







LibriSpeech该数据集为包含文本和语音的有声读物数据集,由Vassil Panayotov编写的大约1000小时的16kHz读取英语演讲的语料库。数据来源于LibriVox项目的阅读有声读物,并经过细致的细分和一致。经过切割和整理成每条10秒左右的、经过文本标注的音频文件,非常适合入门使用。
LibriTTS 是一种多语言英语语种,以 24kHz 采样率阅读英语语音约 585 小时,由 Heiga Zen 在 Google 语音和 Google 大脑团队成员的协助下编写。LibriTTS 语料库专为 TTS 研究而设计。它派生自LibriSpeech语料库的原始材料(来自LibriVox的MP3音频文件和古腾堡项目的文本文件)。
发现没有预训练的模型唉。。。那就自己训练吧。。。
明白论文是怎么回事了,但需要进一步的研究
只能用tarcoton了。但这个100是不是只有一个集合啊?
怎么做呢?我认为mfa_extraction的readme有错误。实际上就是加一个duration嘛。
CUDA_VISIBLE_DEVICES=0 python examples/tacotron2/extract_duration.py \
--rootdir ./libritts/ \
--outdir ./libritts/durations/ \
--checkpoint ./examples/tacotron2/exp/train.tacotron2.v1/checkpoints/model-65000.h5 \
--use-norm 1 \
--config ./examples/tacotron2/conf/tacotron2.v1.yaml \
--batch-size 32 \
--win-front 3 \
--win-back 3我还是需要弄懂这些到底是什么东西。唉。果然是发现不了的,怎么办呢?
4Preprocessing:
-
tensorflow-tts-preprocess --rootdir ./libritts \ --outdir ./dump_libritts \ --config preprocess/libritts_preprocess.yaml \ --dataset libritts
- 少一个train.txt?这是哪里来的?是网格化带来的,而tactron2可没有。没见过。我必须下载比较低版本的,那么找哪一个呢?两个两个来试试。
- 如果自己编译呢?
- 倒是成了,只不过有错误:
- 26565 wav file(s) were ignored because neither a .lab file or a .TextGrid file could be found, please see /home/beibei/Documents/MFA/libritts/logging/corpus.log for more information
Traceback (most recent call last):
File "aligner/command_line/align.py", line 186, in <module>
File "aligner/command_line/align.py", line 146, in validate_args
File "aligner/command_line/align.py", line 85, in align_corpus
File "aligner/corpus.py", line 539, in speaker_utterance_info
ZeroDivisionError: division by zero
Failed to execute script align
这个东西比我想象的要严重 - 这个lab文件原来是txt文件。。。
- 完全不行啊,还是少东西。。。
- 5Normalization:
-
tensorflow-tts-normalize --rootdir ./dump_libritts \ --outdir ./dump_libritts \ --config preprocess/libritts_preprocess.yaml \ --dataset libritts
Extract for valid set:
CUDA_VISIBLE_DEVICES=0 python examples/tacotron2/extract_duration.py \
--rootdir ./dump/valid/ \
--outdir ./dump/valid/durations/ \
--checkpoint ./examples/tacotron2/exp/train.tacotron2.v1/checkpoints/model-65000.h5 \
--use-norm 1 \
--config ./examples/tacotron2/conf/tacotron2.v1.yaml \
--batch-size 32
--win-front 3 \
--win-back 3Extract for training set:
CUDA_VISIBLE_DEVICES=0 python examples/tacotron2/extract_duration.py \
--rootdir ./dump/train/ \
--outdir ./dump/train/durations/ \
--checkpoint ./examples/tacotron2/exp/train.tacotron2.v1/checkpoints/model-65000.h5 \
--use-norm 1 \
--config ./examples/tacotron2/conf/tacotron2.v1.yaml \
--batch-size 32
--win-front 3 \
--win-back 3毕竟现在哪里有train与valid呢,说不定预处理后就有了。对,预处理后就有了。
训练是:完全不是一个人写的吧。。。绝壁不是一个人写的。。。我应该可以用之前的完成,因为都是一样的。不用这个100的了,用之前的实现。但是格式不一样啊?之前的如何实现的呢?
说不定可以了,但是太少了。而且extract duration是前是后,还是不相关呢?看看那代码,train与valid是自动生成的吗?
