






在过去三周的工作中,我们围绕MicroLens、PixelRec、Amazon等多模态推荐系统数据集展开数据清洗、预处理、召回模块构建等一系列实践操作。随着对多模态数据结构和处理方式的逐步深入,我们团队开始进一步思考:如果把推荐系统中的多模态表征能力放到更强大的框架中,如当下火热的多模态大语言模型(Multimodal Large Language Models, MLLMs)中,会不会带来更加泛化且灵活的解决方案?
带着这个问题,本周我们系统阅读了四篇发表在ICLR 2024顶会上的代表性多模态LLM论文:NExT-GPT、DreamLLM、LaVIT、MoE-LLaVA,分别从“任意模态处理能力”“生成理解协同”“统一视觉语言预训练”“稀疏专家结构”等方向,展现了当前MLLM的发展趋势和关键创新。本文将逐一梳理它们的核心思想,结合我们的推荐系统实践,探讨其中对我们项目的潜在启示与借鉴价值。
一、NExT-GPT:实现“任意输入-任意输出”的多模态对齐梦想
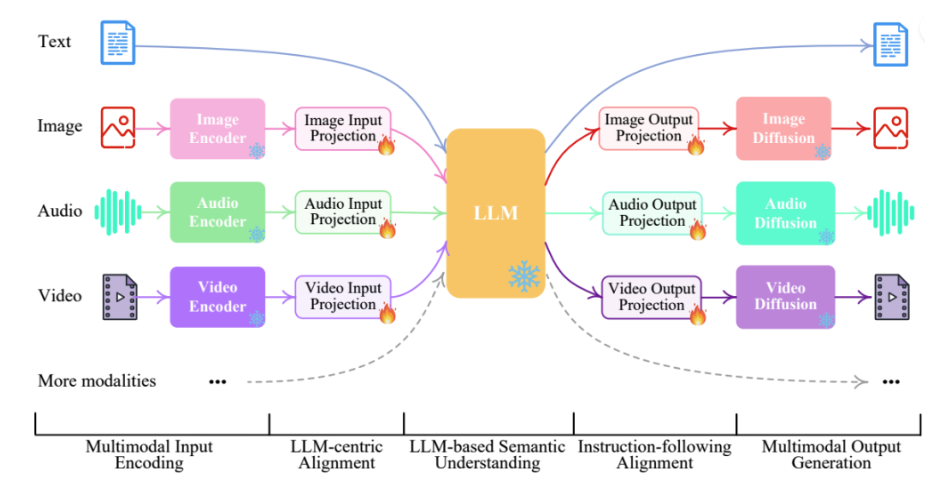
1.1 核心观点
NExT-GPT尝试解决的,是一个几乎“终极”的多模态目标:模型能同时理解并生成文本、图像、音频、视频等任意模态的信息。它采用了模块化的架构——基于预训练LLM主体,加入不同模态的Adapter和多种解码器,再通过引入“MosIT”(模态切换指令调优)机制来实现灵活地模态互通。
更重要的是,NExT-GPT不追求完全重训整个LLM,而是仅通过调整1%的参数完成适配,显著降低了训练成本。
1.2 与项目关联
我们目前的多模态推荐系统主要以文本(如商品描述、评论)和图像(商品图)为主,而NExT-GPT展示了一种完全解耦、统一处理所有模态的方法。如果未来我们希望构建一个支持更丰富用户行为理解的系统,比如分析用户上传视频、语音等内容,那NExT-GPT所提出的“任意模态感知-任意模态生成”路线就是极具启发性的参考方向。
二、DreamLLM:理解与创作双轮驱动的多模态通才
2.1 核心观点
