









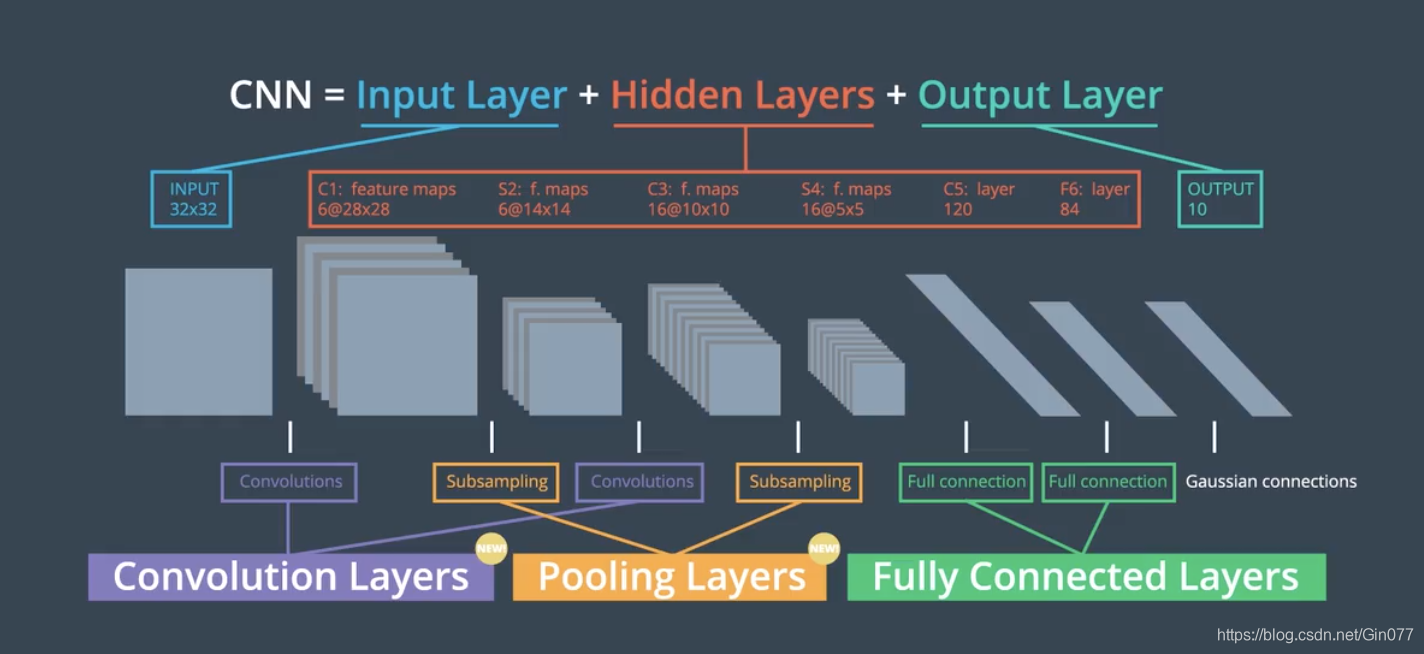
1、MLP和CNN的区别

MLP丧失了二维图像信息,必须转成向量
2、将全连接层转换为局部连接层
stride和填充:stride步长,对于超出范围的区域,可以删除或者填充默认值,根据需要选择(pandding分别对应valid和same)
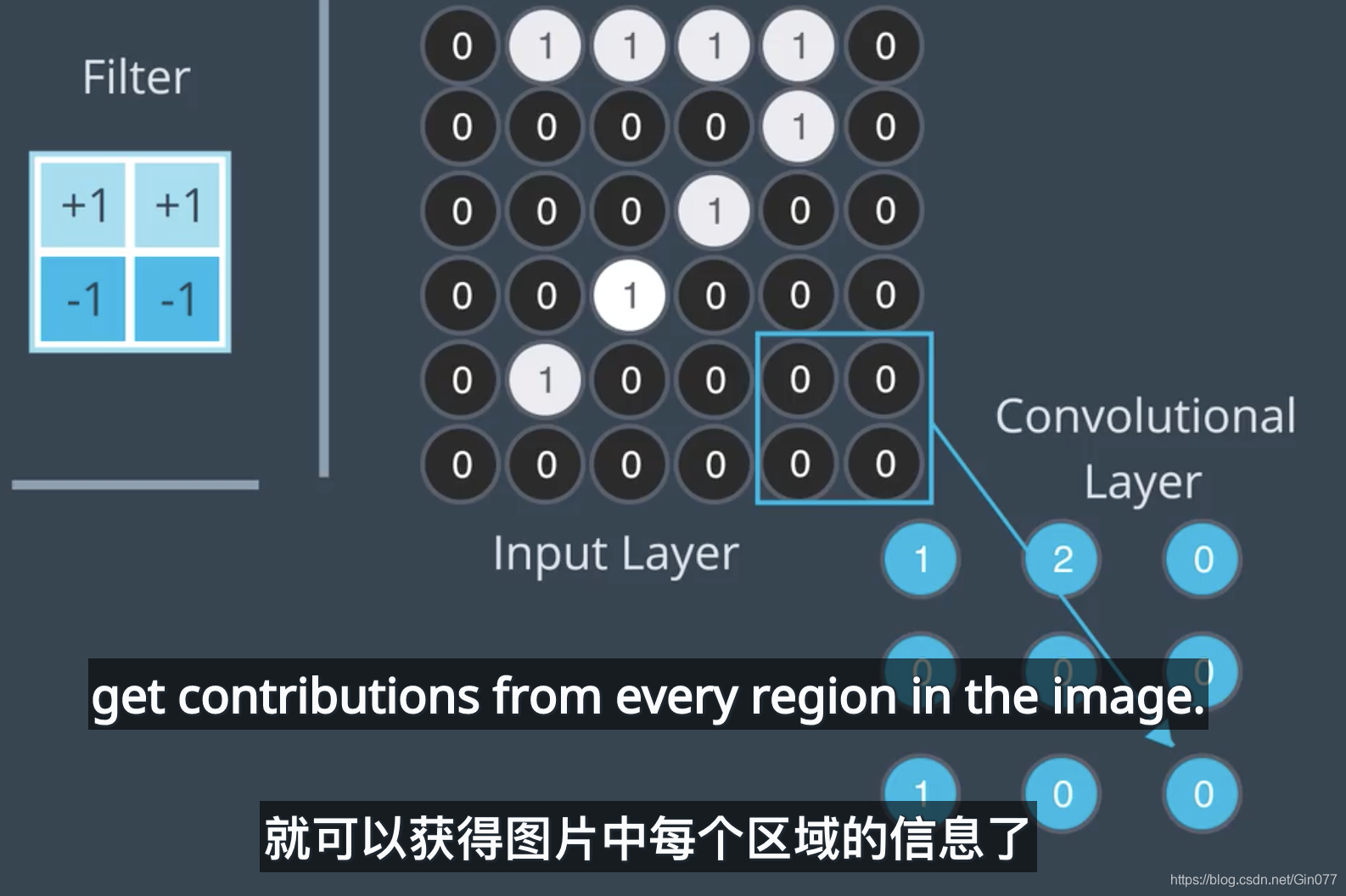
3、卷积层的维度
公式:卷积层中的参数数量
卷积层中的参数数量取决于 filters、kernel_size 和 input_shape 的值。我们定义几个变量:
K- 卷积层中的过滤器数量F- 卷积过滤器的高度和宽度D_in- 上一层级的深度
注意:K = filters,F = kernel_size。类似地,D_in 是 input_shape 元组中的最后一个值。
