






前言
在使用大模型处理书籍 PDF 时,有时你会遇到扫描版 PDF,也就是说每一页其实是图像形式。这时,大模型需要先从图片中提取文本,而这就需要借助 OCR(光学字符识别)技术。``
像
Gemini 2.5
这样的强大模型,具备非常强的从图片中提取文本的能力。实际上,我们完全可以利用它来执行
OCR
任务。
利用这样的大模型进行 OCR,不仅能处理复杂的图像场景,还能理解文本的结构,保留格式,并正确处理表格、标题等内容,为后续的文本分析、自动化处理和智能搜索提供强大的支持。这种结合 OCR 和 NLP 的智能文档处理方式,正在成为解决实际问题的强大工具。
然而,像 Gemini 这样的强大模型只能通过远程访问,且存在 API 受限和高成本的问题。那么,是否有可能在本地部署类似的大模型来完成这一任务呢?
虽然本地部署或直接安装已经有很多方案,后期文章中我们也将逐一比较。但我们更想自己手撸一个,想着将来大模型不断升级之中我们也能紧随其后直接升级是不**。**
一、选择有多模态能力的大模型
首先,我们去 Hugging Face 找找具有这种本事的大模型。
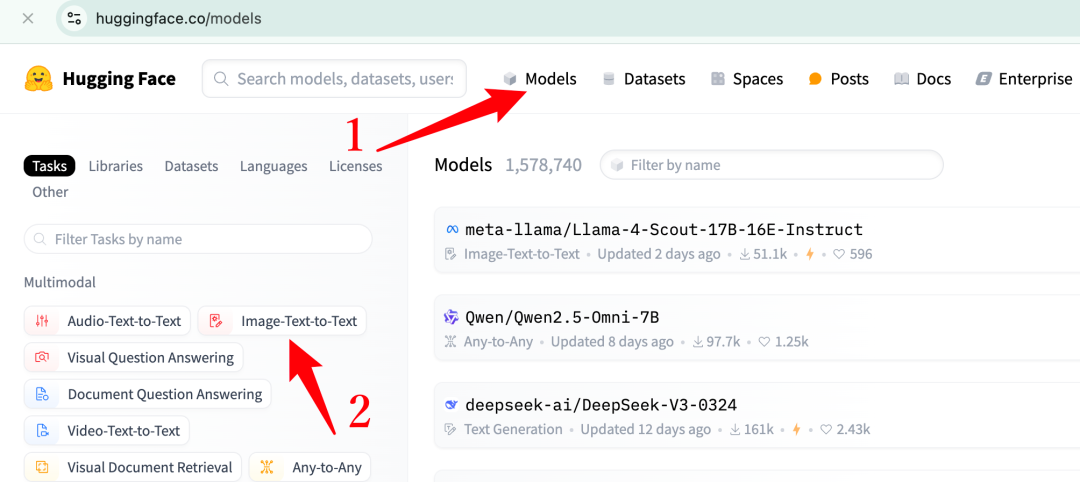
看到 Image-Text-to-Text 没有,它表示模型能够处理图像和文本输入,符合我们的任务要求。点击进去,首先看到的是一批新发布的模型,
