







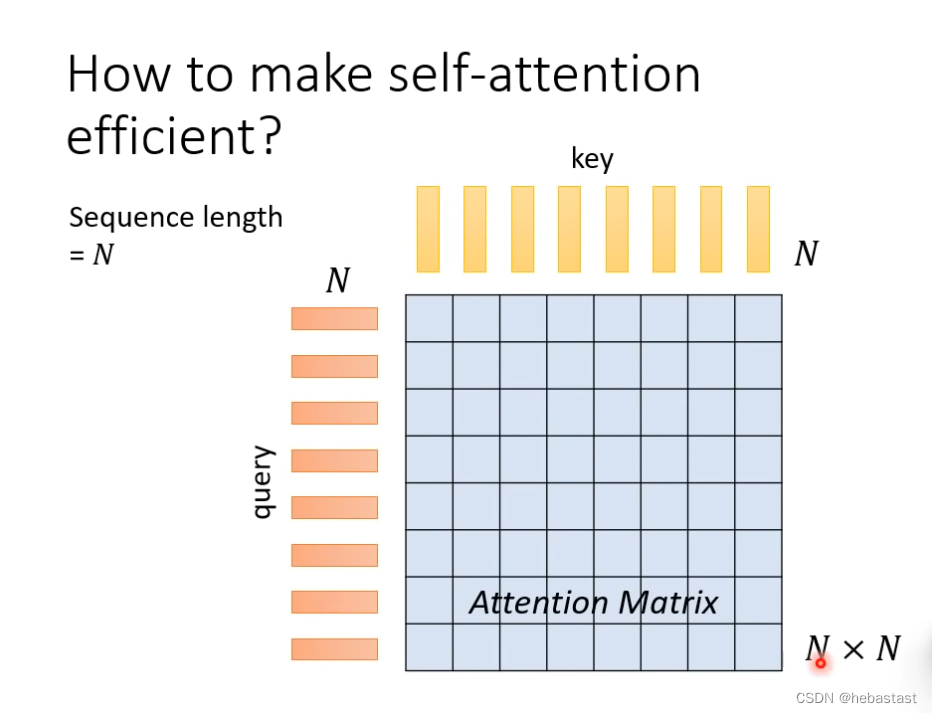
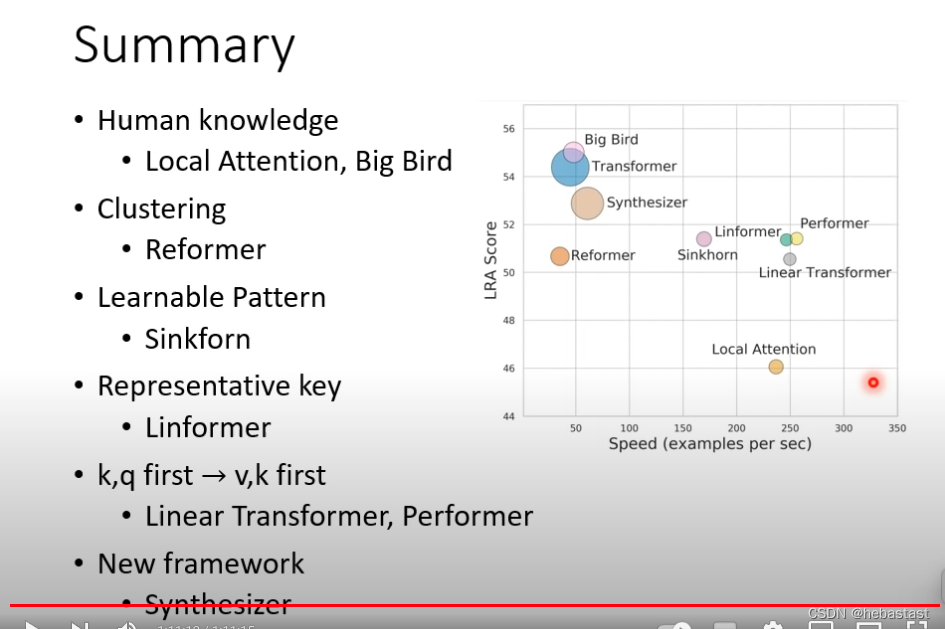
当输入sequence N很大的时候,这个时候self-attention 占据了绝大部分算力
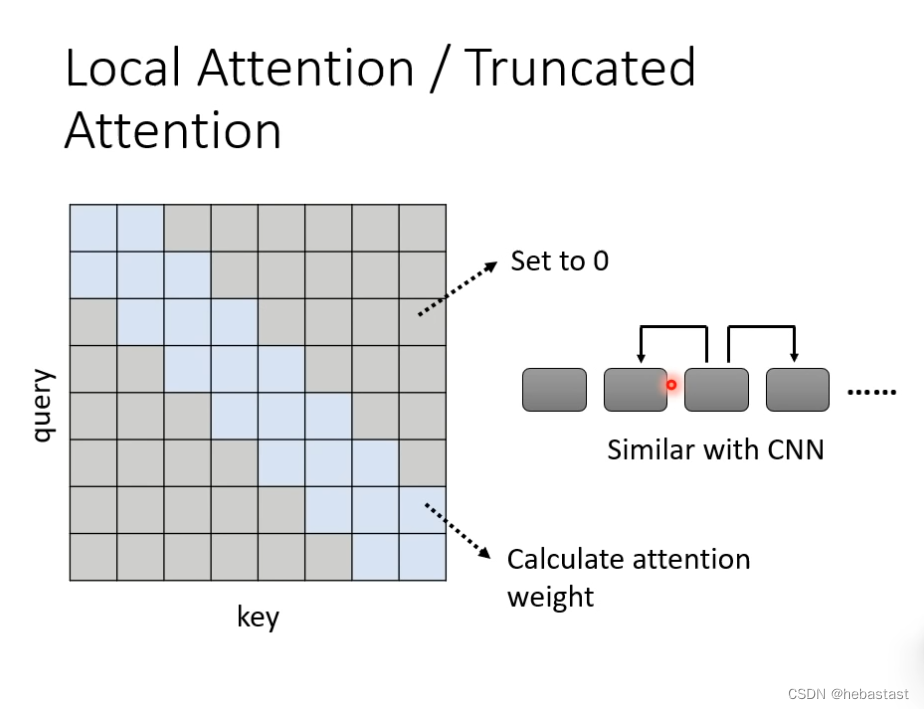
Local Attention / Truncated Attention
只需要关注附近的attention, local attention 和cnn 差不多,可以加速计算,但效果不一定好
