







 本文探讨了国内如美团和国际Swiggy、Zomato等外卖平台如何利用客户数据进行食品订单预测,优化配送效率。通过分析年龄、婚姻状况、职业等信息,研究发现特定客户群体更频繁订餐,并应用随机森林分类器构建模型预测客户再次订购行为,以提高服务效率和商机识别。
本文探讨了国内如美团和国际Swiggy、Zomato等外卖平台如何利用客户数据进行食品订单预测,优化配送效率。通过分析年龄、婚姻状况、职业等信息,研究发现特定客户群体更频繁订餐,并应用随机森林分类器构建模型预测客户再次订购行为,以提高服务效率和商机识别。
咱们国内的美团和国外的 Swiggy 和 Zomato 引入市场后,在线订餐的需求量很大。食品配送公司利用客户的购买习惯来加快配送过程。食品订单预测系统是这些公司可以用来加快整个交付过程的有用技术之一。
这些公司对客户的主要目标是在正确的时间交付食物。为了更快地交付食物,这些公司确定了在线食品订单需求较高的地区,并在这些地区雇用了更多的外卖员来在订单较多的地区更快地交付食物。
这些公司拥有大量有关客户的数据,因此他们现在了解所有客户的订餐习惯。利用这些数据,他们还可以预测客户是否会再次从他们的应用程序订购。这是识别具有更多商机的地区、家庭和客户类型的好方法。
引入相关的包和加载数据集
import numpy as npimport pandas as pdimport numpy as npimport plotly.express as pximport plotly.graph_objects as goimport matplotlib.pyplot as pltimport seaborn as snssns.set_theme(style="whitegrid")data = pd.read_csv("../data/onlinefoods.csv")data.head()
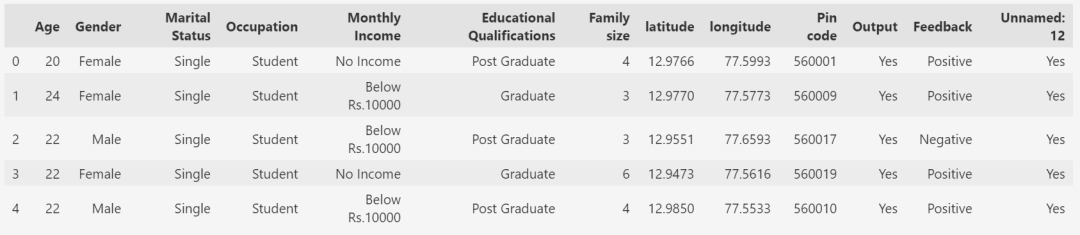
数据包含以下信息
-
客户的年龄(Age)
-
客户的婚姻状况(Marital Status)
-
客户的职业(Occupation)
-
客户的月收入(Monthly Income)
-
客户的受教育程度(Educational Qualifications)
-
客户的家庭规模(Family size)
-
客户所在位置的纬度和经度(latitude, longitude)
-
客户居住地的 Pin code