DreamLLM强调“理解”与“创造”的协同关系。传统的MLLM往往只强调感知理解,但忽视内容生成的能力。而DreamLLM采用了“原始多模态空间采样”方式,直接在图像-文本空间联合建模,不借助外部特征提取器,从而实现更自然的文本-图像生成。
此外,DreamLLM支持生成“交错内容”(Interleaved Document),即图文混排的自由结构内容,是向AI内容创作方向迈出的重要一步。
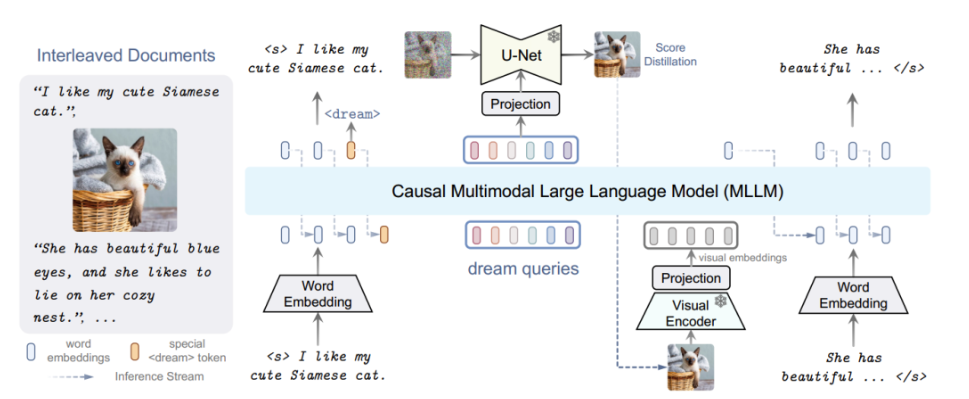
2.2 与项目关联
虽然我们当下的目标是推荐而非生成,但DreamLLM的理念仍然具有启发意义。推荐的本质是理解用户意图并生成反馈内容——推荐结果。而一个系统如果不仅能理解图片和文本,还能“创作”商品描述、甚至生成个性化商品封面,那么它就能更贴合用户的审美与需求。
此外,DreamLLM不使用传统视觉特征提取器,也提醒我们反思:当前我们使用的ResNet、ViT等模型是否已经过时?是否可以尝试更原始的、联动式的图文嵌入方法,提升推荐系统的表征能力?
三、LaVIT:打通图文信息壁垒的“视觉标记化”
LaVIT最大的创新点是“将图像内容标记化”,即通过视觉离散化模块,把图片转化为离散的token,然后输入语言模型处理,从而实现视觉与文本在输入层就对齐的能力。这种方式与传统将图像嵌入为高维向量不同,它强调图文“语义对等”,提升了模型对图文混合任务的适应能力此外,LaVIT是一个真正统一输入通道的模型,具备良好的多任务适应能力。
我们在项目中遇到的一个典型问题是:文本和图像信息在向量空间中差异过大,导致融合后难以产生语义一致性。而LaVIT的做法提供了一种思路:图像是否也可以“文本化”处理?例如我们是否可以引入CLIP tokenizer对商品图像进行token化处理,然后与文本token一起输入模型中?这种方法也可能提升我们在后续排序任务中的多模态融合质量。
四、MoE-LLaVA:稀疏专家机制带来的轻量化与精准性
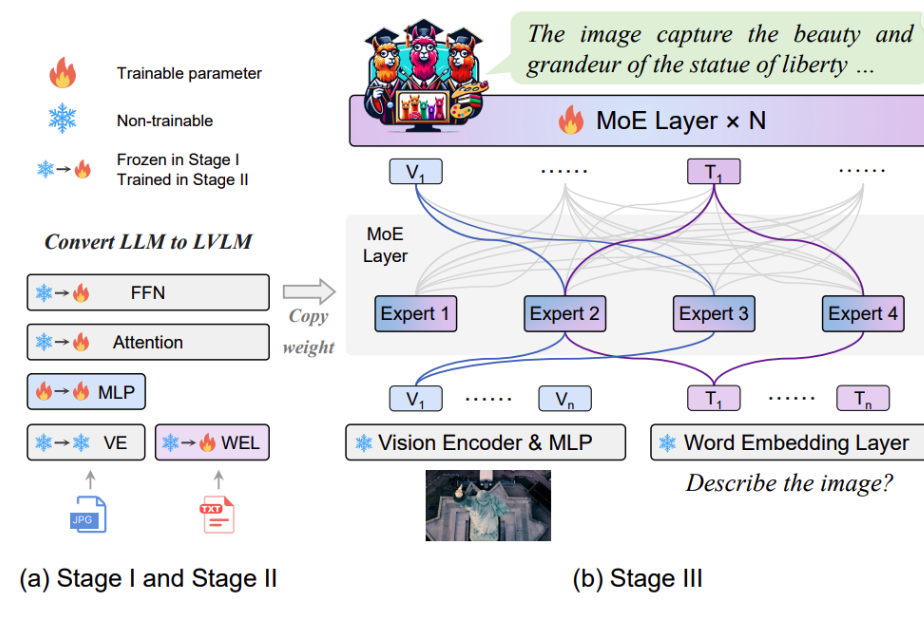