那么接下来我是放哪一个呢?是phone还是word?看你输入是什么了,我预测fastspeech是,音素的。。。看它的那个架构就是这样的。
CUDA_VISIBLE_DEVICES=0 python examples/fastspeech2_libritts/train_fastspeech2.py \
--train-dir ./dump/train/ \
--dev-dir ./dump/valid/ \
--outdir ./examples/fastspeech2_libritts/outdir_libri/ \
--config ./examples/fastspeech2_libritts/conf/fastspeech2libritts.yaml \
--use-norm 1 \
--f0-stat ./dump/stats_f0.npy \
--energy-stat ./dump/stats_energy.npy \
--mixed_precision 1 \
--dataset_config preprocess/libritts_preprocess.yaml \
--dataset_stats dump/stats.npy
最后的训练,也是如此的,
好吧,现在处理AIShell
哪里是处理好的,分明是刚下好的。。。
跟ljspeech完全不同啊。。。我真的需要看看这个data整理的py了。
先extration duration吧
AIShell是原生的。我需要对其进行处理,但是用fastspeech2来训练AIShell?不可能的,哪有这个example?自己造一个example?学的又多了,那么现在我先mfa出来交差。自己写一个脚本处理了。
好,处理完了
数据好像蛮多的,处理时间贼长
bin/mfa_align \
aishell/train \
lexcoin/mandarin-for-montreal-forced-aligner-pre-trained-model.lexicon \
pretrained_models/mandarin.zip \
result
TypeError: 'NoneType' object is not subscriptable
[23270] Failed to execute script align
这个问题是间歇性的,有时候能用,有时候不能用,可能是aishell忘了写train,这个问题没办法解决。。。
cannot create temp file for here-document: No space left on device,磁盘爆满,我再转移回去。。。
而且这个cd,tab一直是这么个东西。。。
2 该问题是在IO读写的时候,临时占用的内存不够,从而需要引入新的临时文件夹
在执行python命令前先执行
export JOBLIB_TEMP_FOLDER=/data/zhangweisong/TensorFlowTTS/montreal-forced-aligner/temp(临时目录的路径)
./bin/mfa_align ./aishell/train ./lexicon/mandarin.lexicon /pretrained_models/mandarin.zip ./result
这应该是下一步的问题。。。
centos-root 462843076 462843056 20 100% /
原来根目录满了。。。现在cd加tab不能用了。。462GB光home就349GB,应该不是我的问题
linux文件严格大小写,cannot create temp file for here-document: No space left on device
查看当前目录磁盘使用情况:
df -h查看指定目录磁盘使用情况:
df -h /data/查看当前目录每个文件夹的情况:
du --max-depth=1 -h
查看指定目录每个文件夹的情况:
du --max-depth=1 -h /data/查看文件夹下文件的数量:
ls ~ | wc -w
mfa_align: error: the following arguments are required: output_directory
这算什么意思呢?参数明明都设置好了啊?
换到另一个环境中试试呢?
FileNotFoundError: [Errno 2] No such file or directory: '/home/beibei/Documents/MFA/test/train/mfcc/raw_mfcc.0.scp'
是这个问题。。。
现在,更改模型,emmm,
fs2还是fs继承来的。。。我需要搞懂调用链。
你要知道,我首先设定的语句为:
CUDA_VISIBLE_DEVICES=0 python examples/fastspeech2/train_fastspeech2.py \
--train-dir ./dump_aishell3/train/ \
--dev-dir ./dump_aishell3/valid/ \
--outdir ./examples/fastspeech2/exp/train.fastspeech2.v1/ \
--config ./examples/fastspeech2/conf/fastspeech2.bilingual.v1.yaml \
--use-norm 1 \
--f0-stat ./dump_aishell3/stats_f0.npy \
--energy-stat ./dump_aishell3/stats_energy.npy \
--mixed_precision 1 \
--dataset_mapping ./dump_aishell3/bilingual_mapper.json
--resume ""
还是先看看代码吧,这是跑main函数,进行解析到args,有一个config参数,这个文件被解析到config
trainer与dataset应该毫不相关
比我想象的要难一点。。。
我认为不同的fs2实际上并没有什么不同。
现在就是漫无目的地修改
但是二者如何结合呢?
