







使用pytorch/torchrl和mujoco实现强化学习PPO算法
目录
0.实验目的
使用torchrl框架,实现PPO算法,训练mujoco机器人。以下是我的实验环境配置(仅供参考)。
电脑操作系统:windows11
conda环境(python=3.8)相关pip包版本:
gym=0.25.2
mujoco=2.2.0
numpy=1.23.5
pydeps=1.12.17
pygame=2.5.2
setuptools=63.2.0
tensordict-nightly=2023.1.12
torch=1.13.1+cu116
torchaudio=0.13.1+cu116
torchrl-nightly=2023.1.30
typer=0.9.0
typing_extensions=4.8.0
wheel=0.36.0
yapf=0.40.2
zipp=3.17.0
1.安装torch和torchrl和mujoco
(1)torch安装
torch按照自己的CUDA版本和conda环境的Python版本选择合适的安装就可以。如果要安装的不是最新版本torch,可以直接从torch的whl下载链接下载whl到本地,在本地激活了conda环境之后,pip install 本地whl路径 。
(2)torchrl安装
torchrl在win11上安装有些不同,不能pip install torchrl,win11需要安装的是torchrl-nightly,安装命令pip install torchrl-nightly,相对应的,tensordict也需要安装tensordict-nightly版本。
如果是macos或者是liunx系统,这一步安装建议直接按照github官方说明。
torchrl的github链接
(3)mujoco安装
mujoco直接pip install mujoco,注意不是安装mujoco_py,mujoco是deepmind发行的全新版本。安装mujoco那么gym的版本就不能太低(嫌麻烦可以直接pip install gym==0.26.0),太低版本的gym即便对接了mujoco,也没有完全封装好。
mujoco_py的安装很麻烦,我尝试了好几天没有安装成功,根据部分博主建议最好使用python=3.7的环境尝试。
2.实验设置
(1)mujoco游戏
这篇文章使用到的mujoco游戏有InvertedDoublePendulum-v4和InvertedPendulum-v4,因为我主要参考的torchrl官网PPO算法教程的代码,所以选择了状态空间和动作空间都连续的env环境。你也可以使用其他游戏尝试新的算法。
两个游戏的官网介绍链接:Gymnasium Documentation
(2)PPO算法
PPO算法是一个on-policy算法,这里不多做介绍,为了训练PPO算法的时候效果更好,用到了以下几个技巧(一般RL开源算法库都会这么做)。
- GAE广义优势函数估计
- 经验回放(Experience Replay)
- 经验回放是通过保存每个训练轮次(epoch)中的轨迹(trajectories)来实现的。这里PPO经验回放不是DQN的replay buffer形式,on-policy算法的经验回放只会使用同策略的经验,换言之,一旦策略已经更新,旧的经验就不能使用了,DQN却不是。
- 梯度截断
3.代码
torchrl官网教程:
REINFORCEMENT LEARNING (PPO) WITH TORCHRL TUTORIAL
注意 :笔者的代码和torchrl官方的PPO算法tutorial代码略有不同,不同的原因在于,官方的教程把policy和env的交互封装在datacollector中,这样做虽然训练很方便,但是不便于我后续更改用于其他自定义Env环境和拓展代码,所以我把policy和env的交互部分专门独立出来了。没有这个需求的可以直接学习官方tutorial的代码,讲解的很详细。
代码一共三个文件,放在同一个文件夹下面:
- utils.py 一些自定义的功能函数
- algo.py 基类class文件
- algo_ppo.py 实验主要文件
(1)utils.py
import gym
from tensordict import TensorDict
import torch
import datetime
def is_env_registered(env_id):
try:
gym.envs.registration.spec(env_id)
return True
except gym.error.UnregisteredEnv:
return False
def get_time_diff(start):
time_diff = datetime.datetime.now() - start
# 提取小时、分钟和秒
hours = time_diff.seconds // 3600
minutes = (time_diff.seconds // 60) % 60
seconds = time_diff.seconds % 60
# 打印时间差
return "{:02d}:{:02d}:{:02d}".format(hours, minutes, seconds)
(2)algo.py
from tensordict.nn import TensorDictModule
from tensordict import TensorDict
from torchrl.data.replay_buffers import ReplayBuffer
from torchrl.data.replay_buffers.storages import LazyTensorStorage, ListStorage
from torchrl.data.replay_buffers.samplers import SamplerWithoutReplacement
import torch
# RL算法的config基类
class AlgoConfig(dict):
def __init__(self, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
self.validate()
pass
def validate(self):
pass
# PPO的经验回放基类
class MyBuffer(ReplayBuffer):
def __init__(
self,
storage=None,
sampler=None,
writer=None,
collate_fn=None,
pin_memory=False,
prefetch=None,
transform=None,
):
super(MyBuffer, self).__init__(storage=storage,
sampler=sampler,
writer=writer,
collate_fn=collate_fn,
pin_memory=pin_memory,
prefetch=prefetch,
transform=transform, )
def clear(self, max_size=None, device=None):
# 清空replay buffer存储数据的函数,因为PPO算法是on-policy算法,模型参数一旦更新,就不能用旧参数的数据了
print("[INFO] Clearing the buffer.")