MoE-LLaVA的创新在于引入“稀疏专家”(Mixture of Experts, MoE)结构,只在推理时激活部分专家模块。这样既能保持模型总参数量的高容量,又能控制计算成本,提升训练和推理效率。实验显示,MoE-LLaVA在使用不到LLaVA-13B一半计算资源的情况下,实现了相当甚至更优的性能,尤其在图像问答任务中表现亮眼。对于资源受限的应用场景,如在边缘设备或中小企业部署推荐系统,轻量化是关键。而MoE结构正好提供了“一种稀疏但高效”的解决方案。如果我们未来尝试部署多模态推荐系统至真实业务中,MoE策略值得进一步研究。同时,稀疏激活专家也可引申为多模态信息的“注意力路由”策略,或可用于处理图文冗余与噪声问题。
-------------------------------------------
下面是第二次多模态推荐系统相关论文的调研
# MENTOR: Multi-level Self-supervised Learning for Multimodal Recommendation| AAAI'2024
1. 论文核心内容总结
问题背景:
- 电商场景中,传统推荐系统受限于数据稀疏性(用户-物品交互数据不足)和标签稀疏性(高质量标注数据稀缺)。
- 多模态推荐(视觉、文本等)通过利用多媒体信息缓解数据稀疏性,但面临模态噪声(不同模态分布差异大)和模态对齐难题。
MENTOR解决方案:
- 多模态融合:用GCN提取模态特异性特征,融合视觉和文本模态。
-多级自监督学习:
跨模态对齐任务:通过ID嵌入引导多级对齐,保留历史交互信息。
通用特征增强任务:从图和特征层面增强鲁棒性(抗噪声、抗扰动)。
实验验证:在三个公开数据集上表现优于基线模型。
2. 与LLM电商推荐系统的关联与可借鉴点
- 共同挑战:电商场景中用户长尾物品交互少,需利用多模态信息(如商品图片、描述、评论)。LLM生成的文本特征需与视觉/ID特征对齐(例如商品标题与图片的一致性)。
通过阅读这篇论文,我认为我们的电商推荐系统可借鉴该篇论文的如下技术:
- 多模态融合框架:可参考MENTOR的GCN-based特征提取与融合方法。并用LLM生成文本特征(如商品摘要),替代传统文本编码器,增强语义理解。同时可以可借鉴多级对齐任务,避免丢失历史交互信息。通过掩码语言建模(MLM)或图扰动增强LLM特征的鲁棒性(类似MENTOR的通用特征任务)。MENTOR强调保留历史交互信息,对电商推荐至关重要。可设计类似机制,确保LLM生成的特征不与用户行为数据冲突。
