







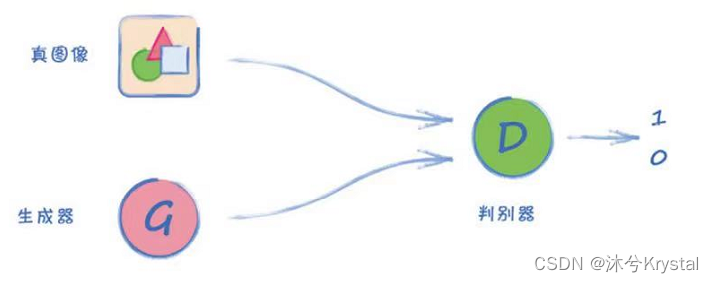
GAN的概念
对抗训练

-
如何训练生成器:
- 如果图像通过了鉴别器的检验,我们奖励生成器;
- 如果伪造的图像被识破,我们惩罚生成器。
-
随着训练的进展,鉴别器的表现越来越好,生成器也必须不断进步,才能骗过更好的鉴别器。最终,生成器也变得非常出色,可以生成足以以假乱真的图像。
-
这种架构叫做生成对抗网络(Generative Adversarial Network, GAN)。它利用竞争来驱动进步,并且,我们不需要定义具体的规则来描述要编码到损失函数中的真实图像,相反,我们让GAN自己来学习什么是真正的图像。
GAN的训练
- 三步训练循环:
- 第1步——向鉴别器展示一个真实的数据样本,告诉它该样本的分类应该是1.0。
- 第2步——向鉴别器显示一个生成器的输出,告诉它该样本的分类应该是0.0。
- 第3步——向鉴别器显示一个生成器的输出,告诉生成器结果应该是1.0。
生成1010格式规律
- 我们来构建一个GAN,用生成器学习创建1010格式规律的值。在这个GAN架构中,真实的数据集被替换成了一个函数,会一直生成1010格式规律的数据,所以我们不需要使用PyTorch的 torch.utils.data.Dataset 对象。
- 生成器是一个神经网络,有4个输出值,我们希望训练它输出1010格式规律的数据。
真实的数据源
def generate_real():
real_data = torch.FloatTensor(
[random.uniform(0.8, 1.0),
random.uniform(0.0, 0.2),
random.uniform(0.8, 1.0),
random.uniform(0.0, 0.2)])
return real_data
generate_real()
构建鉴别器
- 鉴别器,它是一个继承自 nn.Module 的神经网络。按照PyTorch所需要的方式初始化网络,并创建一个 forward() 函数。构造函数如下:
class Discriminator(nn.Module):
def __init__(self):
# 初始化PyTorch父类
super().__init__()
# 定义神经网络层
self.model = nn.Sequential(
nn.Linear(4, 3),
nn.Sigmoid(),
nn.Linear(3, 1),
nn.Sigmoid()
)
# 创建损失函数
self.loss_function = nn.MSELoss()
# 创建优化器,使用随机梯度下降
self.optimiser = torch.optim.SGD(self.parameters(), lr=0.01)
# 计数器和进程记录
self.counter = 0
self.progress = []
pass
- 通过forward() 函数调用上面的模型,输入数据并返回网络输出。
def forward(self, inputs):
# 直接运行模型
return self.model(inputs)
- 训练函数的标准流程。首先,神经网络根据输入值计算输出值。损失值是通过比较输出值与目标值计算得到的。网络中的梯度由这个损失值计算得到,再通过优化器逐步更新可学习参数。
def train(self, inputs, targets):
# 计算网络的输出
outputs = self.forward(inputs)
# 计算损失值
loss = self.loss_function(outputs, targets)
# 每训练10次增加计数器
self.counter += 1
if (self.counter % 10 == 0):
self.progress.append(loss.item())
pass
if (self.counter % 10000 == 0):
print("counter = ",self.counter)
pass
# 归零梯度,反向传播,并更新权重
self.optimiser.zero_grad()
loss.backward()
self.optimiser.step()
pass
测试鉴别器
- 由于还没有创建生成器,因此我们无法真正测试与之竞争的鉴别器。目前能做的是,检验鉴别器时候能将真实数据与随机数据区分开。
- 创建一个函数来生成随机噪声:
def generate_random(size):
random_data = torch.rand(size)
return random_data
- 现在用一个训练循环来训练鉴别器,并对以下两种分类提供奖励:
- 符合1010格式规律的数据是真实的,目标输出是1.0
- 随机生成的数据是伪造的,目标输出是0.0
- 训练循环如下:
D = Discriminator()
for i in range(10000):
# 真实数据
D.train(generate_real(), torch.FloatTensor([1.0]))
# 随机数据
D.train(generate_random(4), torch.FloatTensor([0.0]))
pass
构建生成器
- 生成器是一个神经网络,输出层需要有4个节点,对应实际数据格式。
- 生成器的隐藏层应该多大?输入层呢?我们需要配合鉴别器的学习速度,许多人从复制鉴别器的构造入手来设计生成器,也就是一个反向鉴别器。
class Generator(nn.Module):
def __init__(self):
# 初始化PyTorch父类
super().__init__()
# 定义神经网络层
self.model = nn.Sequential(
nn.Linear(1, 3),
nn.Sigmoid(),
nn.Linear(3, 4),
nn.Sigmoid()
)
# 创建优化器,使用随机梯度下降
self.optimiser = torch.optim.SGD(self.parameters(),lr=0.01)
# 计数器和进程记录
self.counter = 0
self.progress = []
pass
def forward(self, inputs):
# 直接运行模型
return self.model(inputs)
- 在GAN的训练循环中,我们使用的唯一的损失函数是根据鉴别器的输出计算的,最后,我们根据鉴别器损失值计算的误差梯度来更新生成器。
- 对于鉴别器,我们知道目标输出是什么,而对于生成器,我们不知道目标输出。我们已知的是反向传播梯度,它更加GAN训练循环第3步的鉴别器的输出损失值计算得出。
- 因此,训练生成器也需要鉴别器的损失值,一种方法是将鉴别器传递给生成器的train() 函数。
def train(self, D, inputs, targets):
# 计算网络输出
g_output = self.forward(inputs)
# 输入鉴别器
d_output = D.forward(g_output)
# 计算损失值
loss = D.loss_function(d_output, targets)
# 每训练10次增加计数器
self.counter += 1
if (self.counter % 10 == 0):
self.progress.append(loss.item())
pass
# 梯度归零,反向传播,并更新权重
self.optimiser.zero_grad()
loss.backward()
self.optimiser.step()
pass
- 更新由self.optimiser而不是D.optimiser触发,这样一来,只有生成器的链接权重得到更新。
检查生成器输出
- 在训练生成器之前,检查一下它的输出是否符合要求。