if device is None:
self._storage = LazyTensorStorage(max_size=max_size, device=device)
else:
self._storage = LazyTensorStorage(max_size=max_size)
self._writer._cursor = 0
self._writer.register_storage(self._storage)
if __name__ == "__main__": # 测试用到的代码,正常的话不会报错
my_buffer = MyBuffer(
storage=LazyTensorStorage(1000),
sampler=SamplerWithoutReplacement()
)
my_buffer._len = 0
data = TensorDict(
{
"a": torch.arange(8).view(2, 4),
("b", "c"): torch.arange(10).view(2, 5),
},
batch_size=[2],
)
my_buffer.extend(data)
print(my_buffer.state_dict())
my_buffer.clear(1000)
print(my_buffer.state_dict())
my_buffer.extend(data)
print(my_buffer.state_dict())
(3)algo_ppo.py
# -*- coding: utf-8 -*-
# @File name : algo_ppo.py
import matplotlib.pyplot as plt
import torch
from tensordict.nn import TensorDictModule
from tensordict import TensorDict
from tensordict.nn.distributions import NormalParamExtractor
from torch import nn
from torchrl.data.replay_buffers.samplers import SamplerWithoutReplacement
from torchrl.data.replay_buffers.storages import LazyTensorStorage
from torchrl.envs import (Compose, DoubleToFloat, ObservationNorm, StepCounter,
TransformedEnv)
from torchrl.envs.libs.gym import GymEnv
from torchrl.envs.utils import check_env_specs
from torchrl.modules import ProbabilisticActor, TanhNormal, ValueOperator
from torchrl.objectives import ClipPPOLoss
from torchrl.objectives.value import GAE
from utils import *
from algo import AlgoConfig, MyBuffer
from constants import *
import datetime
# ENV_NAME = "InvertedDoublePendulum-v4"
ENV_NAME = 'InvertedPendulum-v4'
# 设置随机种子
seed = 114
# random.seed(seed)
# np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
class PPOConfig(AlgoConfig):
def __init__(self) -> None:
self.device = "cpu" if not torch.cuda.is_available() else "cuda:0"
# env settings
self.env_actions_continous = True
self.env_obs_continous = True
# model learning settings
self.lr = 1.7e-4 # 学习率
self.clip_param = 0.2
self.lambda_ = 0.95 # GAE参数
self.gamma = 0.98 # 折扣因子
# PPO train config
self.frames_per_batch = 1000
# PPO minibatch config per frames_per_batch
self.minibatch_size = 128 # 64
self.num_epochs = 6 # 10
# PPO loss config
self.entropy_eps = 1e-4
self.clip_epsilon = 0.2
# model setting
self.value_hid_size = [256, 512, 256]
self.policy_hid_size = [256, 512, 256]
self.actions_activation = [nn.Tanh(), nn.Tanh(), nn.Tanh()]
self.value_activation = [nn.Tanh(), nn.Tanh(), nn.Tanh()]
super(PPOConfig, self).__init__()
def validate(self):
super().validate()
if utils.is_env_registered(ENV_NAME):
base_env = GymEnv(ENV_NAME, device=self.device)
print("Create environment successfully!")