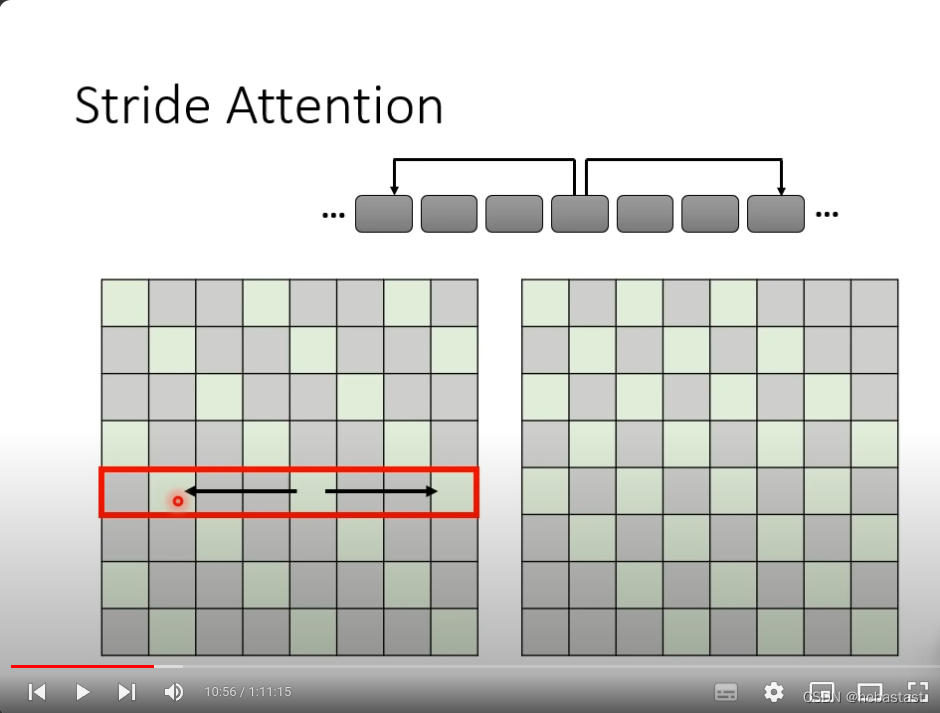
Stride attention
空几格attention ,需要根据问题本身来定义
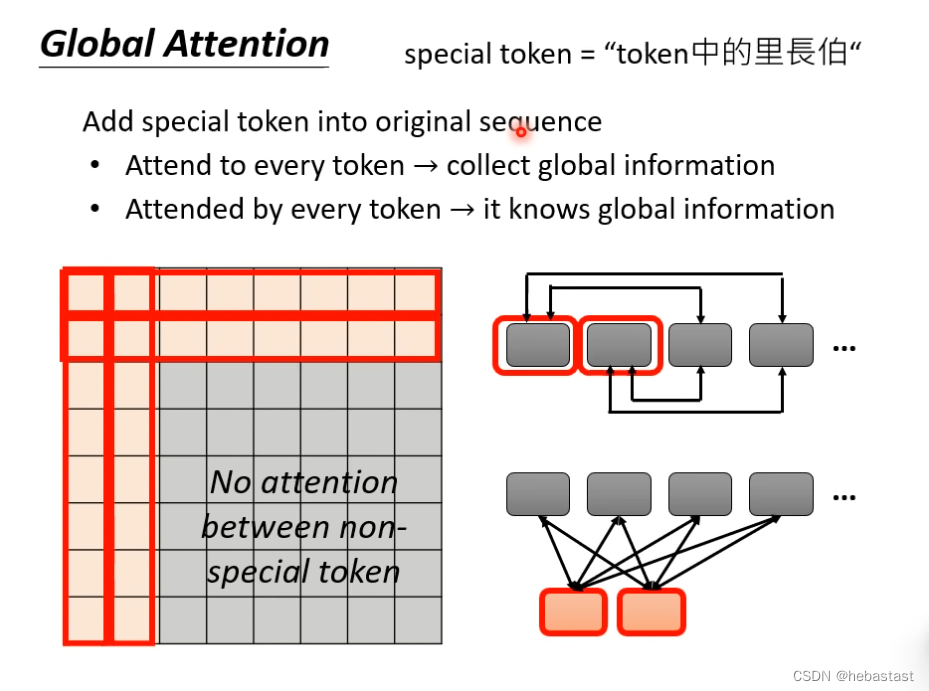
Global Attention
一种是在原来的token 里面 选几个作为special token
另外一种是,额外再做几个token ,其他所有的token 都要和这几个token 做attention
