








📝个人主页🌹:Eternity._
🌹🌹期待您的关注 🌹🌹


概述
DETR3D介绍了一种多摄像头的三维目标检测的框架。与现有的直接从单目图像中估计3D边界框或者使用深度预测网络从2D信息中生成3D目标检测的输入相比,DETR3D直接在3D空间中进行预测。DETR3D从多个相机图像中提取2D特征,使用3D对象查询的稀疏集来索引这些2D特征。使用相机变换矩阵将3D位置链接到多视图图像。最后对每个目标单独进行边界框预测,使用集合到集合的损失来衡量真值和预测之间的差异。
本文所涉及的所有资源的获取方式:这里
模型结构
DETR3D架构的输入是一组投影矩阵(内参和相对外参的组合)和已知的相机收集的RGB图像,为场景中的物体输出一组3D边界框参数。与过去的方法相比,DETR3D基于一些高级需求构建体系结构。
- DETR3D将3D信息合并到中间计算中,而不是在图像平面上执行纯粹的2D计算
- DETR3D不估计密集的三维场景几何,避免相关的重建误差
- DETR3D避免了NMS等后处理步骤
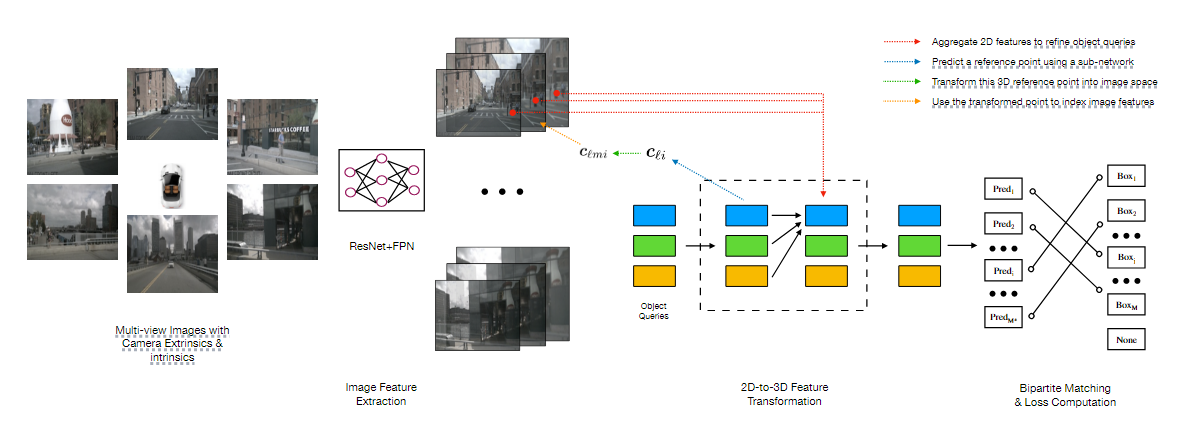
如上图所示,DETR3D使用一个新的集合预测模块来解决这些问题,该模块通过在2D和3D计算之间交替来连接2D特征提取和3D边界框预测。我们的模型包括三个关键部分:
- 首先,遵循2D视觉中的常见做法,它使用共享ResNet主干从相机图像中提取特征。这些特征可以选择性的由特征金字塔网络增强
- 一个检测头,以集合感知的方式将计算出的2D特征连接到一组3D边界框预测中。检测头的每一层都是从一组稀疏的对象查询开始,这些查询是从数据中学习的。每个对象查询编码一个3D位置,该位置被投影到相机平面上,用于通过双线性插值收集图像特征。DETR3D使用多头注意力通过结合对象交互来细化对象查询。该层重复多次,在特征采样和对象查询细化之间交替。
- DETR3D采用了一个集合到集合的损失来训练网络
特征学习

检测头
在相机输入中检测物体的现有方法通常采用自下而上的方法,该方法预测每张图像的密集边界框,过滤图像之间的冗余框,并在后处理步骤中汇总相机之间的预测。这种范式由两个关键的缺点:密集边界框预测需要精确的深度感知,这本身就是一个具有挑战性的问题;基于NMS的冗余删除和聚合是不可并行化的操作,会引入大量的推理开销。
DETR3D采用下面描述的自顶向下的目标检测头来解决这些问题。它使用L层基于集合的计算从2D特征图中产生边界框估计,每层都遵循如下的步骤:
- 预测一组与对象查询相关的边界框中心
- 使用相机变换矩阵将这些中心投影到所有的特征映射中
- 通过双线性插值采样特征,并将其合并到对象查询中
- 采用多头注意力机制描述对象的相互作用


