







一、核心训练框架
1. PyTorch
动态计算图:支持即时执行模式,研究者在训练过程中可实时修改网络结构
生态整合:与Hugging Face Transformers等库深度集成,提供完整训练工具链
生产限制:需通过TorchScript/ONNX实现模型部署,静态图优化能力弱于TensorFlow
典型场景:学术研究(论文复现率超80%)与小规模模型训练(参数规模<10B)

2. DeepSpeed
显存突破:ZeRO内存优化技术可将万亿参数模型分割存储于GPU集群
硬件依赖:需NVIDIA A100/H100 GPU配合CUDA 12.3+环境运行
典型场景:千亿参数级大模型训练(如GPT-4架构优化)
二、推理加速引擎
并发处理:动态批处理技术实现请求级并行,吞吐量提升3-5倍
部署复杂度:YAML配置模板需定义模型输入/输出张量维度

4. vLLM
技术创新:PagedAttention优化KV缓存,推理速度达Hugging Face的24倍
架构限制:仅支持Transformer类模型(LLaMA/GPT系列)
三、高效微调工具
5. PEFT
参数压缩:LoRA技术通过低秩分解将可训练参数降至1%-5%
显存优化:QLoRA量化支持在24GB显存设备微调70B参数模型

6. Unsloth
速度突破:内核级优化实现训练迭代速度提升300%
部署风险:自定义CUDA算子需重新编译二进制文件

四、边缘计算方案
7. llama.cpp
量化能力:GGUF格式支持4-bit量化,ARM设备内存占用减少70%
硬件加速:Apple Silicon Metal加速推理速度提升5-8倍

8. ONNX Runtime
格式统一:提供PyTorch→ONNX单行转换命令(torch.onnx.export)
芯片支持:Intel OpenVINO与NVIDIA TensorRT双后端加速
五、企业级服务平台
9. Xinference
多模态支持:集成Stable Diffusion/Whisper等视觉/语音模型
监控体系:内置Prometheus+Grafana看板,支持节点自动扩缩容

10. Ray Serve
流水线架构:支持模型组合服务(检索增强生成系统)
资源消耗:默认实例占用2核CPU/4GB内存
六、分布式训练工具
11. Accelerate
环境配置:通过accelerate config命令自动生成多GPU训练配置
功能扩展:与DeepSpeed兼容实现ZeRO-2/3优化

12. torchrun
弹性训练:支持节点动态扩缩容(最大容错率30%)
替代方案:逐步取代torch.distributed.launch启动器

七、大模型专项工具
13. Megatron-LM
并行技术:模型并行+流水线并行实现3D并行训练
硬件绑定:仅支持NVIDIA GPU集群(A100/H100)

14. Transformers
模型覆盖:Hugging Face Hub提供10万+预训练模型
显存瓶颈:70B参数模型推理需占用160GB显存

15. Ollama
本地部署:支持LLaMA-2 7B模型在M2 MacBook运行
隐私保护:数据全程不离开本地设备

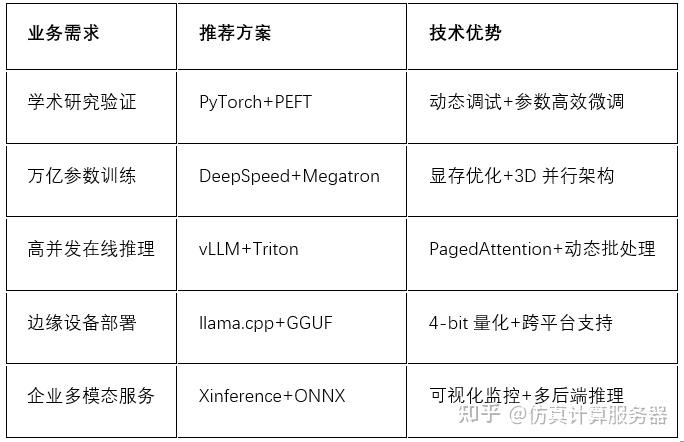
技术选型矩阵

















 8297
8297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