else:
print("Create environment failed!")
return
try:
self.env = TransformedEnv(
base_env,
Compose(
# normalize observations
ObservationNorm(in_keys=["observation"], ),
DoubleToFloat(in_keys=["observation"]),
StepCounter(),
),
)
except Exception:
return
self.env.transform[0].init_stats(num_iter=1000, reduce_dim=0, cat_dim=0)
try:
check_env_specs(self.env)
print("check_env_specs successfully!")
except Exception:
print("check_env_specs failed!")
return
self.env_obs_dim = self.env.reset().get("observation").shape[0]
self.env_obs_spec = self.env.observation_spec
self.env_actions_spec = self.env.action_spec
self.env_actions_dim = self.env.action_spec.ndim
self.env_reward_dim = self.env.reward_spec.ndim
class PPO():
def __init__(self, configer: AlgoConfig):
self.configer = configer
self.env = configer.env
self.device = configer.device
self.policy = self.create_policy()
self.value = self.create_critic()
# ----------initialize the network----------
self.policy(self.env.reset())
self.value(self.env.reset())
# ------------------------------------------
self.replay_buffer = MyBuffer(
storage=LazyTensorStorage(self.configer.frames_per_batch),
sampler=SamplerWithoutReplacement(),
)
self.advantages = GAE(
gamma=self.configer.gamma,
lmbda=self.configer.lambda_,
value_network=self.value,
average_gae=True
)
self.loss = ClipPPOLoss(
actor=self.policy,
critic=self.value,
advantage_key="advantage",
clip_epsilon=self.configer.clip_epsilon,
entropy_bonus=bool(self.configer.entropy_eps),
entropy_coef=self.configer.entropy_eps,
# these keys match by default but we set this for completeness
value_target_key=self.advantages.value_target_key,
critic_coef=1.0,
gamma=0.99,
loss_critic_type="smooth_l1",
)
self.optimizer = torch.optim.Adam(self.loss.parameters(), self.configer.lr)
def create_policy(self):
layers = []
for i in range(len(self.configer.policy_hid_size)):
if i != len(self.configer.policy_hid_size) - 1:
layers.append(nn.LazyLinear(self.configer.policy_hid_size[i], device=self.device))
layers.append(self.configer.actions_activation[i])
else:
layers.append(nn.LazyLinear(2 * self.configer.env_actions_dim, device=self.device))
layers.append(NormalParamExtractor())
actor_net = nn.Sequential(*layers)
actor_dict = TensorDictModule(actor_net, in_keys=["observation"], out_keys=["loc", "scale"])
if self.configer.env_actions_continous:
policy_module = ProbabilisticActor(
actor_dict,
spec=self.configer.env_actions_spec,
in_keys=["loc", "scale"],
distribution_class=TanhNormal,
distribution_kwargs={
"min": self.configer.env_actions_spec.space.minimum,
"max": self.configer.env_actions_spec.space.maximum,
},
return_log_prob=True,
)
else:
print("discrete action space is not supported yet!")
return
return policy_module
def create_critic(self):
layers = []
for i in range(len(self.configer.policy_hid_size)):
if i != len(self.configer.policy_hid_size) - 1:
layers.append(nn.LazyLinear(self.configer.value_hid_size[i], device=self.device))
layers.append(self.configer.value_activation[i])
else:
layers.append(nn.LazyLinear(1, device=self.device))
value_net = nn.Sequential(*layers)
value_module = ValueOperator(
module=value_net,
in_keys=["observation"],
)
return value_module
def do_policy(self, observation: TensorDict):
return self.policy(observation)
def compute_advantages(self, tensordict: TensorDict):
return self.advantages(tensordict)
def save_data(self, tensordict: TensorDict):
if len(self.replay_buffer) < self.configer.frames_per_batch:
self.replay_buffer.add(tensordict)
else:# 抛错误
raise RuntimeError(
"[ERROR] replay buffer is full, please recheck your replay buffer config is appropriate!")
def update_batch(self):
print(
f"[INFO] update network per batch [{self.configer.frames_per_batch} | {self.configer.minibatch_size} | {self.configer.num_epochs}...")
