







1.什么是神经网络
神经网络的核心只是机器学习算法中的另一种工具。神经网络由一组“神经元”组成,这些值从输入数据开始,然后乘以权重,相加,然后通过激活函数产生新的值,然后这个过程在神经网络必须产生输出的“层”上重复。看起来有点像下图
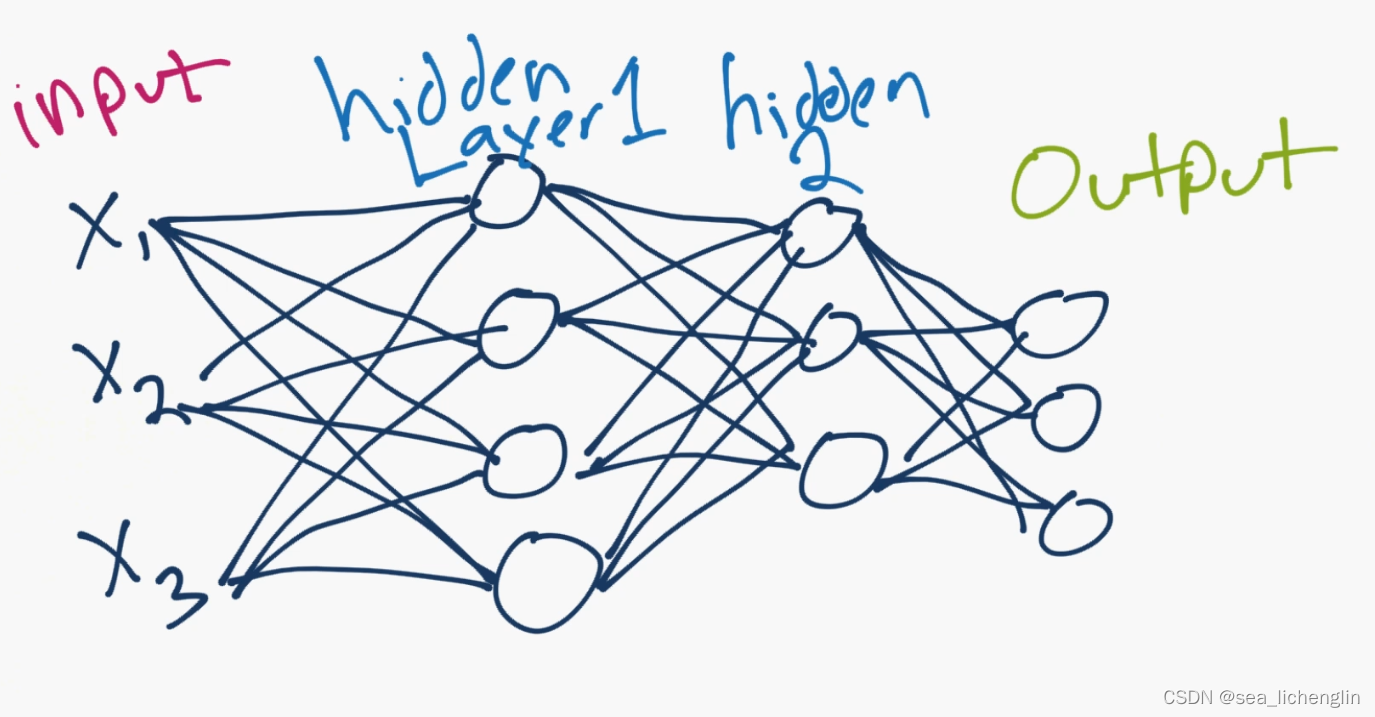
X1、X2、X3是数据的“特征”。这些可以是图像的像素值,也可以是描述数据的其他数字特征。
在你的隐藏层中(“隐藏”通常指的是程序员并没有真正设置或控制这些层的值,机器会这样做),这些是神经元,按你想要的数量进行编号(你控制有多少,只是不控制这些神经元的值),然后它们会产生一个输出层。输出通常是用于回归任务的单个神经元,或者是类中任意数量的神经元。在上面的例子中,有3个输出神经元,所以这个神经网络可能是对狗、猫和人进行分类。每个神经元的值都可以看作是神经网络认为是该类别时的置信度得分。
无论哪个神经元的值最高,这就是预测的类别!因此,三个输出神经元的顶部可能是“人”,然后是中间的“狗”,然后是底部的“猫”。如果人类价值最大,那么这就是神经网络的预测。
连接所有神经元的是这些线。每一个都是一个权重,也可能是一个偏差。因此,输入值乘以权重,加上偏差,然后在下一个神经元处求和,通过激活函数,成为下一个的下一个输入值!
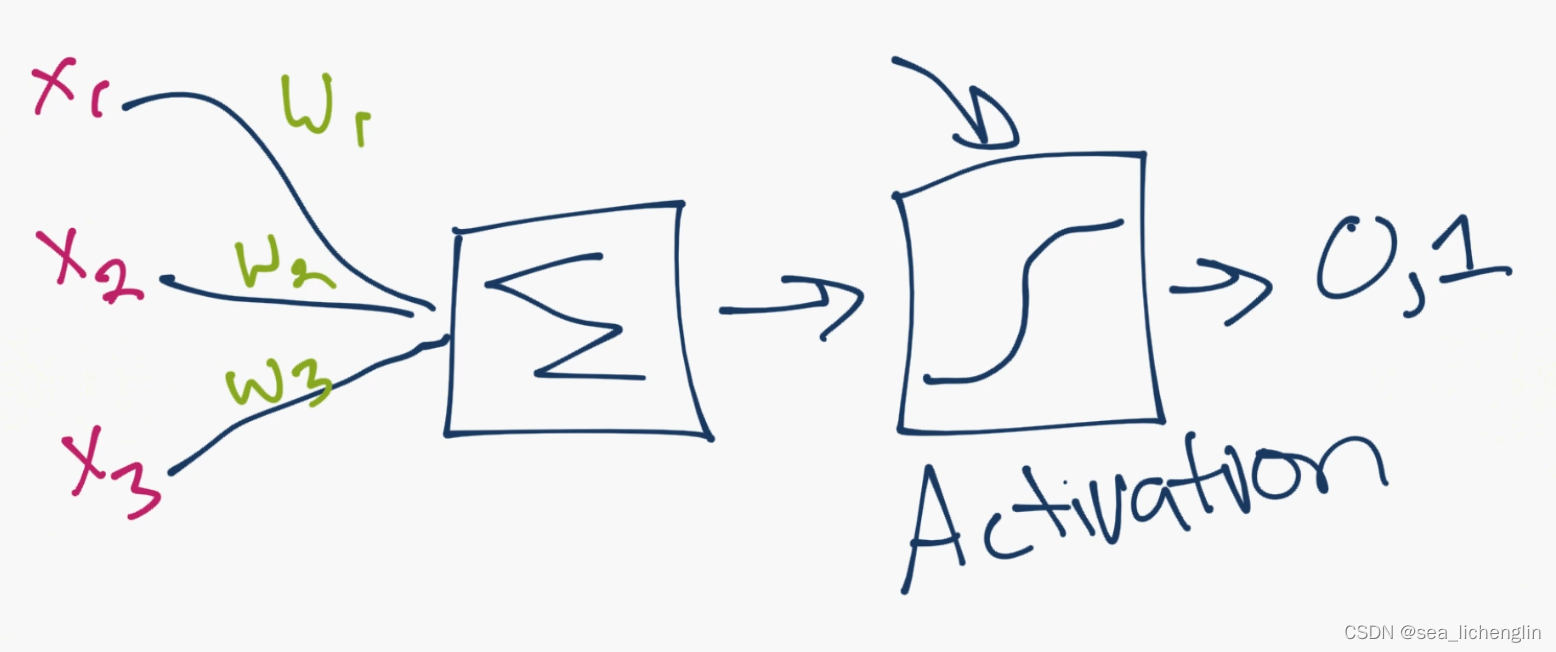
上面是一个“放大”的例子,可以说是显示了单个神经元的机制。你可以看到来自其他神经元的输入,它们乘以权重,然后相加。在这个求和之后,它们通过一个激活函数。激活函数的任务是计算一个神经元是否在“激活”,或“激活”的程度。神经元可以输出0或1来关闭或打开,但更常见的是,也可以输出0到1之间的范围,例如,作为下一层的输入。
2.如何学习神经网络
现在,我们只考虑“监督学习”方法,程序员向神经网络显示输入数据,然后告诉机器输出应该是什么。