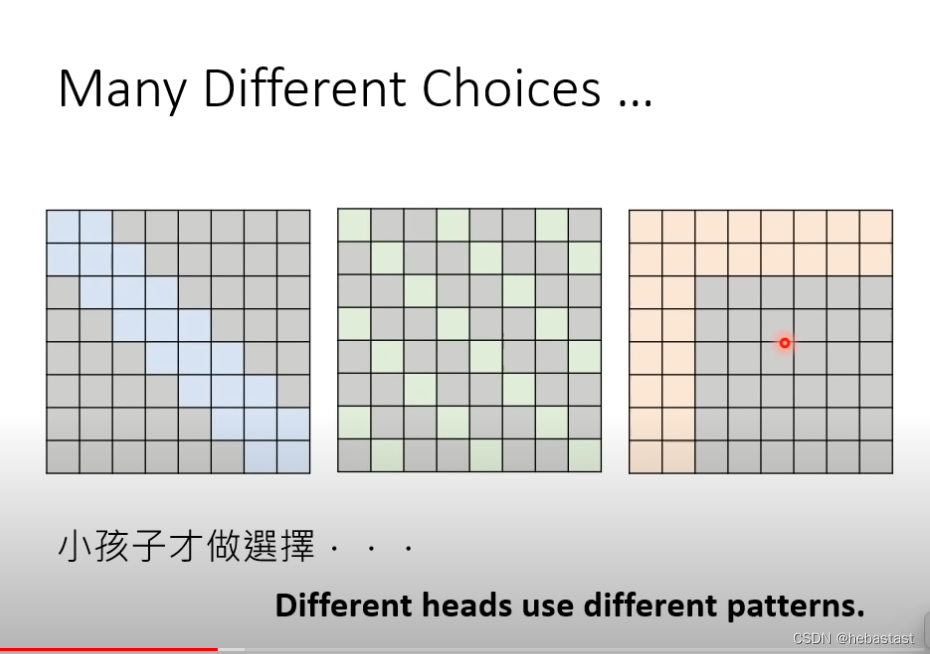
不同的head 做不同的attention
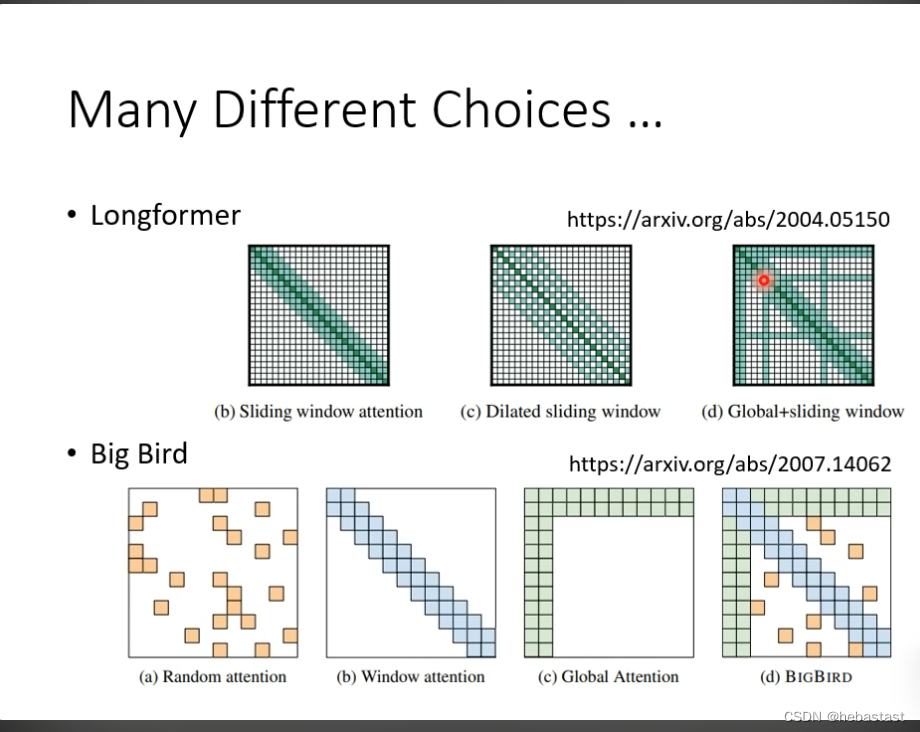
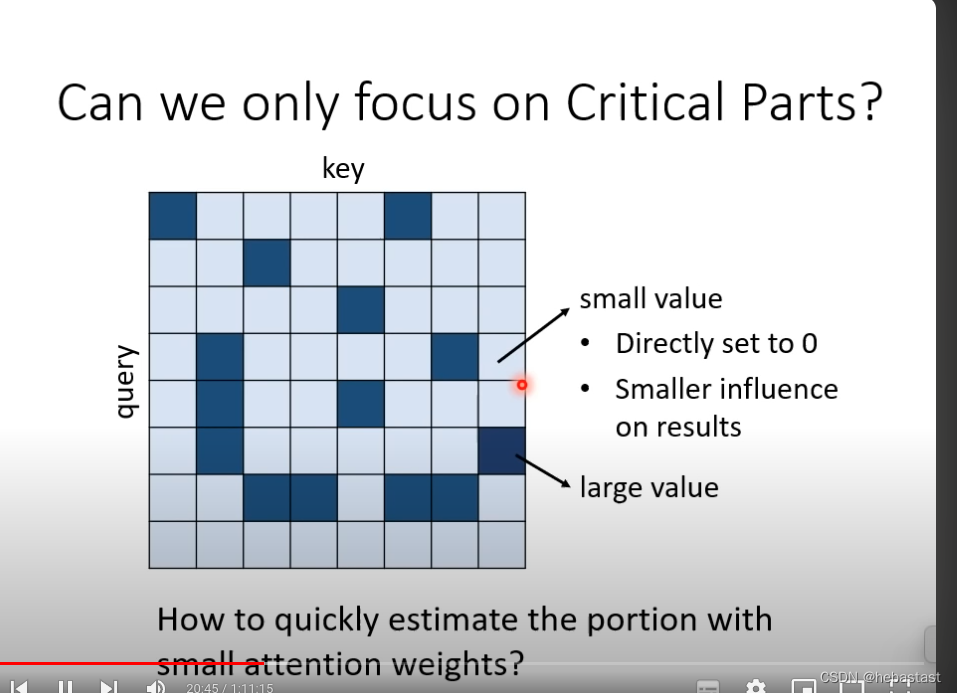
能不能 不要用人去规定哪个地方算attention , 哪些地方不算attention
大的attention 算,小的attention 的值不算
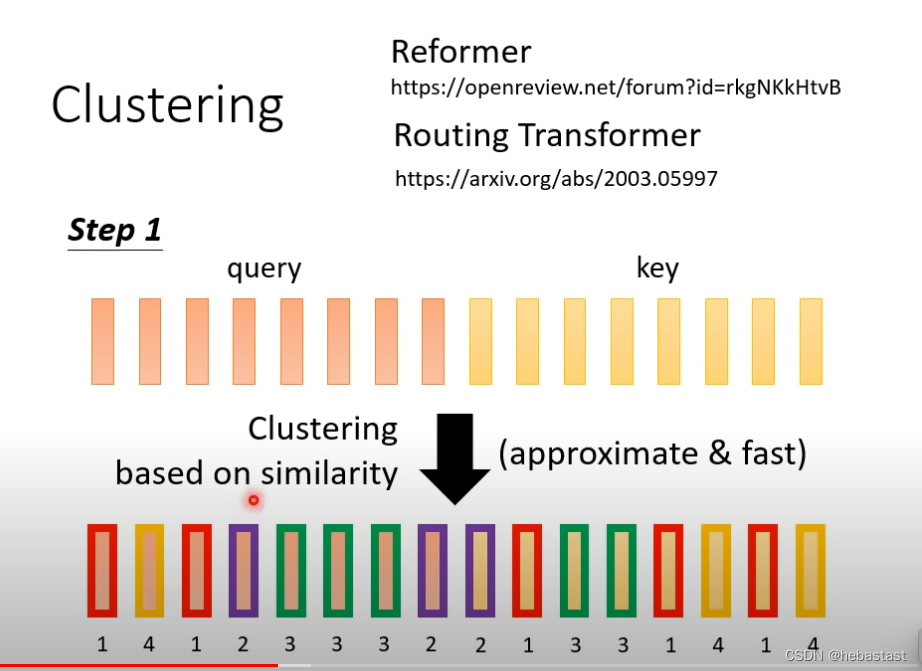
先做clustering 分类