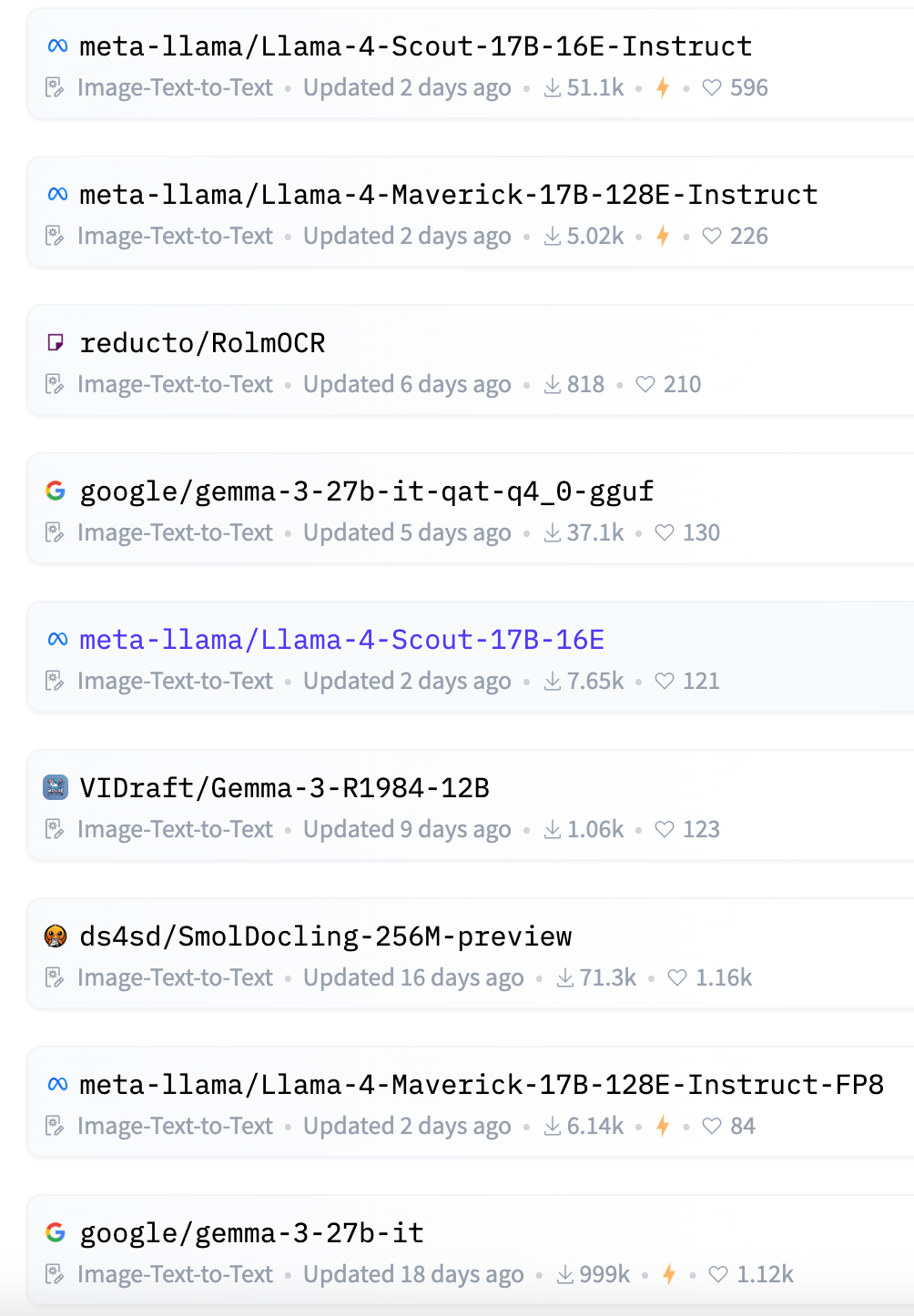
我们往后翻,找到下面这个 https://huggingface.co/Qwen/Qwen2.5-VL-3B-Instruct。
选这个模型的主要原因是想在笔记本上也能跑起来,所以参数量不能太多。先用我的 Macbook Air 试试本地大模型的 OCR 能力,然后再部署到显卡好一点的电脑上去干活。
代码放在
github
仓库:
https://github.com/mathinml/pdf2md
二、分析项目任务
本项目的任务明确如下:实现一个本地部署的多模态大语言模型,如 Qwen2.5-VL,用于从 PDF 文件中提取文字内容并完成 OCR 任务,最好保留表格形式,并将其转换为 Markdown 文档。模型是可选的,只需调整参数即可切换到其他模型。尽管这个功能看似简单,但它为后续更复杂任务奠定了基础。我们使用两款电脑来测试:Macbook Air M3 处理器,16G 内存;Ubuntu,V100 32G 显存。
¸用到的库