3. 对项目的启发与指导
LLM可视为强文本模态编码器,与其他模态(视觉、用户行为图)结合,提升推荐解释性和准确性。MENTOR的多级对齐减少噪声,可优化LLM输出与其他模态的融合效率(例如通过注意力机制)。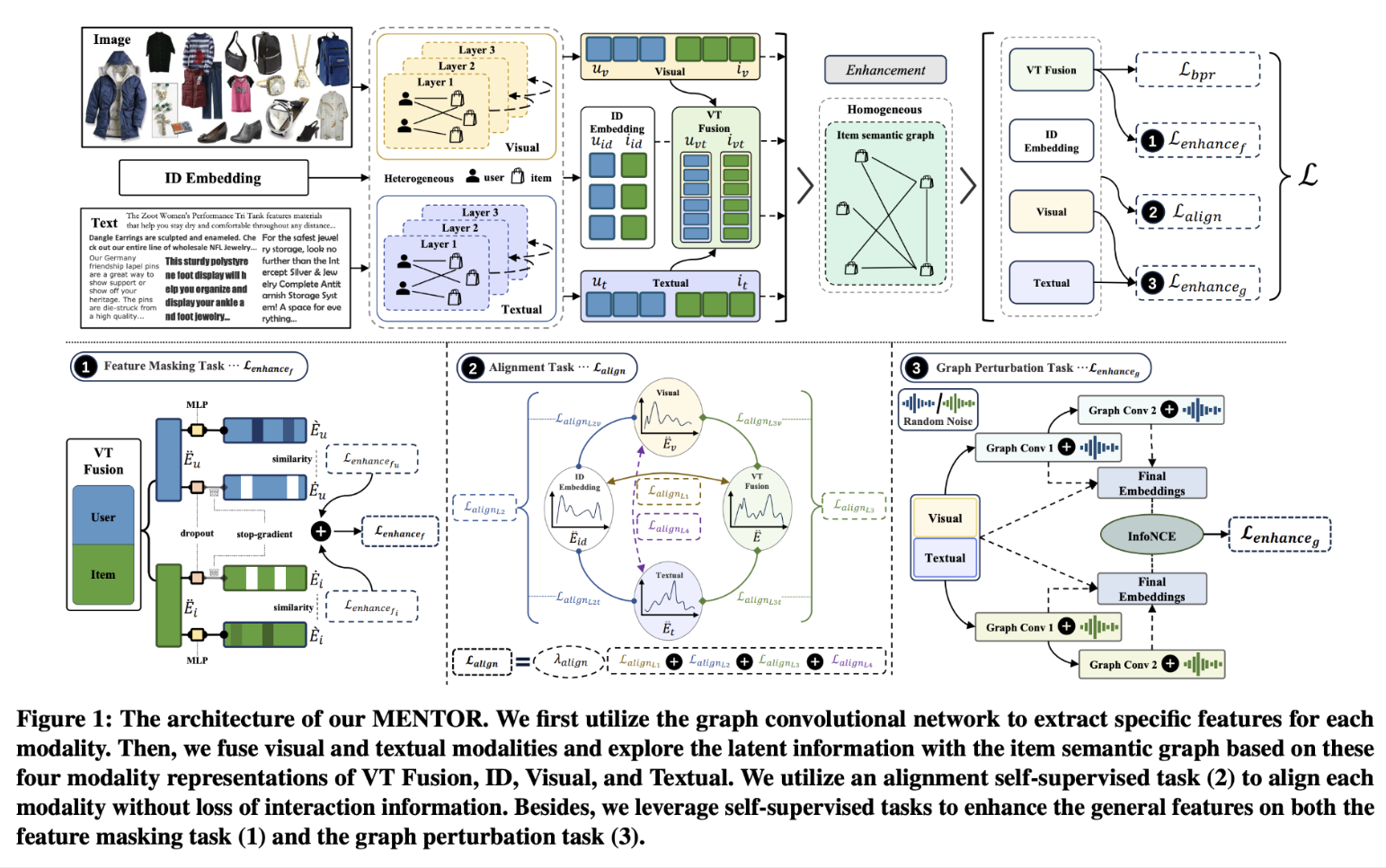
因此,在数据层面,我们可以构建商品多模态数据集(文本+图像+用户行为图),利用LLM生成富文本特征(如情感分析、关键词提取)。若标注数据少,我们可采用MENTOR的自监督策略,从无标注数据中学习。
对于我们的模型,可以用LLM作为模态编码器:LLM(如GPT-3.5)编码商品描述,替代传统文本编码器,提升语义理解。同时结合用户-物品交互图(如GCN),将LLM特征与协同过滤信号融合。
评估指标可以参考MENTOR的实验设计,除准确率外,加入模态对齐度(如特征相似性)、鲁棒性(对抗噪声)等指标。
但是在计算成本上,MENTOR依赖GCN,若项目需实时推荐,需优化LLM+图模型的推理效率。而且由于模态差异,LLM生成的文本特征分布可能与视觉特征差异更大,需更精细的对齐策略(如引入适配层)。
总之,这篇MENTOR为多模态推荐提供了模块化框架,其自监督学习和模态对齐方法可直接迁移至LLM电商推荐系统。关键是通过LLM增强文本模态表达,同时借鉴MENTOR的多级对齐和特征增强,解决数据稀疏与模态噪声问题。下一步可探索LLM如何替代MENTOR中的文本编码器,并设计更适合电商场景的自监督任务(如基于用户评论的对比学习)。
# Contrastive Modality-Disentangled Learning for Multimodal Recommendation
多模态推荐利用丰富的多模态信息来学习用户偏好,引起了广泛关注。大多数工作侧重于设计强大的编码器来提取多模态特征,并简单地将学习到的特征聚合在一起进行预测。因此,它们学习模态间知识(包括模态共享知识和模态独特知识)的能力有限。