# print(len(self.replay_buffer))
if len(self.replay_buffer) < self.configer.frames_per_batch:
return
for _ in range(self.configer.num_epochs):
mini_batch_data = self.replay_buffer.sample(self.configer.minibatch_size)
tensordict_advantages = self.compute_advantages(mini_batch_data.to(self.configer.device))
# print(len(mini_batch_data))
loss_val = self.loss(tensordict_advantages.to(self.configer.device))
loss_value = (
loss_val["loss_objective"]
+ loss_val["loss_critic"]
+ loss_val["loss_entropy"]
)
self.optimizer.zero_grad()
loss_value.backward()
torch.nn.utils.clip_grad_norm_(self.loss.parameters(), 1.0)
self.optimizer.step()
def update_one_episode(self): # 效果不好,不建议使用
print(
f"[INFO] update network per batch [{len(self.replay_buffer)} | {len(self.replay_buffer)} | {self.configer.num_epochs}...")
for _ in range(self.configer.num_epochs):
batch_data = self.replay_buffer.sample(len(self.replay_buffer))
tensordict_advantages = self.compute_advantages(batch_data.to(self.configer.device))
loss_val = self.loss(tensordict_advantages.to(self.configer.device))
loss_value = (
loss_val["loss_objective"]
+ loss_val["loss_critic"]
+ loss_val["loss_entropy"]
)
self.optimizer.zero_grad()
loss_value.backward()
torch.nn.utils.clip_grad_norm_(self.loss.parameters(), 1.0)
self.optimizer.step()
def PPOTrainer(algo, num_episodes, average=0, draw_reward=True, render=False):
start = datetime.datetime.now()
env = algo.env