Query 和key 进行分类
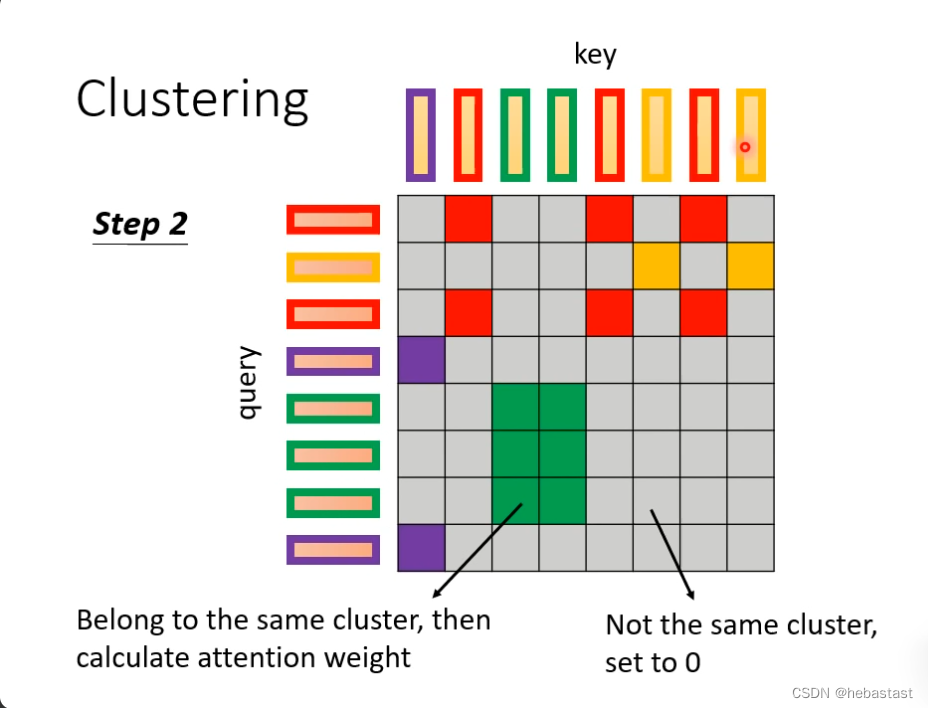
同一个clustering 里面计算attention, 不同的clustering 不计算attention
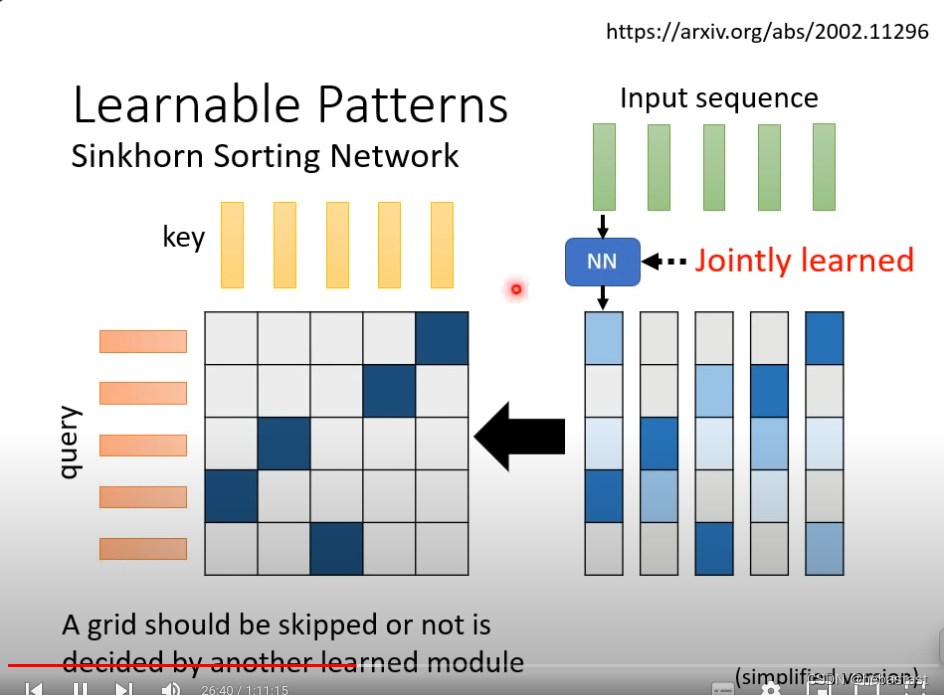
能不能把要不要计算attention 能不能用learn的方法计算出来
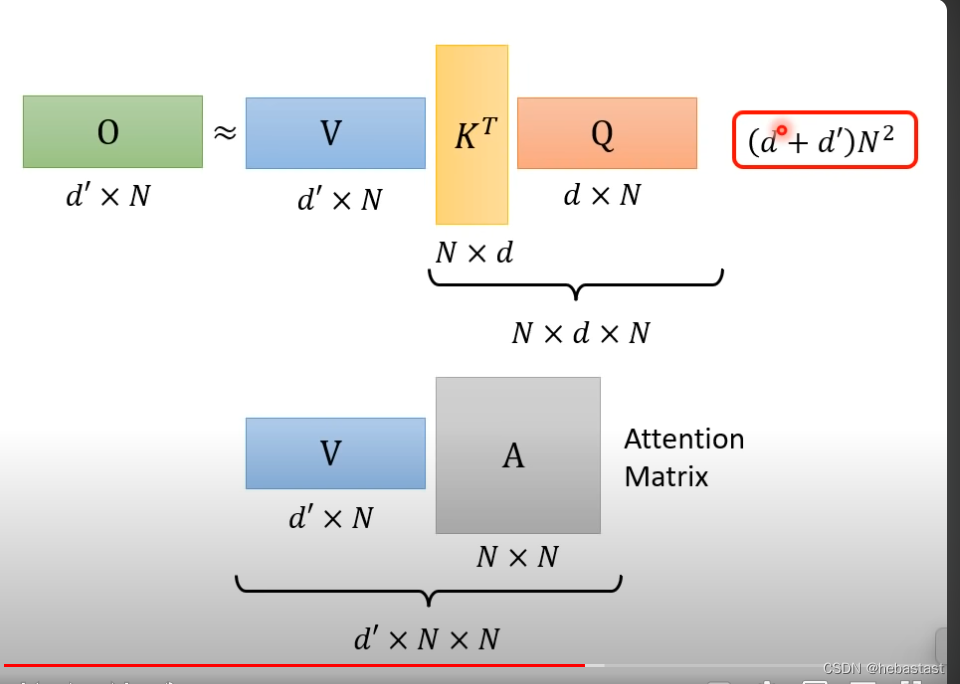
但是我们真的需要一个N*N的attention matrix 吗?