训练GAN
# 创建鉴别器和生成器
D = Discriminator()
G = Generator()
# 训练鉴别器和生成器
for i in range(10000):
# 用真实样本训练鉴别器
D.train(generate_real(), torch.FloatTensor([1.0]))
# 用生成样本训练鉴别器
# 使用detach()以避免计算生成器G中的梯度
D.train(G.forward(torch.FloatTensor([0.5])).detach(), torch.FloatTensor([0.0]))
# 训练生成器
G.train(D, torch.FloatTensor([0.5]), torch.FloatTensor([1.0]))
pass
- 对于生成器输出,detach()的作用是将其从计算图中分离出来。对于更大的网络,这么做可以明显地节省计算成本。
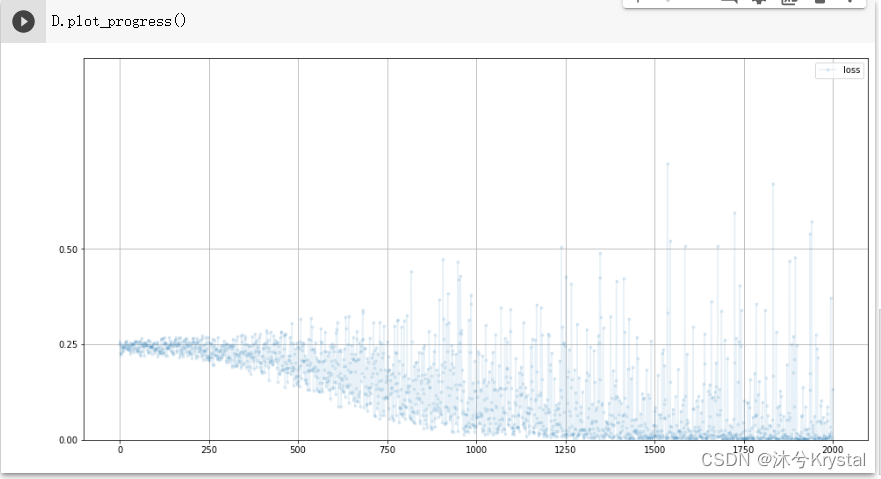
- 看一下鉴别器的训练进展。

- 这里的损失值保持在 0.25 左右。当鉴别器不擅长从伪造数据中识别真实数据时,它就无法确定输出是 0.0 还是1.0,索性就输出 0.5。由于是均方误差,所以损失的结果是 0.25。
- 了解一下生成器的训练进展。

- 试验一下训练后的生成器

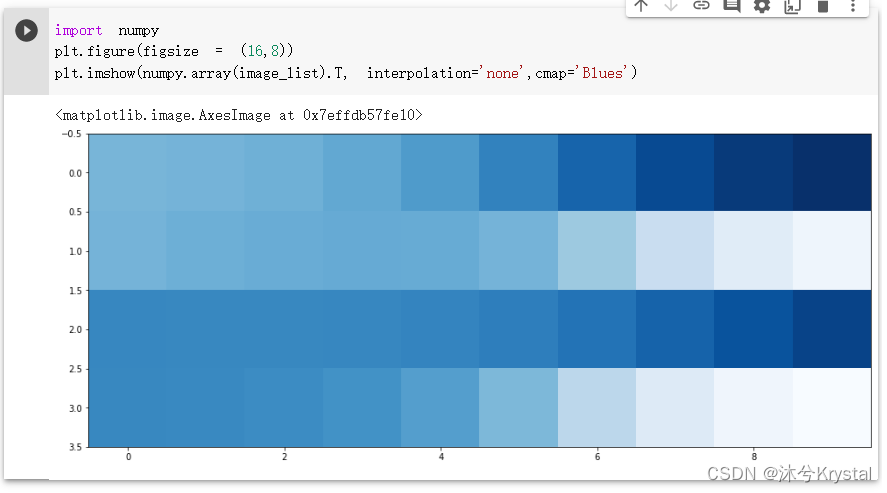
- 额外的实验,看看1010格式规律在训练过程中是如何演变的。我们可以在训练循环之前创建一个空列表image_list,每1000次训练循环记录一次生成器的输出。
# 每训练1000次记录图像
if (i%1000 == 0):
image_list.append(G.forward(torch.FloatTensor([0.5])).detach().numpy())
- 在使用numpy()之前,使用detach()将输出张量从计算图中分离出来。
- 我们将每个输出转换成
10
×
4
10 \times 4
10×4 的numpy数组,再将它对角反转,方便我们从左向右观察它的演化过程。















 356
356











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