return_list = []
steps_list = []
if average != 0:
average_return = []
average_steps = []
for i_episode in range(int(num_episodes)):
episode_return = 0
state = env.reset()
done = False
i_step = 0
while not done:
i_step += 1
with torch.no_grad():
action = algo.do_policy(state)
time.sleep(.002)
tensordict_out = env.step(action)
reward = tensordict_out.get("reward")
done = tensordict_out.get("done").item()
if len(algo.replay_buffer) < algo.configer.frames_per_batch:
algo.save_data(tensordict_out)
# update state from next_state
state = tensordict_out.get("next")
episode_return += reward.item()
if (i_episode + 1) % 100 == 0 and render:
env.render()
time.sleep(0.5)
if not render and i_episode == num_episodes - 1:
env.render()
time.sleep(0.5)
return_list.append(episode_return)
steps_list.append(i_step)
if average != 0 and (i_episode + 1) % average == 0:
average_return.append(sum(return_list[-average:]) / average)
average_steps.append(sum(steps_list[-average:]) / average)
print("[%s] Episode: %d | %d, Total step: %.3f, Return: %.3f" % (utils.get_time_diff(start),
i_episode + 1, num_episodes,
average_steps[-1], average_return[-1]))
if len(algo.replay_buffer) < algo.configer.frames_per_batch:
continue
algo.update_batch()
algo.replay_buffer.clear(algo.configer.frames_per_batch)
if draw_reward:
plt.plot(return_list)
plt.title("Reward")
plt.show()
plt.plot(steps_list)
plt.title("Steps")
plt.show()