不需要一个N*N的matrix 很多的信息是重复的,我们可以拿掉重复的信息,只保留不重复的信息

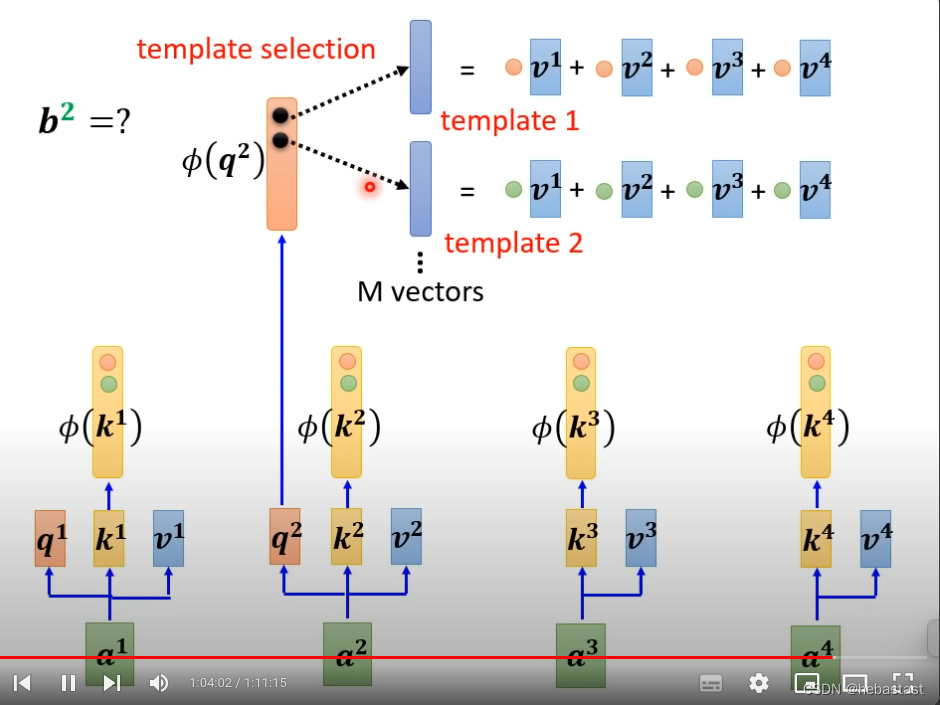
N个key不需要全部用,只需要选几个比较具有代表性的key
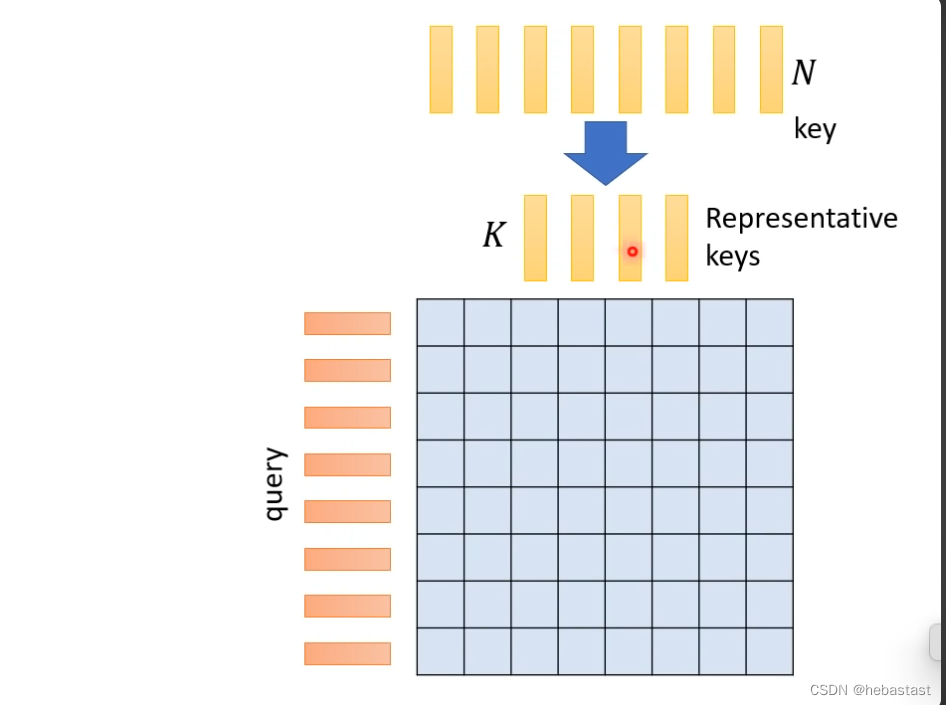
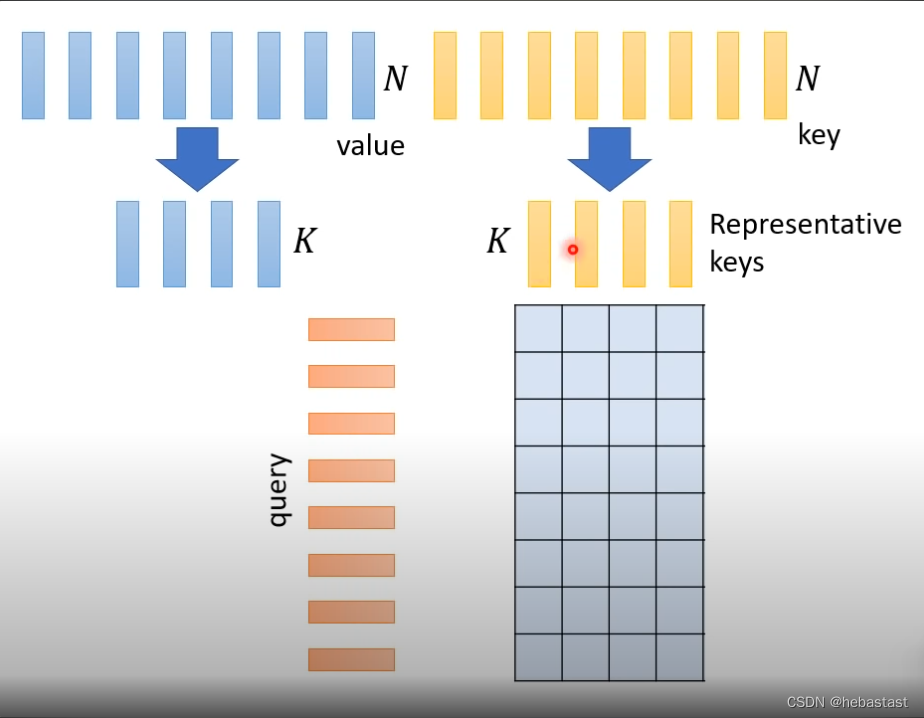
为什么只选有代表性的key ,没有选择有代表性的query ??