-
客户再次订购了吗(Output)
-
最后订单的反馈(Feedback)
我们来看看数据集中所有列的信息:
data.info()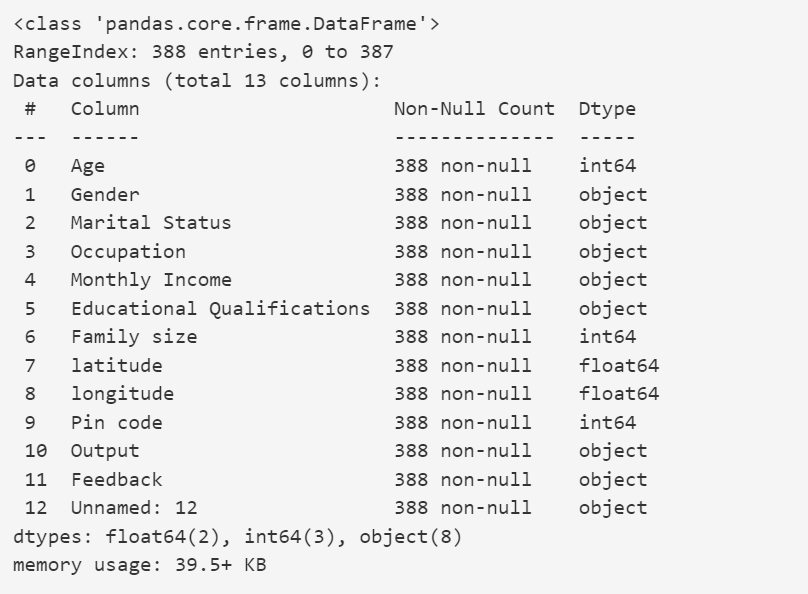
分析这些数据
我将首先根据客户的年龄查看在线食品订单决策:
plt.figure(figsize=(15, 10))plt.title("Online Food Order Decisions Based on the Age of the Customer")sns.histplot(x="Age", hue="Output", data=data)plt.show()
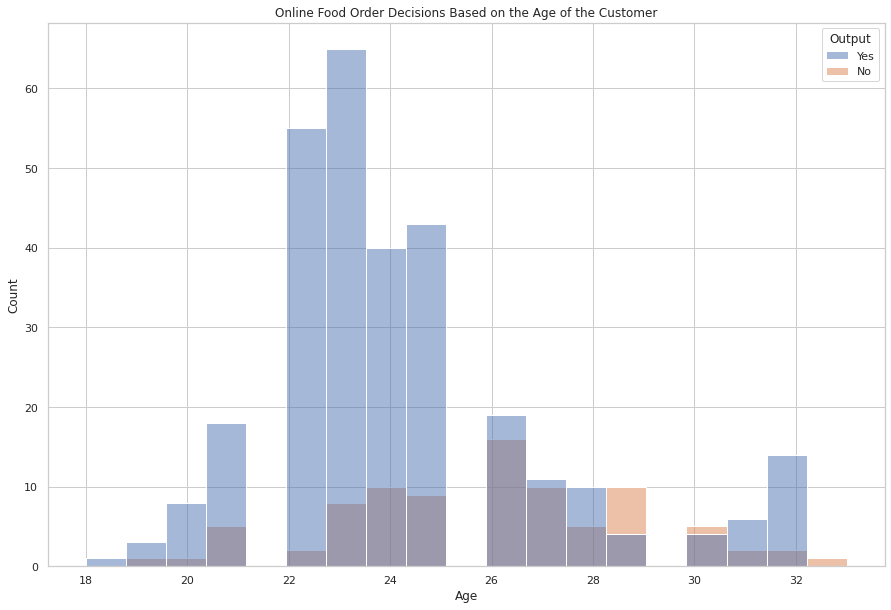
我们可以看到,22-25岁年龄段的人再次频繁点餐。这也意味着这个年龄段是在线食品配送公司的目标客户。
现在让我们看看根据客户家庭人数做出的在线订餐决策:
plt.figure(figsize=(15, 10))plt.title("Online Food Order Decisions Based on the Size of the Family")sns.histplot(x="Family size", hue="Output", data=data)plt.show()
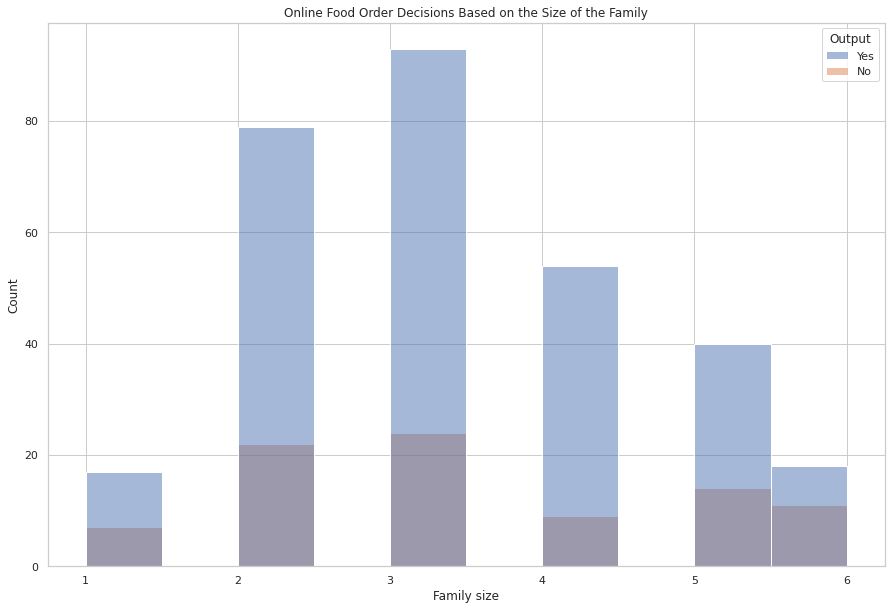
有 2 人和 3 人的家庭经常点餐。也许他们是室友、情侣或三口之家。
创建一个包含所有再次订购食物的顾客的数据集:
buying_again_data = data.query("Output == 'Yes'")buying_again_data.head()
现在我们看一下性别栏。看看哪种性别的客户在网上订餐的次数更多:
gender = buying_again_data["Gender"].value_counts()label = gender.indexcounts = gender.valuescolors = ['gold','lightgreen']fig = go.Figure(data=[go.Pie(labels=label, values=counts)])fig.update_layout(title_text='Who Orders Food Online More: Male Vs. Female')fig.update_traces(hoverinfo='label+percent', textinfo='value', textfont_size=30,marker=dict(colors=colors, line=dict(color='black', width=3)))fig.show()