事实上,学习模态共享知识使我们能够对齐跨模态数据以融合异构模态特征。当推荐任务仅涉及少量共享特征并且必要信息包含在特定模态中时,学习模态独特知识同样重要。在本文中,我们提出了对比模态解缠学习(CMDL)来克服这一关键限制。CMDL 通过实现模态解缠来精确捕获模态间知识。具体而言,CMDL 首先将初始表示解缠为模态不变表示和模态特定表示。随后,CMDL 引入了一种新颖的对比学习方式来近似 MI 上界,以实现解缠正则化。在所提出的正则化基础上,CMDL 鼓励模态不变和模态特定表示分别捕获模态共享和模态独特知识,并在统计上相互独立。从实证上讲,在基准数据集上进行了广泛的实验,证明了 CMDL 与强大的多模态推荐器相比具有卓越的性能。
CMDL的pipeline如下所示:
这个多模态推荐系统(CMDL)的算法流程如下:
1. 构建物品-物品语义图(Construction of Item-Item Semantic Graphs)
• 通过视觉特征提取器和文本特征提取器,分别提取商品的视觉特征(如图片)和文本特征(如描述)。
• 根据这些特征构造视觉和文本模态的物品-物品语义图
2. 学习解耦的多模态表示(Learning Disentangled Multimodal Representation)
• 采用 LightGCN 处理全局交互图 G^b ,学习全局交互表示 h_r^v 和 h_r^t 。
• 通过注意力机制进一步学习解耦的模态特定表示:
• 视觉模态特定表示 e_r^v
• 文本模态特定表示 e_r^t
• 共享模态无关表示 e_r^c
• 通过约束 h_r^v - e_r^v 、 h_r^t - e_r^t 和 h_r^t - e_r^c 来解耦模态信息。
3. 偏好预测与损失优化(Preference Prediction & Prediction Loss)
• 结合最终的多模态表示 e_r^m 和交互表示 h_r^n 生成用户和物品的表示 e_i 和 e_u 。
• 采用 BPR(Bayesian Personalized Ranking)损失进行优化。
4. 基于互信息的解耦正则化(MI-Based Disentanglement Regularization)