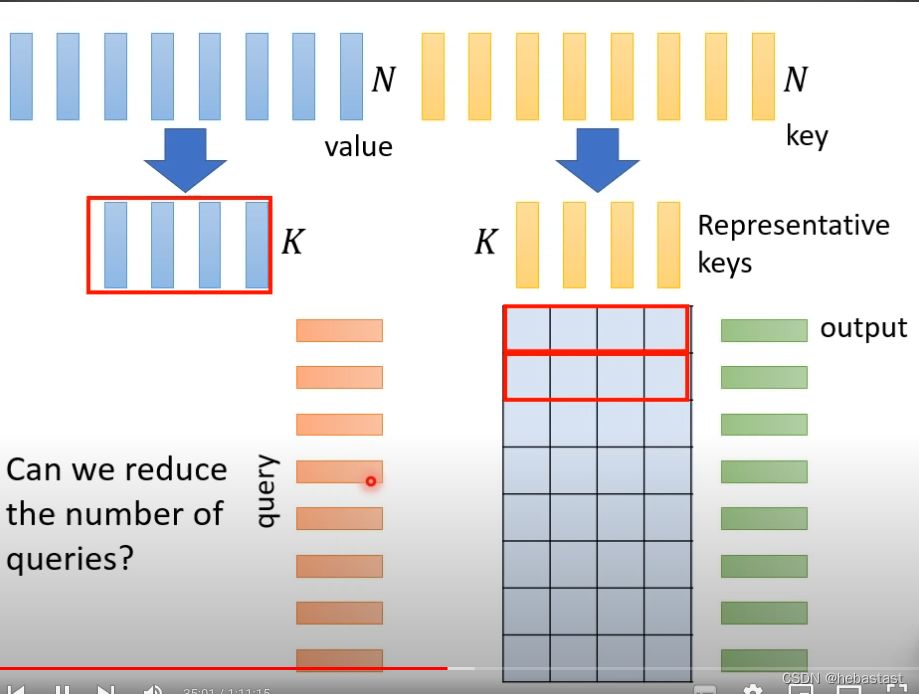
会导致Output sequence 的长度减少, 长度的减少会对 不同的任务有不同的影响。
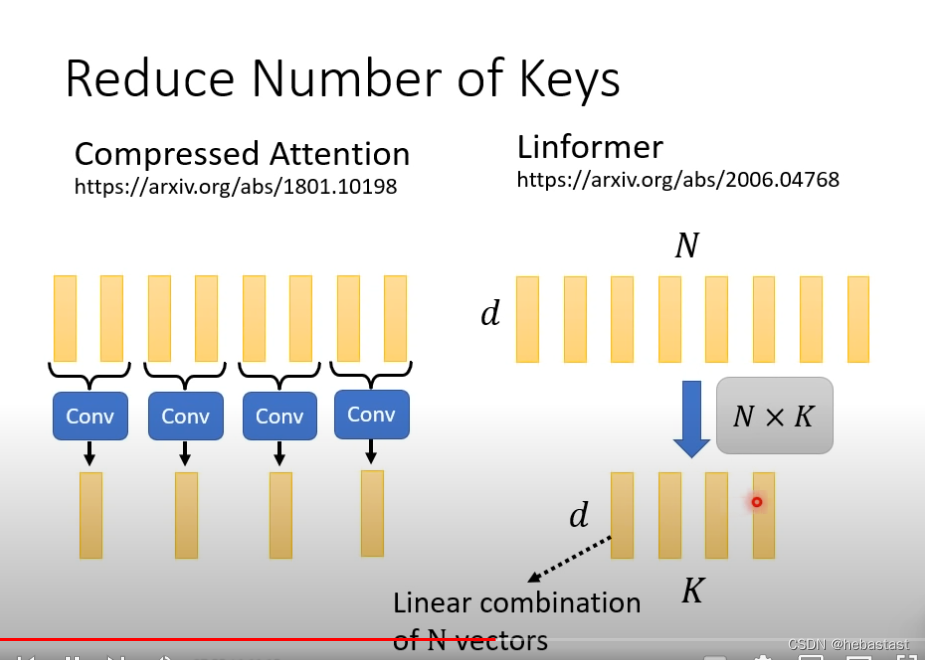
怎么选出有代表性的key呢
-
用cnn 处理
-
用矩阵相乘的形式处理
整个attention的过程用matrix 的形式表示:
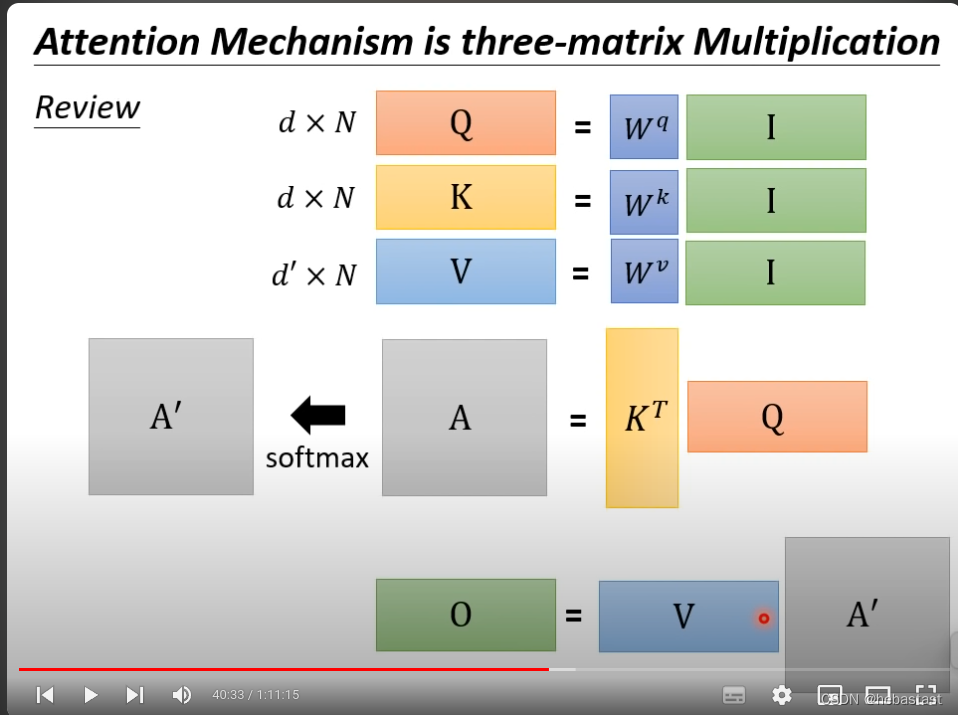
