







对于STATA回归结果以前一直不清不楚,每次都需要baidu一波,因此今天将结果相关分析记录下:
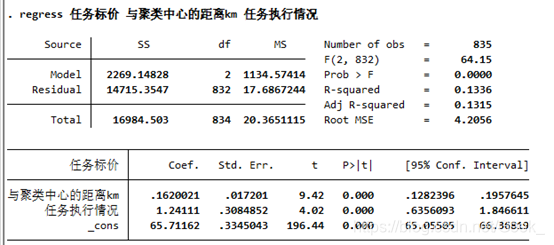
如上图
上面左侧的表是用来计算下面数据的,分析过程中基本不会用到
右侧从上往下
1.Number of obs 是样本容量
2.F是模型的F检验值,用来计算下面的P>F
3.P>F是模型F检验落在小概率事件区间的概率,你的模型置信水平是0.05,也就是说P>F值如果大于0.05,那么模型就有足够高的概率落在F函数的小概率区间,简单的说,如果这个值大于0.05你这个模型设定有就问题,要重新设定模型
4.R-squard也就是模型的R²值,拟合优度,这个数越大你的模型和实际值的拟合度就越高,模型越好
5.Adj .R-squard 这个是调整过的R²,跟上面R²差不多,只需要关注一个
6.Root mse 是残差标准差,值越大残差波动越大,模型越不稳定(这个值我分析的时候一般不太关注)
下侧表格
coef.是估计得到的系数值
std.err是标准差,这个数有重要意义,一般论文里都要求把标准差表示出来,这个数越大模型越不精确,越小越好
t是t检验值,t检验是用来检验某个系数是否显著区别于0的,在分析中这个值一般没什么意义,主要用来计算P>t
P>t,这个值是观察某个解释变量是否有效的主要参数,还是对于你设置的0.05的置信水平,如果这个值大于0.05说明对应的解释变量不能通过t检验,在模型中是不合格的,就需要作调整
后面两个就是置信区间了,95%的置信区间,一般意义不大
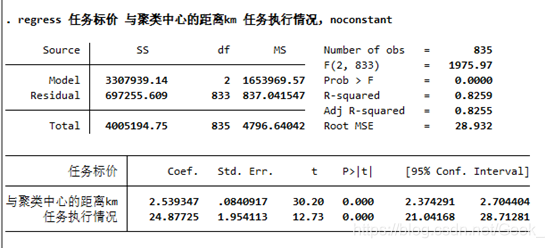
此外_cons 表示常数项,这个在回归之前可以设置,但目前我不太清楚,为什么加了常数项相关指标会降低,而没有常数项如下所示,其指标都较为良好,希望以后能把这个洞补上,此外,像这个结果,如果不考虑常数项,因为因变量标价一定是整数,所以自变量极大概率都是整数,因此这样子拟合其实没太大参考价值,甚至会得出一些与现实明显不符的结果,这个值得注意,因此最好加上常数项,以代表一些不可抗力因素。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









