







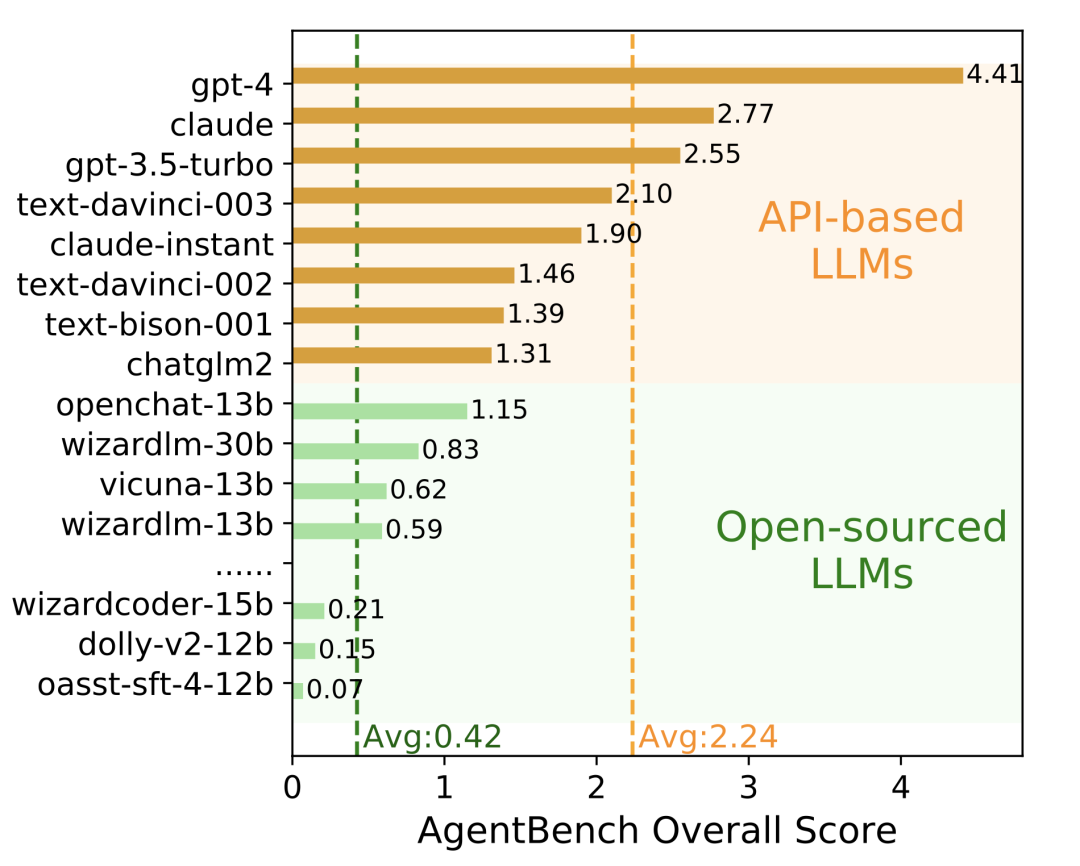
还记得在 8月份,我们公开的 AgentBench 测试榜单吗?在当时的榜单中,各类开源模型的智能体能力普遍表现不佳。
对于 Agent 能力提升的策略,现有许多工作多使用 Prompt / 微调方法优化模型,在单项智能体任务上取得了卓越的表现,但智能体任务之间的促进及泛化效果有待进一步探索。
其实,开源模型并非没有完成智能体任务的能力,可能只是在智能体任务上缺乏对齐。
智谱AI&清华KEG提出了一种对齐 Agent 能力的微调方法 AgentTuning,该方法使用少量数据微调已有模型,显著激发了模型的 Agent能力,同时可以保持模型原有的通用能力。我们也开源了经过 Agent 对齐的语言模型,包括 AgentLM-7B,AgentLM-13B,AgentLM-70B,并开源了相应的数据集 AgentInstruct。
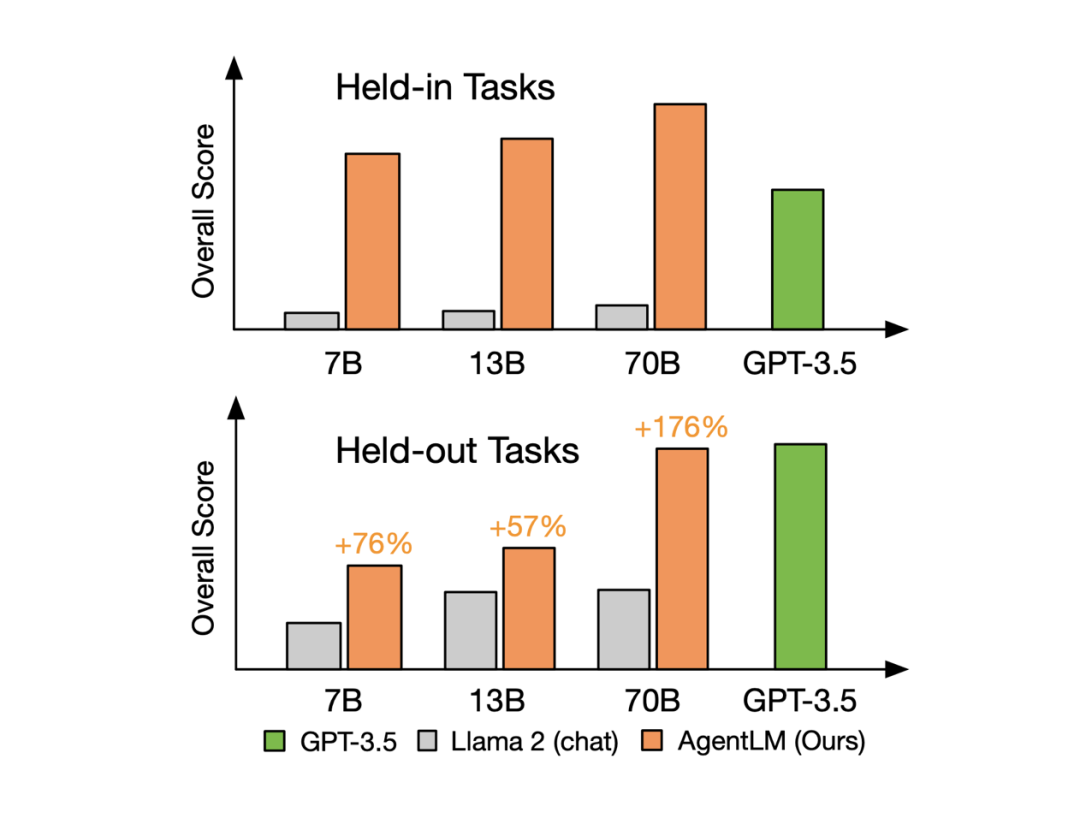
从上图中可以看到,经过微调的模型,内分布任务(Held-in Tasks)中 AgentLM-7B 的综合分数便可达到 GPT-3.5-turbo 的水平;外分布任务(Held-out Tasks,训练过程中未见过的任务)中 AgentLM-7
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5382
5382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