我认为fit联合二者。挺分散的,但是大致框架我猜到了。。。
@tf.function是与图模型有关的东西,与继承没有任何关系。。。
我假设就是如此的,那么,即便wav不是第一时间读取的,那些npy也是第一时间读取的。
dataset是tf包管的,那么接下来,你需要进行改动测试。
果然只是名字而已。
但关键是并不是所有都生成了speaker embedding,
带yield是生成器,这个生成器是一个迭代器,它的特点是debug步进式的,yield就相当于return,走到这一步就停下了。。。
我首先,将文件拆分,希望文件能够对应上
其次,我需要修改dataset,完全不懂的情况下填充,希望没事
最后,我需要给call加上,希望对接成功
的确是512,现在转存成npy,emmm,但是现在有在改,emmmm,唉,转不成npy了
分为三个阶段,整体框架认识,关键模块认识,细枝末节都认识,难道都要达到吗?那么问的可就多了,毕竟最后做答辩的时候,也是要用到的
因此你今晚需要明白明白。
降采样指的是成比例缩小特征图宽和高的过程
optimizer(各种下降)与loss仍是模型的一部分,只不过这是通过继承实现
compile用于配置模型,就是加入optimizer与loss,实际上在一个类,又彼此分开,
metrics:衡量指标,评估模型,用于输出。

那么。。。损失函数就是这些?
tf.keras.losses.Reduction.NONE:与输入形状相同的未减少的加权loss.
1. f0_stat,energy_stat是什么意思?
2. dataset是怎么传送到model里面的?
关于epoch,与batch
这里面,有用其函数吗?
def _train_step(self, batch):
if self._already_apply_input_signature is False:
train_element_signature = self._get_train_element_signature()
eval_element_signature = self._get_eval_element_signature()
self.one_step_forward = tf.function(
self._one_step_forward, input_signature=[train_element_signature]
)
self.one_step_evaluate = tf.function(
self._one_step_evaluate, input_signature=[eval_element_signature]
)
self.one_step_predict = tf.function(
self._one_step_predict, input_signature=[eval_element_signature]
)
self._already_apply_input_signature = True
# run one_step_forward
self.one_step_forward(batch)
# update counts
self.steps += 1
self.tqdm.update(1)
self._check_train_finish()关键代码就是在这里。说实在的,trainer类就没法看了。很明显就是如此提取的。那么呢,就是这么提取的,嗯,就假设如此了,trainer真的不是给人看的。
要是今天能够做好了就好了。
已经开始跑了,而且好像就两张卡。
(base) [root@localhost dump_aishell3]# ls spk_embeds/ | wc -w
88021
(base) [root@localhost dump_aishell3]# ls train/raw-f0 | wc -w
83633
(base) [root@localhost dump_aishell3]# ls train/durations/ | wc -w
83633
(base) [root@localhost dump_aishell3]# ls valid/raw-f0 | wc -w
89
(base) [root@localhost dump_aishell3]# ls valid/raw-energies/ | wc -w
89
发现了一个奇怪的点,
我认为现在的框架已经是极限了,但是模型还没有到极限,学一下模型吧,再学一下自动求导,自动loss
你知道为什么吗?因为有默认参数,那参数是怎么赋予的?那参数是一个items赋予的!
通过train_steps_per_epoch索引的
有的东西不继承,有的东西又继承,真是难受
当一个完整的数据集通过了神经网络一次并且返回了一次,这个过程称为一个 epoch。
在不能将数据一次性通过神经网络的时候,就需要将数据集分成几个 batch_size,每一个batch_size都相当于一个新的小数据集,即batch_size为新的小数据集的大小。为什么不能是全部或者一个,因为全部计算太多,一个则容易过拟合,或者说受误差影响非常大,那么这时候,取一下平均比较好
使用Batch Size个样本训练一次的过程叫做一个Iteration。
然后呢,里面的东西根本看不懂,而外面的东西相对而言很好看,
你用脚本跑一边就知道全不全了
不行,OOM,只能说,打包,发送到另一个。。。
转移断开怎么行?
rsync -avuz -e 'ssh -p 59125' /data/zhangweisong/TensorflowTTS-new.tar.gz beibei@125.77.202.194:/home/beibei/data1/TensorflowTTS-new.tar.gz
密码:bei@2021tts
rsync -auz -e 'ssh -p 59125' /data/zhangweisong/TensorflowTTS-new.tar.gz beibei@125.77.202.194:/home/beibei/data1/TensorflowTTS-new.tar.gz
磁盘又不够了啊啊啊啊,
转移过去了,继续改吧
batch_size: 32
现在看看这个,错误问题
实际上就连dataset都是继承的
为0,而且两次,那么我制作一个脚本,进行转移吧!