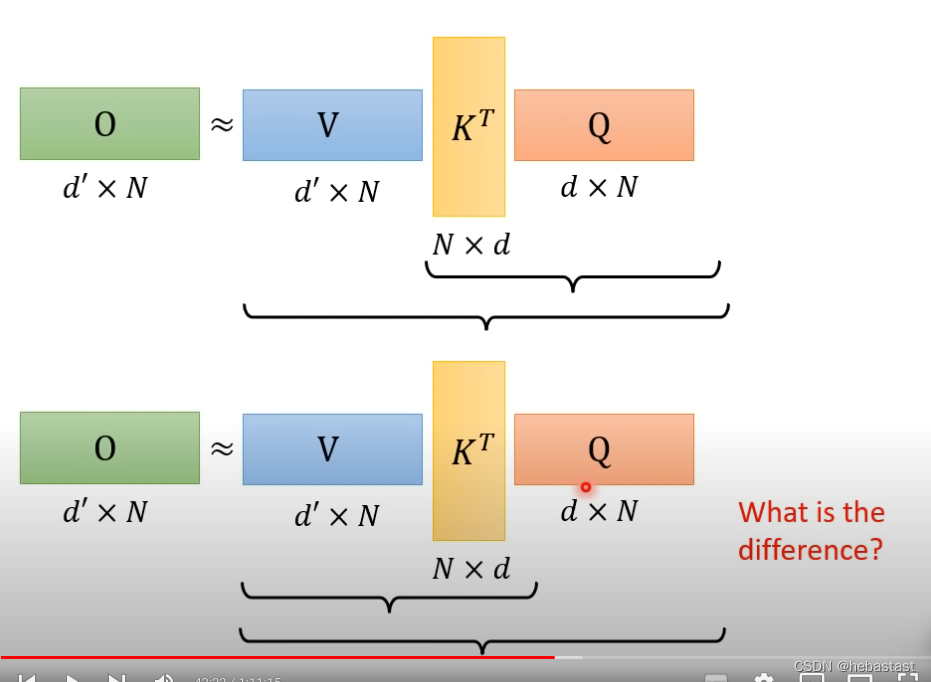
通过改变矩阵的运算的顺序来降低计算的耗时

第一种方法的计算复杂度
第二种方法的计算复杂度
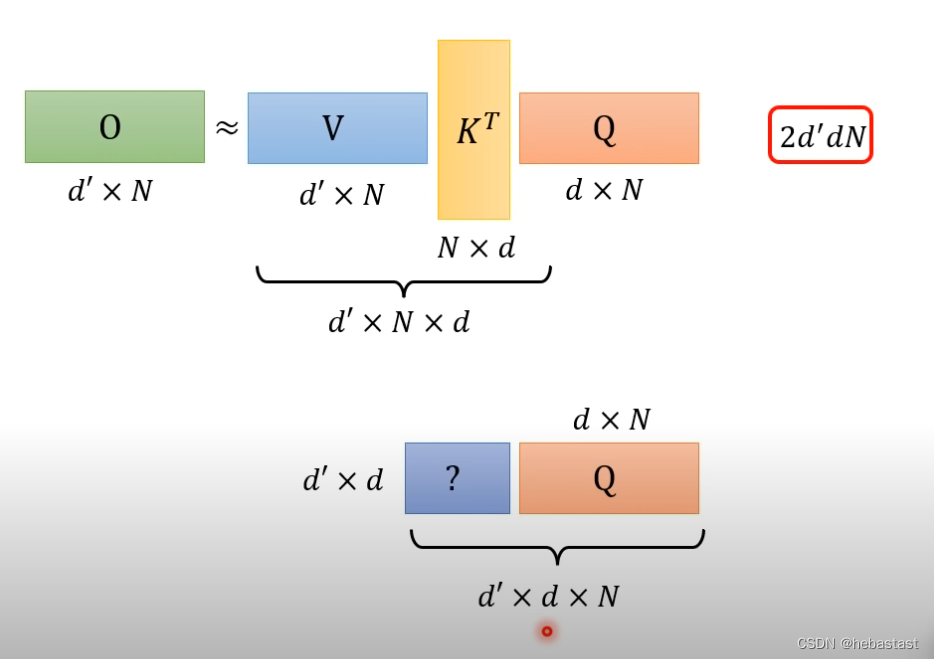
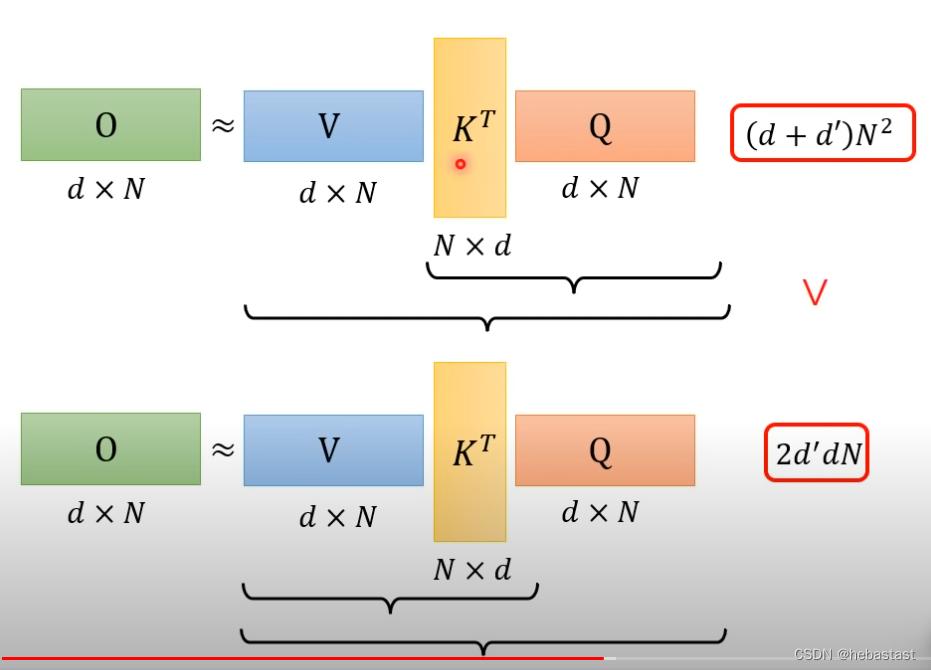
只要改变矩阵相乘的顺序
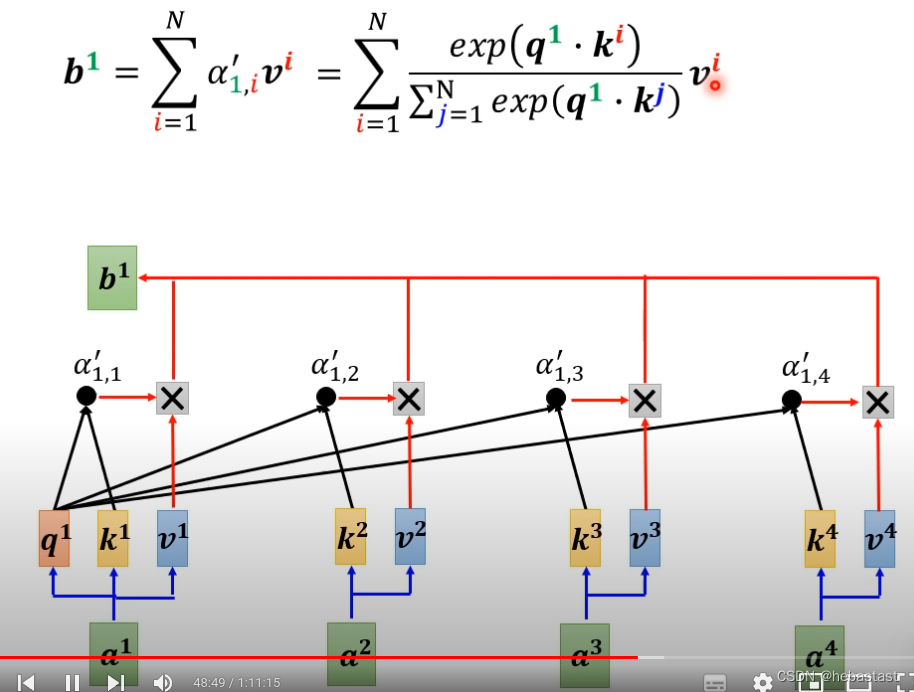