因为每个过滤器有 F*F*D_in 个权重,卷积层由 K 个过滤器组成,因此卷积层中的权重总数是 K*F*F*D_in。因为每个过滤器有 1 个偏差项,卷积层有 K 个偏差。因此,卷积层中的参数数量是 K*F*F*D_in + K。
公式:卷积层的形状
卷积层的形状取决于 kernel_size、input_shape、padding 和 stride 的值。我们定义几个变量:
K- 卷积层中的过滤器数量F- 卷积过滤器的高度和宽度H_in- 上一层级的高度W_in- 上一层级的宽度
注意:K = filters、F = kernel_size,以及S = stride。类似地,H_in 和 W_in分别是 input_shape 元组的第一个和第二个值。
卷积层的深度始终为过滤器数量 K。
如果 padding = 'same',那么卷积层的空间维度如下:
- height = ceil(float(
H_in) / float(S)) - width = ceil(float(
W_in) / float(S))
如果 padding = 'valid',那么卷积层的空间维度如下:
- height = ceil(float(
H_in-F+ 1) / float(S)) - width = ceil(float(
W_in-F+ 1) / float(S))
4、池化层:维度过高,参数就会过多,就容易过拟合,所以用池化层降维
有最大池化层和全局平均池化层等
5、CNN架构设计
卷积层:使得穿过卷积层的数组更深
池化层:用于减小空间维度

flatten之后输入全连接层
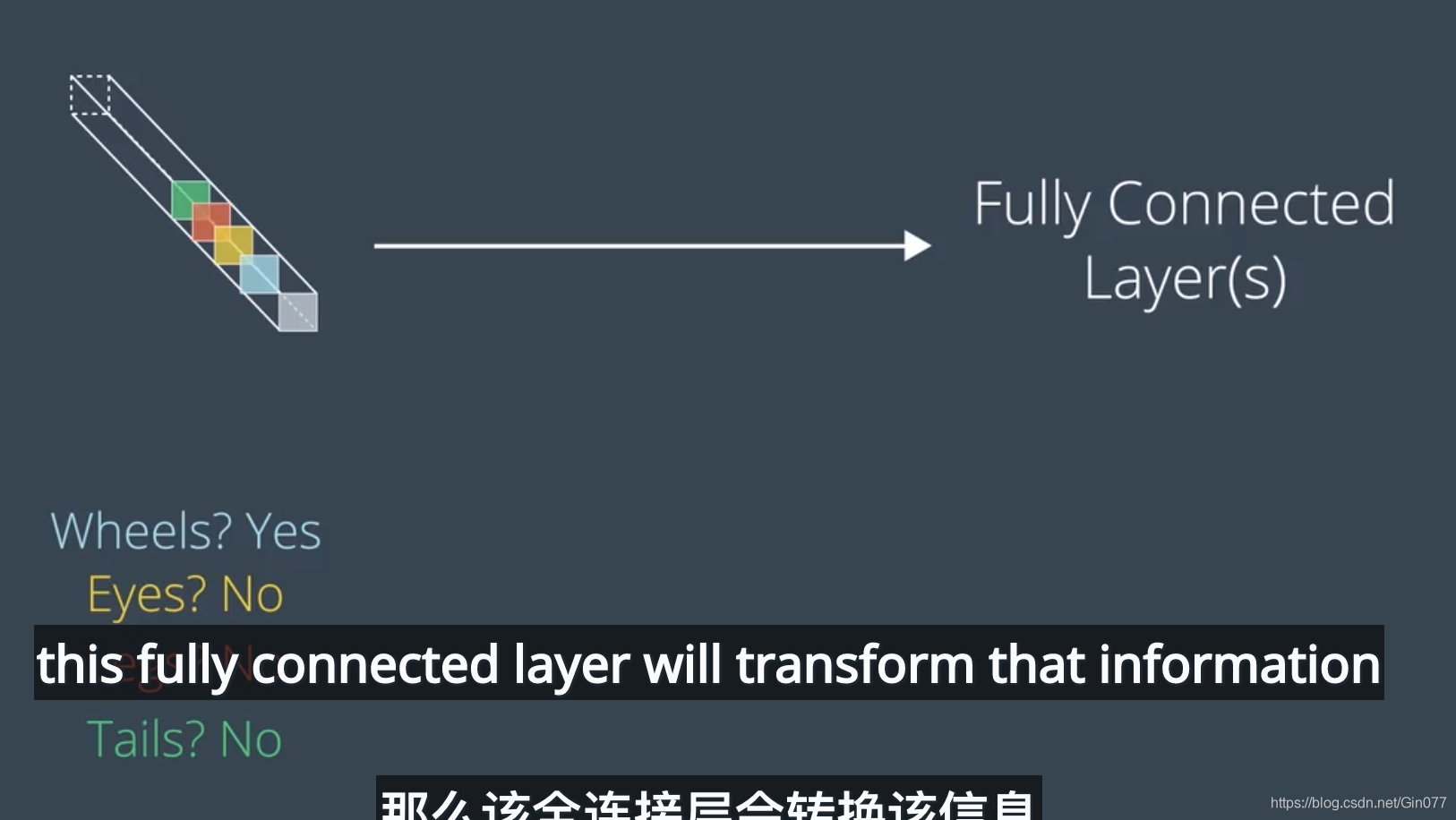
比如