给了我全套的。。。看来要我自己好好处理了!那个spk_embeds就不要了!啊啊啊啊。。。。
接下来就是转换成npy,之前有做过,它在翔安。
啊,明白了,我不应该自作聪明
处理完毕,接下来应该是别的py
说实在的,放一块比较合适
得了,又重新开始。。。。
发现了名字上的大问题。。。SSB19180503,一共11个,SSB000900248,一共12个。。。卧槽。。。。
SSB0011-00283-raw-f0.npy
SSB001100283
SSB12190102
SSB00090030
卧槽,算了,先解压出来。
看来是可以了。
竟然能跑了,我感觉不大对劲啊。。。
stats.npycontains the mean and std from the training split mel spectrogramsstats_energy.npycontains the mean and std of energy values from the training splitstats_f0.npycontains the mean and std of F0 values in the training splittrain_utt_ids.npy/valid_utt_ids.npycontains training and validation utterances IDs respectively
有一个大问题,为什么必须要初始化呢?这不是送过来的吗?
第二,为什么不输出呢?
用pdb查出大问题了
这个可就不好办了,开始fit前必定要读取数据,这时间也太长了
它自己跑起来了。。。。
其他的变量预测器与speaker embedding是不同的,每一句都是生成的,对,不甚清楚,里面包含着这些信息
那还能怎么加?实际上multihead是不用管的,那么基本上就差不多了。
终于训练完了!试试看,太好奇了
发现连输出都不输出了,可能还要训练melgan
如果你仔细想一下它的这个结构,说实在确实可以分层,你要知道它这个张量是怎么回事,如果硬加的话,完全可以看作是乱码了,
它是包含的,batch size应该永远都是1,speaker就是10了,feather是384,你需要,emmmm,
inference里面的
duration_outputs = self.duration_predictor( # 预测器是在这里使用了
[last_encoder_hidden_states, speaker_ids, attention_mask]
) # [batch_size, length]
energy_embedding = self.energy_dropout(
self.energy_embeddings(tf.expand_dims(energy_outputs, 2)), training=True
)
而call里面的
energy_embedding = self.energy_embeddings(
tf.expand_dims(energy_gts, 2) # 从参数里传来的
) # [barch_size, mel_length, feature]tf.expand_dims(
input, axis=None, name=None, dim=None
)
例如,如果您有一个shape的图像[height, width, channels],则可以expand_dims(image, 0),这将使shape成为[1, height, width, channels]。
一次call是一个batch的,不然加s干嘛,对吧。而load_data是一次一个语音,这中间用trainer运作的。那么batch啊,speakerid啊,就不是自己操作的了。
它必然是个张量无疑,原来两层mel是,毕竟一个mel是一个194的数组,然后扩充了之后,里面每个元素都加上了384个,实际上这个是全新的了,
好吧,它必须完全地明白。
首先呢,一段文本或音素 encode,然后成中间变量,再decode,就成语音了。
为什么音素不直接拼接变成语音呢?实际上就是要它的连贯性,之前依次合成(自回归)可能有些技巧实现,但是现在并不需要什么技巧了,硬合就可以了。
其次,什么是对齐呢?对齐就是一个音素要多长时间,训练时添加,生成时就自己合成了
然后它一个batch来一组的,一个batch的语音文本用矩阵的方式合成,至于怎么back,是需要特别的数学矩阵运算的
然后中间有卷积什么的,那么怎么做呢?
大致框架绝对没问题,那么它这个隐藏的特征是怎么回事呢?
一个duration肯定是一个数组嘛,一个音素序列也是一段数组,
mel_length 可以理解成对多少帧的语音,帧实际上就是采样,每一个帧那可就细多了,每一个帧有384个特征
f0 和 energy 都是依照帧级别进行提取的,相当于每一个帧一个f0,究竟是数组还是数这个不好讲,它是什么格式的?很明显,是[barch_size, mel_length, feature]这样的,都写好了的。它是怎么训练和推断的呢?在call里直接就有,在inference里自己生成,它是怎么变成这个格式的呢?
