







Method
Value-Based
step1: 将神经网络作为actor
step2: 衡量actor的好坏
step3: 选择最好的actor
Policy-Based
Critic: 用来评估actor
State value function(V): 在看到某一个状态state的时候预期能够得到的累积收益Estimation of V:
- Monte-Carlo(MC): critic会观察actor π \pi π 玩游戏的整个过程, 具有不确定性,较大的方差,但结果无偏
- Temporal-difference(TD): 只计算状态与状态之间的收益reward,具有较小的方差,但是结果可能造成偏误
- State action value function: 基于状态state和行动action得到收益reward
- Q-learning: actor π \pi π和环境做互动,然后不断用一个更好的 π ′ \pi' π′来更新 π \pi π
Actor-Critic
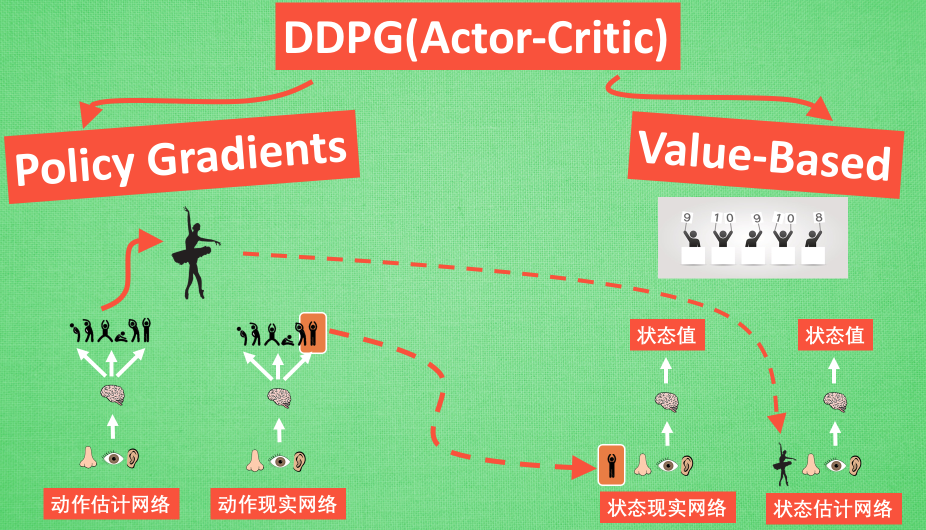
Actor
actor网络基于Policy Gradients,输入为state,输出为采取各个action的概率(action需要是离散的)
Critic
critic网络基于value-based,输入为state和action,输出为value,即对Q(s,a)的估值
使用actor估计出来的action在critic中估值,并用估计出来的Q(s,a)对actor网络优化
Policy
强化学习中一般有两个策略,行为策略(Behavior Policy)和目标策略(Target Policy),我们使用行为策略在训练时做决策,而目标策略则是训练结束后拿去应用的策略。
On-Policy
学习到的agent以及和环境进行互动的agent是同一个agent
Sarsa
使 用 ϵ − g r e e d y 算 法 选 择 a c t i o n a ′ Q ( s , a ) = Q ( s , a ) + α [ R ( s , a ) + γ Q ( s ′ , a ′ ) − Q ( s , a ) ] s = s ′ ; a = a ′ 使用\epsilon-greedy算法选择action\ a'\\ Q(s,a)=Q(s,a)+\alpha[R(s,a)+\gamma Q(s',a')-Q(s,a)]\\ s=s';a=a' 使用ϵ−greedy算法选择action a′Q(s,a)=Q(s,a)+α[R(s,a)+γQ(s′,a′)−Q(s,a)]s=s′;a=a′
Off-Policy
学习到的agent以及和环境进行互动的agent是不同的agent
Q-learning
Q ( s , a ) = Q ( s , a ) + α [ R ( s , a ) + γ max a ′ { Q ( s ′ , a ′ ) } − Q ( s , a ) ] s = s ′ Q(s,a)=Q(s,a)+\alpha[R(s,a)+\gamma \max_{a'}\left\{Q(s',a') \right\}-Q(s,a)]\\ s=s' Q(s,a)=Q(s,a)+α[R(s,a)+γa′max{Q(s′,a′)}−Q(s,a)]s=s′
可以看作是使用了另外一个greedy的policy作为target policy
DQN
DQN作为一个例子来说更加直观,使用两个critic网络进行估值,其中target网络固定不变,训练main网络,在一定次数的训练后再同步两个网络,这时候可以明显看出行为策略与目标策略是不相同的。
本文内容主要基于李宏毅老师的机器学习基础课程,如果想要详细了解可以直接去观看视频















 627
627











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