该网络以三个卷积层(后面跟着最大池化层)序列开始。前 6 个层级旨在将图片像素数组输入转换为所有空间信息都丢失、仅保留图片内容信息的数组 。然后在 CNN 的第七个层级将该数组扁平化为向量。后面跟着两个密集层,旨在进一步说明图片中的内容。最后一层针对数据集中的每个对象类别都有一个条目,并具有一个 softmax 激活函数,使其返回概率。
6、图片增强
标度不变性:图片的大小
旋转不变性:图片的角度
平移不变性;在采集区的位置
通过对原图作平移、旋转,向训练集中添加更多新样本,也可以避免过拟合

7、梯度消失的问题
http://neuralnetworksanddeeplearning.com/chap5.html
8、CNN的可视化
https://cs231n.github.io/understanding-cnn/
https://blog.keras.io/how-convolutional-neural-networks-see-the-world.html
https://blog.openai.com/adversarial-example-research/
9、迁移学习
迁移学习是指对提前训练过的神经网络进行调整,以用于新的不同数据集。
取决于以下两个条件:
- 新数据集的大小,以及
- 新数据集与原始数据集的相似程度
使用迁移学习的方法将各不相同。有以下四大主要情形:
- 新数据集很小,新数据与原始数据相似
- 新数据集很小,新数据不同于原始训练数据
- 新数据集很大,新数据与原始训练数据相似
- 新数据集很大,新数据不同于原始训练数据


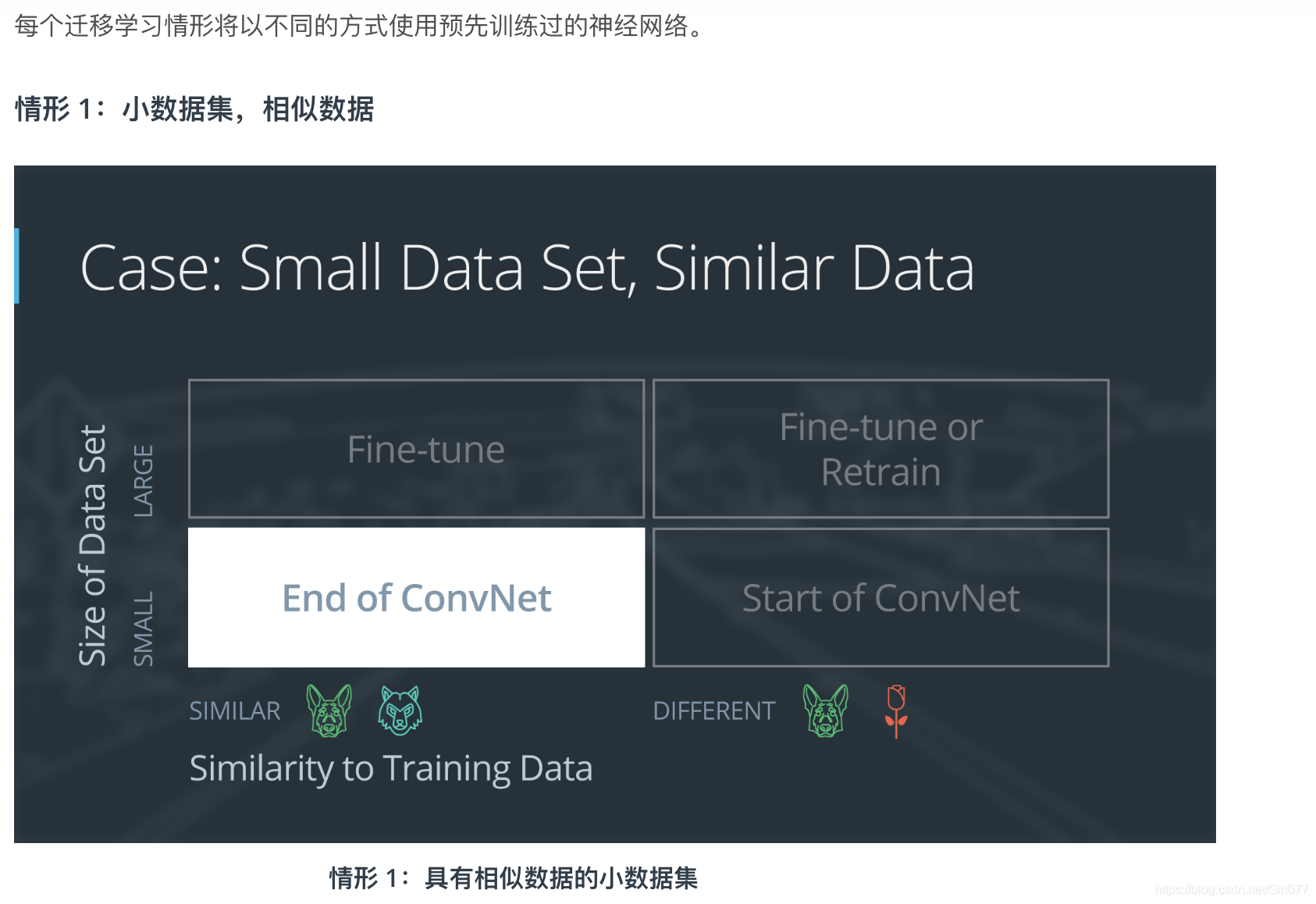
如果新数据集很小,并且与原始训练数据相似:
- 删除神经网络的最后层级
- 添加一个新的完全连接层,与新数据集中的类别数量相匹配
- 随机化设置新的完全连接层的权重;冻结预先训练过的网络中的所有权重
- 训练该网络以更新新连接层的权重