• 通过互信息(MI)估计上、下界来约束解耦表示:
• 互信息下界估计 I(h_r^v; e_r^c) 和 I(h_r^t; e_r^c) 。
• 互信息上界估计 I(h_r^v; e_r^c) 、 I(h_r^t; e_r^c) 和 I(e_r^v; e_r^c) 。
CMDL 通过构建物品-物品语义图提取视觉和文本模态特征,并通过 LightGCN 和注意力机制学习解耦的多模态表示。同时,采用基于互信息的正则化方法提高模态解耦能力,并最终利用 BPR 损失优化推荐效果。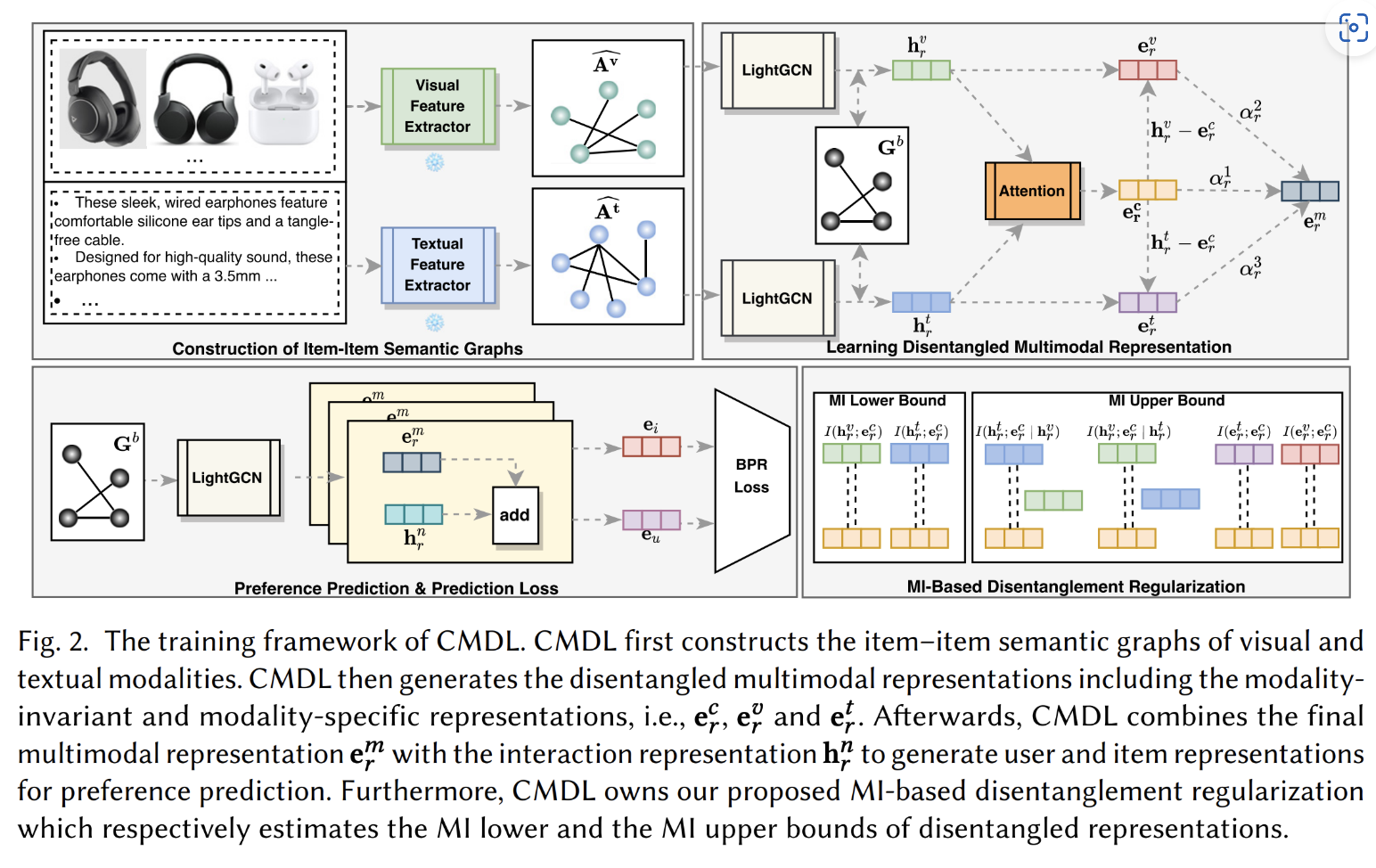
这篇文章提出的 CMDL(Contrastive Multimodal Disentangled Learning) 主要聚焦于多模态表示的解耦学习,尤其是如何从视觉和文本模态中提取信息,同时保证模态间的信息独立性,从而提高推荐系统的表现。对于我们的基于 LLM 的多模态电商推荐系统,这篇文章有几个值得借鉴的地方。
CMDL 采用 物品-物品语义图(Item-Item Semantic Graphs) 来建模不同模态的信息关联,这对基于 LLM 的电商推荐系统有直接的启发。在 LLM 时代,多模态信息(如商品图片、文本描述、用户评论等)可以通过大模型的嵌入层来获得统一的表示,但如何构造高质量的多模态关系图仍是关键。你可以借鉴 CMDL 的思路,构造一个基于 LLM 生成的 语义关系图,不仅包含商品间的相似度信息,还可以结合 LLM 提取的概念关联(如同类型、替代品、配套商品等),从而增强推荐系统的可解释性和泛化能力。
然后我发现,CMDL 在 学习解耦的多模态表示(Disentangled Multimodal Representation Learning) 方面的做法值得关注。它通过 LightGCN 进行全局交互建模,并利用注意力机制学习模态特定(视觉、文本)和模态共享(通用)表示,同时引入互信息(Mutual Information, MI)进行正则化,确保不同模态的信息不被混淆。这一思路对于基于 LLM 的推荐系统同样适用。