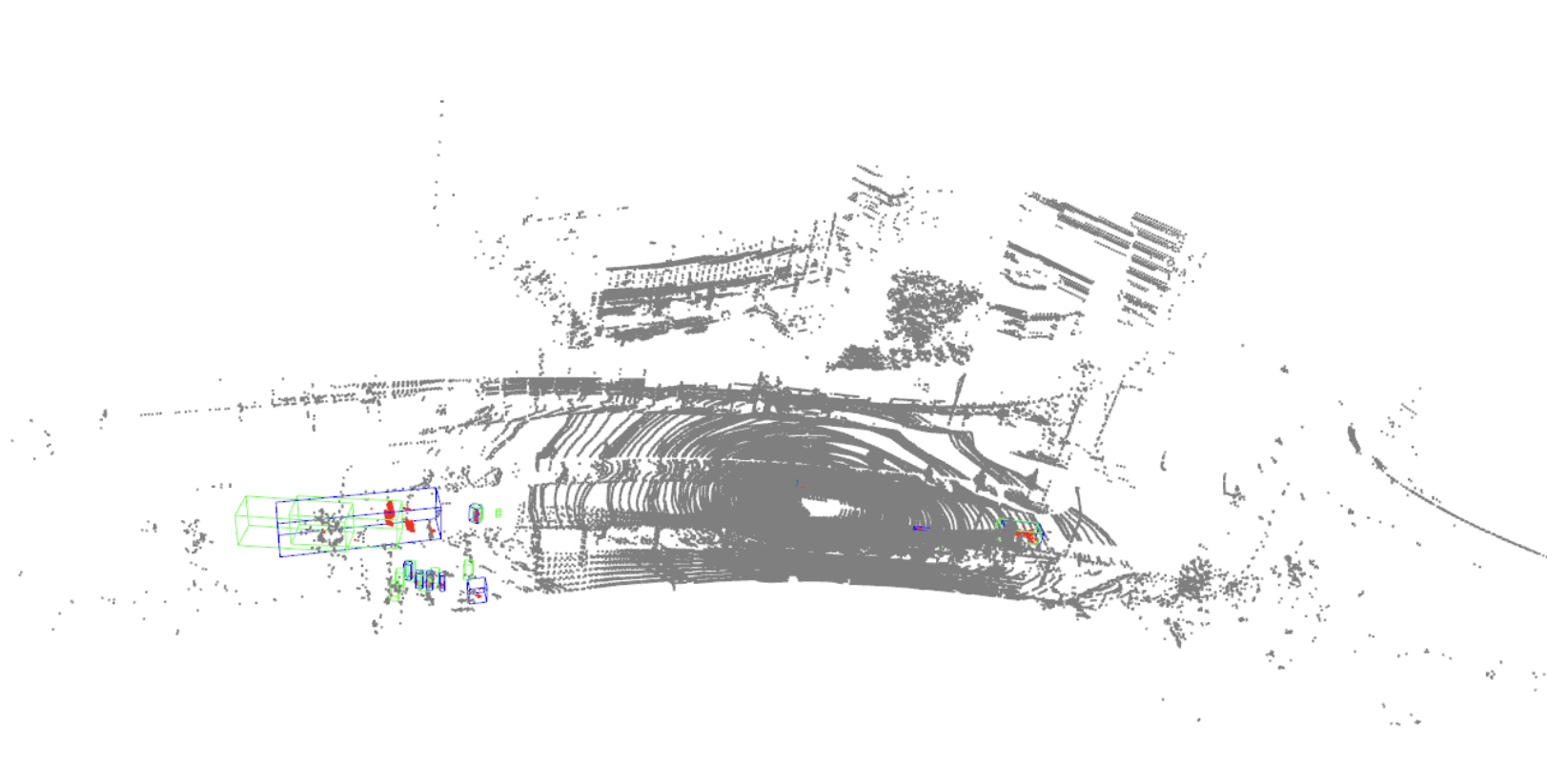
演示效果



核心逻辑
FPN结构
对经过ResNet的特征图进行特征交互与融合操作
def forward(self, inputs):
"""Forward function."""
assert len(inputs) == len(self.in_channels)
# build laterals
laterals = [
lateral_conv(inputs[i + self.start_level])
for i, lateral_conv in enumerate(self.lateral_convs)
]
# build top-down path
used_backbone_levels = len(laterals)
for i in range(used_backbone_levels - 1, 0, -1):
# In some cases, fixing `scale factor` (e.g. 2) is preferred, but
# it cannot co-exist with `size` in `F.interpolate`.
if 'scale_factor' in self.upsample_cfg:
# fix runtime error of "+=" inplace operation in PyTorch 1.10
laterals[i - 1] = laterals[i - 1] + F.interpolate(
laterals[i], **self.upsample_cfg)
else: # 使用双线性插值的方法将高层特征图扩大,并且两者相加
prev_shape = laterals[i - 1].shape[2:]
laterals[i - 1] = laterals[i - 1] + F.interpolate(
laterals[i], size=prev_shape, **self.upsample_cfg)
# build outputs
# part 1: from original levels
# out[0]:[6,256,116,200] out[1]:[6,256,58,100] out[2]:[6,256,29,50]
outs = [
self.fpn_convs[i](laterals[i]) for i in range(used_backbone_levels)
]
# part 2: add extra levels
if self.num_outs > len(outs):
# use max pool to get more levels on top of outputs
# (e.g., Faster R-CNN, Mask R-CNN)
if not self.add_extra_convs:
for i in range(self.num_outs - used_backbone_levels):
outs.append(F.max_pool2d(outs[-1], 1, stride=2))
# add conv layers on top of original feature maps (RetinaNet)
else:
if self.add_extra_convs == 'on_input':
extra_source = inputs[self.backbone_end_level - 1]
elif self.add_extra_convs == 'on_lateral':
extra_source = laterals[-1]
elif self.add_extra_convs == 'on_output':
extra_source = outs[-1]
else:
raise NotImplementedError
outs.append(self.fpn_convs[used_backbone_levels](extra_source))
# 增加最后一层 out[3]: [6,256,15,25]
for i in range(used_backbone_levels + 1, self.num_outs):
if self.relu_before_extra_convs:
outs.append(self.fpn_convs[i](F.relu(outs[-1])))
else:
outs.append(self.fpn_convs[i](outs[-1]))
return tuple(outs)
特征采样
BEV查询和特征图进行交互