if average != 0:
plt.plot(average_return)
plt.title("Average Reward")
plt.show()
plt.plot(average_steps)
plt.title("Average Steps")
plt.show()
return return_list
if __name__ == "__main__":
ppo_configer = PPOConfig() # 配置类
# print("Env: \n", ppo_configer.env)
# print("Env observation_spec: \n", ppo_configer.env.observation_spec)
# print("Env action_spec: \n", ppo_configer.env.action_spec)
# print("Env reward_spec: \n", ppo_configer.env.reward_spec)
algo_ppo = PPO(ppo_configer) # 算法类
# print(algo_ppo.do_policy(ppo_configer.env.reset()))
# print(algo_ppo.do_value(ppo_configer.env.reset()))
PPOTrainer(algo_ppo, 3_500, average=20, draw_reward=True, render=False) # 训练
4.实验结果
(1)InvertedPendulum-v4游戏
"""以下是3.代码 algo_ppo.py文件 里面需要修改的部分"""
ENV_NAME = 'InvertedPendulum-v4'
seed = 99
# 超参数设置
self[LR] = 1.65e-4 # 学习率 1.7也行
# model setting
self.value_hid_size = [128, 128, 128]
self.policy_hid_size = [128, 128, 128]
self.actions_activation = [nn.Tanh(), nn.Tanh(), nn.Tanh()]
self.value_activation = [nn.Tanh(), nn.Tanh(), nn.Tanh()]
# PPO train config
self.frames_per_batch = 1000
# PPO minibatch config per frames_per_batch
self.minibatch_size = 128
self.num_epochs = 5
# 训练函数,注意里面的update函数选用update_batch()函数
PPOTrainer(algo_ppo, 1000, average=10, draw_reward=True, render=False)
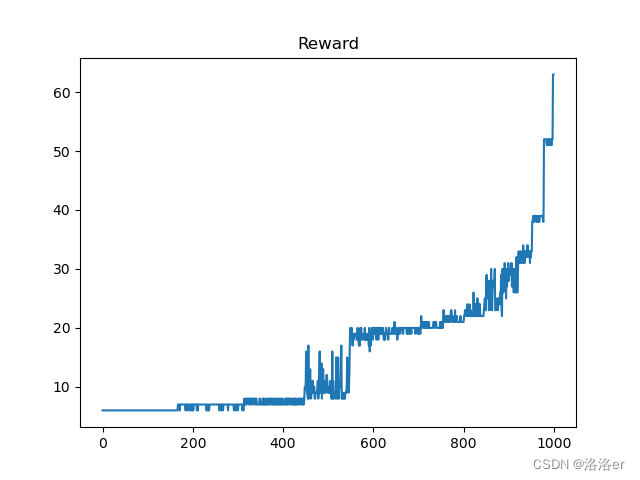
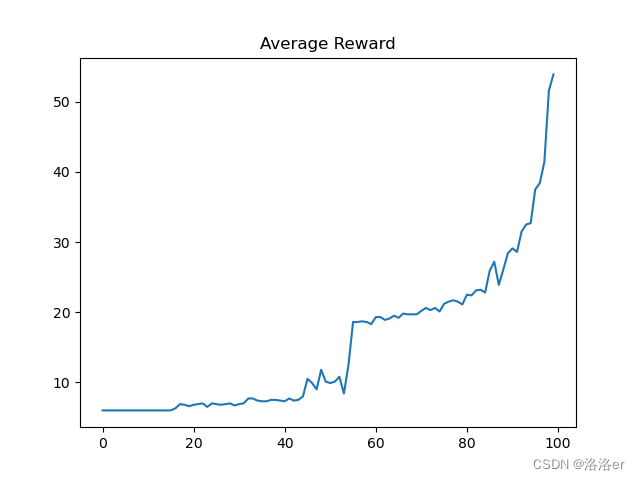
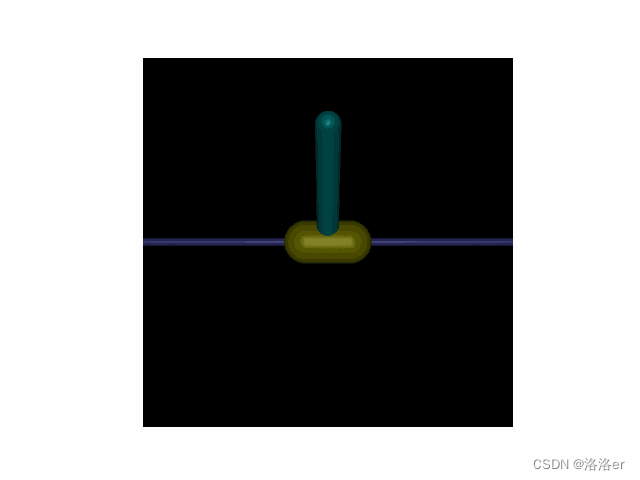