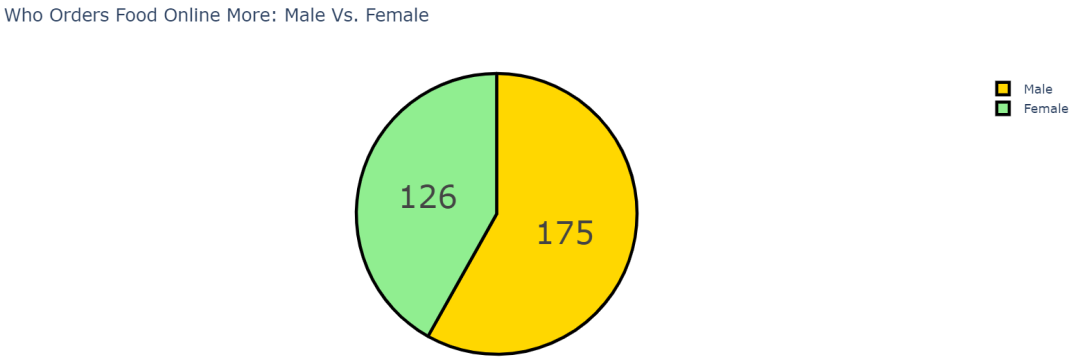
数据显示,男性顾客比女性顾客订购的商品更多。
看看再次下单的顾客的婚姻状况
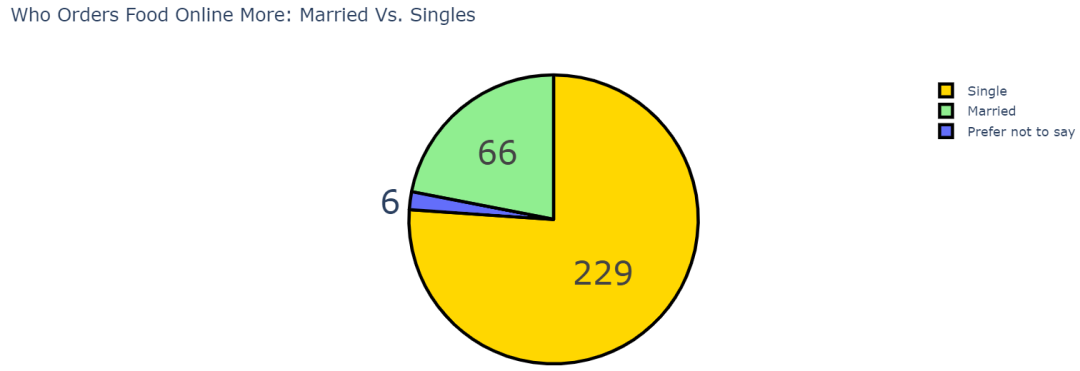
根据上图,76.1%的常客是单身人士。
现在我们再看看再次点餐的顾客的收入群体是怎样的:
income = buying_again_data["Monthly Income"].value_counts()label = income.indexcounts = income.valuescolors = ['gold','lightgreen']fig = go.Figure(data=[go.Pie(labels=label, values=counts)])fig.update_layout(title_text='Which Income Group Orders Food Online More')fig.update_traces(hoverinfo='label+percent', textinfo='value', textfont_size=30,marker=dict(colors=colors, line=dict(color='black', width=3)))fig.show()
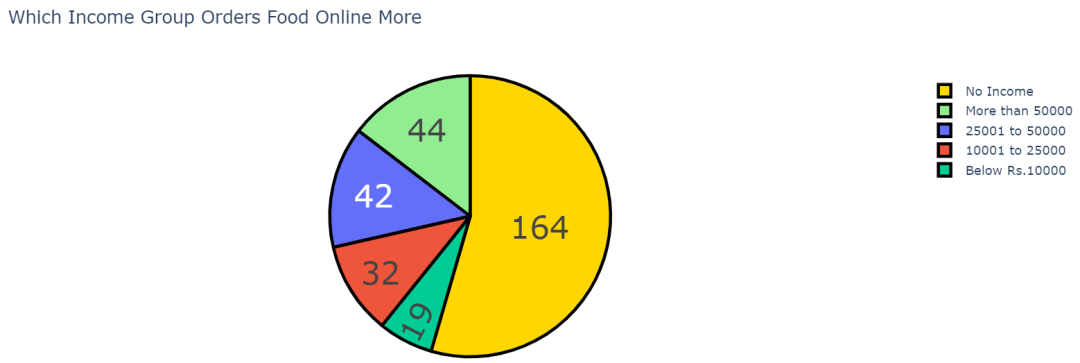
根据上图,54%的客户不属于任何收入群体。她们可以是家庭主妇或学生。
现在我们为训练机器学习模型的任务准备数据。这里我将所有离散特征转换为数值型:
data["Gender"] = data["Gender"].map({"Male": 1, "Female": 0})data["Marital Status"] = data["Marital Status"].map({"Married": 2,"Single": 1,"Prefer not to say": 0})data["Occupation"] = data["Occupation"].map({"Student": 1,"Employee": 2,"Self Employeed": 3,"House wife": 4})data["Educational Qualifications"] = data["Educational Qualifications"].map({"Graduate": 1,"Post Graduate": 2,"Ph.D": 3, "School": 4,"Uneducated": 5})data["Monthly Income"] = data["Monthly Income"].map({"No Income": 0,"25001 to 50000": 5000,"More than 50000": 7000,"10001 to 25000": 25000,"Below Rs.10000": 10000})data["Feedback"] = data["Feedback"].map({"Positive": 1, "Negative ": 0})data.head()

现在我们训练一个机器学习模型来预测客户是否会再次订购。
我首先将数据分为训练集和测试集:
from sklearn.model_selection import train_test_splitx = np.array(data[["Age", "Gender", "Marital Status", "Occupation","Monthly Income", "Educational Qualifications","Family size", "Pin code", "Feedback"]])y = np.array(data["Output"])X_train, X_test, y_train, y_test=train_test_split(x, y, test_size=0.2, random_state=4)
然后训练一个随机森林分类器:
from sklearn.ensemble import RandomForestClassifiermodel = RandomForestClassifier()model.fit(X_train, y_train)model.score(X_test, y_test)
模型在测试集上的准确率约为 94.87%。

















 428
428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