该项目主要涉及三部分,即 Transformers, vLLM 以及具体的大模型如 QWen2.5-VL。这个模型是基于 Transformer 架构开发的多模态模型。具体通过 Hugging Face 的 Transformers 库来加载和使用它,并选择使用 vLLM 来优化 Qwen2.5-VL 模型的推理性能。考虑到后期可能会实际部署到高性能电脑上,因此选择 vLLM,而不是 Ollama。
Transformers, vLLM 以及 QWen2.5-VL 之间的关系如下图所示。
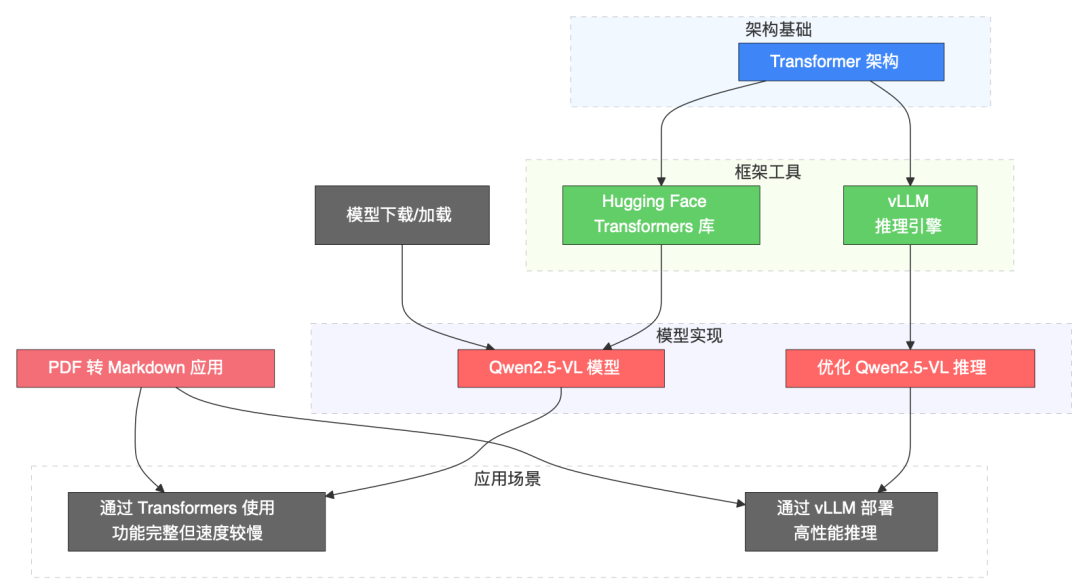
这个关系图展示了三者之间的依赖和协作,具体如下,
Transformers是基础框架:QWen2.5-VL的代码和模型结构依赖于Hugging Face Transformers库。开发者和用户需要安装最新版本的Transformers来加载和运行QWen2.5-VL。vLLM是推理优化引擎:vLLM增强了QWen2.5-VL的推理性能,尤其是在处理视觉和视频任务时。它通过张量并行、动态内存管理等技术,使QWen2.5-VL能够在生产环境中高效运行。vLLM需要与Transformers配合使用,并确保版本兼容(例如,某些版本的Transformers可能需要从源代码安装)。QWen2.5-VL是应用模型:它是具体的多模态模型,利用Transformers提供的架构和vLLM的推理优化来实现其功能。换句话说,QWen2.5-VL的设计目标是处理复杂的视觉语言任务,而Transformers和vLLM则是其技术支撑。