def feature_sampling(mlvl_feats, reference_points, pc_range, img_metas):
lidar2img = [] # bev空间像图像空间的转换
for img_meta in img_metas:
lidar2img.append(img_meta['lidar2img'])
lidar2img = np.asarray(lidar2img) # new_tensor使dtype和device与ref_p相同,大小与lidar2img相同
# [1,6,4,4]
lidar2img = reference_points.new_tensor(lidar2img) # (B, N, 4, 4)
reference_points = reference_points.clone()
reference_points_3d = reference_points.clone()
# [1,900,3] # 分别将每个点投影到BEV网格上的范围
reference_points[..., 0:1] = reference_points[..., 0:1]*(pc_range[3] - pc_range[0]) + pc_range[0]
reference_points[..., 1:2] = reference_points[..., 1:2]*(pc_range[4] - pc_range[1]) + pc_range[1]
reference_points[..., 2:3] = reference_points[..., 2:3]*(pc_range[5] - pc_range[2]) + pc_range[2]
# reference_points (B, num_queries, 4)
# 最后拼接全是1的形式,形成齐次化坐标系方便后续的转换
reference_points = torch.cat((reference_points, torch.ones_like(reference_points[..., :1])), -1)
B, num_query = reference_points.size()[:2]
num_cam = lidar2img.size(1)
# ref_p:[1,900,4]->[1,1,900,4]->[1,6,900,4]->[1,6,900,4,1] lid:[1,6,1,4,4]->[1,6,900,4,4]
reference_points = reference_points.view(B, 1, num_query, 4).repeat(1, num_cam, 1, 1).unsqueeze(-1)
lidar2img = lidar2img.view(B, num_cam, 1, 4, 4).repeat(1, 1, num_query, 1, 1)
# [1,6,900,4,1]->[1,6,900,4] 和特征图无关,此时生成齐次化坐标系的形式
reference_points_cam = torch.matmul(lidar2img, reference_points).squeeze(-1)
eps = 1e-5
# z轴需要大于0否则不处于该相机平面上,ones_likes是防止其中的取值为负
mask = (reference_points_cam[..., 2:3] > eps)
reference_points_cam = reference_points_cam[..., 0:2] / torch.maximum(
reference_points_cam[..., 2:3], torch.ones_like(reference_points_cam[..., 2:3])*eps)
# 此时将其进行归一化,并且获得边界框的中心点坐标的形式
reference_points_cam[..., 0] /= img_metas[0]['img_shape'][0][1]
reference_points_cam[..., 1] /= img_metas[0]['img_shape'][0][0]
reference_points_cam = (reference_points_cam - 0.5) * 2
# 将不在该图像上且缩放大于1的数据进行处理
mask = (mask & (reference_points_cam[..., 0:1] > -1.0)
& (reference_points_cam[..., 0:1] < 1.0)
& (reference_points_cam[..., 1:2] > -1.0)
& (reference_points_cam[..., 1:2] < 1.0))