然后,机器的工作就是找出如何调整权重(每行都是一个权重),使模型的输出尽可能接近程序员告诉机器一切都是这样的分类。机器的目标不仅仅是针对单个样本,而是针对多达数百万或更多的样本。。。通过缓慢调整权重进行搜索,如在系统中旋转和调整nob,以使其越来越接近目标/期望输出。
(1)环境
Python 3+。我将专门使用Python3.7。
Pytoch。我在这里使用的是版本1.2.0。
了解Python 3基础知识
理解OOP和其他中间概念
或者,您可能希望在GPU上运行,而不是在CPU上运行。
我们经常想在GPU上运行,因为我们使用这些张量处理库所做的事情是计算大量的简单计算。CPU的每个“核心”只能做一件事。有了虚拟核,这就加倍了,但CPU应该一次处理更复杂、更难解决的问题。GPU旨在帮助生成图形,这也需要许多小/简单的计算。因此,您的CPU可能一次进行8到24次计算。一个像样的GPU可以达到数千次。
(2)Pytoch介绍
Pytorch库与其他深度学习库一样,实际上只是一个对张量进行操作的库。
什么是张量?!
你可以把张量想象成数组。实际上,我们所做的只是对数组进行乘法运算。这就是一切。当我们对所有这些权重运行优化算法以开始修改它们时,这是一个有趣的地方。神经网络本身实际上是超级基础和简单的。它们的优化有点困难,但大多数这些深入学习的库在数学方面也有一定帮助。所以Pytorch旨在模拟Python中非常流行的数字库NumPy。存在许多完全相同的方法,通常名称相同,但有时名称不同。一个常见的任务是生成某种形状的“空”数组。
可以尝试以下例子,加深自己的理解。
import torch
x = torch.Tensor([5,3])
y = torch.Tensor([2,1])
print(x*y)














 1878
1878











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