三、设计程序流程程序流程以及几个主要 Python 文件之间的关系如下图所示。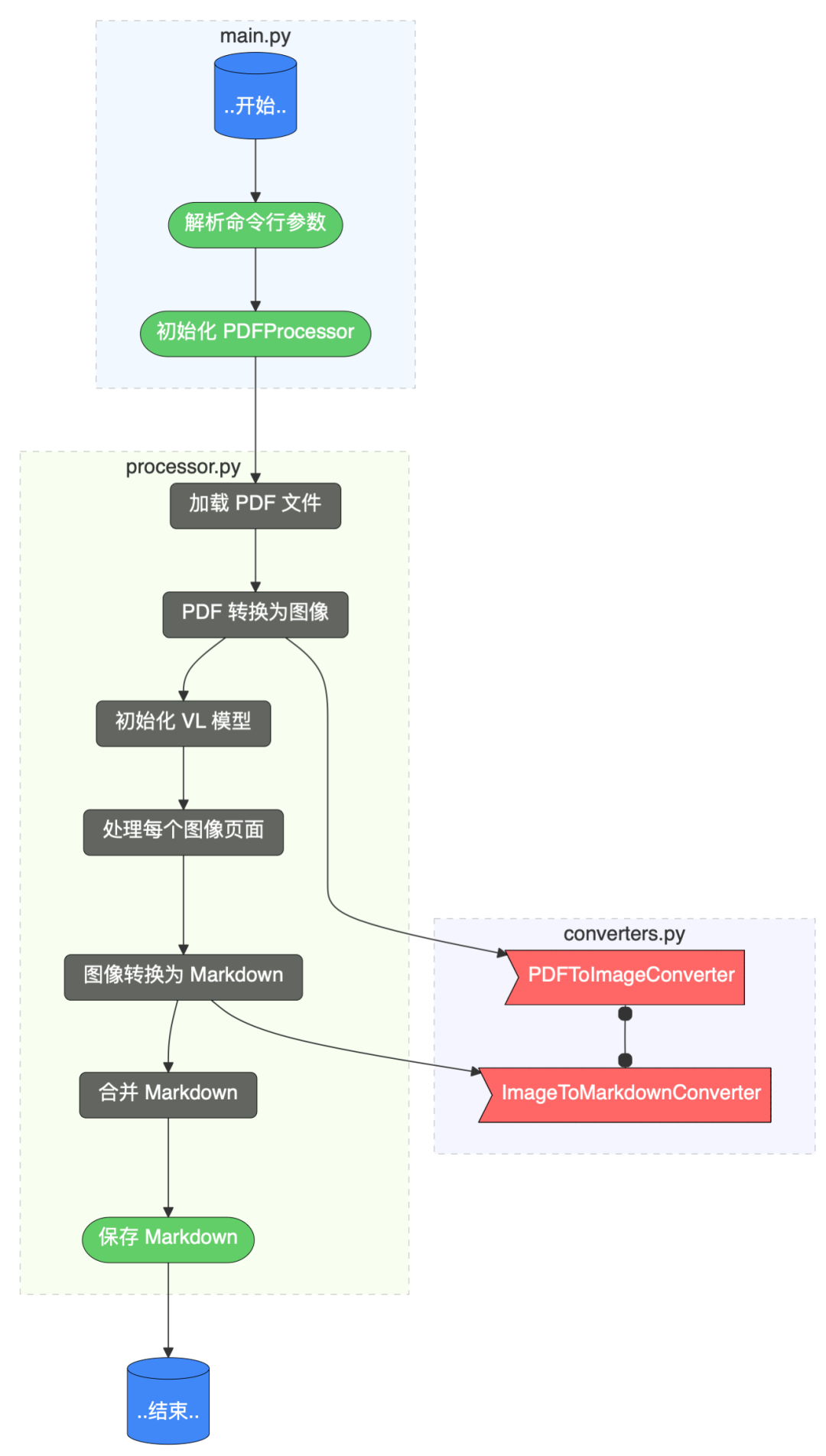
这个程序的主要功能是将 PDF 文件转换为 Markdown 格式,整个流程可以总结如下:1、命令行参数解析:通过 cli.py 中的 parse_args 函数解析用户输入的命令行参数;主要参数包括:PDF 文件路径、模型路径、输出文件路径等。2、初始化处理器:在 main.py 中初始化 PDFMarkdownProcessor 处理器;该处理器是整个转换过程的核心控制器。3、PDF 处理阶段:加载指定的 PDF 文件;使用 PDFToImageConverter 将 PDF 文件转换为图像序列,图像分辨率默认为 1024 宽。4、模型初始化:加载指定的视觉语言模型(如 Qwen2.5-VL-3B-Instruct);该模型需要提前下载到本地指定目录。5、图像处理与转换:对每个 PDF 页面生成的图像进行处理;使用 ImageToMarkdownConverter 将图像内容转换为 Markdown 文本;这一步利用视觉语言模型识别图像中的文本、表格、图片等内容。