当然,你需要完全明白,不能偷工减料
先将N个采样点集合成一个观测单位,称为帧。通常情况下N的值为256或512,涵盖的时间约为20~30ms左右。为了避免相邻两帧的变化过大,因此会让两相邻帧之间有一段重叠区域,此重叠区域包含了M个取样点,通常M的值约为N的1/2或1/3。通常语音识别所采用语音信号的采样频率为8KHz或16KHz,以8KHz来说,若帧长度为256个采样点,则对应的时间长度是256/8000×1000=32ms。
FFT,快速傅里叶变换
每一个帧都有384个特征,这个应该是必然的,不用看论文也知道,
你没有办法直接加上,格式不对,也不能硬加,现在的问题就是把论文的核心部分一句一句琢磨透。
fead forward transformer FFT ,可以理解成最简单的transformer,对于头部和尾部最多大致了解即可,因为从encoder出来它就没有进行过维度变化了
如果如此的话,中间的就很透彻的,看看中间的论文
在变量预测器中,1d卷积的卷积核大小设置为3,这两层的输入/输出的维度为256/256,并且dropout速率设置为0.5。说明普通的输入,f0,energy就是256的shape,嗯,而具体设置都是在config里面

变量预测器有相似的模型结构和FS中的时长预测器。这把隐藏的序列作为输入并且预测了每个音素(时长)的变化,或每一帧(音高和能量)通过均方误差损失。变量预测器由2层的ReLU激活的1D卷积网络组成,每一层都紧跟着LN(层标准化)和dropout层,并且一个额外的线性层去投影隐藏状态到输出序列。对于时长预测器,时长是每个音素在对数域上的长度。对于音高预测器,输出序列是帧级F0序列,对于能量预测器,输出是每个mel谱帧的能量序列。所有的预测器共享相同的模型结构但是不同的模型参数。
什么意思呢?就是只有在最后的线性变换才会有投影的作用,前面的1D卷积网络的作用只是用来提取。
一列w与多列w,emmm,因为输入的是个数组而不是矩阵,而且如果这样的话,就得训练predictor了。
本质上我需要分散这个speaker embedding而已,但是如何分散呢?我之前的错误仅仅是没看batch而已,但是如何分散呢?那如今怎么办呢?我至少今晚需要跟她联系,确定正确方案。
前几个特征是如何从mel水平运作的呢?它用predictor,自动转换,而我这个呢?应该也是如此,至少用一个线性映射,但甭管什么映射,它必然会有反向传播了,那么就必须有误差方程。

melgan是否也需要训练?很有意思的是,它这个也是直接的wav数据,应该不用改。
那么现在怎么办呢?继续深刻地了解原理。至少head你需要,emmm
multihead attention 可以类比CNN中同时使用多个滤波器的作用,直观上讲,多头的注意力有助于网络捕捉到更丰富的特征/信息。当你浏览网页的时候,你可能在颜色方面更加关注深色的文字,而在字体方面会去注意大的、粗体的文字。这里的颜色和字体就是两个不同的表示子空间。同时关注颜色和字体,可以有效定位到网页中强调的内容。使用多头注意力,也就是综合利用各方面的信息/特征。多头注意力的机理还不是很清楚。事实上,注意力机制本身如何工作,这个可解释性工作也还没有完成,multi-head对encoder-decoder attention提升不小,但对self-attention目前看提高很有限。在同一 multi-head attention 层中,输入均为 KQV ,同时进行注意力的计算,彼此之前参数不共享,最终将结果拼接起来,这样可以允许模型在不同的表示子空间里学习到相关的信息。
multi-head attention 这个结构真的是计算简单,效果强大.