(2)InvertedDoublePendulum-v4游戏
"""以下是3.代码 algo_ppo.py文件 里面需要修改的部分"""
ENV_NAME = "InvertedDoublePendulum-v4"
seed = 99 # 随机数种子
# model learning settings
self.lr = 1.45e-4 # 学习率
# PPO train config
self.frames_per_batch = 1000
# PPO minibatch config per frames_per_batch
self.minibatch_size = 128 # 64
self.num_epochs = 6 # 10
# model setting
self.value_hid_size = [256, 256]
self.policy_hid_size = [256, 256]
self.actions_activation = [nn.Tanh(), nn.Tanh()]
self.value_activation = [nn.Tanh(), nn.Tanh()]
# 训练函数,注意里面的update函数选用update_batch()函数
PPOTrainer(algo_ppo, 4_000, average=40, draw_reward=True, render=False)
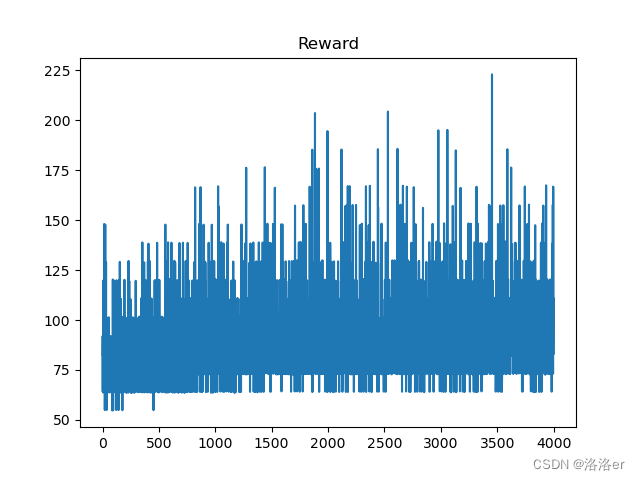
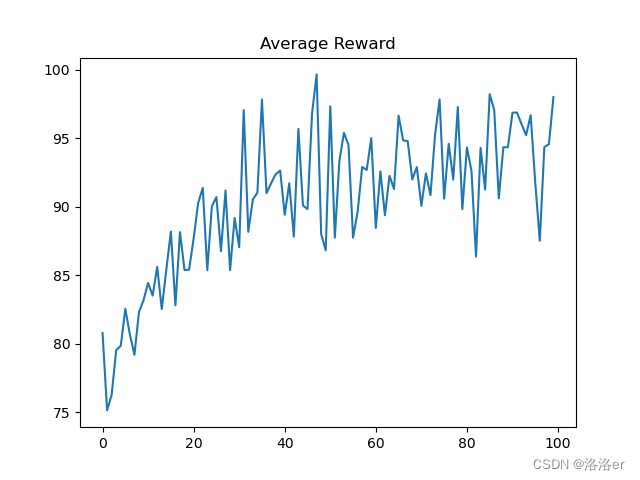
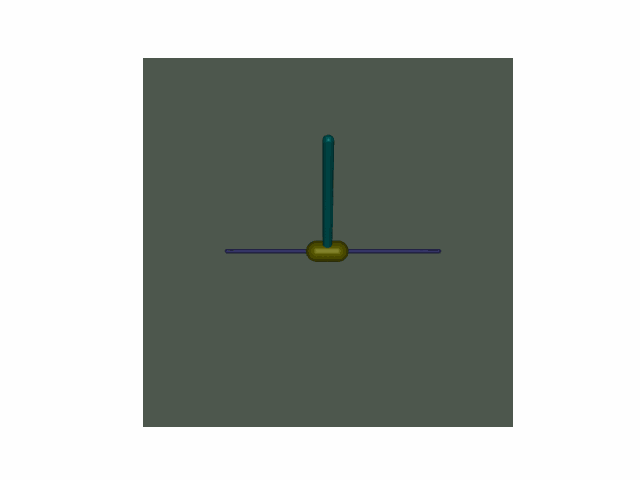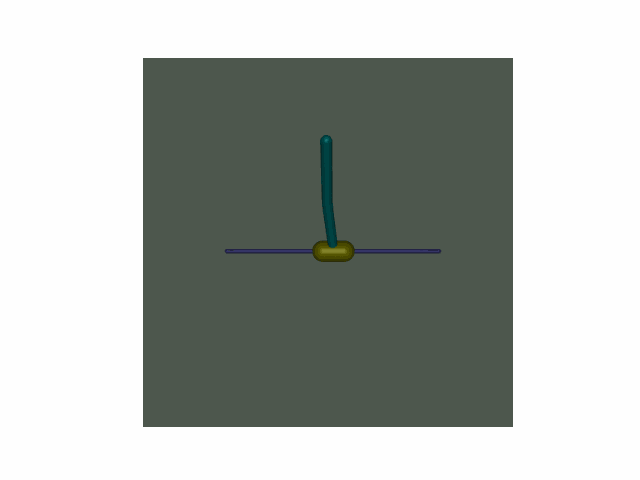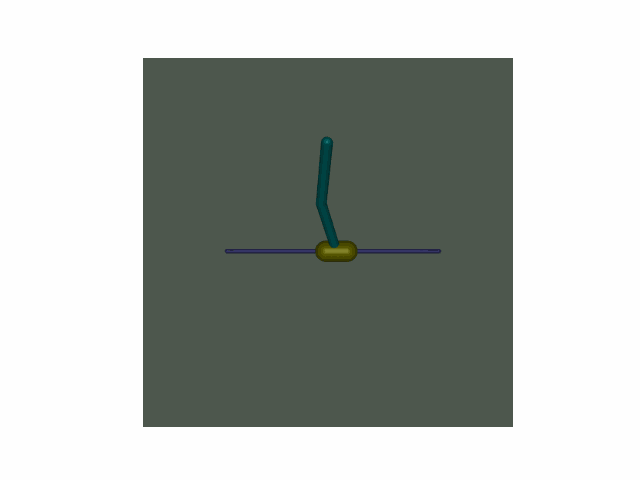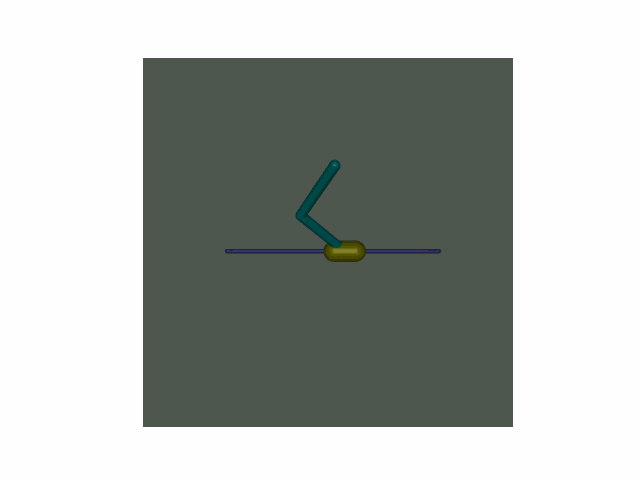
由于一些我不知道的原因,导致算法在选定的超参数下,每次跑出来的结果都有可能不一样,时好时坏,所以超参数仅供参考,你可以自己动手调整试试。
5.遇到的问题和总结
(1)mujoco安装测试
鉴于mujoco_py安装实在是太困难,总是会有各种错误,所以最后安装最新发行的mujoco搭配高版本的gym使用(高版本的gym已经在很多游戏上可以兼容mujoco或者mujoco_py)。
参考教程:配置Mujoco环境
如果安装的mujoco版本是我使用的版本,测试mujoco的代码和参考链接里面稍有改动,完整测试代码如下,测试之前记得下载humanoid.xml文件,和这个py文件放到同一路径。
from gym.envs.mujoco import MujocoEnv
class MyEnv(MujocoEnv):
def __init__(self):
self.metadata = {
'render_modes': [
"human",
"rgb_array",
"depth_array",
# 如果gym=0.25.2,需要放开这两行代码,但是实测没有画面,不知道什么原因,但前面的实验
# 如果gym=0.26.0,这两行注释掉就行
# "single_rgb_array",
# "single_depth_array",
],
