







文章目录
- 前言
- 一、使用MMDetection已有模型在标准数据集上进行推理时遇到的问题
- 1.Command 'nvcc' not found, but can be installed with:sudo apt install nvidia-cuda-toolkit
- 2. RuntimeError: CUDA error: no kernel image is available for execution on the device
- 3.ImportError: libcudart.so.10.1: cannot open shared object file: No such file or directory
- 4.ImportError: /home/hm/anaconda3/envs/openmmlab/lib/python3.8/site-packages/mmcv/_ext.cpython-38-x86_64-linux-gnu.so: undefined symbol: _ZNK2at6Tensor7is_cudaEv
前言
记录在学习使用mmdetection框架时,遇到的一些bug,随时补充。
本文初始环境配置为:
GPU:NVIDIA GeForce RTX 3080 (arch=8.6)
cuda:10.1
Pytorch:1.8.1
torchvision:0.9.1+cu101
torchaudio:0.8.1
一、使用MMDetection已有模型在标准数据集上进行推理时遇到的问题
问题来源:
在学习使用MMdetection已有模型在标准数据集上进行推理时,使用 DetInferencer来获得推理结果,运行代码如下:
from mmdet.apis import DetInferencer
# 初始化模型
inferencer = DetInferencer('rtmdet_tiny_8xb32-300e_coco')
# 推理示例图片
inferencer('demo/demo.jpg', show=True)
结果出现了错误信息1:
GeForce RTX 3080 with CUDA capability sm_86 is not compatible with the current PyTorch installation.
 可参考:https://blog.csdn.net/weixin_43751285/article/details/110651105
可参考:https://blog.csdn.net/weixin_43751285/article/details/110651105
以及错误信息2:
RuntimeError: CUDA error: no kernel image is available for execution on the device
在解决如上两个问题的过程中,接连遇到一些错误提示信息如:
ImportError: libcudart.so.10.1: cannot open shared object file: No such file or directory
ImportError: /home/hm/anaconda3/envs/openmmlab/lib/python3.8/site-packages/mmcv/_ext.cpython-38-x86_64-linux-gnu.so: undefined symbol: _ZNK2at6Tensor7is_cudaEv
下面是最终把问题解决了的操作顺序,包括相应报错及解决方法。
出现上述问题的最根本原因还是CUDA安装以及版本匹配的问题(CUDA版本与驱动程序不兼容、PyTorch版本与CUDA版本不匹配)
首先可以下载https://gitee.com/kwonder/other_public_code/blob/master/collect_env.py代码,运行collect_env.py文件得到如下配置信息:
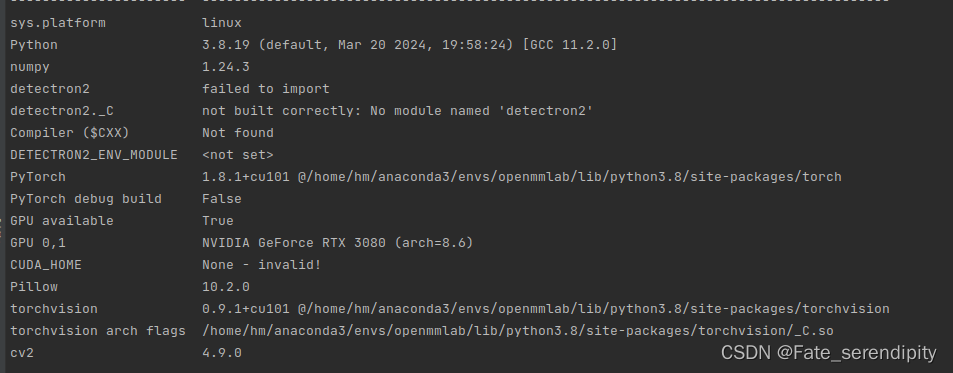 从上图中,我们可以看到已经安装的Python版本、Pytorch版本、GPU型号以及算力等信息,这里大家关注一下
从上图中,我们可以看到已经安装的Python版本、Pytorch版本、GPU型号以及算力等信息,这里大家关注一下CUDA_HOME:
case1:你的CUDA_HOME是None,那么就是CUDA环境配置的问题了,可以按照本文顺序向下看;
case2:CUDA_HOME的值是正常的路径(一般为/usr/local/cuda ),那么可酌情参考后文文章。
1.Command ‘nvcc’ not found, but can be installed with:sudo apt install nvidia-cuda-toolkit
(1)问题来源:
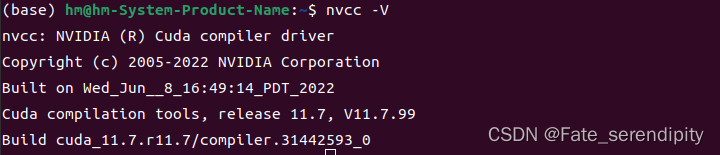
在终端输入nvcc -V,运行后出现了以下提示:
Command ‘nvcc’ not found, but can be installed with:sudo apt install nvidia-cuda-toolkit
(2)产生原因:
一般是没有给CUDA配置环境变量(cuda文件一般在usr/local/目录下),然而我发现我的目录下并没有cuda文件,因此去官网下载相应版本并进行配置(具体安装过程可参考:https://zhuanlan.zhihu.com/p/581720480 安装CUDA之后的内容,我也安装的是11.7版本)
其中,配置环境变量的步骤也可通过vim指令完成:vim ~/.bashrc (上文链接中是通过gedit ~/.bashrc)
(3)按照上述步骤完成后,在终端再次输入nvcc -V`进行验证,运行结果如下,问题解决。
2. RuntimeError: CUDA error: no kernel image is available for execution on the device
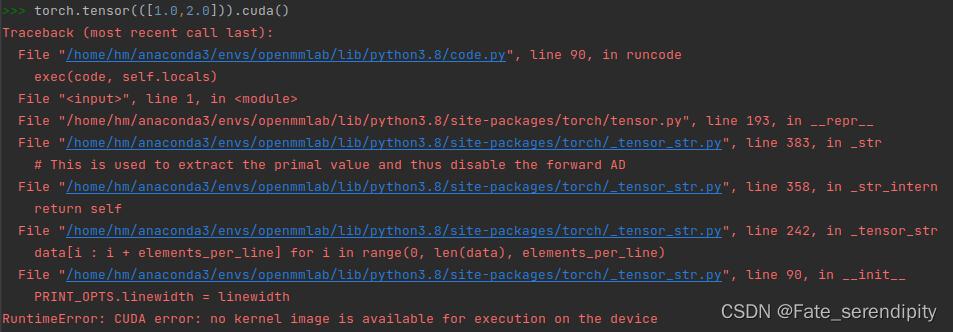
问题来源:使用以下命令来测试你的cuda版本torch是否可以使用,在Python控制台中输入:
import torch
torch.zeros(1).cuda()
提示如下报错信息:
解决方法:
在终端输入nvcc -V查看你的设备的CUDA版本(我是cuda11.7)
从官网找到对应的版本安装,在终端输入指令:
pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu117
(我的cuda是11.7,因此进入官网后,同时按住ctrl-F键,全局搜索:“CUDA 11.7”,找到了上面的命令)
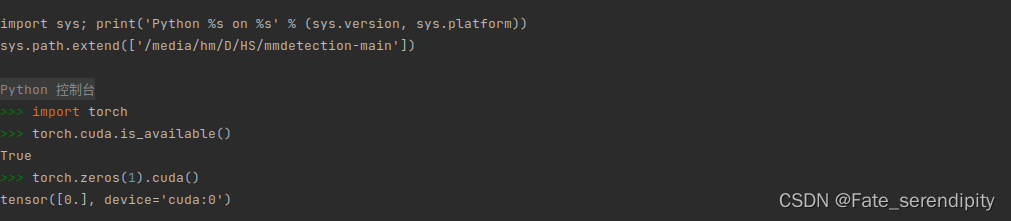
本文安装的版本如下:

安装完成后,再次运行上述指令torch.zeros(1).cuda()测试,运行结果如下,即为成功。
可参考:
https://zhuanlan.zhihu.com/p/466793485
3.ImportError: libcudart.so.10.1: cannot open shared object file: No such file or directory
若在代码运行中出现了此错误,可参考上述过程完成CUDA、Pytorch版本的安装,版本对应上了,就解决了。
参考:
4.ImportError: /home/hm/anaconda3/envs/openmmlab/lib/python3.8/site-packages/mmcv/_ext.cpython-38-x86_64-linux-gnu.so: undefined symbol: _ZNK2at6Tensor7is_cudaEv
(1)问题来源:
在完成了上述操作后,我再一次运行了文章开头的代码进行试验,结果爆出错误信息:
ImportError: /home/hm/anaconda3/envs/openmmlab/lib/python3.8/site-packages/mmcv/_ext.cpython-38-x86_64-linux-gnu.so: undefined symbol: _ZNK2at6Tensor7is_cudaEv
(2)产生原因:
mmcv库非常依赖于Pytorch以及CUDA的版本,需要下载适合目前Pytorch版本的mmcv库。
(3)解决方法:
我原有的mmcv版本是2.1.0,参考以下方式安装 mmcv-full
pip install --upgrade mmcv-full==${MMCV} -f https://download.openmmlab.com/mmcv/dist/cu${CUDA}/torch${PYTORCH}/index.html
需要自行替换${MMCV}, ${CUDA}, 和 ${PYTORCH}为你的版本号,Pytorch and CUDA 对应你已经安装的版本 ,比如你的CUDA是11.1,就将${CUDA} 改为111。
期间又遇到了一些报错,参考了以下的文档:
https://github.com/open-mmlab/mmdetection/issues/4291
https://blog.csdn.net/shysea2019/article/details/129827747
解决完上述问题,最终成功运行了在标准数据集上进行推理的代码。















 208
208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