6、结果整合与输出:合并所有页面转换得到的 Markdown 内容;将最终的 Markdown 文本保存到指定的输出文件中。整个流程体现了模块化设计思想,各个组件职责明确,便于维护和扩展。用户只需通过简单的命令行参数即可完成从 PDF 到 Markdown 的转换过程。
四、下载模型
可以通过命令 huggingface-cli download 来下载 Qwen2.5-VL,但如果 huggingface 不方便使用,可以选择用 modelscope。比如我们要使用的这个模型文件放在这里:https://modelscope.cn/models/Qwen/Qwen2.5-VL-3B-Instruct/files先安装 modelscope:pip install modelscope然后用以下命令,modelscope download --model Qwen/Qwen2.5-VL-3B-Instruct --local_dir ../local_models/Qwen2.5-VL-3B-Instruct将完整模型库文件下载到指定的本地目录 ../local_models/Qwen2.5-VL-3B-Instruct 中。
五、转化效果
对于 1024 分辨率的图像,在 Macbook Air 上转化一页需要六、七分钟,虽然有点久,但至少也能跑起来了,而在 V100 上只需要 10 秒+。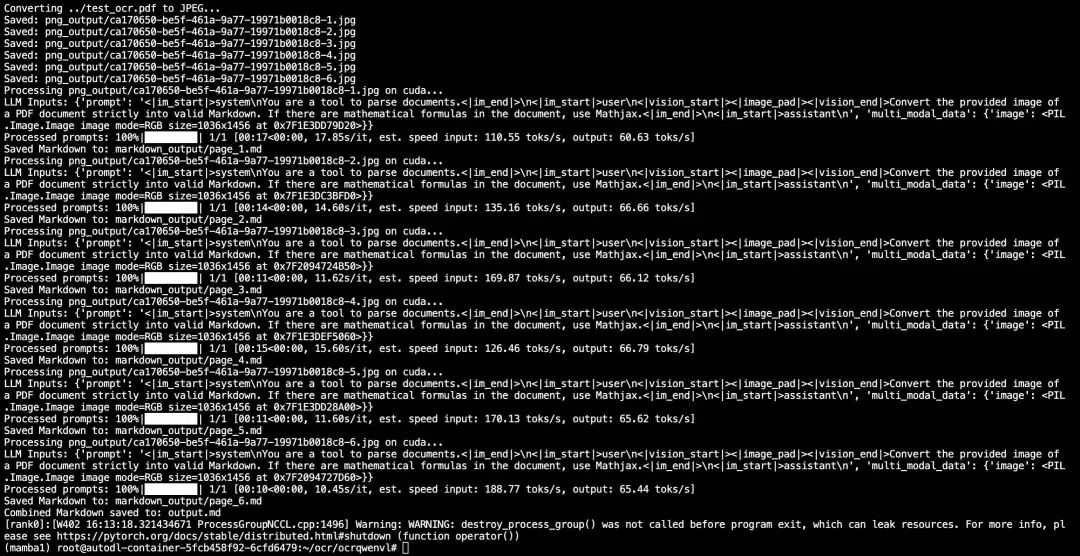 如果页面较清晰,可以降低分辨率,那样自然会提高转化效率。另外,程序中有个参数
如果页面较清晰,可以降低分辨率,那样自然会提高转化效率。另外,程序中有个参数 quantization=None 表明没有启用量化,保持了模型的完整精度。如果想进一步提高效率,可以使用量化版本,即 Qwen/Qwen2.5-VL-3B-Instruct-AWQ。
转化效果
从 PDF 文件中提取的图像,

转化为 Markdown 后,效果如下图所示。是不是文字、表格和数学公式都还保持的不错。
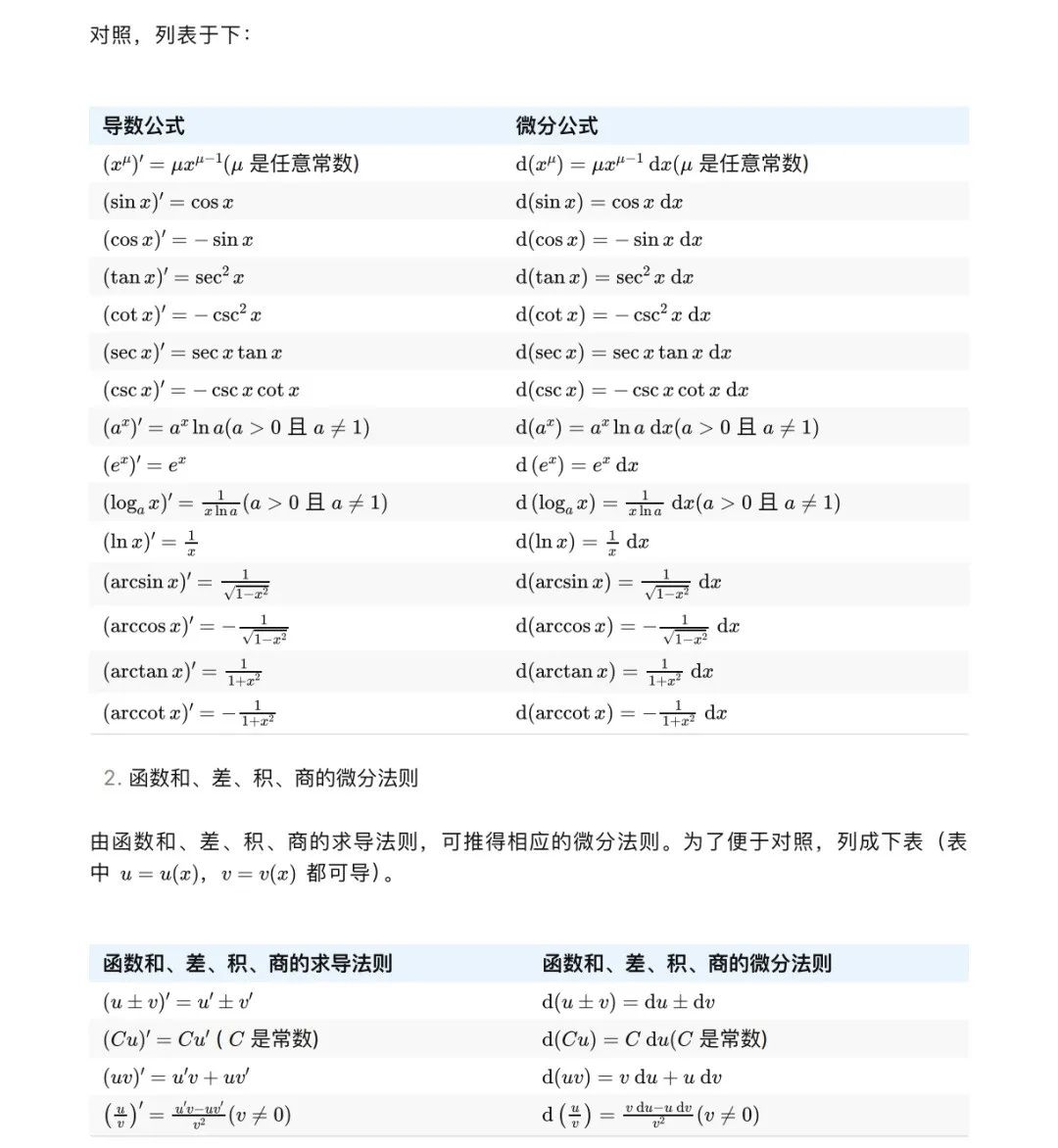
如果想要进一步转成 Word,可以把 Markdown 就当做中间格式,安装一个包 Pandoc,然后一条指令就能转化:pandoc document.md -o document.docx。或者简单点直接安装编辑器 Typora,导出即可。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 3233
3233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









