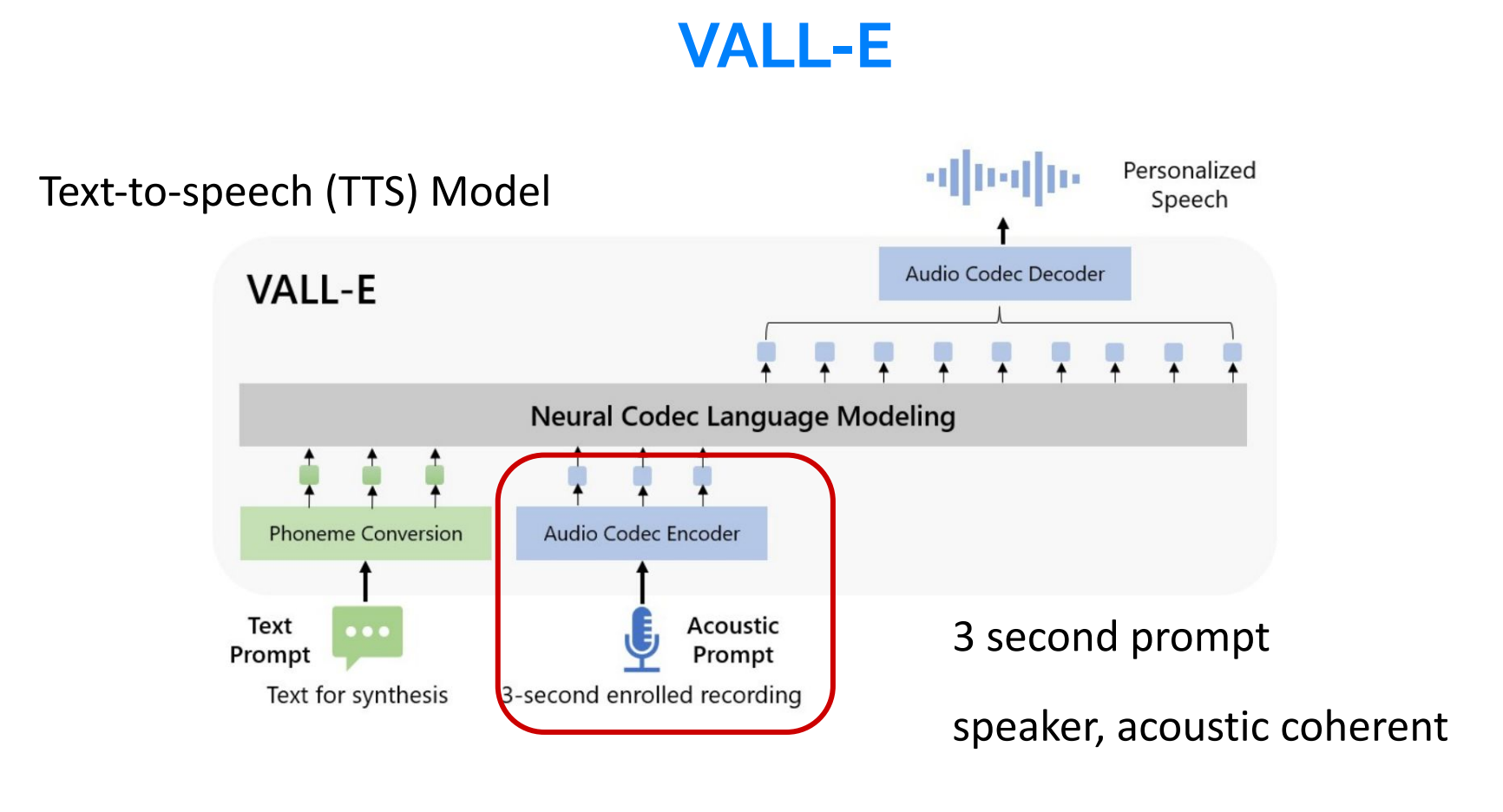
VALL-E
微软称VALL-E为“神经编解码器语言模型”,它建立在Meta于2022年10月宣布的一项名为EnCodec的技术之上。与其他通常通过操作波形合成语音的文本转语音方法不同,VALL-E从文本和声学提示生成离散音频编解码器代码。它基本上分析一个人的声音,通过EnCodec将这些信息分解成离散的组件(称为“令牌”),并使用训练数据来匹配它“知道”的声音,如果它说的是三秒样本之外的其他短语,声音会是什么样子。
为了合成个性化语音(例如,zero-shot TTS),VALL-E生成相应的声学令牌,条件是3秒注册录音和音素提示的声学令牌,分别约束扬声器和内容信息。最后,使用生成的声学标记与相应的神经编解码器解码器合成最终波形。
三、其他语音模型
Whisper
Whisper 是 OpenAI 推出的一种大规模自动语音识别系统(ASR)。它是一个深度学习模型,通过在大量多语言和多领域的音频数据上进行训练,实现了对音频信号中的人类语言的精确识别和转录。Whisper 主要应用于将人类语音转换为文本,为自然语言处理(NLP)任务提供数据来源。
Whisper 的一些主要特点和优势包括:
- 大规模训练:Whisper 在大量音频数据上进行训练,以捕捉世界各地多种语言、口音和说话风格的信息。
- 高性能:经过大规模训练和优化后,Whisper 能够实现高精度的语音识别和转录,为各种 NLP 任务提供可靠的文本输入。
- 适用于多种应用场景:Whisper 可以应用于智能助手、语音搜索、语音翻译、语音输入法、会议记录、客户服务系统等多种场景。