multi-head attention 是继self-attention之后又一重大研究成果,其出发点是在transformer模型上,改进之前使用的传统attention。
普通attention,当翻译一个单词时只注意本单词,self attention,当翻译一个单词时注意句子中所有单词,挑最重要的。multi head是,翻译一个单词时,多用几个人注意句子中所有单词,然后不同的单词就会有不同的评分。
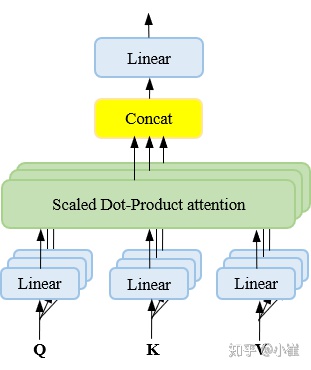
基本就是如此。
关于梯度下降法,back为什么会导致梯度下降呢?因为残差,残差小,改动的就小,在图上看来,它的速度就会变慢,越接近正确的结果,越慢
实际上就是曲线拟合,越接近,残差越小,但关于地形图什么事呢?我为什么要登顶呢?
因为损失函数,什么是损失函数呢?例如均方差损失函数,当它持久为0说明我要的函数拟合很好了。然后呢?我对损失函数求导,
这与最小二乘还不一样,最小二乘一下子就求出来了,
损失方差持久为0,或者很小一个值,则证明真实值与预测值相差不大,这就是最拟合的函数了,高峰或低谷就是我们想要的。梯度下降为什么不叫梯度上升呢?就是顶端就是一个残差极大值,并且不能再大了(存疑)。为什么梯度下降呢?实际上以参数作为自变量,隐含告诉你了这个函数是下凸的,是U型的。如果是n型,那就是梯度上升了。
紧接着,我们求的导,就是这个点的斜率,
全量梯度下降会达到最佳最小值,批量梯度下降容易进入局部最小值。只是一条的话就会有剧烈波动。
梯度下降法简单来说就是一种寻找目标函数最小化的方法。
以参数为自变量,以误差函数作为函数,找到这个函数的最低值(为0)时的参数值,这时候的参数最拟合原函数,
因为误差函数里就包括着原函数,那么参数也就包括着,那么原来的自变量是随便改的啊?没事吧?但是它们的特征是相似的,这是一族的,没问题,如果特征不相似,那的确收敛不了。
而为什么全部batch能下降到全局最优,部分batch只能下降到部分最优呢?
明白了,单个求导固然可以,但是同时算出多个一起求导也不是不行,再加之参数是一直变化的,就算全局也需要每次都重新计算梯度。
好了,那么就真的明白了。批量下降是需要特殊的数学运算的。
不对啊,这个不是很好看吗?哦,train文件是不对应的,淦,那这有什么意义呢?
文件里可能有,也可能没有,但wav文件是固定的,我需要提取而已。那我需要先读取文本,获取一个总的对应关系
然后根据不同的文件夹,找到它们的语音,用这个map对应,写一个新文件
现在至多有两个主要任务嘛,一个是看看语音是否真的有重的,只要比较文件夹的名字即可,二是重新生成这个文件
如今改的话绝对没问题
在深度学习里面,使用学习好的模型做预测的过程叫inference,至少在predict中有问题。但我不知道添加inference参数会不会报错啊,应该会报错的,因为用的链条不一样
debug,在不是动态图的情况下会出现这种错误!
Input tensor <name> enters the loop with shape (), but has shape <unknown> after one iteration
张量是不可变的。因为tf.Tensor可以保持在GPU显存中,而NumPy阵列总是由主机内存支持,并且转换涉及从GPU到主机内存的复制。为啥不能改呢,因为在GPU上,因此,先转成numpy,加倍后,转成tensor
已经可以成功训练了,但是,emmm,它的这个相加就不大对劲了
eval is not supported when eager execution is enabled
动态图模式下很多函数就都不认了
这个转整数真的好恶心啊
tensorflow中的tile()函数是用来对张量(Tensor)进行扩展的,其特点是对当前张量内的数据进行一定规则的复制。最终的输出张量维度不变。

把train改成valid,就是如此,果然可以!但是这个bug怎么解决呢?
