







 文章介绍了CritiqueLLM,一种可解释且可扩展的模型,用于高效评价大模型生成文本的质量,尤其在无参考文本场景下表现出色,与人工评分相关系数接近GPT-4。模型通过对话式数据收集和自洽性解码方法提高评价精度。
文章介绍了CritiqueLLM,一种可解释且可扩展的模型,用于高效评价大模型生成文本的质量,尤其在无参考文本场景下表现出色,与人工评分相关系数接近GPT-4。模型通过对话式数据收集和自洽性解码方法提高评价精度。

模型评测,对于模型的研发至关重要。
但如何能够在研发过程中,快速、有效、公平且低成本地对模型性能进行评测,依然是一个重要问题。
传统的评价指标(如BLEU、ROUGE)基于参考文本和生成文本的n-gram重合度计算评价分数,缺乏对生成文本整体语义的把握;而基于模型的评价方法则严重依赖基座模型的选取,只有GPT-4这样“顶级”的大模型才能取得令人满意的评价效果,但其仅能通过API访问的特性又给研究者带来花费高昂、访问困难、数据泄露等一系列挑战。
因此,我们提出了可解释、可扩展的文本质量评价模型 CritiqueLLM。
该模型可以针对各类指令遵循任务上大模型的生成结果提供高质量的评价分数和评价解释。
下图展示了CritiqueLLM在含参考文本的场景下评价生成文本质量的示例,
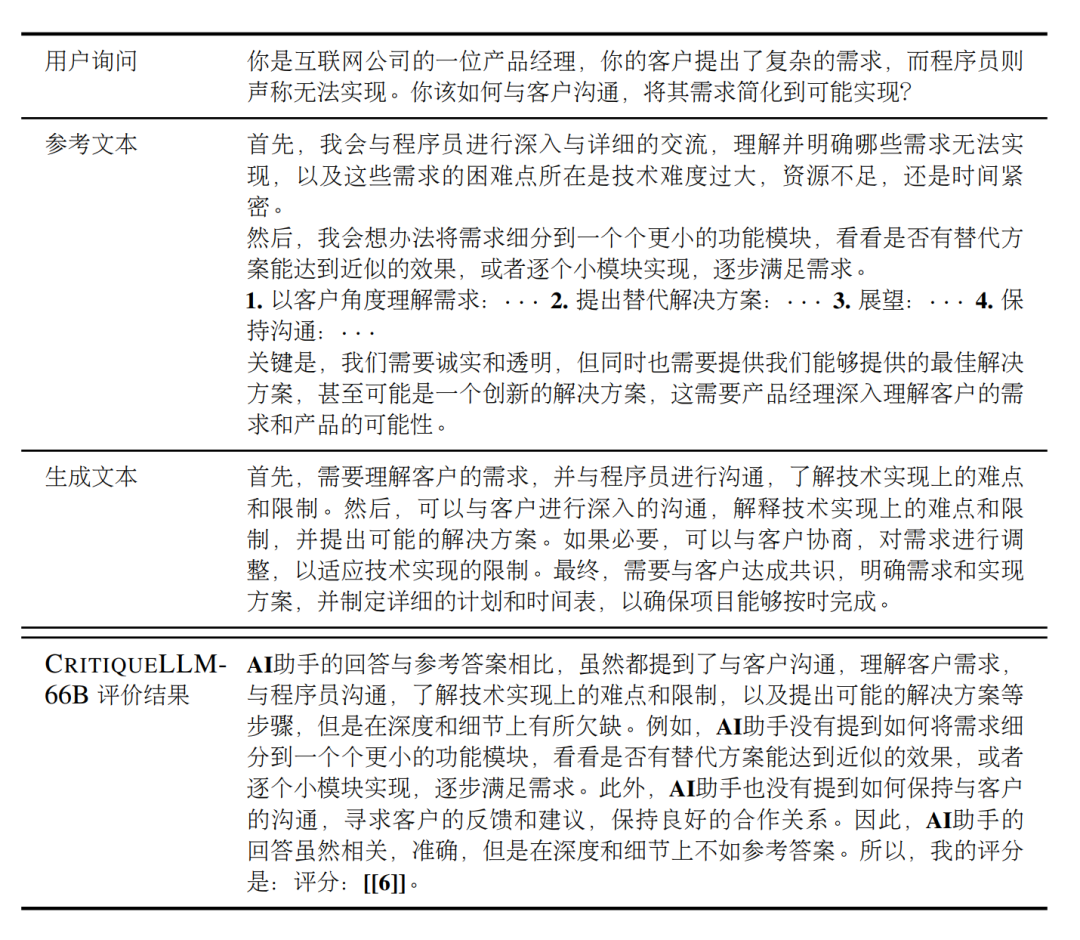
其中 CritiqueLLM 将大模型生成文本和参考文本进行了详尽的对比,全面总结了生成文本的优缺点,最终给出了6分的评分(分数范围为1-10)。
我们在下图展示了8类常见的指令遵循任务(包括逻辑推理、综合问答、专业能力、基本任务、数学计算、角色扮演、文本写作和中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 893
893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