LLM 生成的文本嵌入往往包含丰富的多模态知识,但如何区分哪些信息是文本模态特有的,哪些信息是跨模态共享的,是当前多模态推荐研究中的一个难点。因此,你可以考虑引入类似的解耦学习方法,让 LLM 生成的嵌入在不同模态间进行有针对性的分解,比如利用 对比学习(Contrastive Learning) 或 互信息最小化 来确保视觉、文本和交互特征各司其职,从而提升模型的可解释性和鲁棒性。
此外CMDL 采用 基于互信息的正则化(MI-Based Disentanglement Regularization) 约束模态特定和模态共享的表示分布,这一做法在 LLM 时代仍然具有价值。现代 LLM 模型(如 GPT-4、Gemini、Mistral)虽然可以直接处理多模态数据,但在多模态融合时,仍然容易出现模态信息不均衡的问题。例如,在商品推荐任务中,文本描述可能包含比图片更丰富的细节信息,导致模型对文本模态的依赖性更强,而忽略视觉模态。因此,可以借鉴 CMDL 的 互信息约束策略,在 LLM 生成的多模态表示中,通过互信息上界和下界的估计,控制不同模态的独立性和互补性,从而提高模型的稳定性和泛化能力。
在 优化目标 方面,CMDL 采用 BPR Loss 进行优化,而在 LLM 结合推荐系统的场景下,你可以考虑将其拓展为 融合对比学习、生成式学习以及排序优化 的多任务损失函数。例如,可以结合 基于 LLM 的生成任务(如摘要生成、问答预测),让 LLM 在理解商品信息的同时优化推荐目标。此外,可以设计 用户行为模拟任务,让 LLM 预测用户可能的购买路径,从而提高推荐的精准度和用户体验。
这篇文章在 多模态表示解耦、基于图结构的关系建模、互信息正则化以及优化目标设计 方面提供了许多值得借鉴的思路。在 LLM 赋能的多模态推荐系统中,你可以结合这些方法,让 LLM 不仅作为特征提取工具,更作为推荐过程中的核心推理模块,提高模型的多模态理解能力和推荐效果。

















 2836
2836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