倒也没什么问题。
根本就没办法debug啊。那怎么办?只能看error。。。。
跟f0是不对的,f0是batch,f0_length,换一个叫法吧,Timbre,没法改啊,而且也本来不是这个的问题。
[batch_size, mel_length]=>[batch_size, mel_length, 1]=>[batch_size, mel_length, 384]
[1,10]=>[1,10,1]=>[1,10,384]
[batch_size, 512]=>[batch_size, mel_length, 512]=>[batch_size, mel_length, 384]
[1,10]=>[1, mel_length,10]=>[1,mel_length, 384]
不对呀,是[1, 10]的啊,那么怎么会出错呢?因为乘以10倍。。。也不对
AttributeError: module ‘tensorflow’ has no attribute ‘Session’
提示:TensorFlow中没有模块Session;
原因是:我们引用的TensorFlow2.0版本,此版本与1.0相比没有模块Session。连session都没有吗。。。
解决方法就是把原来的tf.变为 tf.compat.v1.
而且都是1,10,384,没问题啊?
无论如何,维度是正确的,没有问题,但是就是融合不进去。。。
没有加进去之前,有错误:
WARNING:tensorflow:Gradients do not exist for variables ['tf_fast_speech2/speaker_embeddings/kernel:0', 'tf_fast_speech2/speaker_embeddings/bias:0'] when minimizing the loss.
2021-04-02 15:51:16,267 (optimizer_v2:1275) WARNING: Gradients do not exist for variables ['tf_fast_speech2/speaker_embeddings/kernel:0', 'tf_fast_speech2/speaker_embeddings/bias:0'] when minimizing the loss.
2021-04-02 15:51:19.721493: I tensorflow/core/grappler/optimizers/auto_mixed_precision.cc:1924] Converted 1185/11318 nodes to float16 precision using 125 cast(s) to float16 (excluding Const and Variable casts)
2021-04-02 15:51:22.374435: I tensorflow/core/grappler/optimizers/auto_mixed_precision.cc:1924] Converted 0/9362 nodes to float16 precision using 0 cast(s) to float16 (excluding Const and Variable casts)
没有太大的问题,加进去即可
/root/anaconda3/envs/fastspeech2/lib/python3.7/site-packages/tensorflow/python/framework/indexed_slices.py:433: UserWarning: Converting sparse IndexedSlices to a dense Tensor of unknown shape. This may consume a large amount of memory.
"Converting sparse IndexedSlices to a dense Tensor of unknown shape. "
将稀疏指数变换为未知形状的稠密张量,会消耗很大的内存。这个问题看来是做不动了。
Invalid argument: input depth must be evenly divisible by filter depth: 512 vs 10
为什么,因为最开始的初始化后,自动推导的东西,它,第一次就定型了。试一试,但为什么f0就没事呢?因为f0永远是1,没什么问题,而它只管最后的一项。
果然,由于自动推导,以第一个进入的数据类型为前提的话,那么,后面由10改成512就会出现那样的问题。

这算什么问题呢?不过 倒没事。。。
现在解决11层的问题,这个问题改改config应该可以。
这个config哪里是11层呢?得好好看看这个参数了。
n_speakers就不能是1.
hop size = 两个相邻窗口之间错开的sample数,越小,则说明时序解析度越高,计算成本也越高。
ValueError: You are trying to load a weight file containing 11 layers into a model with 10 layers.
并未解决
说实话,就不能用TFAutoModel,但问题是,用脚本的话,就没办法随意添加xvector了,emmm。
但是它这里uuid什么的。。。明白decode了,那么也不是很难了,先试试看看。。。mytest13就先不要了。
那接下来进行解码。
为啥都要绝对路径呢?而且说不定decode_melgan不能 那么做。。。
那么如何合成语音呢?只能自己写脚本了!幸亏自己也懂是什么意思。
但是按照脚本来看,就是那么做的啊?有点悬,但是我想试试她那个。
thrill,果然不一样。我直接复制粘贴。
挺清晰的,而且只是1个说话人!改改它那inference吧。
为什么model里的inference有_,而实际使用时没有呢?因为infernece是一个参数,它规定了静态图运行 了。
input must be 4-dimensional[1,49,512] [Op:Conv2D]
看来batch仍然是有十分重要的作用的,而且现在的batch也要弄了。
用了别人的,变成娃娃音了。。。她mel_gan没训练好。。。
我发现的确跟melgan有很大的问题,就算她的melgan也没办法切换语音。加了xvector变得很模糊。
不同的melgan与不同的fs模型结合,它的音色不同。。。
最佳组合是她的fs加我的melgan,特别清晰。

















 559
559

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