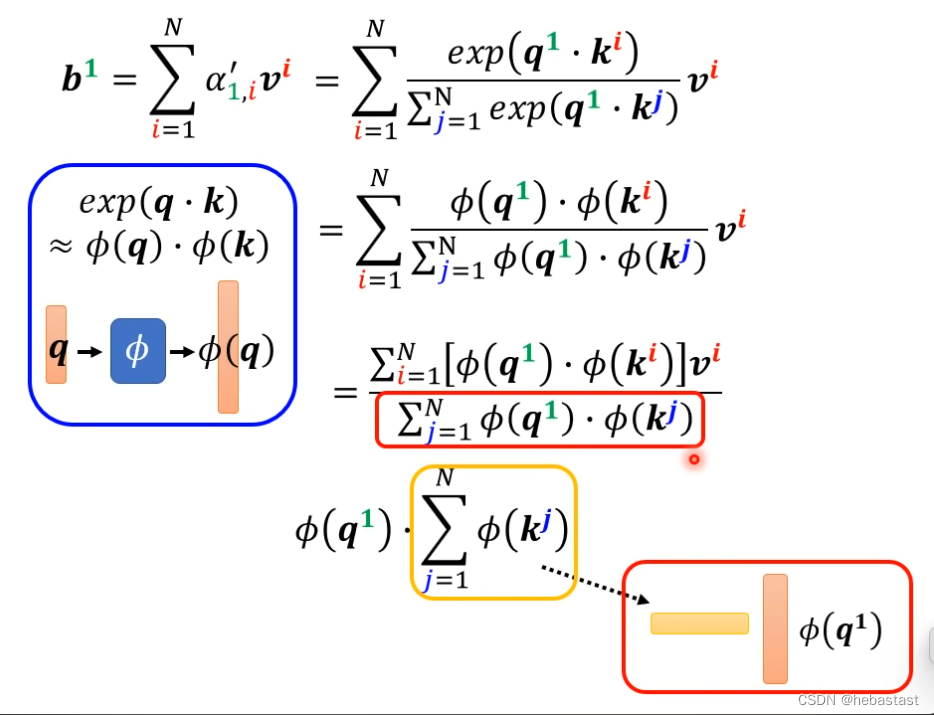
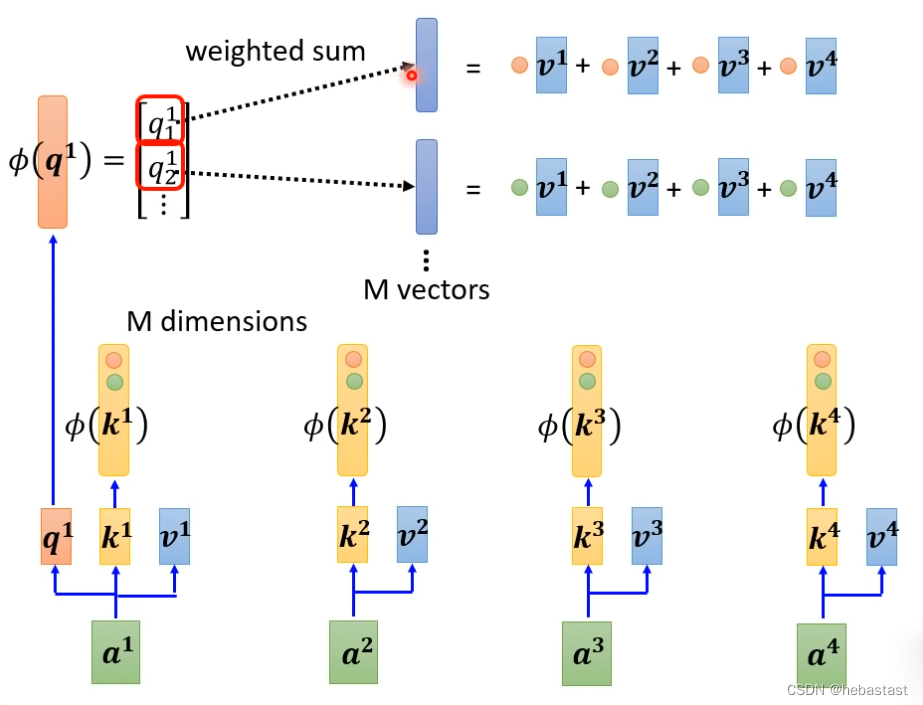
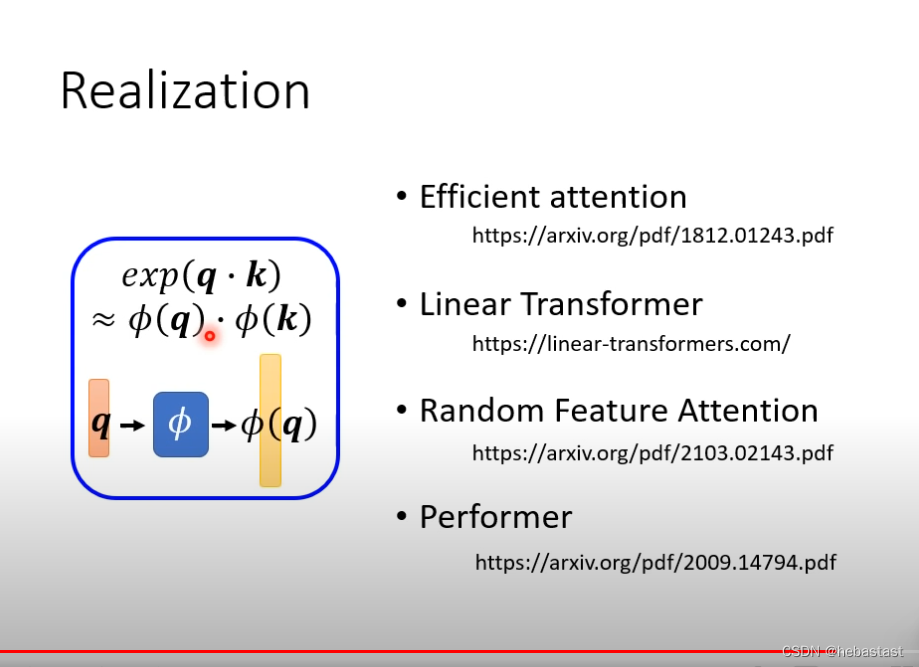
放回soft max 是怎样:


















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