'render_fps': 333 # 要跟xml中帧率保持一致
}
super().__init__("humanoid.xml", 1, None, "human") # xml文件位置, 每个action下仿真的步数, 状态空间, 渲染模式
if __name__ == "__main__":
env = MyEnv()
while True:
env.render()
如果安装正确,那么运行这段代码,你会看到mujoco窗口。

(2)torchrl安装
注意:由于我自己电脑的cuda版本是11.6,torch版本我最高只能安装1.13,所以导致可以适配的tensordict-nightly和torchrl的版本比较低:
- tensordict-nightly=2023.1.12
- torch=1.13.1+cu116
- torchrl-nightly=2023.1.30
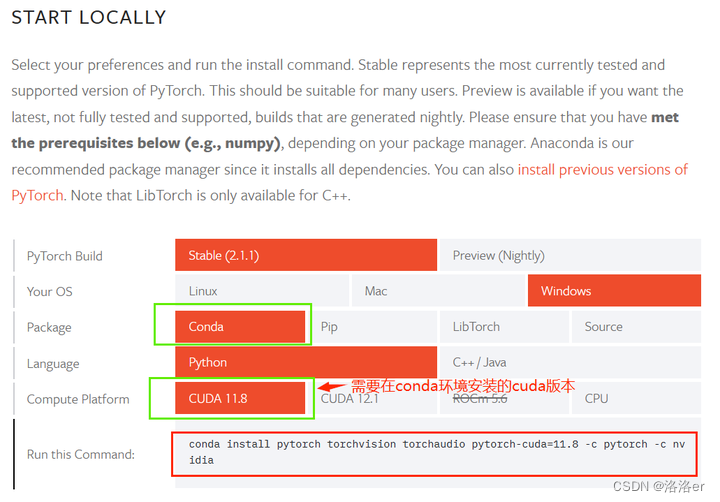
后来,根据一些博主的文章,即使自己的电脑安装CUDA版本比较低,也可以安装高版本torch,只要在conda环境安装torch时使用pytorch官网提供的conda命令就可以,这也可以保证能够跟随torchrl和tensordict官方更新版本。需要的伙伴可以试试看,亲测可以成功,而且torchrl和tensordict都不需要安装nightly版本。
(3)超参数设置
InvertedPendulum-v4的参数我调了很久,效果不是很好,最好的效果是单次episode的步数在150step,然后训练结果就会衰退。主要调整的参数是policy_hid_size、actions_activation、value_hid_size、value_activation、mini_batch、num_epochs和lr,其他的参数我没有调整,可能是其他参数导致的效果不好。
InvertedDoublePendulum-v4的调整的参数和InvertedPendulum-v4 类似。
如果使用mini_batch,那么可能训练以step的总数而不是episode的总数为训练单位会更合适,我后面调参训练意识到这个,但是懒得改代码了。
(4)总结
做这个实验,前后用了10天左右的时间,配置环境就用了3天。torchrl是2023年左右新出来的框架,其实很多开源RL算法库做的都很好,但是它们封装的太完美使得很多部分都是摸不到的黑匣子,对于我这样对机器学习框架了解不多的小白来说,自己动手修改搭建很难,代码出错甚至不知道如何修改bug,这也是为什么我要用torchrl来做这个实验。
之前一直在学习RL理论,但是动手实践调参还是第一次。希望我的这篇文章能够对你有所帮助。
============================================================================================
文章到这里就结束了,笔者水平有限,欢迎看到这篇文章的RL人在评论区交流,如果你喜欢这篇文章,期待你的点赞关注。

















 94
94

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