为了避免小数据集出现过拟合现象,原始网络的权重将保持不变,而不是重新训练这些权重。
因为数据集比较相似,每个数据集的图片将具有相似的更高级别特征。因此,大部分或所有预先训练过的神经网络层级已经包含关于新数据集的相关信息,应该保持不变。
以下是如何可视化此方法的方式:
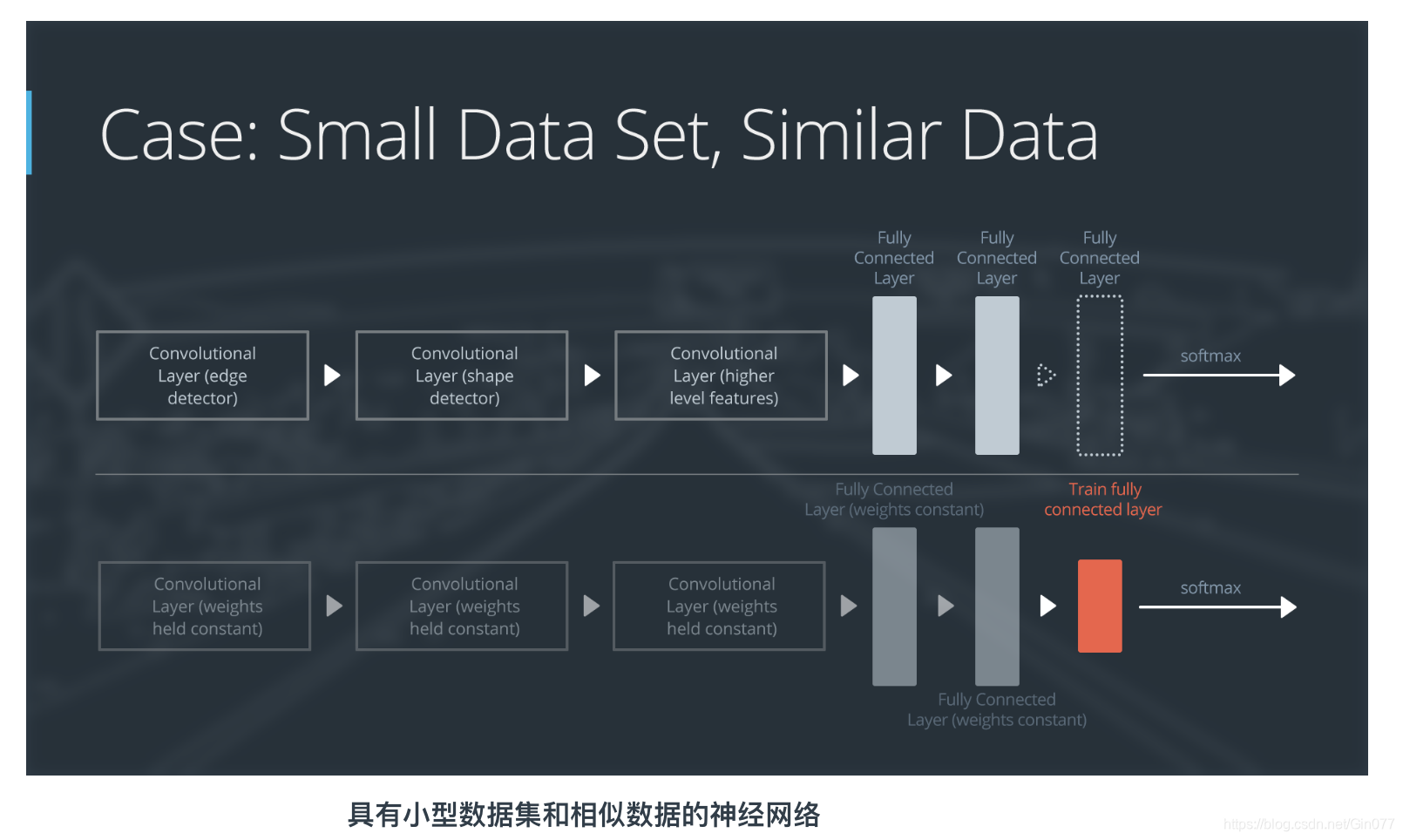
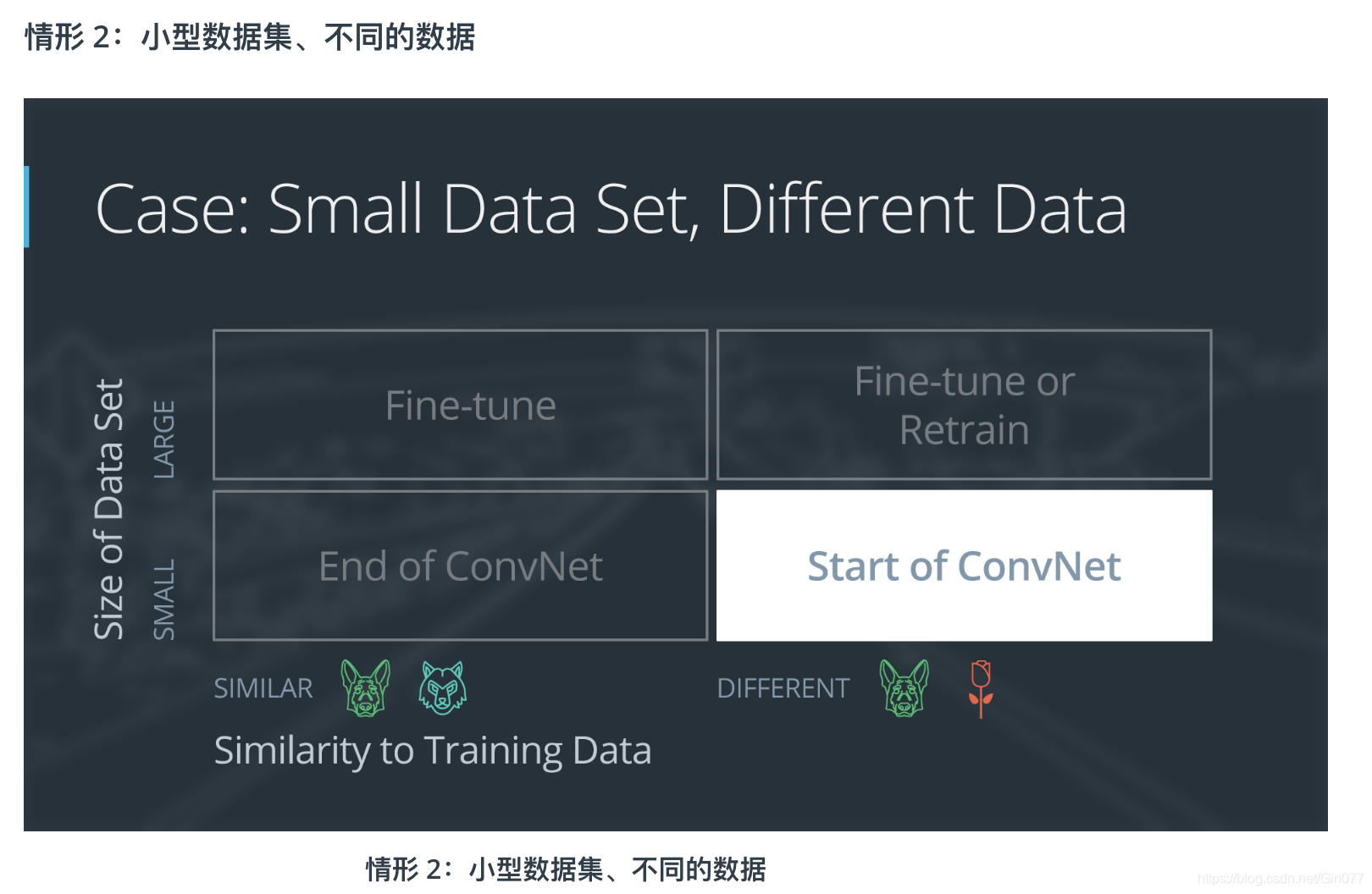
如果新数据集很小,并且与原始训练数据不同:
- 将靠近网络开头的大部分预先训练过的层级删掉
- 向剩下的预先训练过的层级添加新的完全连接层,并与新数据集的类别数量相匹配
- 随机化设置新的完全连接层的权重;冻结预先训练过的网络中的所有权重
- 训练该网络以更新新连接层的权重
因为数据集很小,因此依然需要注意过拟合问题。要解决过拟合问题,原始神经网络的权重应该保持不变,就像第一种情况那样。