# mask:[1,6,900,1]->[1,6,1,900,1,1]->[1,1,900,6,1,1]
mask = mask.view(B, num_cam, 1, num_query, 1, 1).permute(0, 2, 3, 1, 4, 5)
mask = torch.nan_to_num(mask)
sampled_feats = []
for lvl, feat in enumerate(mlvl_feats):
B, N, C, H, W = feat.size() # [1,6,256,116,200]
feat = feat.view(B*N, C, H, W)
# ref_p: [1,6,900,2]->[6,900,1,2]
reference_points_cam_lvl = reference_points_cam.view(B*N, num_query, 1, 2)
# sample_f: [6,256,900,1]->[1,6,256,900,1]->[1,256,900,6,1]
# 根据ref_p给定的网格信息将将feat特征图的值给填充到网格中此时每个query包含的从特征图中提取的信息
sampled_feat = F.grid_sample(feat, reference_points_cam_lvl)
sampled_feat = sampled_feat.view(B, N, C, num_query, 1).permute(0, 2, 3, 1, 4)
sampled_feats.append(sampled_feat)
sampled_feats = torch.stack(sampled_feats, -1)
# [1,256,900,6,1,4]
sampled_feats = sampled_feats.view(B, C, num_query, num_cam, 1, len(mlvl_feats))
# 3d: [1,900,3]坐标直接是bev坐标的形式,是query从256下采样到3得到的结果。
# samp_f: [1,256,900,6,1,4] 是获取不同特征图的组合然后组合在一起
# mask: [1,1,900,6,1,1] 获得在每个相机图像下每个query是否会投影上去
return reference_points_3d, sampled_feats, mask
部署方式
# 安装python=3.7 cu111 torch1.9.0 torchvision 1.10.0
# 需要网上下载轮子采用pip install安装,这里以linux为例
conda create -n detr3d python=3.7
wget https://download.pytorch.org/whl/cu111/torch-1.9.0%2Bcu111-cp37-cp37m-linux_x86_64.whl
wget https://download.pytorch.org/whl/cu111/torch-1.10.0%2Bcu111-cp37-cp37m-linux_x86_64.whl
# 安装MMCV
pip install mmcv-full==1.4.0 -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.9.0/index.html
# 安装MMDetection
git clone https://github.com/open-mmlab/mmdetection.git
cd mmdetection
git checkout v2.19.0
sudo pip install -r requirements/build.txt
sudo python3 setup.py develop
cd ..
# 安装MMSeg
sudo pip install mmsegmentation==0.14.1
# 安装MMDEtection3D
git clone https://github.com/open-mmlab/mmdetection3d.git
cd mmdetection3d
git checkout v0.17.3
sudo pip install -r requirements/build.txt
sudo python3 setup.py develop
cd ..
参考文献
编程未来,从这里启航!解锁无限创意,让每一行代码都成为你通往成功的阶梯,帮助更多人欣赏与学习!
更多内容详见:这里

















 1963
1963

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