Whisper 是 OpenAI 为解决自动语音识别问题而推出的技术解决方案,通过大规模的训练和深度学习技术实现对音频信号中的人类语言的精确识别和转录。
USM
Universal Speech Model(通用语音模型,USM)是一种旨在处理广泛语音任务的通用模型。USM 通过在大量音频数据上进行训练,学习声音信号中的共享表示。这种表示旨在捕捉各种声音、语言、口音和背景噪声等多样化信息。
通用语音模型的目标是,通过单一的大型模型,为多种语音任务提供统一的解决方案。这些任务可能包括自动语音识别、语音合成、发音评估、说话者识别、情感识别等。
USM 的优势在于:
- 经济高效:通过使用单一的通用模型,可以减少不同任务之间重复的训练成本和计算资源需求。
- 泛化能力:经过大规模训练,通用语音模型可以适应多种语言、口音和说话风格,使其具有良好的泛化能力。
- 可扩展性:通用语音模型为不同任务提供统一的基础架构,可以方便地扩展到新的任务或应用场景。
然而,通用语音模型面临着一些挑战,如如何结合多个语音任务的损失函数、如何平衡各任务之间的权重以及如何在有限的计算资源下实现大规模模型训练等。
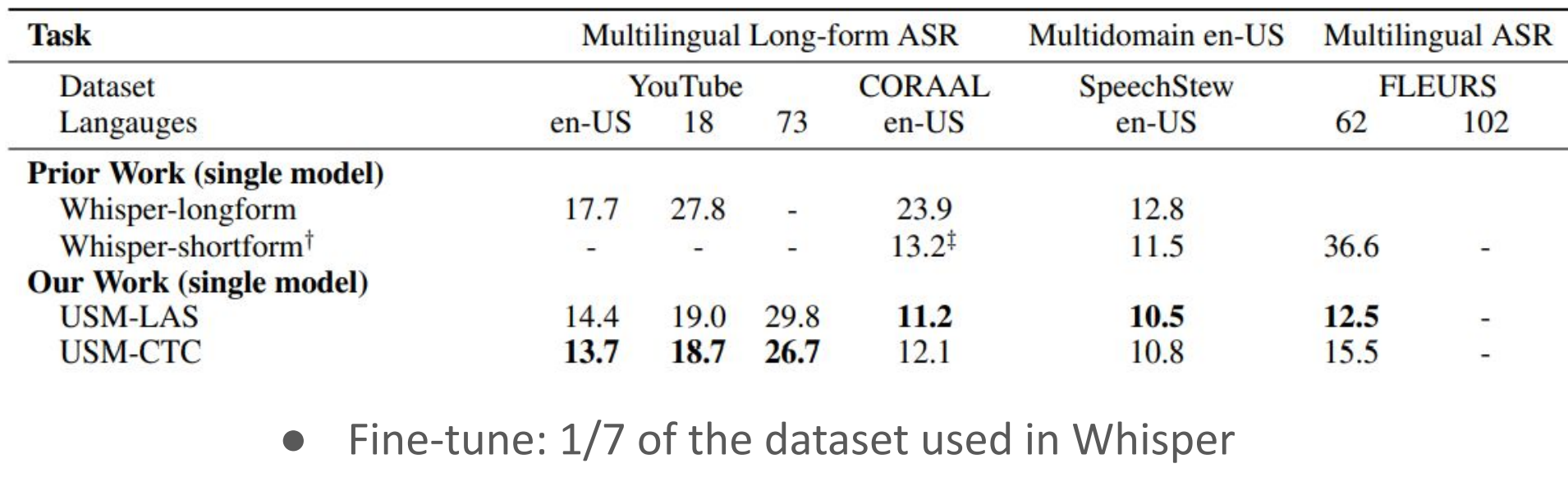
总之,通用语音模型(USM)是一种旨在处理多种语音任务的模型。通过在大量音频数据上进行训练,USM 学习声音信号中的共享表示,并在自动语音识别、语音合成等多种任务上实现高性能。



















 313
313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