但是原始训练集和新的数据集并不具有相同的更高级特征。在这种情况下,新的网络仅使用包含更低级特征的层级。
以下是如何可视化此方法的方式:

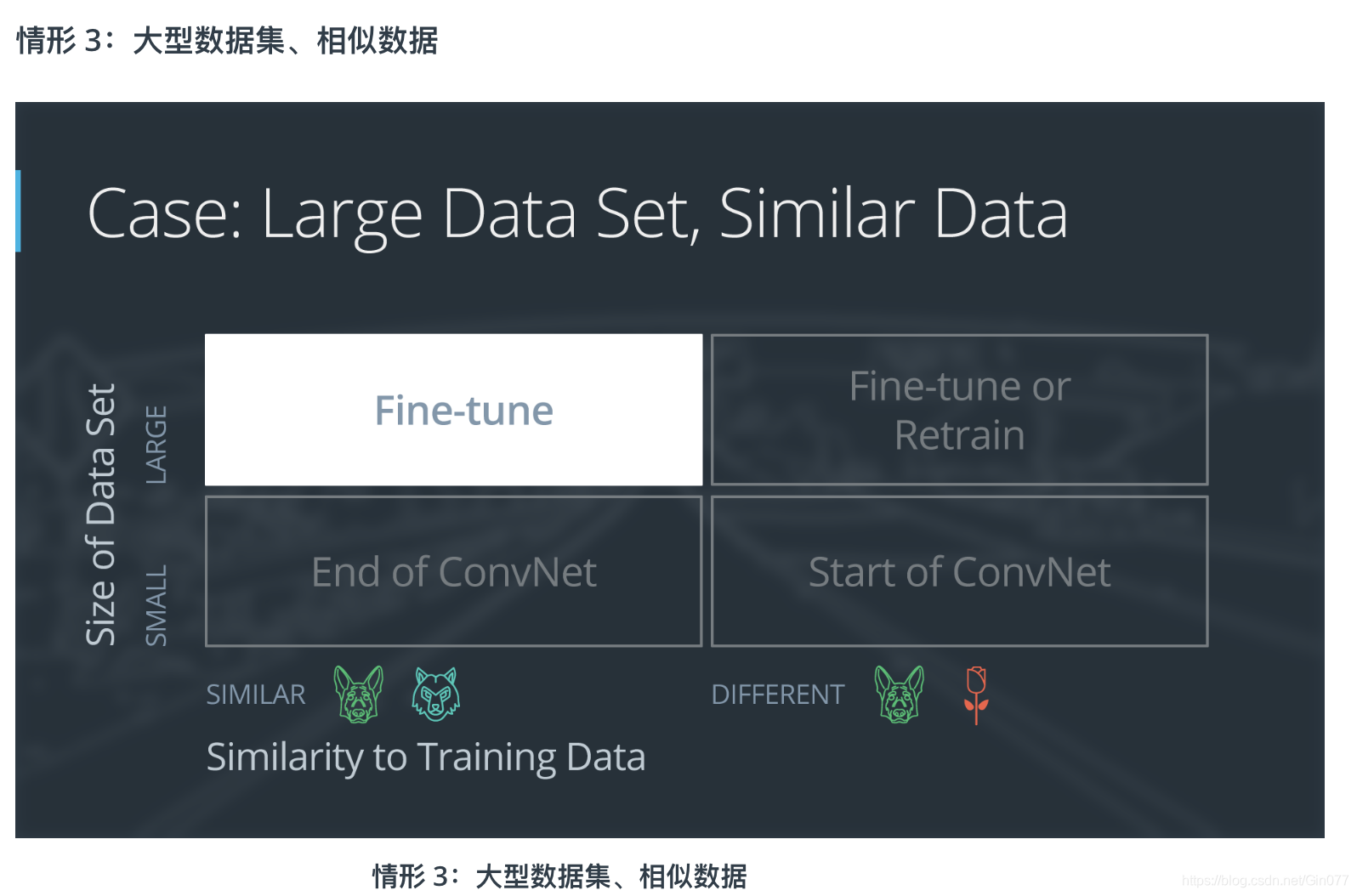
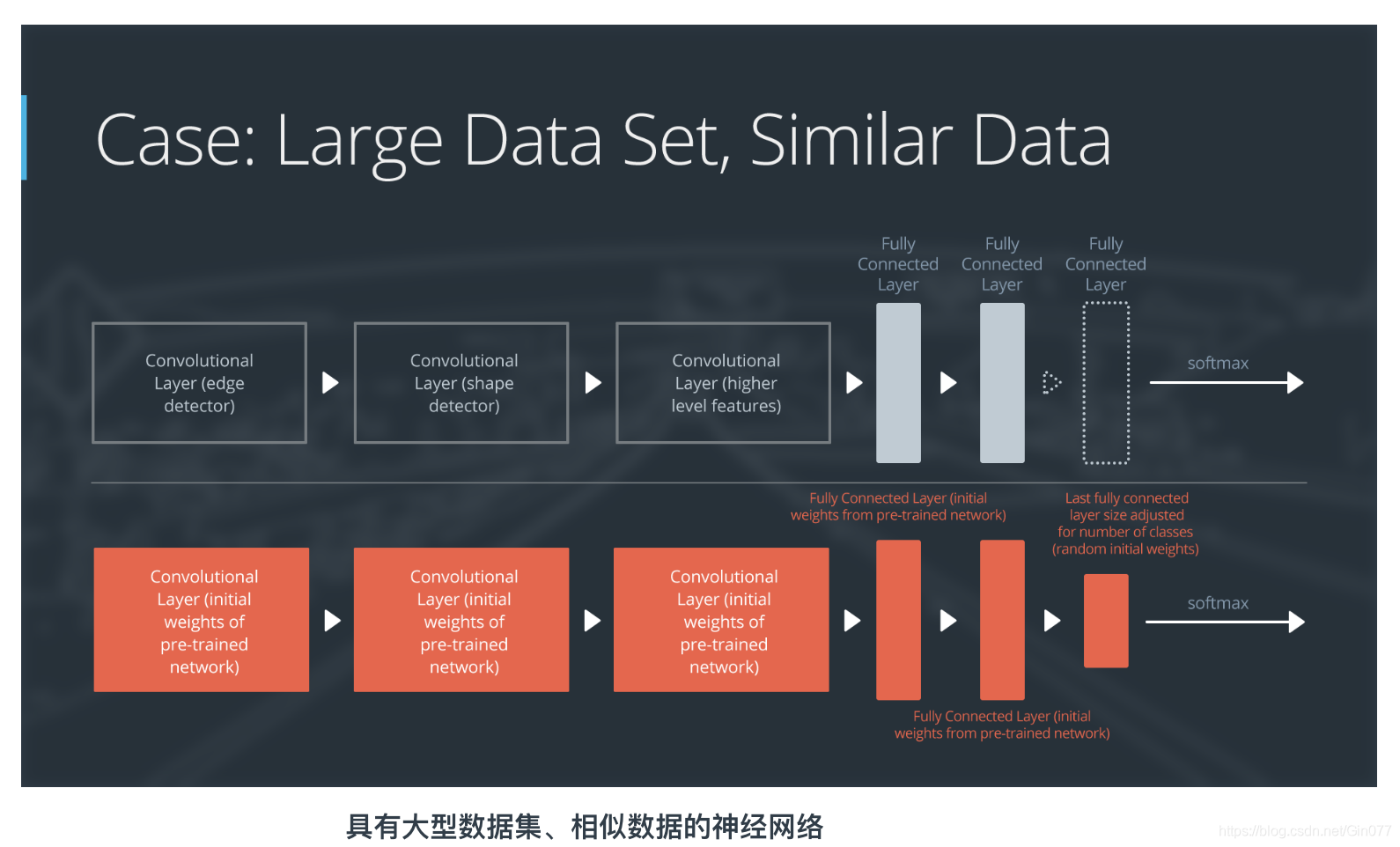
如果新数据集比较大型,并且与原始训练数据相似:
- 删掉最后的完全连接层,并替换成与新数据集中的类别数量相匹配的层级
- 随机地初始化新的完全连接层的权重
- 使用预先训练过的权重初始化剩下的权重
- 重新训练整个神经网络
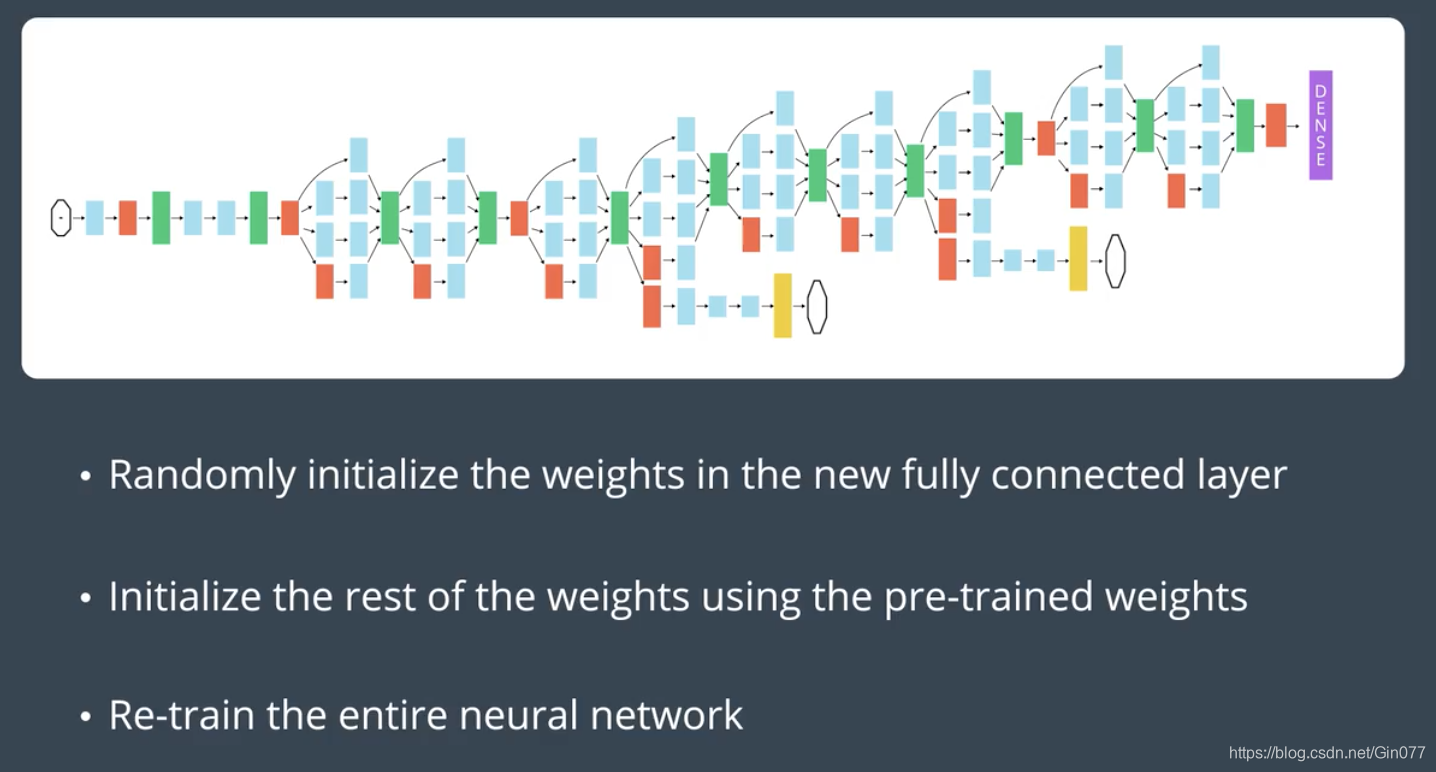
训练大型数据集时,过拟合问题不严重;因此,你可以重新训练所有权重。
因为原始训练集和新的数据集具有相同的更高级特征,因此使用整个神经网络。
以下是如何可视化此方法的方式:

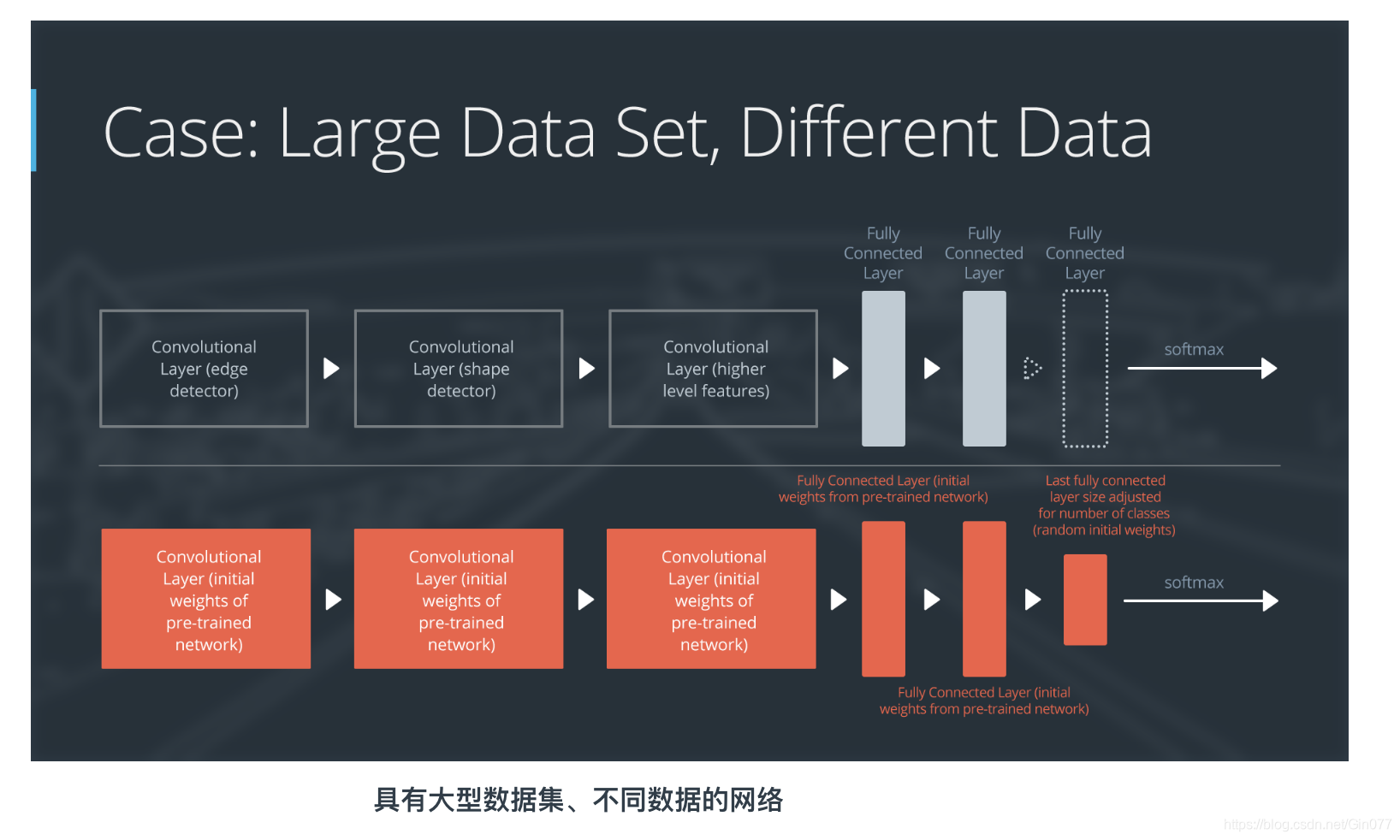
如果新数据集很大型,并且与原始训练数据不同:
- 删掉最后的完全连接层,并替换成与新数据集中的类别数量相匹配的层级
- 使用随机初始化的权重重新训练网络
- 或者,你可以采用和“大型相似数据”情形的同一策略
虽然数据集与训练数据不同,但是利用预先训练过的网络中的权重进行初始化可能使训练速度更快。因此这种情形与大型相似数据集这一情形完全相同。
如果使用预先训练过的网络作为起点不能生成成功的模型,另一种选择是随机地初始化卷积神经网络权重,并从头训练网络。
以下是如何可视化此方法的方式:
下面的论文系统地分析了预先训练过的 CNN 中的特征的可迁移性

















 2621
2621

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









